

Vous avez sans doute un grand nombre de jobqs sur votre système, mais connaissez-vous réellement celles qui servent ?
Pour connaitre la liste des jobq utilisées, on va consulter les messages CPF11224 qui indiquent le début d’un travail et qui contiennent dans les données la jobq par laquellle ils sont arrivés
J’ai utilisé dans mon exemple de table dans qtemp, vous pouvez utiliser un with si vous préférez
Liste des jobqs utilisées
create table qtemp/lstjobqus as(
select distinct
cast(substr(message_tokens, 59, 10) as char(10)) as jobq,
cast(substr(message_tokens, 69, 10) as char(10)) as jobq_lib
FROM TABLE(qsys2.history_log_info(START_TIME => CURRENT TIMESTAMP –
30 days , END_TIME => CURRENT TIMESTAMP)) x
where message_id = ‘CPF1124’ ) with data
Liste des jobqs présentes sur le système
create table qtemp/lstjobq as (
SELECT OBJNAME as jobq, OBJLIB as jobq_lib
FROM TABLE(QSYS2.OBJECT_STATISTICS(‘ALL’, ‘JOBQ’)) ) with data
Liste des jobqs non utilisées
select a.jobq, a.jobq_lib from lstjobq as a exception join
lstjobqus as b on
a.jobq= b.jobq and a.jobq_lib = b.jobq_lib
remarque :
Avec cette liste vous pouvez faire du ménage et ne plus démarrer les sous-systèmes inutiles par exemple.
Supposons que vous utilisiez le job scheduler de l’IBMi, (WRKJOBSCDE), si vous utilisez AJS seul le fichier de départ change mais la démarche reste la même.
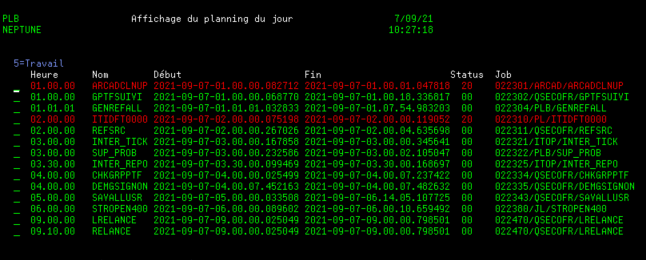
Notre méthode ne marche que pour le jour courant.
On va utiliser la date de prochaine soumission égale à la date du jour dans notre fichier SCHEDULED_JOB qui contient les jobs planifiés .
Vous devez planifier un job tous les matins à 0h et 2 minutes dans la file d’attente QCTL pour être sûr de le faire passer
Ce job aura une requête de ce type qui créera une table plandujour
create table plandujour as (
Select SCHEDULED_JOB_NAME, SCHEDULED_TIME,
ifnull(DESCRIPTION, » ») as description
from QSYS2.SCHEDULED_JOB_INFO
where NEXT_SUBMISSION_DATE = current date and
substr(SCHEDULED_JOB_NAME, 1, 1) <> »Q »
and status <> »HELD »
order by SCHEDULED_TIME ) with data +
Vous avez ainsi tous les jobs prévus pour la journée par heure de planification.
Maintenant nous allons voir comment suivre le déroulement des ces travaux
Pour suivre vos travaux on va utiliser la fonction table suivante HISTORY_LOG_INFO
exemple pour avoir les jobs du jour
SELECT * FROM TABLE(QSYS2.HISTORY_LOG_INFO(CURRENT DATE)) X
Chaque job qui tourne sur le système va générer au moins 2 messages
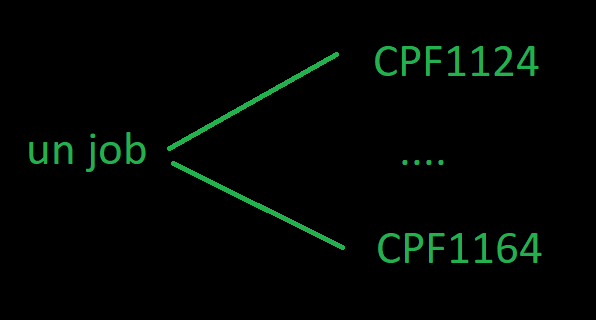
un CPF1124 Travail …/…/… démarré le
un CPF1164 Travail …/…/… arrêté le
donc
si votre travail n’a pas tourné vous n’avez aucun message
si votre travail tourne vous avez un CPF1124
si votre travail est terminé vous avez un CPF1164
Vous pouvez déjà suivre l’avancement grâce à la zone MESSAGE_TIMESTAMP et avoir une durée entre les 2 messages
Remarque :
pour savoir si votre travail c’est terminé normalement c’est un peu plus compliqué, vous devrez analyser le code fin par exemple dans la zone MESSAGE_TEXT.
