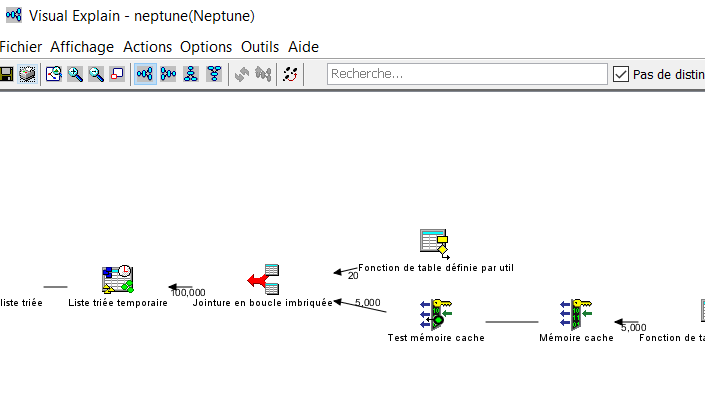
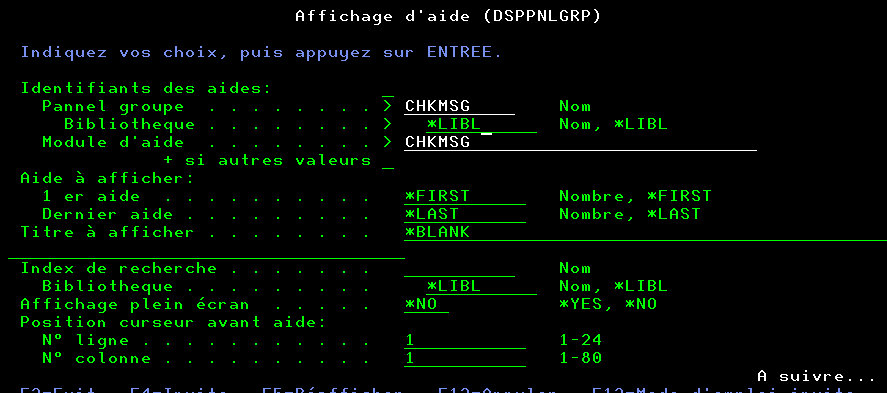
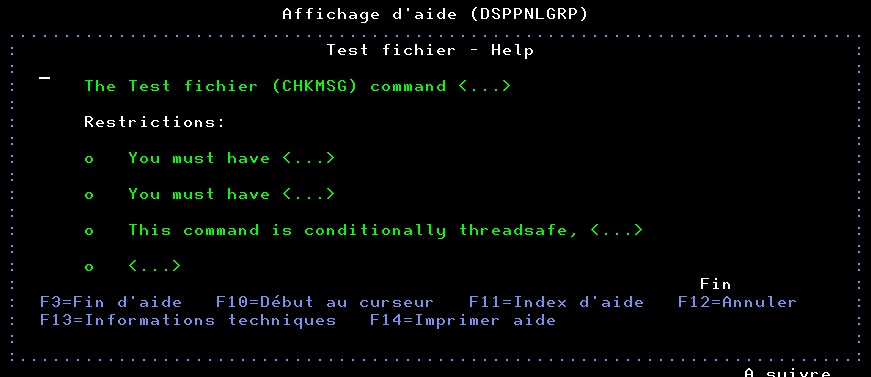
Vous voulez avoir des informations sur des exécutions SQL.
La meilleure méthode est de prendre la requête que vous voulez analyser et de l’exécuter dans Visual Explain.
Mais ce n’est pas toujours possible , dans le cas d’une chaine avec du SQL embarqué .
Si vous avez fait du SQL statique vous pouvez avoir des informations au niveau des programmes par PRTSQLINF.
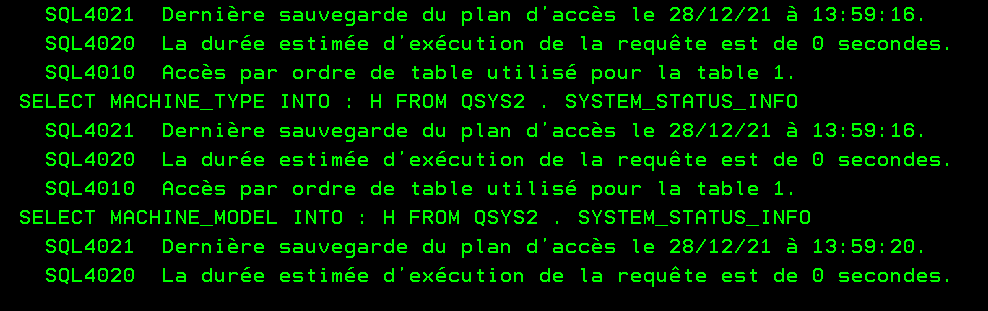
Dans certains cas, on n’a pas ces possibilités. Le plus simple est alors de ce mettre en debug et d’exécuter votre chaine, attention ce n’est pas un mode à mettre en place en production, ça augmente considérablement les informations de log.
