Il est possible que vous ayez un effet de bord sur les fichiers téléchargés par FTP ou SFTP par exemple dans vos cpyfrmstmf ou cpyfrmimpf vous avez un plantage.
Les fichiers étaient jusqu’ici encodés en CCSID = 819 et maintenant par défaut, ils sont encodés en CCSID = 1208
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-05-12 14:04:002023-05-13 09:42:42Migration en V7R4 et IFS
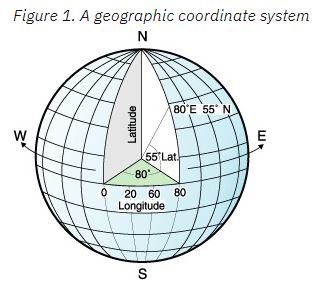
Premier test sur les fonctions géospatiales, elles sont désormais intégrées à DB2
Vous pouvez indiquer les coordonnées GPS d’un lieu dans une zone, et vous pourrez ensuite faire des calculs, de distance , de superficie, etc …
C’est des zones de type QSYS2.ST_POINT, par exemple pour indiquer des coordonnées GPS, mais vous pouvez également indiquer des formes comme des lignes ou des polygones ..
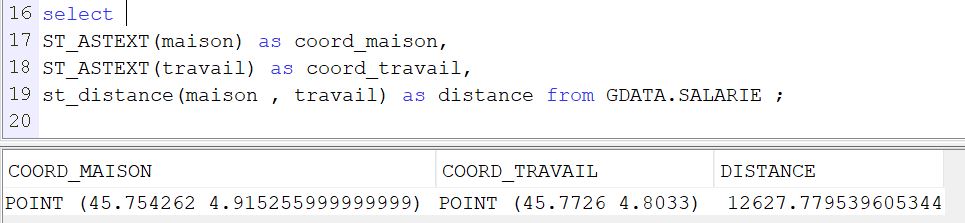
Voici un premier exemple
— Création table des salariés avec leur lieu de travail
create table GDATA.SALARIE (ID int, NOM varchar(30), PRENOM varchar(30), MAISON QSYS2.ST_POINT, TRAVAIL QSYS2.ST_POINT);
— Insertion dans la table des informations Vous pouvez les trouver ici les coordonnées GPS: https://www.coordonnees-gps.fr/
le gouvernement mais également à disposition un site
INSERT INTO GDATA.DOCTEUR VALUES(3, ‘Docteur3’, ‘Paris’, QSYS2.ST_POINT(‘point (48.8532238 2.3678865)’)
) ;
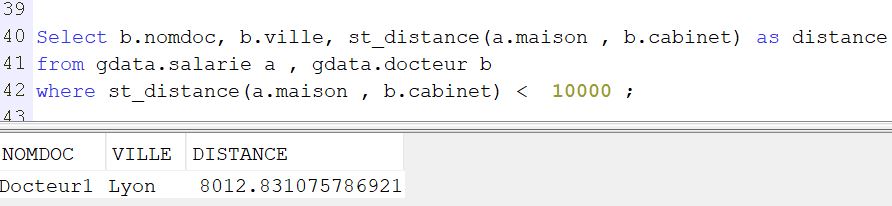
— Je veux les docteurs à moins de 10 km du domicile du salarié
Select b.nomdoc, b.ville, st_distance(a.maison , b.cabinet) as distance from gdata.salarie a , gdata.docteur b where st_distance(a.maison , b.cabinet) < 10000 ;
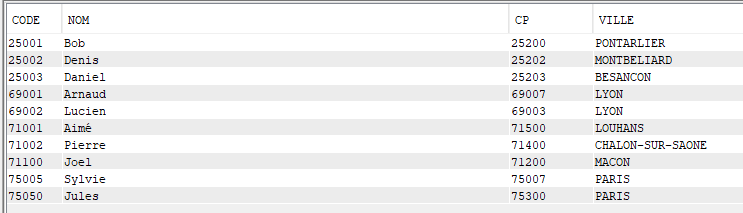
Le résultat
Conclusions :
Il y a des fonctions beaucoup plus poussées, et on imagine bien le type d’application qu’on pourra faire, donc on peut prévoir dès à présent une zone de géolocalisation dans des fichiers clients qu’on va créer, voir modifier .