code fin 0 indiquant une fin normale du traitement
Un exemple de requête (à améliorer)
pour les codes fin , pour les jobs qui débordent de la journée etc…
WITH logdujour (mgr_id, mgr_name, mgr_dept) AS(
SELECT * FROM TABLE(QSYS2.HISTORY_LOG_INFO(CURRENT DATE)) X)
select
a.SCHEDULED_JOB_NAME as nom_travail,
a.SCHEDULED_TIME as
HEURE_prev ,
ifnull(b.MESSAGE_TIMESTAMP, »1911-11-11-00.00.00.00000 ») as Heure_debut ,
ifnull(c.MESSAGE_TIMESTAMP, »1911-11-11-00.00.00.00000 ») as heure_fin,
ifnull(c.SEVERITY, »99 ») as code_sev ,
ifnull(b.FROM_JOB, » ») as name_JOB
from plandujour a
Left outer join logdujour b
on B.MESSAGE_ID = »CPF1124 » and B.FROM_JOB like( »% » concat
A.SCHEDULED_JOB_NAME concat »% »)
Left outer join logdujour c
on C.MESSAGE_ID = »CPF1164 » and C.FROM_JOB like( »% » concat
A.SCHEDULED_JOB_NAME concat »% »)
Vous pouvez planifier un job chaque soir qui vous envoie un récapitulatif de la journée, ou que les jobs en erreur par exemple.
Vous pouvez historiser ces données si vous avez besoin de consolider un suivi, etc …
Exemple d’un outil packagé utilisé dans notre centre de service pour suivre le planning quotidien:
https://github.com/Plberthoin/PLB/tree/master/DSPPLNPRD
Pour les noms des objets collection, table, index, view, etc … le système maintient en double un nom SQL et un nom IBM i
Exemple :
SQL / bd_des_articles et IBMi / BD_DE00001
la règle est la suivante pour les noms supérieurs à 10 caractères le système prends les 5 premières positions et incrémente un compteur sur 5 positions, ce qui n’est pas forcément très lisible.
pour éviter ça, il est conseillé d’indiquer les 2 au moment de la création de votre objet SQL
Bien sur vous ne pourrez pas avoir des doublons ni sur le nom long ni sur le nom court
Voici quelques conseils
Par un create schema par exemple
vous indiquez le nom SQL et vous pouvez forcer un nom court par la clause FOR SCHEMA nomcourt
exemple
CREATE SCHEMA BASE_DE_DONNEES_ARTICLES FOR SCHEMA DBARTICLE
create table
vous indiquez le nom SQL et vous pouvez définir un nom court par la clause SYSTEM NAME nomcourt
il est conseillé pour les mêmes raisons de mettre sur un nom court, un nom long par la clause FOR nomcourt
EXEMPLE
CREATE TABLE DBARTICLE.Fichier_ARTICLES FOR SYSTEM NAME ARTICLES (
NUMERO_ARTICLE FOR COLUMN NUMART DEC ( 6) NOT NULL WITH DEFAULT,
NOMCLI_ARTICLE FOR COLUMN NOMART CHAR ( 30) NOT NULL WITH DEFAULT)
vous pouvez utiliser indifféremment les 2 syntaxes
select
NUMART ,
NOMART
from DBARTICLE.Fichier_ARTICLES
ou
select
NUMERO_ARTICLE ,
NOMART
from DBARTICLE.ARTICLES
pour la plupart des autres objets vous pouvez indiquer la clause FOR SYSTEM NAME nomcourt
CREATE INDEX nomlong FOR SYSTEM NAME nomcourt
ON bd (long ou court)/ table (nom court ou long)
(nom de zone court ou long)
Exemple
CREATE index DBARTICLE.key_articles_numcli FOR SYSTEM NAME key_numli
on DBARTICLE.ARTICLES
(NUMERO_ARTICLE)
CREATE VIEW … FOR SYSTEM NAME nomcourt ()
exemple
CREATE VIEW DBARTICLE.articles_nom_b FOR SYSTEM NAME articleb (
NUMERO_ARTICLE , NOMART )
as
(select
NUMERO_ARTICLE , NOMART
from DBARTICLE.ARTICLES
where NUMART like(‘B%’))
Vous pouvez créer une table en faisant un create table as
exemple
CREATE table DBARTICLE.articles_nom_c FOR SYSTEM NAME articlec as
(select
NUMERO_ARTICLE , NOMART
from DBARTICLE.ARTICLES
where NUMART like(‘B%’))
With data
Ce qui permet de récupérer les attributs des zones de la table
Vous pouvez renommer une zone
exemple
CREATE table DBARTICLE.articles_nom_cbis FOR SYSTEM NAME article1 as
(select
NUMERO_ARTICLE , NOMART as nom_article_bis
from DBARTICLE.ARTICLES
where NUMART like(‘B%’))
With data
Mais c’est une nouvelle zone et le nom court est conservé, bien sur sauf si c’est une zone de travail substr par exemple ….