Vous devez démarrer le debug, le plus souvent en indiquant que vous autorisez les mises à jour sur les fichiers de production. ==>strdbg updprod(*yes)
Vous lancez ensuite votre traitement qui va générer un log avec des messages de votre optimiseur SQL, ce sont des messages id CPI43xx
Il vous suffit ensuite d’analyser votre log et regarder si certains messages vous donnent des informations intéressantes. exemple : CPI432F index à ajouter
Pour vous aider nous avons fait cet outil DBGSQLJOB que vous retrouverez ici et qui vous facilite la démarche https://github.com/Plberthoin/PLB/tree/master/GTOOLS
Pour corriger des erreurs sur des ressources, suite à des arrets intempestifs ou des dsyfonctionnements : Les objets de QSYS Les fichiers de l’IFS Le catalogue Base de données
C’est la commande RCLSTG, elle nécessite de passer le système en mode restreint.
2) Date du dernier Reclaim Storage
Elle est indiquée dans la dtaara QRCLSTG de QUSRSYS DSPDTAARA DTAARA(QRCLSTG) position 1 date au format CYYMMDD vous pouvez visualiser la date de dernière exécution par SQL
SELECT CASE
substr(DATA_AREA_VALUE , 1 , 1) WHEN ‘1’ THEN substr(DATA_AREA_VALUE , 6 , 2) concat ‘:’ concat substr(DATA_AREA_VALUE , 4 , 2) concat ‘:20’ concat substr(DATA_AREA_VALUE , 2 , 2) ELSE ’01:01:2001′ END as datrclstg FROM QSYS2.DATA_AREA_INFO WHERE DATA_AREA_LIBRARY = ‘QUSRSYS’ and DATA_AREA_NAME = ‘QRCLSTG’
3) Estimer le temps d’exécution
RCLSTG ESTIMATE(*YES)
Se base sur les informations contenues dans la dtaara QRCLSTG. Si vous n’avez pas encore exécuté la commande, vous n’avez rien
En gros vous pouvez estimer à minimum 1 heure.
4) Voici ce qui est à vérifier après exécutions
Les objets sans propriétaire WRKOBJOWN QDFTOWN Les objets endommagés Dans QSYS DSPLIB LIB(QRCL) Dans L’IFS WRKLNK OBJ(‘/QOpenSys/QReclaim’) WRKLNK OBJ(‘/QReclaim’)
5) Avant de faire un RCLSTG
Vous avez certaines commandes qui peuvent permettre de corriger des erreurs sans être en mode restreint
Sur les bibliothèques RCLLIB
Sur l’IFS RCLLNK RCLDLO
Sur la base de données RCLDBXREF
Conclusion :
Même s’il est difficile de donner une fréquence, nous en conseillons un par an .. et dans tous les cas il est recommandé d’en faire un avant une montée de version
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-12-27 16:01:152022-04-06 10:53:155 choses à savoir sur le Reclaim Storage
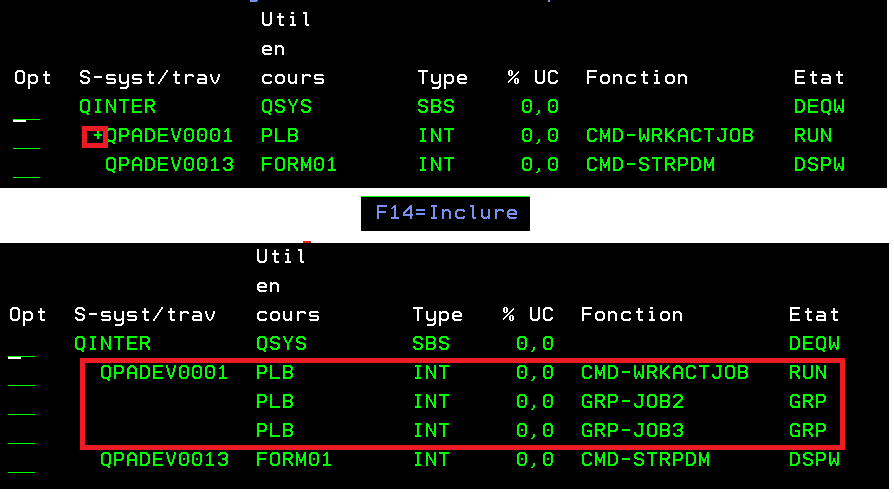
Vous pouvez utiliser une possibilité qui vous permet d’initialiser 16 travaux en même temps (mais un seul actif), c’est ce qu’on appelle les travaux de groupe; un peu comme une session alternée que vous obtenez en appuyant sur la combinaison de touches Appel système 1 .
