On entend beaucoup de choses, je vais essayer de vous clarifier un peu les choses
Les directives /COPY et /INCLUDE sont identiques sauf qu’elles sont gérées différemment par le précompilateur SQL, en gros si vous codez avec un Source en SQLRPGLE.
Sur la commande CRTSQLRPGI vous avez le paramètre RPGPPOPT Permet d’indiquer si le compilateur ILE RPG va être appelé pour prétraiter le membre source avant lancement de la précompilation SQL. Cette étape sur le membre source SQL permet de traiter certaines instructions de compilation avant la précompilation SQL. Le source prétraité est placé dans le fichier QSQLPRE de la bibliothèque QTEMP. Il servira à la précompilation SQL. puis à la complilation RPGLE
3 valeurs possibles sont : *NONE Le compilateur n’est pas appelé pour le prétraitement. *LVL1 Le compilateur est appelé pour le prétraitement afin de développer /COPY et traiter les instructions de compilation conditionnelles à l’exception de /INCLUDE. *LVL2 Le compilateur est appelé pour le prétraitement afin de développer /COPY et /INCLUDE et traiter les instructions de compilation conditionnelles
voici un exemple Un module utilise la description d’un fichier qui est dans un include
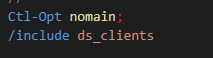
le source à inclure
sa déclaration dans le programme ou le module
.
Compile avec *NONE
Compile avec *LVL2
Remarque Si vous faites du SQLRPGLE, ce qui est fortement recommandé à ce jour forcer cette valeur *LVL2 comme ca pas de doute !
Il existe de nombreuses méthodes pour convertir du code RPGLE colonné vers du RPG FREE.
La plupart des conversions se passent sans problème, mais on constate que le code RPG ou RPG IV colonné pouvait être plus permissif et permettre des choses que le FREE ne tolère pas.
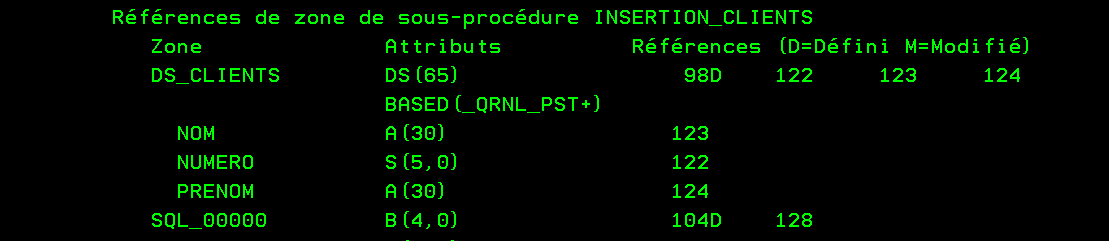
Voici un exemple qu’on a rencontré récemment, on est d’accord il résulte d’une incohérence dans le développement initial, mais jusque la ça passait à l’exécution.