Si vous souhaitez utiliser vos tables en RPG, vous pouvez préciser un nom de format, ce qui vous evitera un renommage dans le programme RPGLE
c’est en utilisant la clause RCDDFMT
CREATE TABLE nomdb.nomtable ( ) RCDFMT nomfmt
Exemple
CREATE TABLE DBARTICLE.Fichier_ARTICLES FOR SYSTEM NAME ARTICLES (
NUMERO_ARTICLE FOR COLUMN NUMART DEC ( 6) NOT NULL WITH DEFAULT,
NOMCLI_ARTICLE FOR COLUMN NOMART CHAR ( 30) NOT NULL WITH DEFAULT)
RCDFMT ARTICLEF
Pour connaitre les correspondances sur les objets existants, vous pouvez utiliser les vues SQL
pour les tables
SELECT TABLE_NAME, SYSTEM_TABLE_NAME FROM systables
where …
pour les index
SELECT INDEX_NAME, SYSTEM_INDEX_NAME FROM SYSINDEXES
where
pour les vues
SELECT TABLE_NAME, SYSTEM_VIEW_NAME FROM sysviews
where
oui la vue s’appelle TABLE_NAME ?????????? ça sent le copier coller …
on peut renommer des noms systèmes sur des objets SQL
Exemples
RENAME TABLE GDATA.LONG_NOM_TABLE TO SYSTEM NAME LONG_NOM
RENAME index GDATA.LONG_INDEX_ZONE1 TO SYSTEM NAME I_ZONE1
RENAME index GDATA.LONG_VIEW_ALL TO SYSTEM NAME LONG_VIEW
Particularité pour renommer une table
Nous créerons la table suivante
CREATE TABLE gdata/nom_long_table FOR SYSTEM NAME nom_court (
NUMERO_ARTICLE FOR COLUMN NUMART DEC ( 6) NOT NULL WITH DEFAULT,
NOMCLI_ARTICLE FOR COLUMN NOMART CHAR ( 30) NOT NULL WITH DEFAULT)
rappel
Une table a un nom long et un nom court qui doivent être unique
on essaye de dupliquer la table dans la même bibliothèque
CRTDUPOBJ OBJ(NOM_COURT)
FROMLIB(GDATA)
OBJTYPE(FILE) TOLIB(GDATA) NEWOBJ(NOM_COURT2) DATA(YES)
duplication impossible dans la même bibliothèque, le probléme étant sur le nom long qui est dupliqué
Le message est le suivant
Le nom de remplacement attribué au fichier NOM_COURT2 n’est pas admis.
Pour dupliquer votre table vous devez donc passez par SQL
create table gdata/nom_long_table2 like gdata/nom_long_table
vous obtenez bien une 2éme table qui se nomme nom_long_table2
Mais le nom ibmi est fixé par le système ici NOM_L00001
est si vous voulez le renommer vous pouvez le faire par RNMOBJ
RNMOBJ OBJ(GDATA/NOM_L00001) OBJTYPE(*FILE) NEWOBJ(NOM_COURT2)
Vous avez nom long nom_long_table2
Vous avez nom court nom_court2
Vous devez bien faire les 2 opérations
Si vous voulez juste sauvegarder les données
Préférer un create table as en SQL ou un cpyf crtfile(*YES) en IBMI
On a souvent du mal a régler ODBC voici quelques points qui peuvent vous aider dans cette tache.
L’apport de la procédure SET_SERVER_SBS_ROUTING qui permet de router des jobs ODBC, par adresses IP ou utilisateurs à considérablement changer la donne.