C’est les jobs que vous voyez avec un + dans la commande wrkactjob
Voici comment utiliser les travaux de groupe
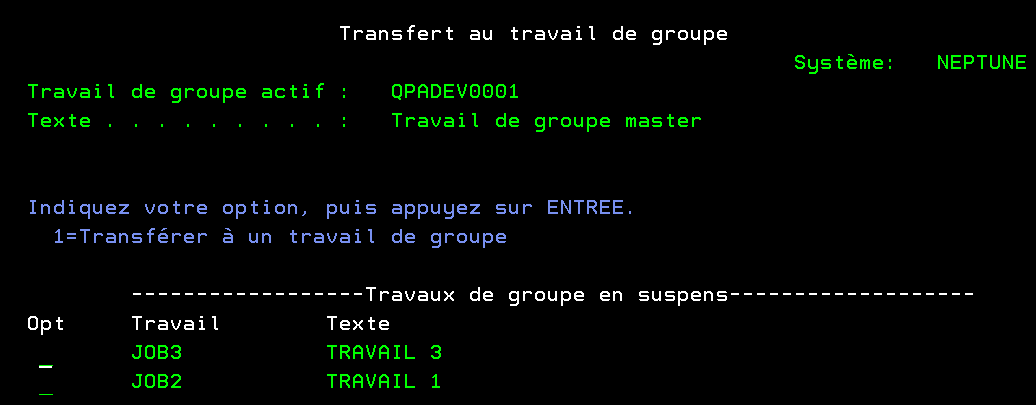
1) Démarrage
CHGGRPA GRPJOB(QPADEV0001) TEXT(‘Travail de groupe master’)
Vous pouvez communiquer entre vos différents jobs en utilisant une DTAARA particulière , *GDA (512 caractères) On est de moins en moins obligé de les utiliser, mais sachez comment cela fonctionne …
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-12-27 12:10:132022-04-12 09:56:19Les travaux de groupe
Vous installez de nouveaux PCs et vous désirez savoir les ports à ouvrir pour pouvoir accéder à vos partitions IBMi.
Voici une liste de ports à ouvrir en priorité
Pour ACS :
23 requis TELNET 449 requis arborescence du serveur IBM i 8470 à 8476 (voir RDI)
Pour RDi :
446 Requis (DRDA : connecteur base de données entre serveurs) 449 (as-srvmap) requis arborescence du serveur IBM i 3825 (Debugger) : débogage RDi 4300 (STRRSESVR) débogage via RDi (permet le rappel par l’IBM i du client RDi) 8470 (as-central) requis : Gestion des licences 8471 (as-database) requis base de données 8472 (as-dtaq) requis : serveur de file d’attente de données 8473 (as-file) requis : serveur de fichiers 8474 (as-netprt) serveur d’impression réseau 8475 (as-rmtcmd) requis : envoi de commandes 8476 (as-signon) requis : serveur ouverture de session
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-12-10 09:42:312022-04-12 09:57:53Ports à ouvrir pour ACS et RDi
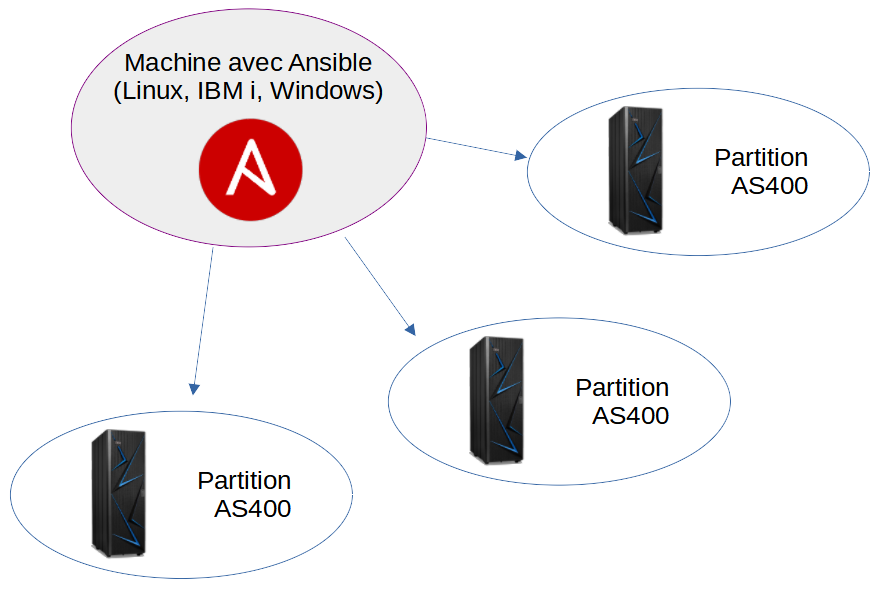
Ansible est un outil écrit en Python qui permet de faire des déploiements.