Quand un travail démarre, il crée dans la log système un message CPF1124 et un message CPF1164 quand il se termine.
C’est comme ca qu’on sait qu’un job à tourné
Mais attention, Il existe des travaux pour lesquels les messages CPF1124 et CPF1164 ne sont pas logués dans QHST : il s’agit des SPAWN jobs.
Les travaux QP0ZSPWP & QP0ZSPWT en sont de bons exemples.
Spawn batch jobs : https://www.ibm.com/docs/en/i/7.4?topic=jobs-spawn-batch
Spawn est une fonction qui crée un nouveau processus de travail (processus enfant) qui hérite de nombreux attributs du processus appelant (processus parent). Un nouveau programme est spécifié et commence à s’exécuter dans le processus enfant. Lorsque vous lancez un travail par lots, vous utilisez un travail parent pour transmettre des arguments et des variables d’environnement au travail enfant. L’API spawn() utilise des travaux batch immédiats, des travaux pré-démarrés ou des travaux batch pré-démarrés.
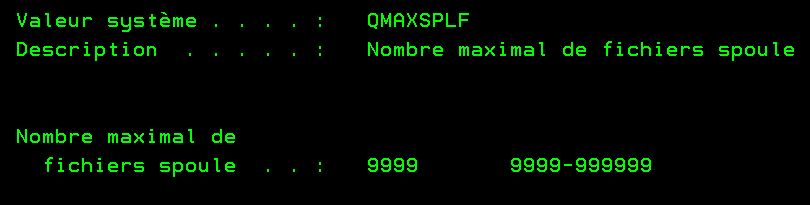
Nombre de spools d’un job est fixé globalement par la valeur système QMAXSPLF. Elle est par défaut à 9999 et le maximum 999999 sont changement ne nécessite pas d’IPL.
Il est possible que pour un job cette valeur soit insuffisante pour un asynchrone par exemple qui est chargé de faire de l’impression.
Vous recevrez le message CPF4167
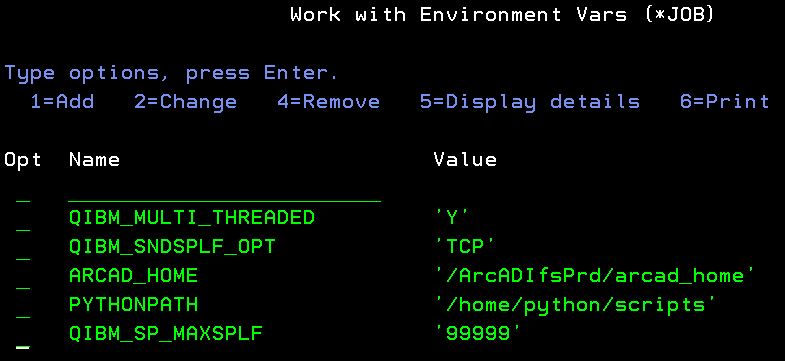