Gestion par utilisateur
call qsys2.SET_SERVER_SBS_ROUTING(‘PLB’, ‘QZDASOINIT’ , ‘ODBC’)
pour activer la redirection
call qsys2.SET_SERVER_SBS_ROUTING(‘PLB’, ‘QZDASOINIT’ , NULL);
pour supprimer cette redirection
SELECT * FROM QSYS2.SERVER_SBS_ROUTING
Pour les redirections existantes par nom user
Gestion par adresse IP
Pour activer
CALL QSYS2.SET_SERVER_SBS_ROUTING(AUTHORIZATION_NAME => ‘*ALL’,
SERVER_NAME => ‘QZDASOINIT’,
IP_ADDRESS_START => ‘192.168.1.10’,
IP_ADDRESS_END => ‘192.168.1.30’,
SUBSYSTEM_NAME => ‘ODBC’)
Pour supprimer cette redirection
CALL QSYS2.SET_SERVER_SBS_ROUTING(AUTHORIZATION_NAME => ‘*ALL’,
SERVER_NAME => ‘QZDASOINIT’,
IP_ADDRESS_START => ‘192.168.1.10’,
IP_ADDRESS_END => ‘192.168.1.30’,
SUBSYSTEM_NAME => NULL);
pour voir les redirections existantes par adresses IP
SELECT * FROM QSYS2.SERVER_SBS_CONFIGURATION;
Voici quelques axes qui peuvent vous donner des idées
Ce qui permet une meilleur administration.
Vous pourrez router vos jobs par utilisateurs ou par adresse IP grâce à la procédure SQL SET_SERVER_SBS_ROUTING
CRTSBSD SBSD(VOTRESBS)
POOLS((1 *BASE))
TEXT(‘Sous-système pour job ODBC’)
vous pouvez indiquer le pool de base
un travail à démarrage automatique
ADDPJE SBSD(GODBC) PGM(QSYS/QZDASOINIT) INLJOBS(QZDASOINIT) JOBD(Qgpl/votrejobd) CLS(QSYS/votreclasse) user(votreuser)
et un poste de routage
ADDRTGE SBSD(VOTRESBS)
SEQNBR(9999)
CMPVAL(*ANY)
PGM(VOTREPGM)
CLS(VOTRECLASS)
Ce qui permettra de réinitialiser votre cache entre 2 benchmarks.
POOLS((1 *SHRPOOL7))
Ce qui permettra de régler les priorités d’exécution sur la commande RTGE.
la classe par défaut est la QPWFSERVER , dupliquez la et ajustez les paramètres que vous désirez par CHGCLS.
Par exemple, les priorités.
par exemple sur la commande ajout des travaux auto.
la jobd par défaut est la QDFTSVR , dupliquez la et ajustez les paramètres que vous désirez par CHGJOBD.
Par exemple le niveau de log.
Pour par exemple choisir le fichier QAQQINI pour les réglages SQL.
Le programme par défaut est QCMD , voici un exemple.
Par exemple, changer le fichier QAQQINI
PGM
CHGQRYA QRYOPTLIB(&LIB)
SNDPGMMSG MSGID(CPF9898) MSGF(QCPFMSG) MSGDTA(‘Vous +
utilisez désormais QAQQINI de la +
bibliothèque, ‘ BCAT &LIB) MSGTYPE(STATUS)
ENDPM
Ici on traite pas de la traçabilité, il est important de voir qui peut faire de l’ODBC sur votre système.
Nous avons un logiciel GODBC qui peut vous aider dans cette tache ici : https://www.gaia.fr/produits/
Vous pouvez désormais accéder aux fichiers des messages par SQL grâce à la vue SQL QSYS2.MESSAGE_FILE_DATA.
Vos menus personnalisés utilisent des commandes qui sont stockés dans des fichiers messages.
Voici une idée pour améliorer vos menus : prendre la commande à exécuter et l’afficher, vous pouvez customizer l’affichage du texte
J’ai publié le code sur github l’adresse suivante : https://github.com/Plberthoin/PLB/tree/master/GTOOLS
Vous devez récupérer, un DDS , un SQLRPGLE et une CMD.
Voila qui peut vous donner des idées pour la gestion de vos fichiers messages

Pour mettre en place une authentification par JWT sur IBMi, on utilise l’API Qc3VerifySignature.
Il est composé de trois partie :
Pour obtenir la signature, il faut tout d’abord encoder séparément le header et le payload avec BaseURL64, ensuite, on les concatène en les séparant d’un point.
