Sécurisez vos services IBM i ! Nous ne le répéterons jamais suffisamment : vous devez crypter les accès au telnet 5250, au serveur de base de données etc … Bref partout où transitent aussi bien vos profils/mots de passe que vos informations métier.
Nous prenons ici l’exemple de telnet, le plus visuel.
Pour crypter vos connexions telnet : https://www.ibm.com/docs/en/i/7.5?topic=server-assigning-certificate-telnet
En synthèse :
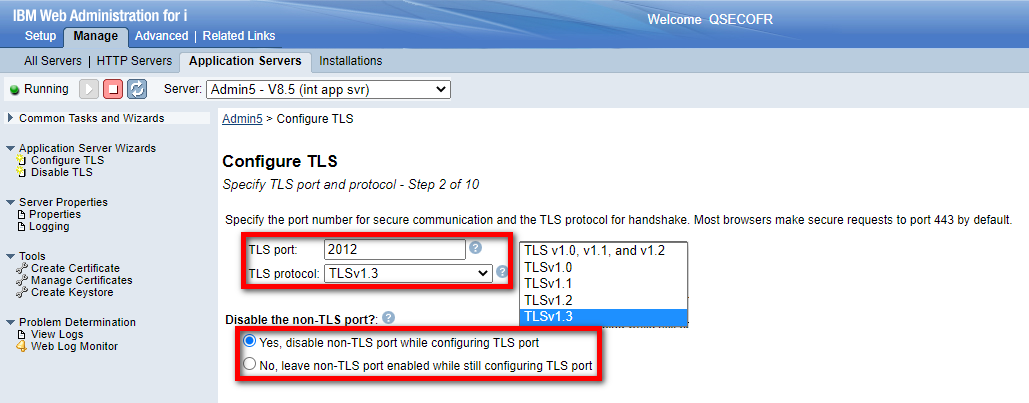
- Importer ou créer un certificat dans DCM (Digital Certificate Manager)
- Associer ce certificat aux services à sécuriser : TELNET ici mais aussi CENTRAL, SIGNON, DATABASE …
- Ne pas oublier de permettre la connexion sécurisée à telnet :
Permettre l'accès non sécurisé et sécurisé (ports 23 et 992) : CHGTELNA ALWSSL(*YES) Permettre l'accès sécurisé uniquement (port 992 uniquement) : CHGTELNA ALWSSL(*ONLY)
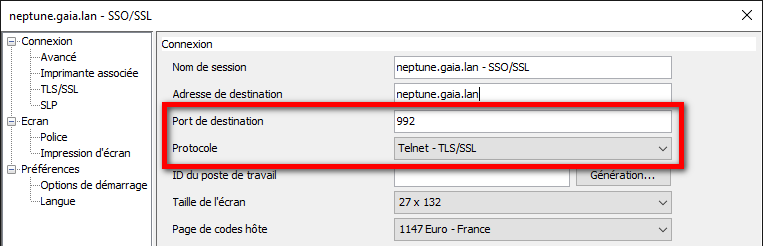