Vous pouvez augmenter cette limite en utilisant une variable d’environnement QIBM_SP_MAXSPLF
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-04-14 06:42:392023-04-14 14:19:45Nombre maximum de spools par JOB
WITH dbmon1 (QQRID, total1) AS (
SELECT QQRID,
COUNT(*)
FROM votrebib.QZGxxxxxx << monitor 1
GROUP BY QQRID
),
dbmon2 (QQRID, total2) AS (
SELECT QQRID,
COUNT(*)
FROM votrebib.QZGyyyyyyy << monitor 2
GROUP BY QQRID
)
SELECT dbmon1.QQRID,
dbmon1.total1,
dbmon2.total2
FROM dbmon1
JOIN dbmon2
ON dbmon1.QQRID = dbmon2.QQRID
En temps d’exécution
WITH dbmon1 (QQRID, total1) AS (
SELECT QQRID,
sum(QQETIM - QQsTIM )
FROM votrebib.QZGxxxxxxx << monitor 1
GROUP BY QQRID
),
dbmon2 (QQRID, total2) AS (
SELECT QQRID,
sum(QQETIM - QQsTIM )
FROM votrebib.QZGyyyyyyyy << monitor 2
GROUP BY QQRID
)
SELECT dbmon1.QQRID,
dbmon1.total1,
dbmon2.total2
FROM dbmon1
JOIN dbmon2
ON dbmon1.QQRID = dbmon2.QQRID
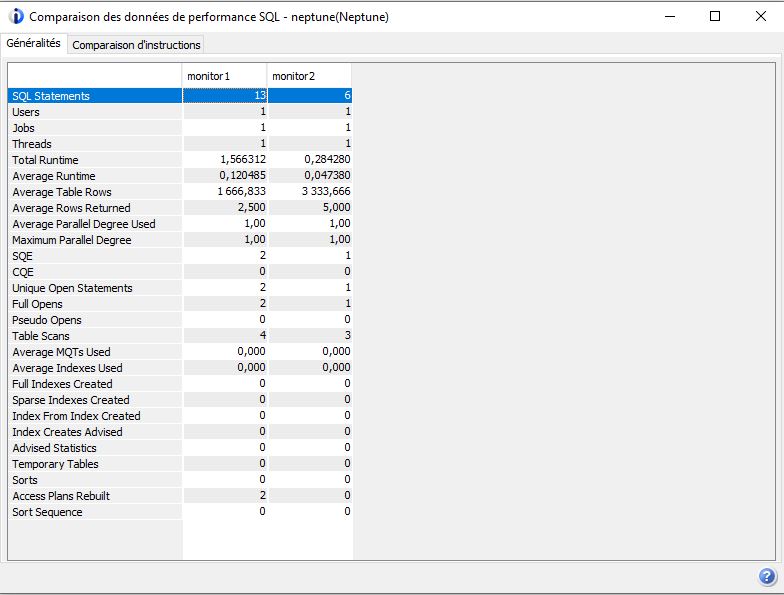
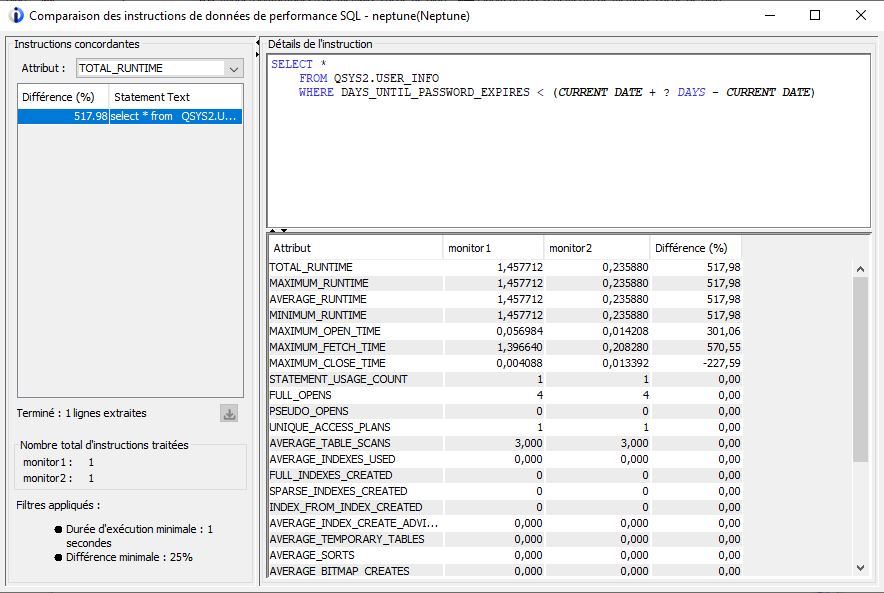
Après il vous faudra enquêter sur les différences que vous avez constaté
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-04-13 07:08:342023-04-13 07:08:36Comparer 2 monitors de base de données
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-04-11 16:43:202023-04-11 22:09:25TR2 pour la V7R5
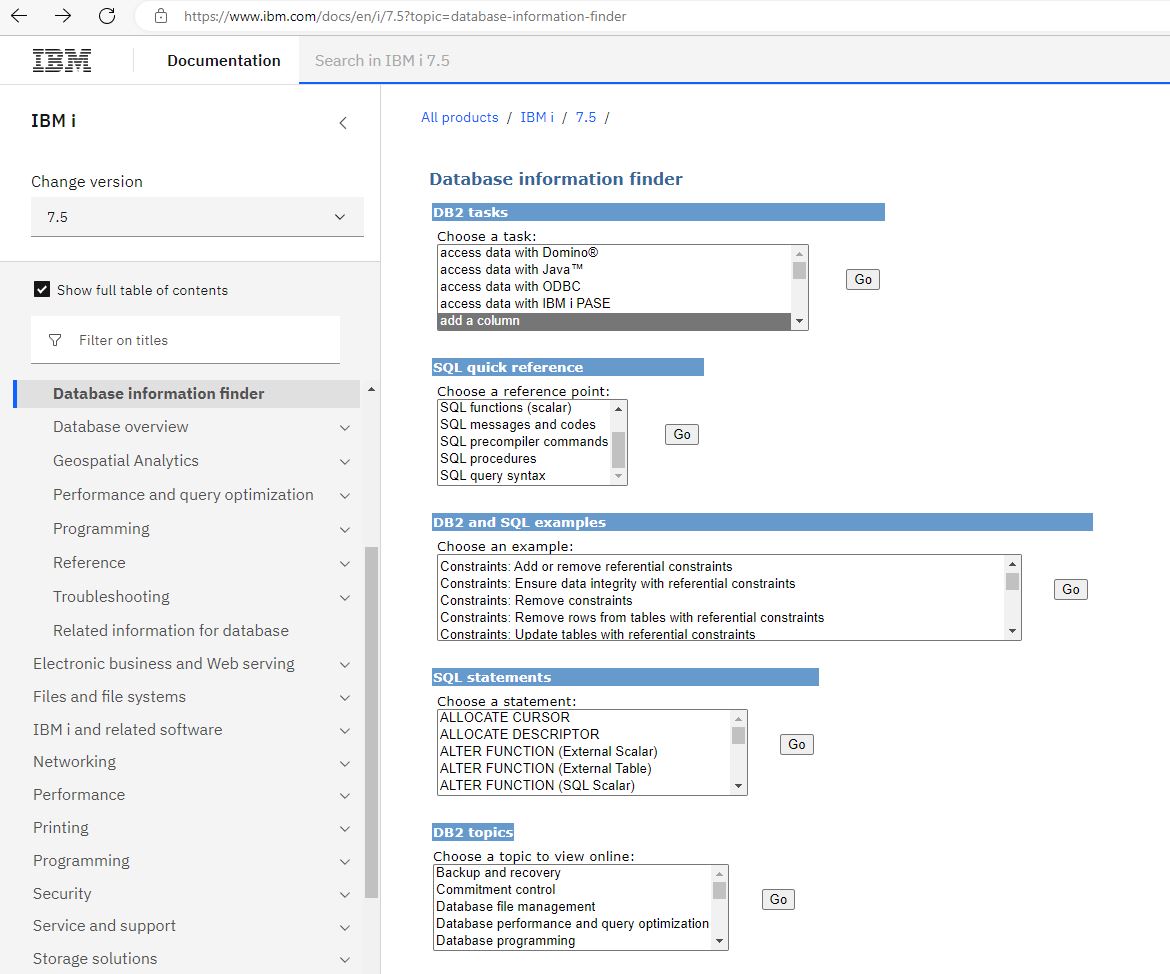