On calcule enfin une signature d’après le header et le payload afin de garantir que le jeton n’a pas été modifié, d’après l’algorithme défini dans le header (RS256, HS256, HS512, …). Cette signature binaire est elle-même encodée ensuite en Base64URL.
On obtient ainsi le JWT : { header }.{ payload }.{ signature }
Afin de tester cette API, il faut dans un premier temps générer une clé au format PEM en suivant les étapes ci-dessous :
Pour créer une demande certificate (.csr = certificat signing request)
Cela crée deux fichiers : monserveur.csr et privkey.pem
Cela crée le fichier monserveur.key (clé privée sans le mot de passe)
Cela crée le fichier monserveur.cert, qui est le certificat.
La signature est fournie en BASE64, il faut la convertir en binaire pour la fournir à l’API
La longueur de la signature fournie après sa conversion
{ header }.{ payload } en ASCII
C’ ‘est une Data Structure qui contient les paramètres de l’algorithme.
C’ ‘est une Data Structure qui contient les paramètres de la clé.
C’est une Data Structure qui indique le code retour de l’exécution
Pour mettre en place l’appel à Qc3VerifySignature, nous avons défini les formats suivants :
On crée la donnée à contrôler en concaténant header et payload, séparés d’un point, comme expliqué au paragraphe précédent.
Exemple :

ATTENTION : Il faut, pour être utilisable, que celle-ci soit en ASCII. Pour ce faire on utilise le programme système QDCXLATE qui permet de faire de la conversion de chaines de caractères grâce à des tables système.
cipher INT(10) inz(50) // Code secret pour RSA , initialisé à 50
PKA CHAR(1) inz(1) // PKCS bloc 01
filler CHAR(3) inz(x’000000’) // Réservé : ce champ doit rester NULL
hash INT(10) inz(3) // Signature Algorithme de Hash 3=SHA256
keylen INT(10) // Longueur du certificat PEM
filler CHAR(4) inz(x’00000000′) // Réservé : ce champ doit rester NULL
key CHAR(4096) CCSID(65535) // Certificat PEM en ASCII
L’appel de l’API avec les paramètres choisis , retourne un Data Structure ErrorCode décrite ci-dessous :
bytesProv INT(10) inz( %size( ErrorCode ) ); // ou 64 pour voir MSGID
bytesAvail INT(10) inz(0);
MSGID CHAR(7);
filler CHAR (1);
data CHAR (48);
Dans le cas où la signature est vérifiée, les valeurs retour sont les suivantes
Si la signature n’est pas vérifiée, les valeurs retour seront :
Téléchargement de PTF par FTP
Depuis mi-juillet 2021, ce n’est plus un choix le mode FTP simple en anonymous ne fonctionne plus, vous le voyez quand vous allez sur fix central le mode ftps ou sftp est par défaut .
Quand vous faites votre demande vous recevez désormais 3 mails au lieu de 2
– Le premier, pour vous dire que votre demande a été prise en compte.
– Le deuxième, pour vous indiquer les instructions à passer pour votre téléchargement
– Le Troisième (nouveau) qui contiendra le mot de passe que vous devrez utiliser
Comment faire désormais pour télécharger ces PTFs, on va voir 2 méthodes ?
Le logiciel connait le certificat racine Digicert, donc si vous vous connectez en SSL sur le site delivery01-bld.dhe.ibm.com, il vous propose la première fois de télécharger le certificat.
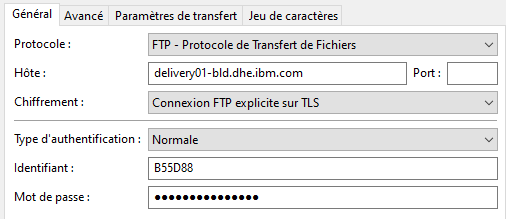
Et vous pouvez faire ensuite votre téléchargement .
Il va vous falloir installer le certificat racine Digicert et le certificat du site dans DCM qui gère les certificats du coté IBMi.
Il est conseillé pour faire ses installations d’utiliser le logiciel QMGTOOLS.
Nous vous conseillons également de le mettre à jour pour éviter les problèmes.