En RPGIV colonné
c z-add 9999999 zone7 7 0 c z-add zone7 zone5 5 0 c eval *inlr = *on
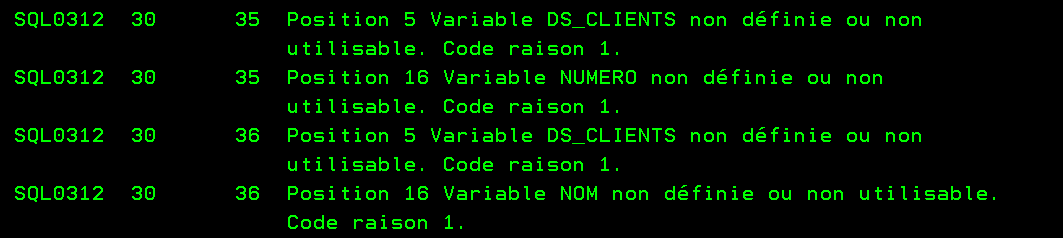
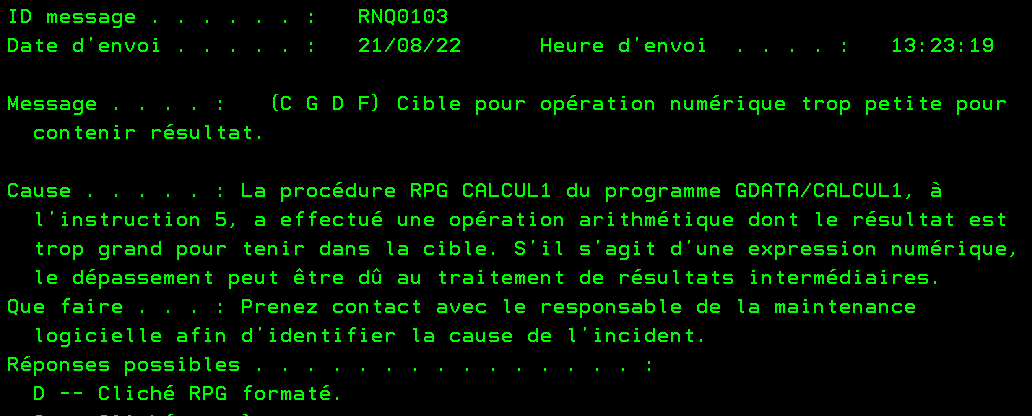
Quand vous exécutez ce code, il n’y a pas d’erreur, on est d’accord le résultat est faux …
Quand vous exécutez ce code, il y a un plantage, ce qui est normal
Conclusion
On peut donc tomber sur quelques cas que le RPG III ou IV acceptait mais que le nouveau code ne permet plus. C’est bien sûr du code de mauvaise qualité, et la réécriture peut s’avérer nécessaire surtout si on rencontre des instructions déstructurantes comme des GOTO par exemple.
Bien que le MD5 ne soit plus utilisé pour l’encryption, il est toujours utilisé pour valider l’authenticité et la conformité des fichiers.
Qu’est-ce qu’un MD5
Un md5 est une chaine de 16 caractères composée de symboles hexadécimaux. Il s’agit en réalité du nom de l’algorithme utilisé pour générer la chaine.
Comme indiqué précédemment son usage est le contrôle d’intégrité des fichier, par exemple lors du partage d’un fichier, on peut mettre à disposition le MD5 afin de contrôler que le téléchargement du fichier s’est bien passé ou que le fichier n’a pas été modifié entre temps.
Pour la suite nous aurons besoin d’un fichier, par simplicité j’utiliserai un simple .txt qui contient la phrase « This is not a test! » présent dans mon répertoire de l’ifs.
Fichier dans l’ifs
/home/jl/file.txt
Contenu du fichier
This is not a test!
md5
EDA20FB86FE23401A5671734E4E55A12
QSH – md5sum
La première méthode pour générer le MD5 d’un fichier est d’utiliser la commande unix md5sum via QSH :
La fonction retourne le hash et le chemin du fichier.
RPGLE – _cipher
Il est également possible de générer le MD5 via RPG en exploitant la procédure externe cipher. Je ne m’épancherai pas sur son implémentation complète ici, car bien plus complexe que les deux autres méthodes présentées. De plus, passer par cette méthode, n’est plus le sens de l’histoire.
// Déclaration de la procédure
dcl-pr cipher extproc('_cipher');
*n pointer value;
*n pointer value;
*n pointer value;
end-pr;
// Appel de la procédure
cipher(%ADDR(receiver) : %ADDR(controls) : %ADDR(source));
En sql on retrouve la fonction hash_md5, qui retourne le hash d’une chaine de caractère passée en paramètre.
❗ Attention à l’encodage de votre chaine de caractères. ❗
Pour que le résultat soit cohérent entre différents systèmes il faut commencer par convertir la chaine de caractère en UTF-8 :
VALUES CAST('This is not a test!' AS VARCHAR(512) CCSID 1208); -- 1208 = UTF-8
-- Retour : This is not a test!