Dès lors vous pouvez vous connecter avec ACS en mode sécurisé. Soit en indiquant au niveau de la configuration dans l’émulateur 5250 (menu Communication puis Configuration) :
Soit au niveau de la connexion système dans sa globalité :
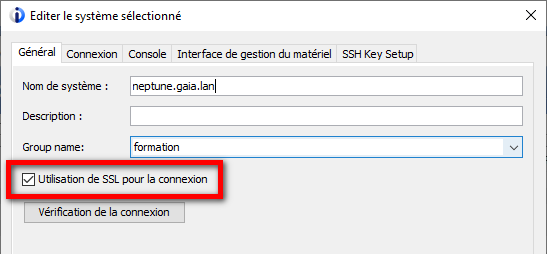
A la prochaine connexion vous obtenez :
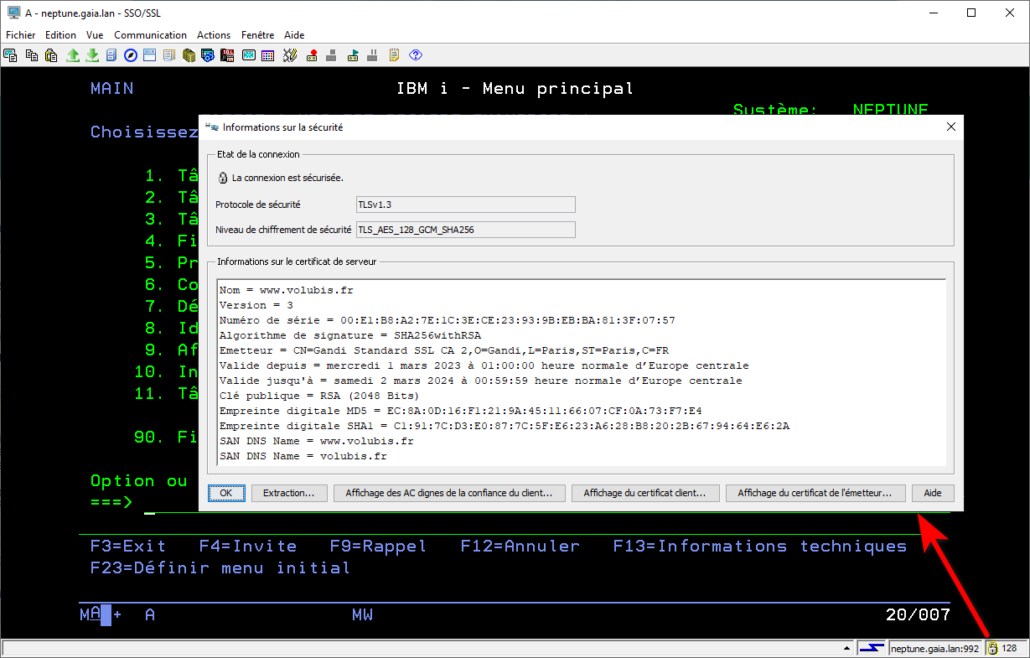
Mais comment ces certificats sont-ils gérés par ACS ?
Principe d’un certificat, chaîne de certification
Un certificat est une clé de cryptage permettant de chiffrer les données entre un serveur et un client.
La question est de savoir comment faire confiance à un certificat (celui de votre banque par exemple ?).
Un certificat est lui-même signé, c’est à dire validé, par une autorité de certification à laquelle nous faisons confiance.
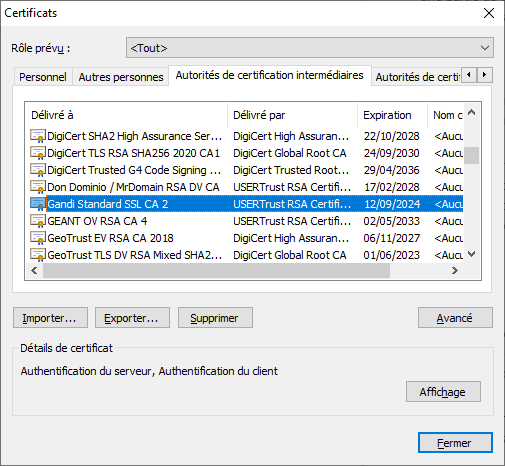
Exemple avec les informations issues d’un navigateur :
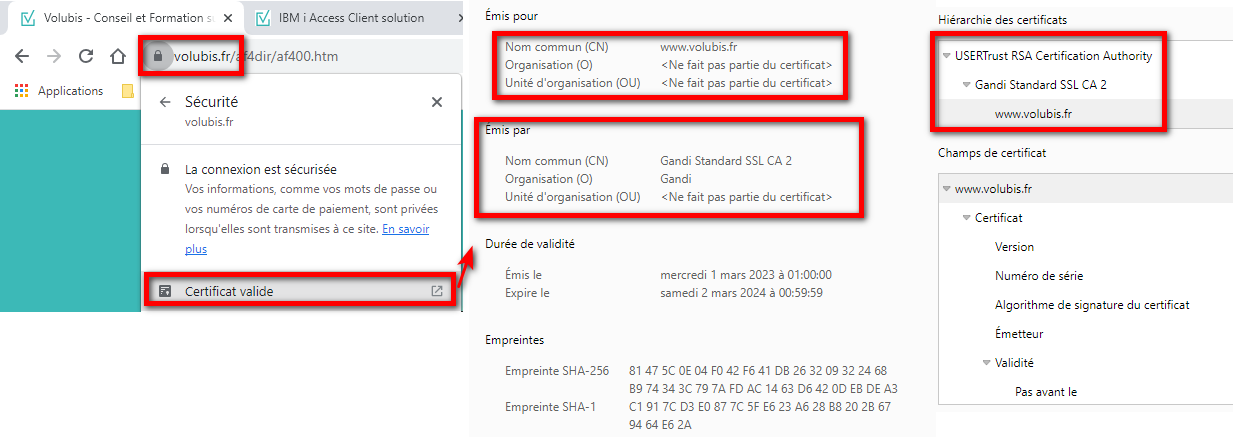
Le navigateur fait confiance à www.volubis.fr car le certificat est lui-même signé par « Gandi Standard SSL CA 2 » et « USERTrust RSA Certification Authority » qui sont eux connus du navigateur :