ADDLIBLE LIB(QMGTOOLS)
GO MENU(MG)
Vous pouvez donc maintenant faire vos installations
Le certificat racine est disponible ici
https://www.ibm.com/support/pages/node/1077897
Vous devez dezipper vos fichiers et les copier dans l’IFS de votre IBMi par exemple /temp
Vous allez utilisez la première commande suivante
GETSSL pour le certifcicat racine
détail ici
https://www.ibm.com/support/pages/node/683901
et pour installer le certificat vous allez à nouveau utiliser la commande GETSSL avec le paramétrage suivant
QMGTOOLS/GETSSL IP(WWW.ECUREP.IBM.COM)
PORT(443)
AUTOIMP(Y)
STOREPWD(‘votre mot de passe’)
Si vous allez dans DCM vous avez un nouveau certificat installé QMG0001
Vous pouvez désormais vous connecter au site avec la commande suivante
FTP RMTSYS(‘delivery01-bld.dhe.ibm.com’) SECCNN(*SSL)
Attention cependant vous devrez forcer le mode par la commande FTP SENDEPRT
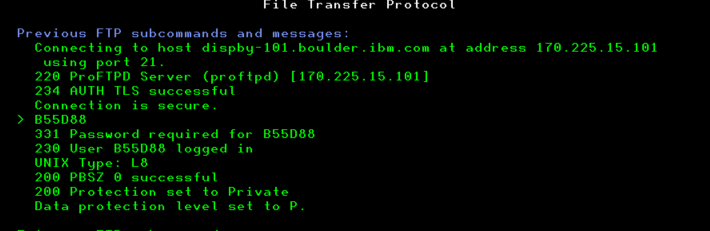
Voila, une fois que vous avez paramétré vous pouvez utiliser télécharger vos PTFs comme avant.
Comment voir à un instant donné, les requêtes les plus consommatrices de votre système ?
Vous êtes sans doute demandé comment connaitre les requêtes SQL qui consomment sur votre système, voici une solution.
Nous allons utiliser un dump du plan cache , vous pouvez aussi y accéder par ACS en quelques clics.
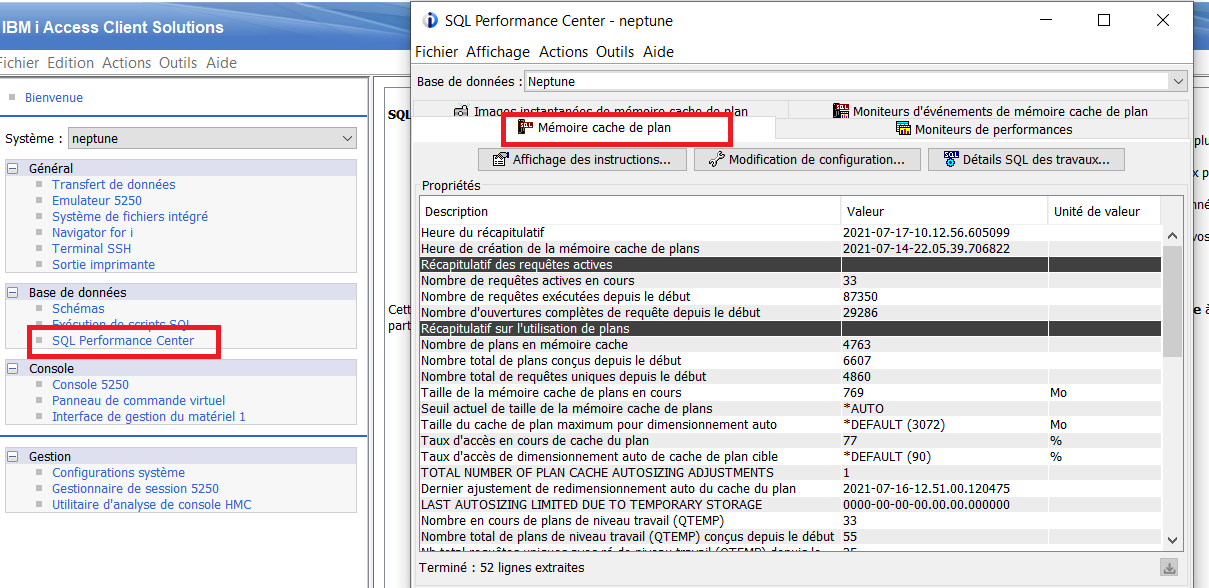
Voici une méthode qui va vous permettre d’automatiser et de trouver plus rapidement un problème.
Commencer par supprimer le fichier qui va servir à extraire le dump
Drop table gdata.dump_cache ;
Extrayez le cache dump dans votre fichier de travail
CALL QSYS2.DUMP_PLAN_CACHE (fileschema => ‘GDATA’, Filename => ‘DUMP_CACHE’) ;
Exécuter une requête sur ce fichier
Dans notre exemple, on sélectionne les jobs actifs sur le système, on sélectionne les requêtes SELECT et on trie par consommation descendante !