Le résultat est plutôt flagrant ! D’accord pas vraiment… Par contre si on regarde la valeur hexadécimale de la chaine avec et sans conversion :
VALUES HEX('This is not a test!');
-- Retour : E38889A24089A2409596A3408140A385A2A34F
VALUES HEX(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : 54686973206973206E6F742061207465737421
Le hachage se fait en hexadécimal, donc le résultat ne serait pas le même sans conversion préalable.
Il suffit maintenant de hacher notre chaine de caractères :
VALUES HASH_MD5(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : EDA20FB86FE23401A5671734E4E55A12
On obtient donc la même valeur que celle que l’on a obtenu précédemment (puisque que le contenu de notre fichier est strictement égale à cette chaine de caractère).
La dernière étape est de générer le MD5 directement à partir du fichier, pour cela il suffit d’utiliser la fonction GET_BLOB_FROM_FILE :
VALUES HASH_MD5(GET_BLOB_FROM_FILE('/home/jl/file.txt')) WITH CS;
-- Retour : EDA20FB86FE23401A5671734E4E55A12
Autres algorithmes de hash
Il existe d’autres algorithmes de hash qui permettent de hacher du texte et des fichiers. Trois autres algorithmes sont généralement disponibles :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2022-08-18 00:30:512022-08-18 12:51:20Utilisation du MD5 sur votre IBM i
Il existe de nombreuses tables dans QSYS qui constituent le catalogue DB2, Ces tables sont accessibles par des vues qui se trouvent dans QSYS2 de manière globale et dans les bibliothèques de vos collections SQL.
On utilise pas assez ces informations pour analyser la base de données, elles contiennent une multitude d’informations
On va faire une petit exemple:
Imaginons que nous voulons savoir ou est utilisée une zone
Nous fixerons la database par set schema , pour éviter les qualifications
exemple de manière globale SET SCHEMA QSYS2
On va utiliser une vue qui s’appelle SYSCOLUMNS qui contient les zones de votre database
SELECT A.SYSTEM_COLUMN_NAME, A.SYSTEM_TABLE_NAME, A.SYSTEM_TABLE_SCHEMA FROM SYSCOLUMNS A WHERE COLUMN_NAME = ‘NUMCLI’
Vous obtenez une liste de tous les fichiers (tables, vue, PF, LF) etc …
Imaginons ensuite que vous ne vouliez que les tables ou PF vous pouvez utiliser la vue SYSTABLES
SELECT a.SYSTEM_COLUMN_NAME, A.SYSTEM_TABLE_NAME, A.SYSTEM_TABLE_SCHEMA FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in(‘T’ , ‘P’) WHERE COLUMN_NAME = ‘NUMCLI’
Vous limitez ainsi votre recherche aux tables et PF
Imaginons maintenant que vous ne vouliez que les tables et PF qui ont été utilisées sur l’année flottante (13 mois), on va utiliser la vue SYSTABLESTAT
SELECT a.SYSTEM_COLUMN_NAME, A.SYSTEM_TABLE_NAME, A.SYSTEM_TABLE_SCHEMA FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in( ‘T’ , ‘P’) join SYSTABLESTAT c on A.SYSTEM_TABLE_NAME=c.SYSTEM_TABLE_NAME and a.SYSTEM_TABLE_SCHEMA = c.SYSTEM_TABLE_SCHEMA and c.LAST_USED_TIMESTAMP > (current date – 13 months) WHERE COLUMN_NAME = ‘NUMCLI’
Cette exemple n’est pas parfait, mais il vous montre qu’avec le catalogue db2 et un peu de SQL vous pouvez avoir de nombreuses informations pertinentes sur cette dernière . Vous pouvez par exemple avoir des informations statistiques sur vos colonnes par la vue SYSCOLUMNSTAT et une vue globale avec la vue SYSFILES qui permet d’avoir un bon résumé de vos fichiers
https://www.ibm.com/support/pages/node/6486897
Voici un lien qui vous présente les vues disponibles,
Voici une fonction RPGLE pour contrôler un numéro de sécurité sociale.