D’autres critères entrent en compte comme la durée de validité par exemple
Pour un certificat non reconnu par votre navigateur, vous avez :
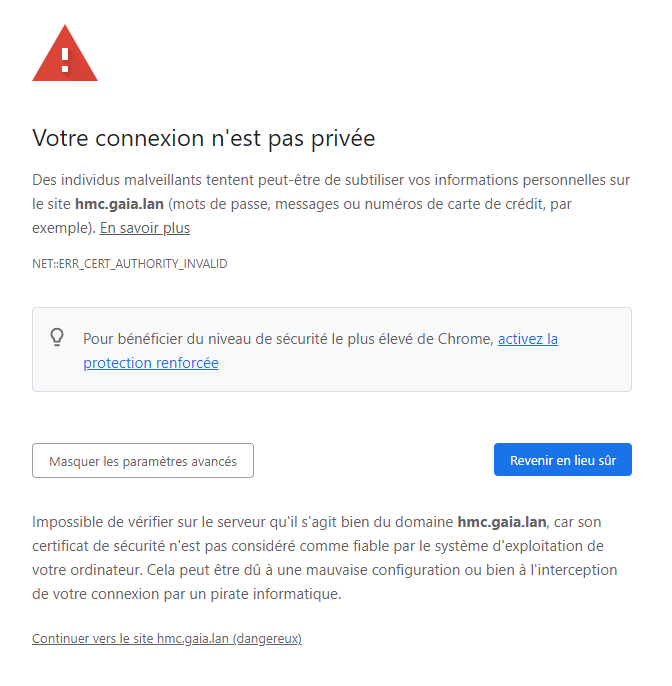
Validation par Access Client Solutions
ACS va utiliser la même mécanique : si l’autorité de certification est connue de ACS, alors le certificat est validé.
Si l’autorité n’est pas connue : demande à l’utilisateur de valider ou non l’accès.
Access Client Solutions utilise plusieurs magasins de certificats pour stocker les autorités :
- le magasin lié à votre JVM qui exécute ACS
- un magasin propre à ACS en complément
Magasin lié à la JVM
Pour trouver la JVM utilisée par ACS :
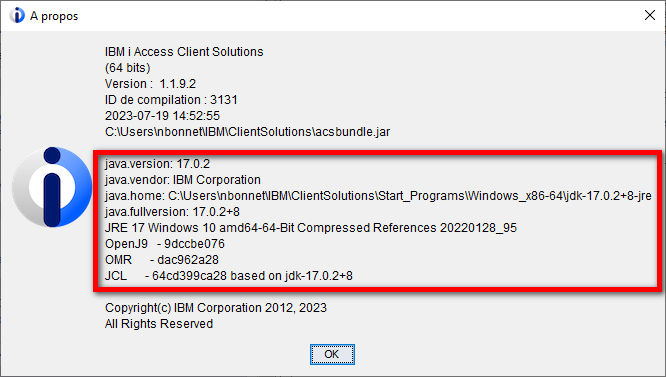
Java utilise par défaut un magasin de certificats JAVA_HOME\lib\security\cacerts. Ce magasin est protégé par un mot de passe (défaut = changeit)
Remarque :
Cette configuration par défaut peut être modifiée par fichier de configuration ou arguments de démarrage de la JVM.