Ansible se sert de deux fichiers de configuration pour fonctionner.
Le premier est l’inventory, il regroupe les adresses réseau des machines qu’on souhaite gérer.
Le second est un playbook, il agit comme un script qu’on pourra exécuter sur n’importe laquelle des machines de l’inventory.
Tous les fichiers de configuration d’Ansible sont au format YAML.
À partir de ces deux fichiers Ansible établit des connexions SSH sur les machines de notre choix (depuis l’inventory), transfert le playbook sur les machines connectées, l’exécute et enfin fait remonter les résultats.
Cette approche permet de facilement réaliser n’importe quel type de déploiement à petite comme à grande échelle en écrivant un seul script, et en utilisant une seule commande.
Les résultats et les erreurs (si il y en a) sont tous remontés une fois que tout est fini.
Ansible est écrit en Python et l’utilise également pour exécuter les playbooks sur les machines, il faut donc que ce dernier soit installé sur les systèmes où l’on veut faire des déploiements.
Les actions qu’on peut demander à Ansible de réaliser sont des modules, qui permettent de réaliser une tâche spécifique.
Chaque tâche dans le playbook utilise un module, et on peut ajouter autant de tâches qu’on a besoin, comme dans un script.
Parmi les modules fournis avec Ansible on peut par exemple exécuter des commandes shell, manipuler des fichiers, en télécharger, etc.
L’intérêt du fonctionnement par modules c’est que tout le monde peut en écrire et on peut utiliser ceux qui sont publiés sur Ansible Galaxy par la communauté.
Cette plateforme regroupe des centaines de collections, qui contiennent un ou plusieurs modules. Il en existe déjà pour énormément de services et applications de toutes sortes (bien trop pour tous les citer ici).
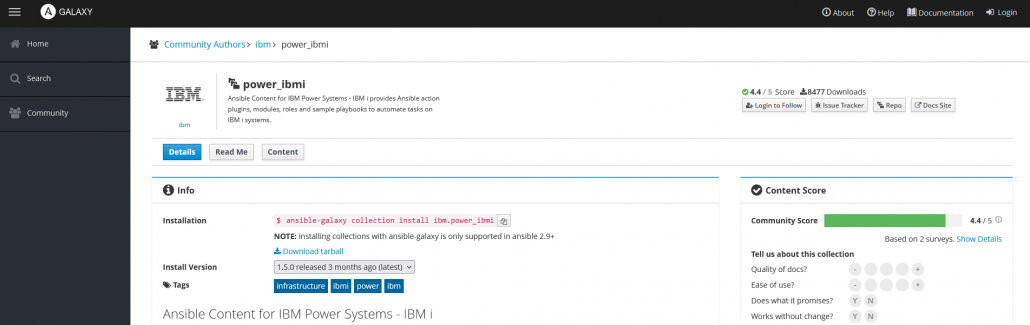
Il y a également des collections fournies par IBM pour interagir avec leurs systèmes, notamment l’IBM i avec la collection power_ibmi.
Pour réaliser des plus petites tâches rapidement il est possible d’exécuter des commandes dites ad hoc. L’exécution sera la même qu’avec un playbook, sauf qu’il n’y aura pas besoin de créer un playbook, à la place on donne les paramètres du module directement dans la ligne de commande.
Cette méthode est très utile pour des actions simples et moins fréquentes, par exemple pour redémarrer toutes les machines d’un inventory.
Quelques exemples simples
Voici à quoi ressemble un inventory très simple qui liste deux machines (machineA et machineB).
La partie vars permet de donner des paramètres supplémentaires pour les connexions SSH et l’exécution des modules.
Le paramètre ansible_ssh_user permet d’indiquer en tant que quel utilisateur Ansible doit se connecter par SSH, ici nous serons root.
Voilà désormais un playbook très simple également qui ne fait qu’un simple ping, cela permet de vérifier si Ansible peut se connecter aux machines et exécuter un playbook.