Si vous n’administré pas au quotidien votre base de données, mais que vous devez intervenir ponctuellement, Vous avez un lien qui référence les principales opérations à faire et qui peut vous aider
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-04-10 09:05:432023-04-10 09:05:44Database Information Finder
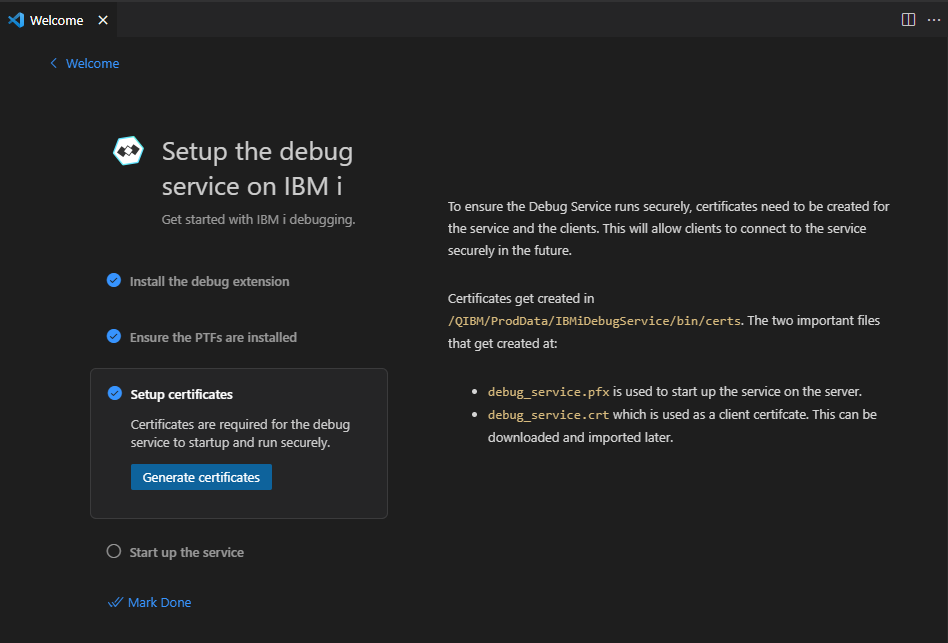
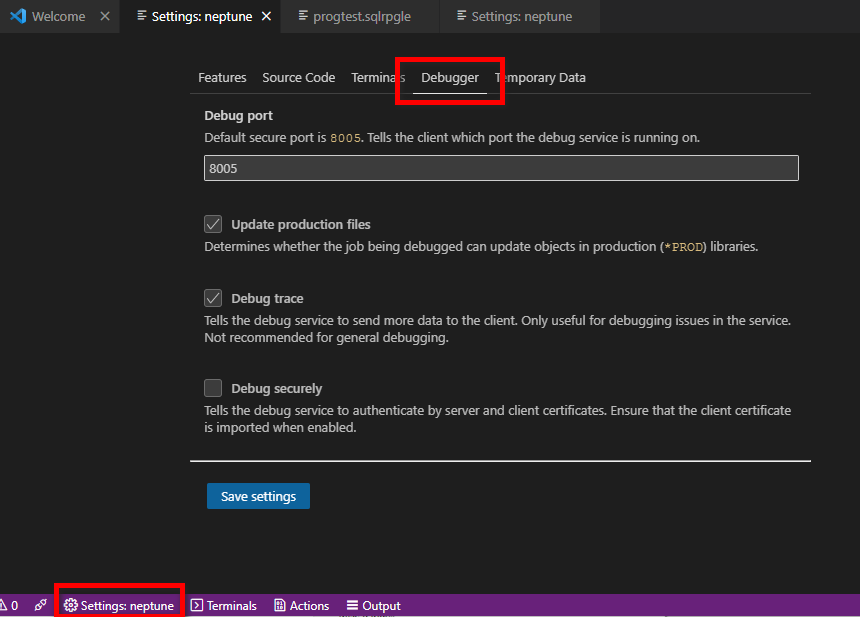
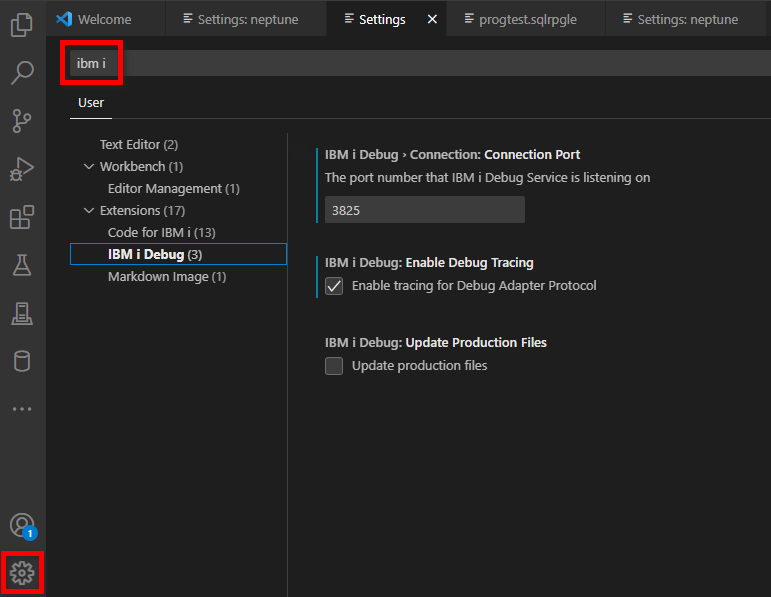
Une fois le service configuré et l’extension installée, il nous faut régler quelques options importantes.
Nous allons retrouver des options à deux endroits :
Au niveau de la connexion
Au niveau des options de l’extension :
Déboguer avec VSCode