Ou outil de gestion des certificats est fourni avec votre JVM : keytool (cf https://docs.oracle.com/javase/8/docs/technotes/tools/unix/keytool.html)
Exemple :
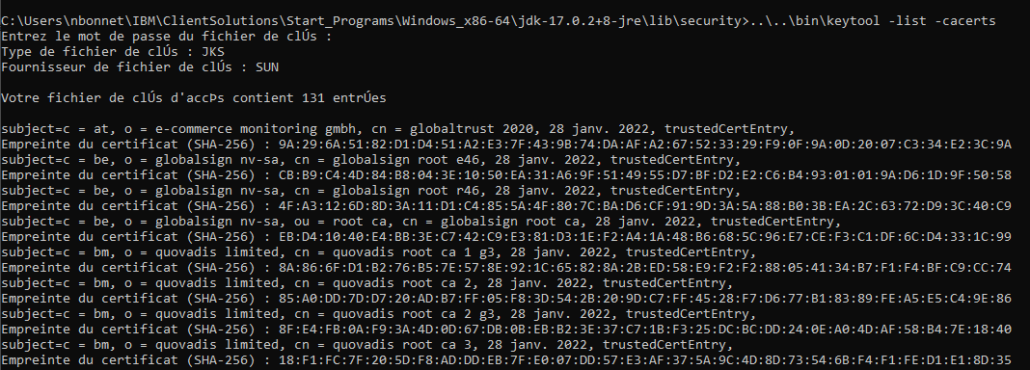
Nous retrouvons bien notre autorité primaire « USERTrust RSA Certification Authority » :

Magasins liés à ACS
Par défaut, chaque utilisateur d’ACS dispose de son propre magasin de certificat (complémentaire à celui de l’environnement Java ci-dessus).
Dans les préférences vous retrouvez l’emplacement des configurations :
Access Client Solutions dispose également d’un outil de gestion des certificats pour son propre magasin uniquement : menu « Outils » puis « Gestion des clés » :
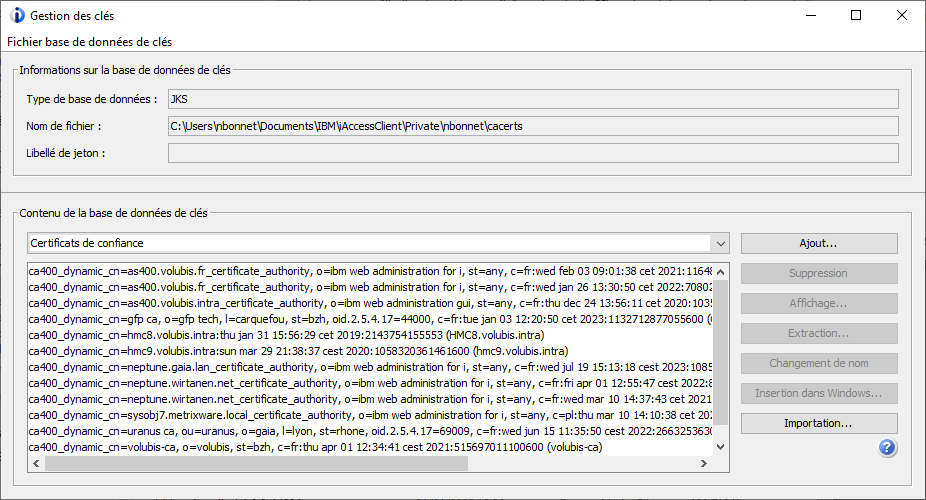
Cela vous permet d’importer, supprimer, voir vos certificats.
Remarque :
Cette configuration par défaut peut être modifiée par fichier de configuration AcsConfig.properties : permet d’indiquer l’emplacement du magasin de certificats.
Cas d’un certificat « internet »
Si vous avez acheté votre certificat auprès d’un organisme certificateur (Gandi pour nous, mais aussi OVH, Sectigo … Let’s encrypt gratuit), Access Client Solutions ne devrait rien vous demander et accepter directement le certificat : les autorités présentes dans le magasin associé à votre JVM permettent la validation.
Vous pouvez rencontrer des problèmes avec d’anciennes installations de Java non mises à jour : les nouvelles autorités de certification ne seront pas présentes. Bien sûr cela n’arrive jamais.
Cas d’un certificat « local »
Pour un certificat que vous avez généré sur votre IBM i, ou autre plateforme dans votre SI, si vous disposez de vos propres autorités de certification internes (fréquent dans les sociétés de grande taille) : Access Client Solutions ne dispose pas des autorités permettant la validation !
Remarque :
Si vos équipes de déploiement des postes client livrent les autorités de certification dans le magasin de la JVM, vous revenez dans le cas précédent.
A la première connexion, vous avez ce message :
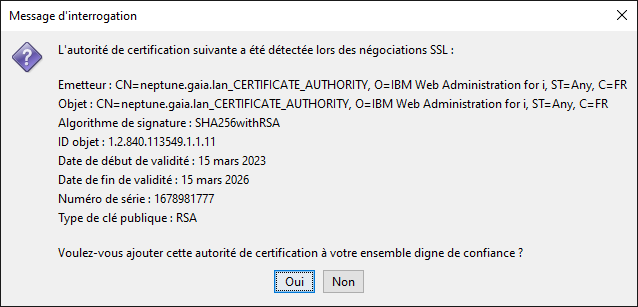
Non : vous refusez la connexion
Oui : l’autorité de certification est ajoutée au magasin de certificats d’ACS.