- name: playbook ping
gather_facts: no
hosts: all
tasks:
- ping:
Le paramètre gather_facts est par défaut configuré sur yes. Le gather facts récupère des informations sur le système où le playbook s’exécute (système d’exploitation, environnement, versions de Python/Ansible, etc) qu’on peut ensuite utiliser dans le playbook ou afficher. Ici on ne souhaite faire qu’un ping pour vérifier qu’Ansible fonctionne bien, on peut désactiver le gather facts puisqu’on ne s’en sert pas.
Le paramètre hosts permet d’indiquer sur quels machines de l’inventory ce playbook doit être exécuté par défaut.
Le paramètre tasks liste chaque tâche à exécuter (avec le nom du module). Ici on utilise le module ansible.builtin.ping qu’on peut abréger en ping.
Pour exécuter ce playbook on utilise la commande ansible-playbook -i inventory.yml playbook.yml (en remplaçant bien entendu les noms des fichiers par ceux que vous avez).
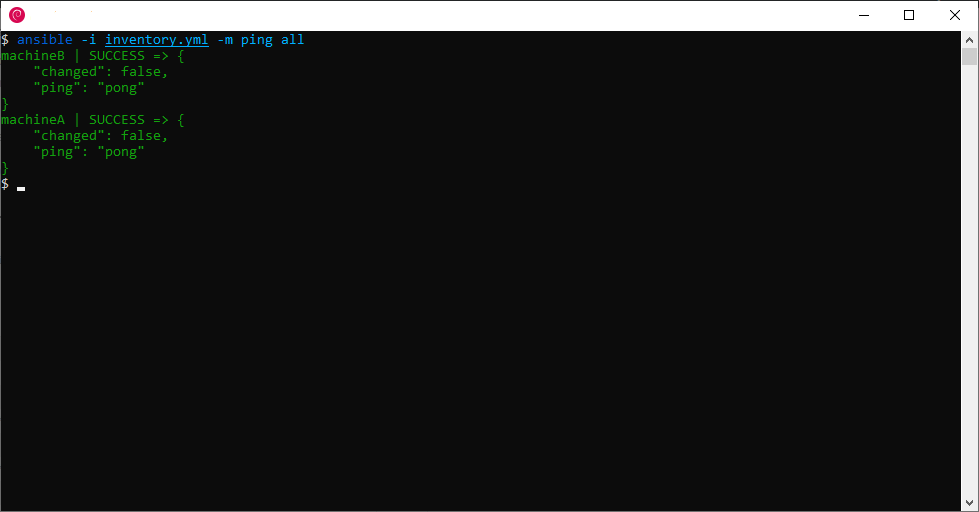
Voici le résultat qu’on obtient avec l’inventory et le playbook précédents :
Ansible nous rapporte que la tâche ping a réussi sur les deux machines. La partie PLAY RECAP résume les résultats de toutes les tâches.
L’équivalent de ce playbook en mode Ad Hoc est la commande :
$ ansible -i inventory.yml -m ping all
Le dernier paramètre all correspond au paramètre hosts du playbook, il indique d’exécuter la commande sur tous les hôtes présents dans l’inventory.
Le paramètre -m ping indique quel module utiliser (la documentation sur les commandes ad hoc est disponible ici).
Commande ad hoc de ping
Ansible for i
IBM fournit la collection power_ibmi qui contient beaucoup de modules pour interagir avec les IBM i, la documentation se trouve ici, et la référence des modules ici.
Cette collection est d’ailleurs disponible sur Github ici (avec plusieurs exemples et autres ressources).
Voici un exemple de playbook qui utilise cette collection, plus particulièrement le module ibmi_sysval. Ce playbook va récupérer une valeur système puis faire une assertion de sa valeur.
- hosts: all
gather_facts: no
collections:
- ibm.power_ibmi
tasks:
- name: Vérification CCSID
ibmi_sysval:
sysvalue:
- {'name': 'qccsid', 'expect': '1147'}
Le paramètre collections indique qu’il faut d’abord chercher le module ibmi_sysval dans les collections énumérées (dans l’ordre) mais cette partie est optionnelle (comme indiqué dans la documentation ici).
Puis on indique que l’élément nommé qccsid dans la variable de retour sysvalue doit correspondre à la valeur 1147.
Voilà le résultat qu’on obtient lorsque la valeur système correspond :
Et si le QCCSID ne correspond pas Ansible affiche une erreur à la place de ok: [machine], au format JSON :
fatal: [machineA]: FAILED! =>
{
"changed": false,
"fail_list": [{
"check": "equal",
"compliant": false,
"expect": "1147",
"msg": "Compliant check failed",
"name": "QCCSID",
"rc": -2,
"type": "10i0",
"value": "65535"
}],
"message": "",
"msg": "non-zero return code when get system value:-2",
"rc": -2,
"stderr": "non-zero return code when get system value:-2",
"stderr_lines": ["non-zero return code when get system value:-2"],
"sysval": []
}
Note: Dans le terminal cette erreur est souvent affichée sans indentation ni retours à la ligne.