Il y a plusieurs possibilités dans l’éditeur, nous en choisissons une.
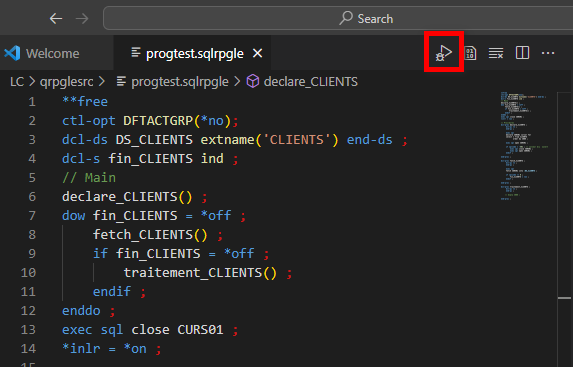
Ouvrez le source du programme à déboguer (on parlera ILE plus tard) :
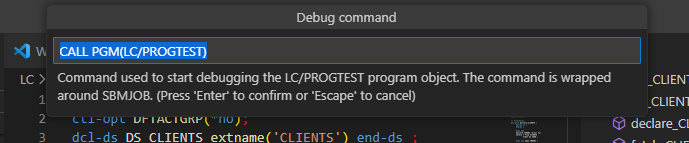
L’outil vous demande votre mot de passe sur l’IBM i pour valider votre profil, et prompte ensuite la commande d’appel du programme :
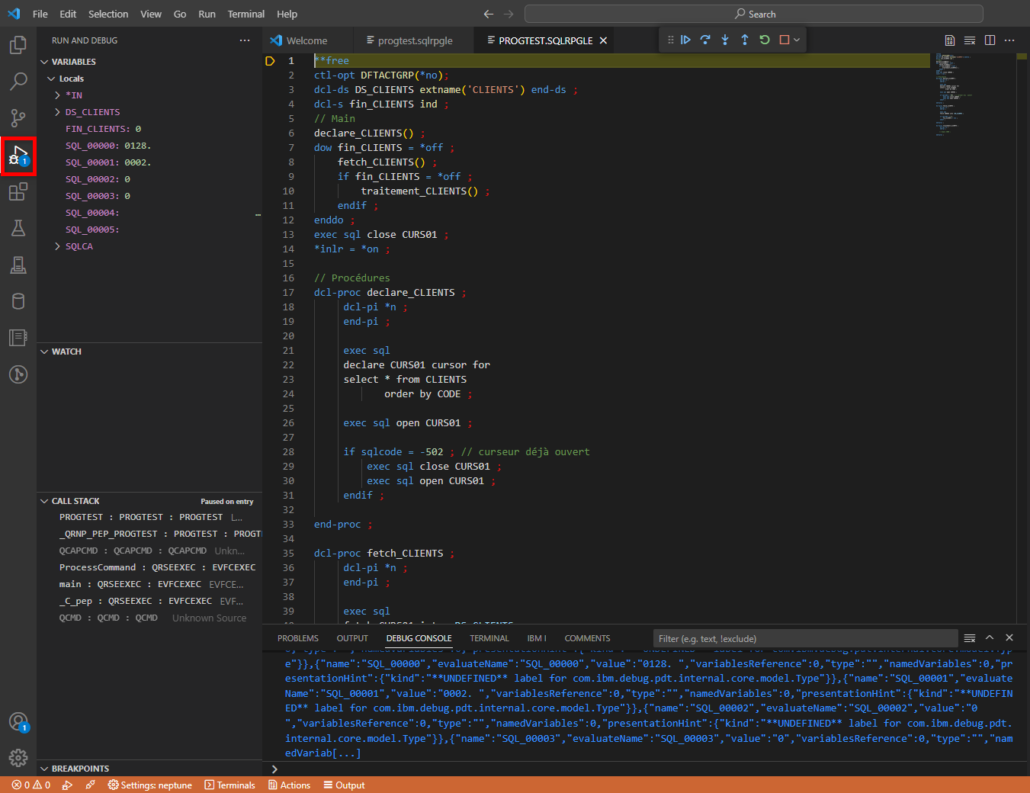
Vous basculez alors dans l’affichage du déboguer :
Voyons les outils :
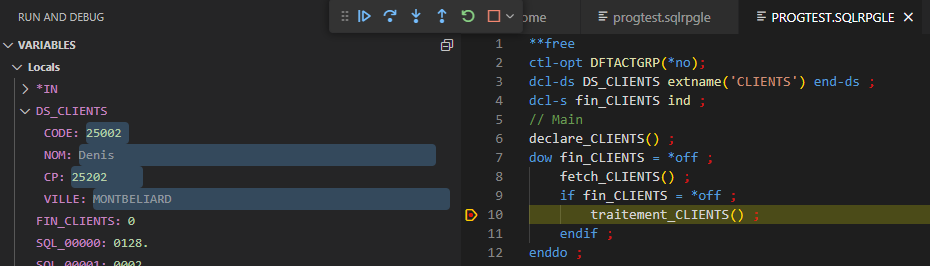
affichage des variables
Affiche les variables locales (quand vous êtes dans une procédure, vous ne voyez que les variables locales de la procédures, pas les variables globales du module).