Après avoir répondu « Oui » :
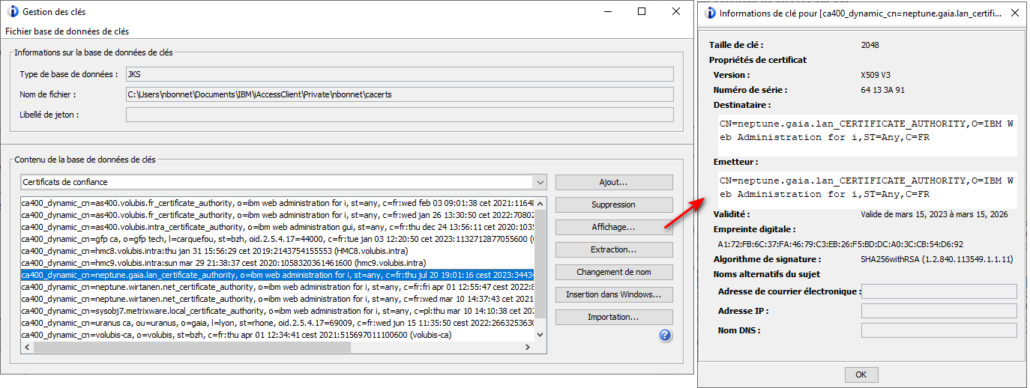
Aucun message affiché lors des prochaines connexions.
Changement de certificat
Comment faire en sorte que la sécurisation de vos services ou un changement de certificat soit transparent pour vos utilisateurs ?
Nous savons que demander à des centaines d’utilisateurs de répondre « Oui » peut générer un support très important aux équipes et être anxiogène.
Mise en place
Au-delà du certificat, il faut procéder aux changements de configurations : au niveau de la définition du système et/ou de la session 5250.
Pour le certificat, plusieurs solutions :
- Vous disposez d’un poste modèle sur lequel vous avez installé ACS, et importez manuellement l’autorité de certification. Il vous suffit alors de déployer le fichier cacerts de ACS sur les différents postes.
Ce dernier est ici : "C:\Users\{USER}\Documents\IBM\iAccessClient\Private\{USER}\cacerts"
- Dans le fichier de configuration AcsConfig.properties : vous pouvez indiquer un fichier cacerts mutualisé sur un lecteur réseau par exemple :

- Injection du certificat en mode commande
ACS dispose de commande, avec option silencieuse :
/PLUGIN=certdl => demande à downloader l’autorité de certification et l’importer dans le magasin
/SYSTEM=nom système configuré => depuis le système en question
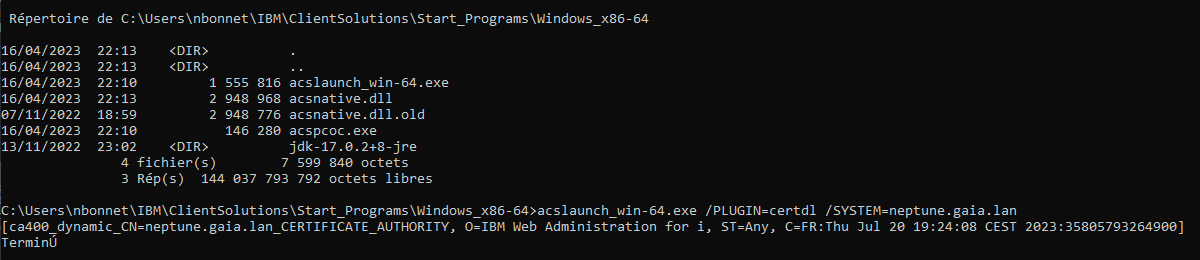
A intégrer dans vos outils de déploiement pour exécution sur chaque poste client ! Le certificat est ensuite visible dans le menu « Outils » puis « Gestion des clés ».
Renouvellement
- Le certificat est issu de la même autorité de certification que le précédent : rien à faire ! C’est l’autorité qui est stockée, pas le certificat lui-même
- Le certificat est issu d’une autre autorité (autre fournisseur, autorité précédente périmée ou invalidée) : il faut injecter l’autorité dans le magasin de certificat (cf Mise en place)
En synthèse : pas de difficulté, plusieurs solutions en fonction de votre organisation et outillage !
N’oubliez pas de renouveler vos certificats avant la date d’expiration …