Ici on peut voir que l’assertion a échoué, la valeur système était 65535, mais le playbook s’attendait à ce qu’elle soit 1147.
Il y a de nombreux autres cas d’usage, plusieurs exemples sont disponibles sur le dépôt Github ansible-for-i.
Il y a quelques exemples pour des utilisations spécifiques ici, et d’autres exemples de playbooks ici.
Interfaces graphiques : AWX et Tower
Ansible est un outil qui s’utilise dans le terminal, mais il existe deux solutions qui fournissent une interface graphique plus intuitive en plus d’autres fonctionnalités (planification de tâches, gestion de plusieurs utilisateurs et de leurs droits, notifications).
Ces deux solutions sont AWX et Tower, les deux sont très similaires : AWX est un projet open-source (disponible ici), et Tower (disponible ici) est une solution qui est basée sur AWX mais qui nécessite une licence.
La principale différence entre les deux est que Tower subit beaucoup plus de tests pour être plus stable et vous pouvez recevoir de l’aide du support technique Red Hat si besoin. AWX en revanche est moins testé et donc plus susceptible de rencontrer des instabilités, il n’y a également pas de support technique pour AWX.
Si la stabilité est une nécessité (comme en environnement de production) mieux vaut s’orienter vers Tower.
AWX est compatible sur Linux (les distributions les plus populaires devraient toutes le faire fonctionner), Tower est également compatible sur Linux mais est beaucoup restreint. Actuellement ce dernier n’est compatible que sur Red Hat Enterprise Linux (RHEL), CentOS et Ubuntu.
Nous avons testé AWX sur Debian (Bullseye), l’installation peut être assez compliquée lorsqu’on découvre AWX et son environnement mais son utilisation est plutôt intuitive.
L’interface et le fonctionnement de Tower sont quasiment identiques à AWX.
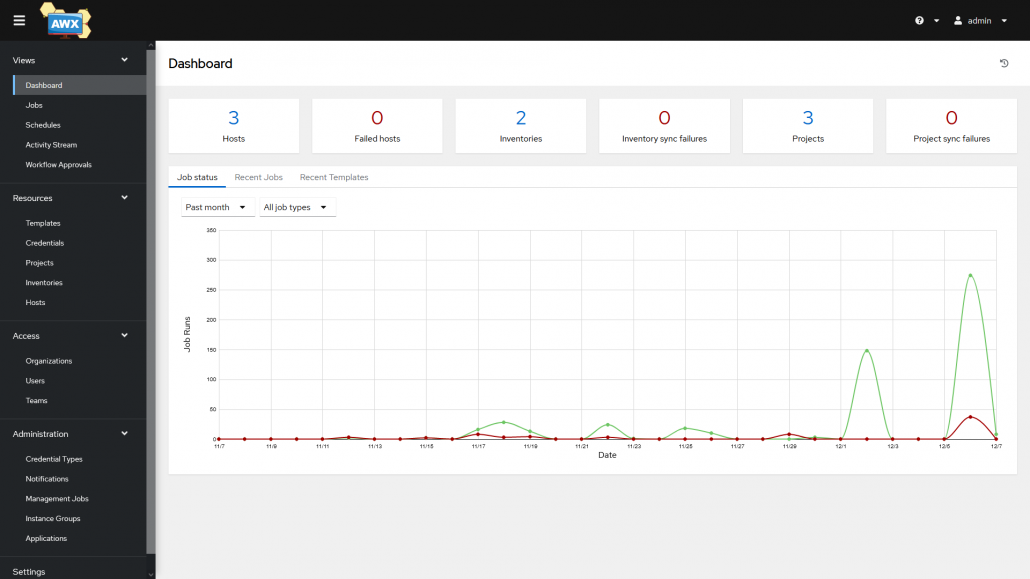
Dashboard AWX
Il y a plusieurs différences dans la manière d’utiliser Ansible dans le terminal et depuis AWX.
La configuration des machines, de leurs identifiants et des inventory est similaire et très facile. En revanche pour les playbooks ce n’est pas la même méthode.