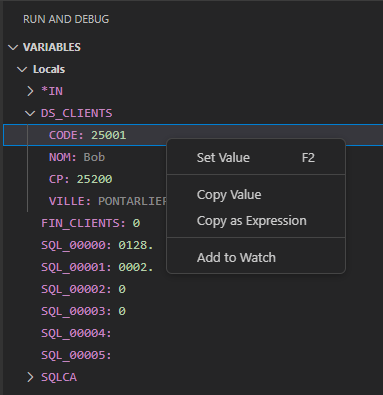
Vous pouvez copier les valeurs, les modifier, ajouter un guet
Guet (watch)
Affiche, et permet la saisie, de guets de variables.
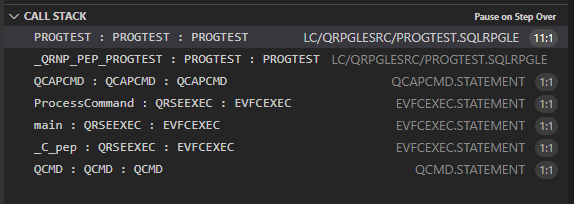
Pile d’appel
Permet de voir la procédure en cours d’exécution :
L’ordre d’affiche est : procédure / module / programme (de service)
Points d’arrêt
Liste les points d’arrêt, permet la création de nouveaux points et la suppression :
Contrôle de l’avancement
Permet d’avancer dans le débogage :
Dans l’ordre :
Avancer jusqu’au prochain point d’arrêt (équivalent F12 dans STRDBG)
Avancer et entrer en débogage dans la procédure ou programme appelé (équivalent F22 dans STRDBG)
Continuer jusqu’à ressortir de la procédure en cours
restart : non supporté pour l’IBM i
Arrêt du débogage (équivalent F3 dans STRDBG)
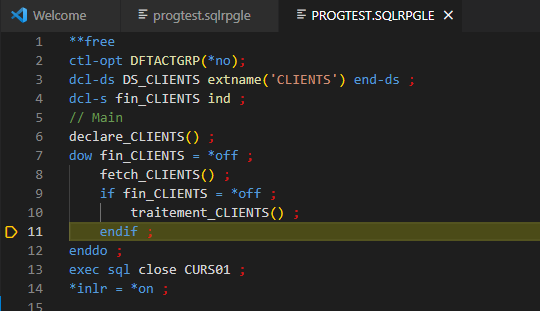
Editeur
Identification visuelle de la ligne en cours de débogage (non encore exécutée) :
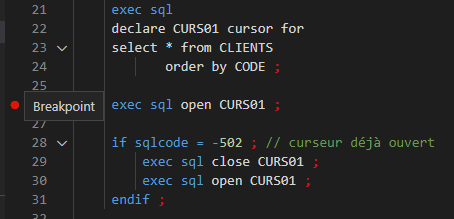
Point d’arrêt
Pour ajouter un point d’arrêt :
Soit clique gauche dans la marge
Le débogueur s’arrête sur le point d’arrêt au prochain passage.
Les variables modifiées par la dernière instruction sont mises en évidence.
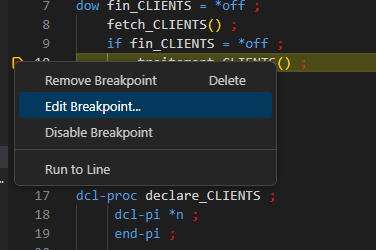
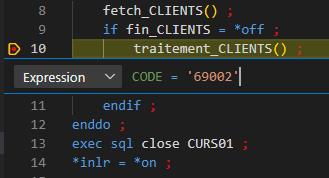
Point d’arrêt conditionné
Commencer par définir le point d’arrêt, puis clique droit -> Editer sur le point :
Puis indiquer votre condition avec la même syntaxe qu’avec STRDBG :
On ne s’arrêtera que lorsque la condition sera vraie !
Par rapport à RDi, le debug de VSCode ne permet pas, pour le moment, les points d’entrée de service ! Il faut donc que VSCode déclenche lui même l’exécution du programme à déboguer ! Gageons la situation évoluera très vite …
Une fois que vous êtes habitués au débogage, regardez les options de couverture de code …