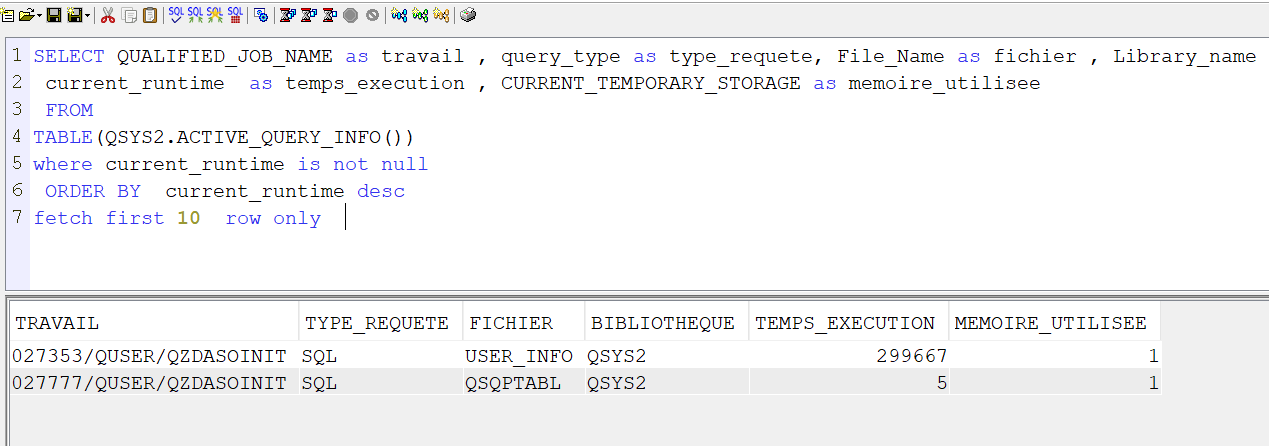
Vous connaissez l’outil ACS de gestion des packages OPEN SOURCE
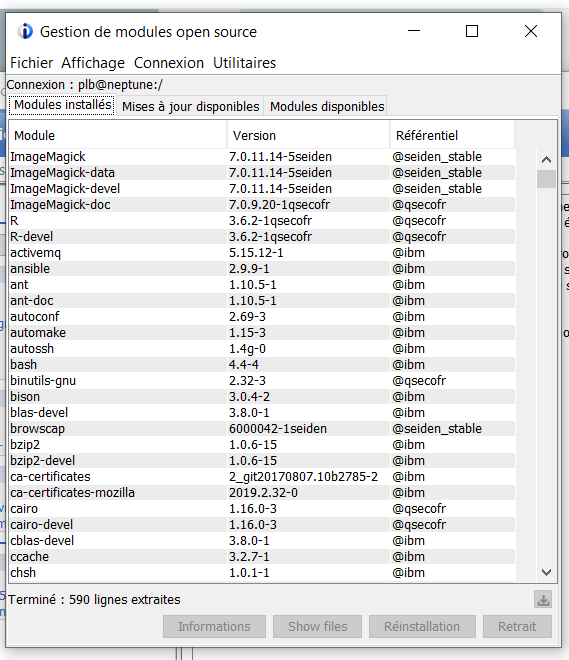
Si vous décidez d’utiliser l’Open source vous vous rendrez compte qu’il faudra sans doute automatiser la mise à jour des Packages RPM par YUM.
Voici donc quelques éléments pour réaliser cette opération !
D’abord vous devrez vérifier que vous avez bien Yum installé sur votre machine, normalement il est là, ACS l’utilise.
Les logiciels open source sont installés dans le répertoire
/QOpenSys/pkgs/bin
sous QSH
faire un cd /QOpenSys/pkgs/bin
puis ls yum*
yum yum-builddep yum-debug-dump yum-groups-manager
yumdownloader yum-config-manager yum-debug-restore
$ Vous devez avoir le fichier yum
il est conseillé de mettre ce répertoire dans votre Path.
Vous avez un fichier .profile éditer le pour ajouter ces 2 lignes par exemple à la fin de votre fichier .profile :
PATH=/QOpenSys/pkgs/bin:$PATH
export PATH
Il est également conseillé pour des questions d’homogénéisation de votre système d’utiliser un répertoire /home/votreprofil qui est la valeur par défaut de votre profil utilisateur (paramètre HOMEDIR de votre USER IBMi) et votre .profile devrait s’y trouver
Attention si vous voulez que ça fonctionne dans tous les environnements votre fichier .profile doit être en CCSID 819 !
Maintenant voyons comment procéder pour automatiser ces opérations de mise à jour
vous devrez planifier une tache qui lancera un QSH
la commande à passer pour voir si des mises à jour sont disponibles
c’est > yum check-update
Pour se faciliter la vie on mettra cette information dans un fichier txt
yum check-update > majpackage.txt
Ce fichier comporte l’intégralité des mises à jours et même les obsolescences
pour se limiter au logiciel qu’on veut mettre à jour on peut faire un cat avec un grep, par exemple nous on veut les mises à jour pour le logiciel NODEJS
cat majpackage.txt | grep « node »
nodejs14.ppc64 14.17.5-1 ibm
$
On voit qu’on a une mise à jour à faire, vous pouvez alors envoyer un mail par la commande sndsmtpemm pour indiquer la mise à jour à faire.
ou faire la mise à jour directement
yum update nodejs14.ppc64 -y –enablerepo=ibm
-y pour indiquer que vous allez installer en batch !
Il est conseillé de mettre un fichier de log exemple
Vous pourrez analyser ensuite la log en cas de problème en principe le nettoyage étant fait à la fin et votre version continu à fonctionner !
Il suffit de faire un ou 2 programmes CLP ou scripts Unix et d’y intégrer ce qu’on vient de voir !