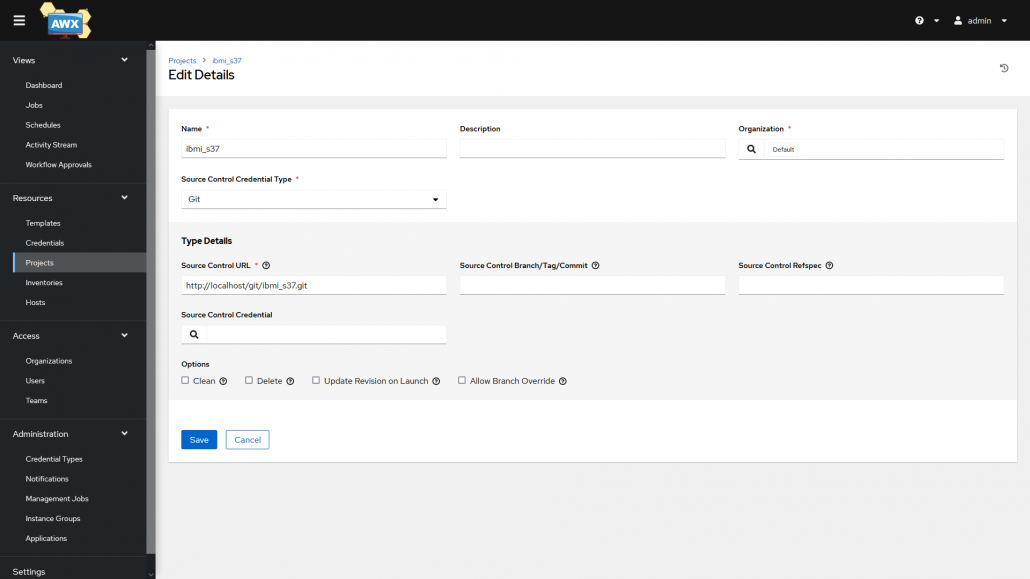
Premièrement on doit configurer un projet. Un projet est un groupe d’un ou plusieurs playbooks sous la forme d’un dépôt Git ou d’une archive.
Paramètres d’un projet
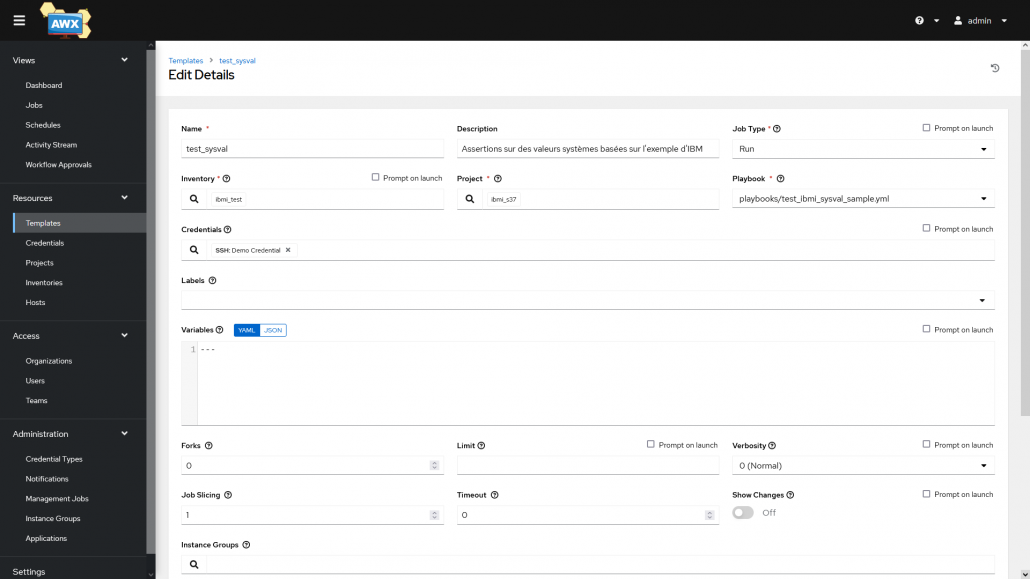
Ensuite il faut créer des templates, une template peut être considérée comme la commande pour exécuter un playbook : on choisit quel playbook exécuter depuis un projet, on choisit sur quel inventory l’exécuter et les identifiants à utiliser pour les connexions SSH sur les machines de l’inventory.
Paramètres d’une template
On peut ensuite exécuter les templates et suivre leurs avancements et résultats dans l’onglet Jobs ou depuis la page de la template.