Elle reçoit une variable caractère de 15 de long qui contient le numéro de sécu + sa clé et renvoie un booléen indiquant si la clé calculée est différente ou égale de la clé passée.
C’est une fonction que vous pouvez inclure dans un programme de service par exemple !
Voici le code à inclure dans votre programme de service :
https://www.gaia.fr/wp-content/uploads/2022/08/IMG-20200712-WA0017.jpg1024768admin/wp-content/uploads/2017/05/logogaia.pngadmin2022-08-09 14:41:372022-08-09 16:51:01Contrôlez un numéro de sécu
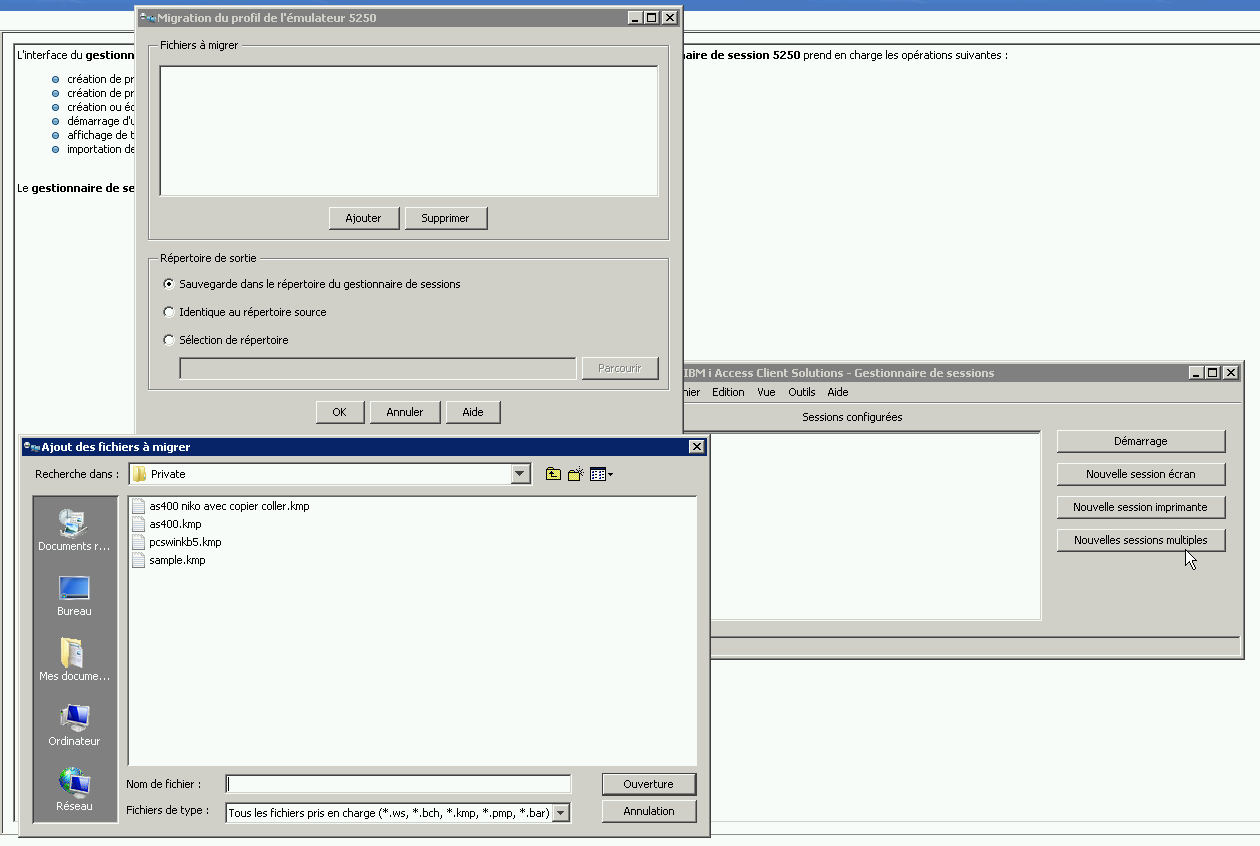
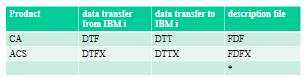
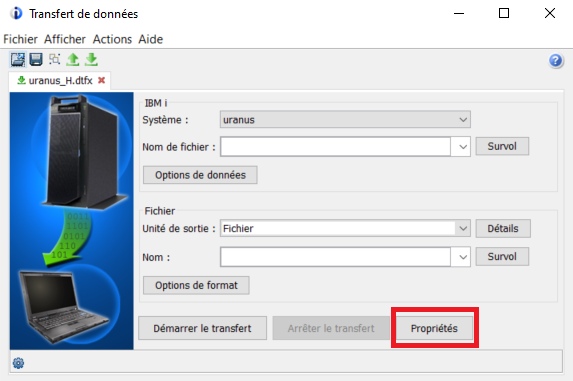
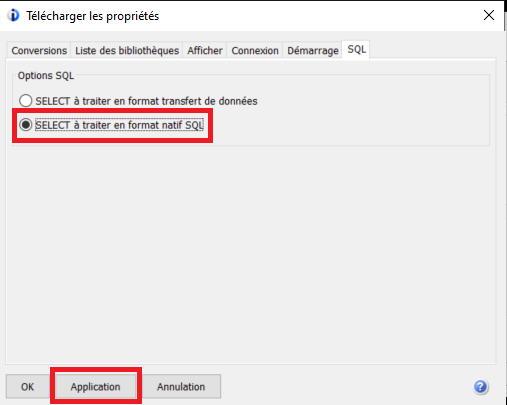
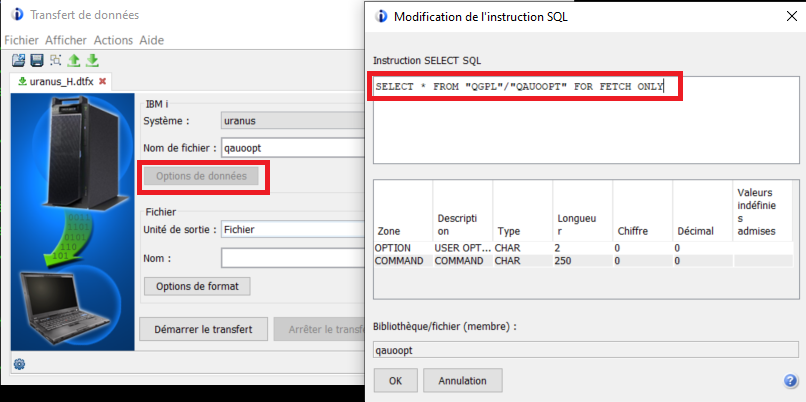
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-08-08 18:14:582022-08-08 18:14:59Créer une requête DTFX en SQL
Pour faire un peu de place il peut être important de supprimer certains récepteurs de journaux inutiles
D’abord la liste des récepteurs détachés de plus de 30 jours
SELECT JOURNAL_RECEIVER_LIBRARY, JOURNAL_RECEIVER_NAME FROM QSYS2.JOURNAL_RECEIVER_INFO WHERE ATTACH_TIMESTAMP < current date – 30 days and DETACH_TIMESTAMP is not null
A partir de cette liste vous pouvez faire une DLTJRNRCV de ces recepteurs
Liste des journaux qui n’éffacent pas les récepteurs après détachement SELECT JOURNAL_NAME, JOURNAL_LIBRARY FROM qsys2/JOURNAL_INFO WHERE DELETE_RECEIVER_OPTION = ‘NO’
A partir de cette liste vous pouvez modifier le récepteur en indiquant de supprimer les recepteurs après détachement !
CHGJRN DLTRCV(*YES)
Attention :
Il ne faut pas supprimer des récepteurs de votre base de données de production mais il y a souvent une multitude de bases de tests qui n’ont pas besoin de leurs récepteurs détachés pour permettre de faire des tests
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2022-08-08 17:39:102022-08-08 17:39:112 requêtes pour gérer vos récepteurs de journaux