With job_act (JOB_NAME_SHORT, JOB_USER, JOB_NUMBER, JOB_USER_IDENTITY)
as (SELECT JOB_NAME_SHORT, JOB_USER, JOB_NUMBER,JOB_USER_IDENTITY
FROM TABLE (QSYS2.ACTIVE_JOB_INFO(DETAILED_INFO => ‘ALL’)) X
where substr(job_user_identity, 1, 1) <> ‘Q’)
Select qqjob, qquser, qvc102, qqjnum, qq1000, qqi6 as temps_execution
from gdata.dump_cache a join job_act b on
QQJOB = JOB_NAME_SHORT and QQUSER = JOB_USER and QQJNUM = JOB_NUMBER
where substr(QQ1000 , 1, 6) = ‘SELECT’
order by qqi6 desc
Vous pouvez changer vos critères de tri et de sélection, ici on est en mode pompier ?
Vous pouvez planifier cette requête et la faire tourner plusieurs fois par jour sur votre système en gardant le résultat ou les dump cache.
Nous avons packagé ce script pour faire une commande WRKSQLJOB que vous pouvez trouver ici !
https://github.com/Plberthoin/PLB/tree/master/GTOOLS

Vous retrouvez également une version un peu plus évoluée dans notre produit GODBC
https://www.gaia.fr/produits/
Les sites à connaitre, si vous voulez aller plus loin :
https://www.ibm.com/docs/en/i/7.4?topic=services-dump-plan-cache-procedure