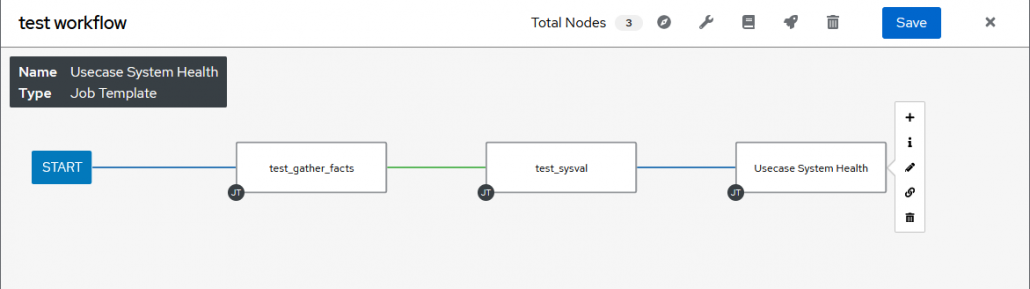
Dans l’onglet des templates on peut aussi créer des workflows, un workflow permet d’exécuter plusieurs templates à la suite en y ajoutant des conditions.
On peut choisir d’exécuter certaines templates si une autre réussit, et d’autres si elle échoue.
Éditeur des workflows
Ressources et liens utiles pour apprendre Ansible
Cette courte présentation vise à vous faire découvrir Ansible et ne couvre donc que les bases (beaucoup de détails ont été omis pour éviter la surcharge d’informations). Ansible est un outil très complet et il existe de nombreuses ressources pour apprendre à le prendre en main et le maîtriser.
Ansible est un outil très puissant aux applications nombreuses, et peut notamment faciliter l’administration des IBM i (surtout à grande échelle). Malheureusement il n’existe à l’heure actuelle aucune solution clé en main, apprendre à utiliser Ansible et créer ses propres playbooks est indispensable.
Cet apprentissage peut prendre du temps sans expérience préalable avec les environnements Unix et/ou Python. Mais si Ansible peut paraître difficile à prendre en main et maîtriser, des solutions plus guidées et faciles d’accès pourraient arriver à l’avenir, permettant à tous d’utiliser Ansible à son plein potentiel sans avoir à le maîtriser chaque aspect.
/wp-content/uploads/2017/05/logogaia.png00Sébastien C/wp-content/uploads/2017/05/logogaia.pngSébastien C2021-12-09 16:09:482021-12-09 16:09:50Ansible et IBM i
Vous devez indiquer l’utilisateur local qui servira à faire la requête d’écriture.
Pour voir les postes existants, vous avez une vue SQL
SELECT * FROM QSYS2.DRDA_AUTHENTICATION_ENTRY_INFO
le service DDM doit être démarré
STRTCPSVR *DDM
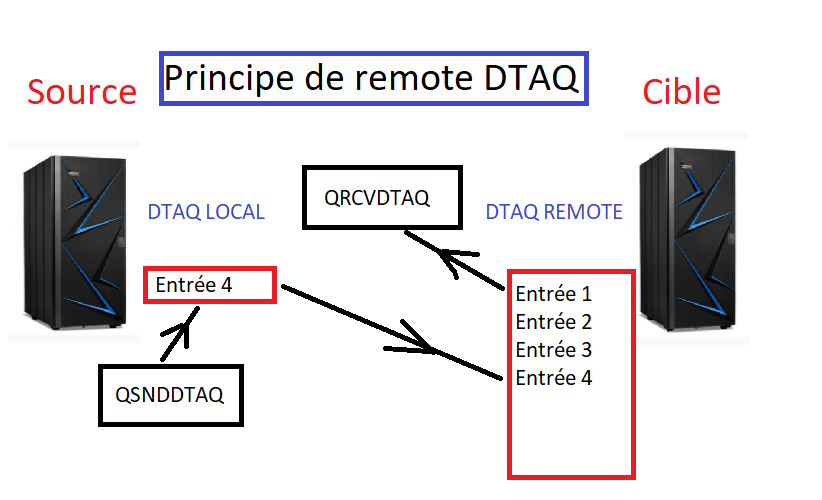
Pour écrire dans votre DTAQ
Sur la source, vous devez écrire des postes à la demande
Par L’API
Call QSNDDTAQ
Par la procédure SQL service, depuis le niveau 4 de la TR en 7.4
QSYS2.SEND_DATA_QUEUE()
sur la cible,
Pour écrire lire votre DTAQ
Vous devez avoir un traitement qui boucle pour traiter vos entrées
par l’API
Call QRCVDTAQ
Par la fonction SQL service, depuis le niveau 4 de la TR en 7.4
QSYS2.RECEIVE_DATA_QUEUE()
Conclusions
Vous pouvez mettre en place une solution de remote outq, pour répliquer des changement de mots passe par exemple !
Si vous utilisez des DTAQ, vous aurez besoin d’une commande pour visualiser le contenu de celle ci, vous pouvez en trouver un ici c’est la commande DSPDTAQ
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-12-04 20:10:212022-04-12 10:02:39Afficher un panel de groupe