https://www.ibm.com/docs/en/i/7.4?topic=cache-creating-snapshots
https://www.ibm.com/docs/api/v1/content/ssw_ibm_i_74/pdf/rzajqpdf.pdf
Vous utilisez la solution de single signon sur IBMi à base de kerberos et EIM
Votre serveur LDAP change de nom
Voici la liste des opérations à effectuer
Sur le serveur LDAP, vous n’avez rien à faire
Sur le serveur Kerberos
Vous avez 2 modifications à faire
Changer le nom du KDC sur l’onglet principal
Changer le nom du serveur de mot de passe sur l’onglet Serveur de mot de passe
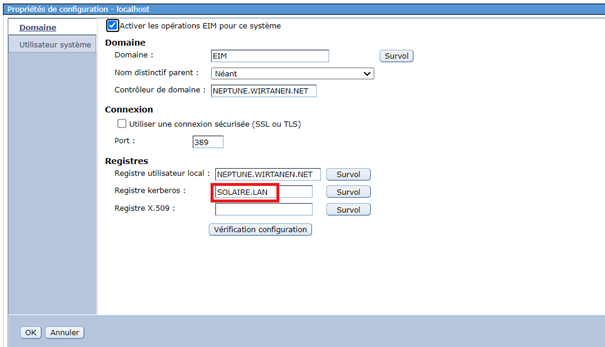
Sur le serveur EIM
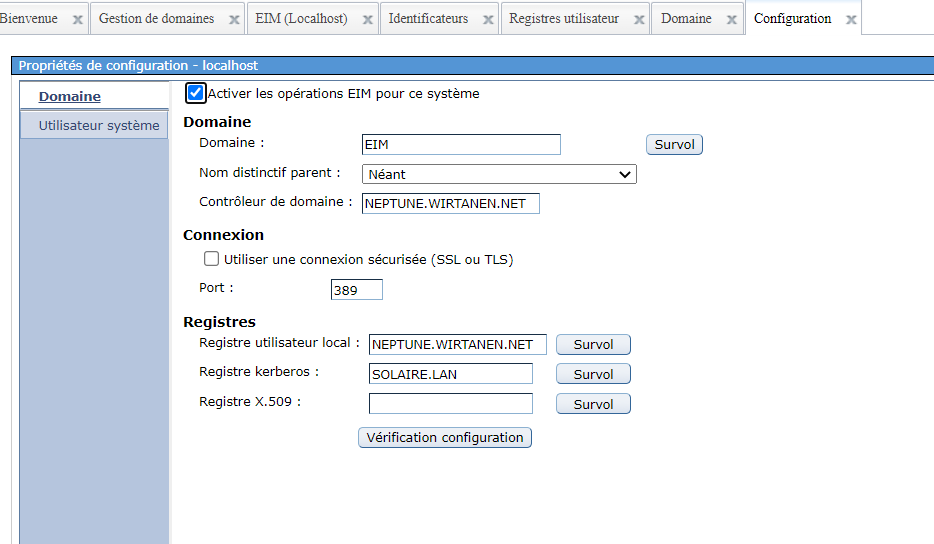
Sur le domaine changer le registre kerberos
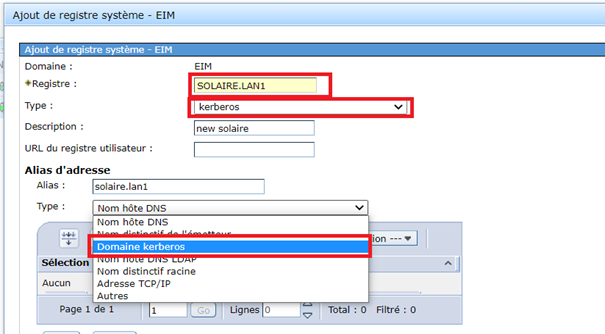
Créer un nouveau registre utilisateurs de type source kerberos
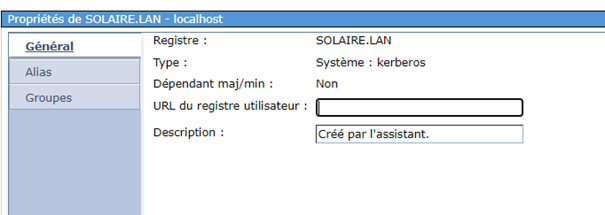
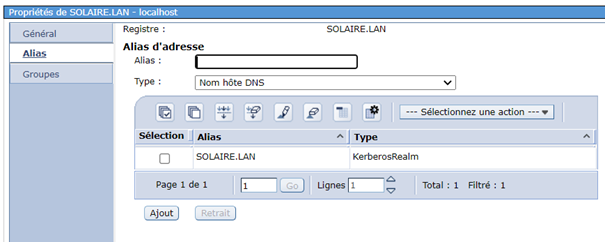
et vous devrez ensuite sur chaque inscription remplacer votre source par le nouveau serveur
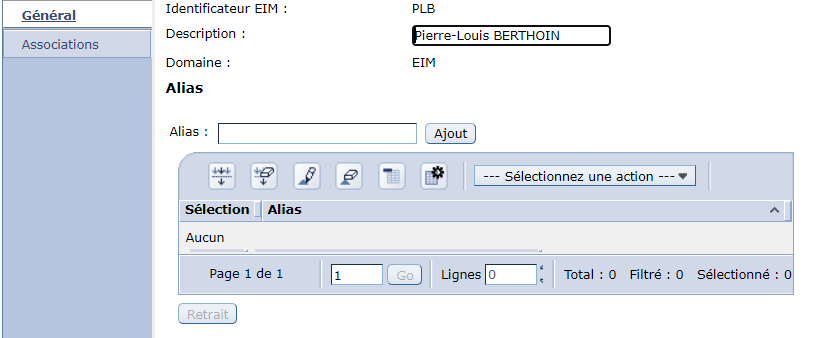
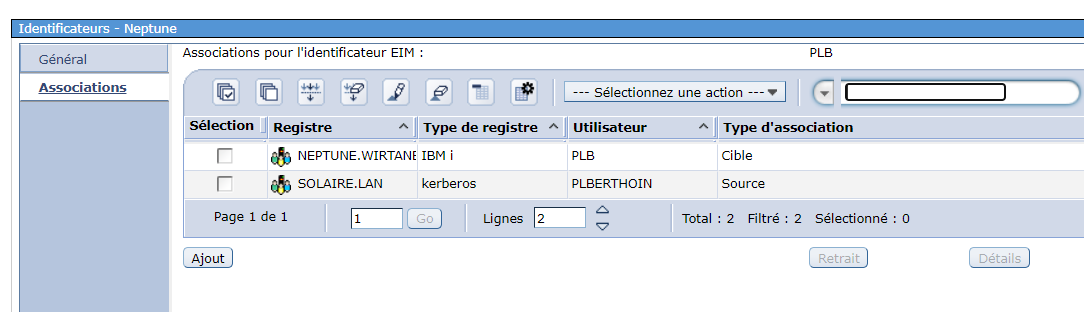
Ca peut être long si vous n’avez pas d’outils pour le faire
Notre produit GEIM peut vous aider dans cette tache !