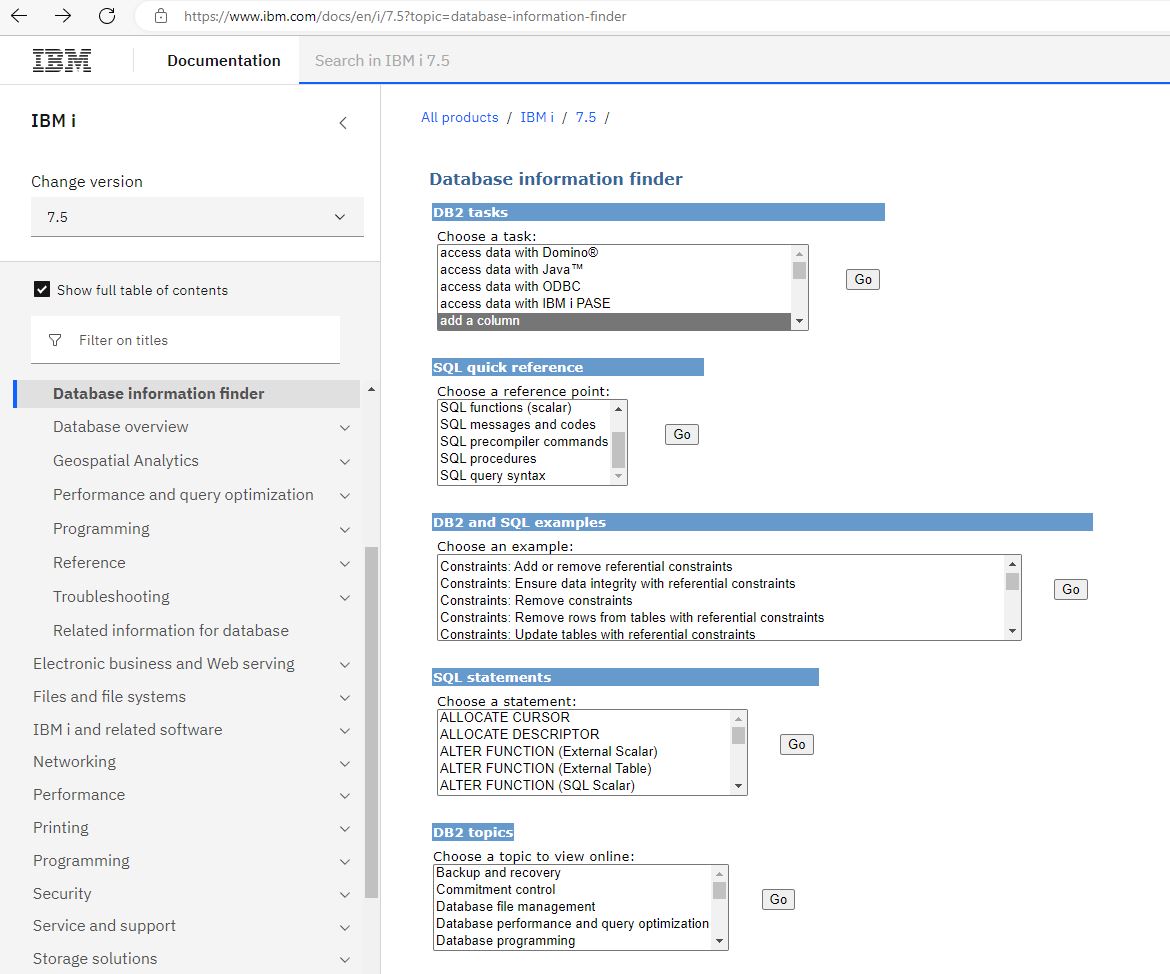
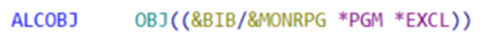Si vous n’administré pas au quotidien votre base de données, mais que vous devez intervenir ponctuellement, Vous avez un lien qui référence les principales opérations à faire et qui peut vous aider
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-04-10 09:05:432023-04-10 09:05:44Database Information Finder
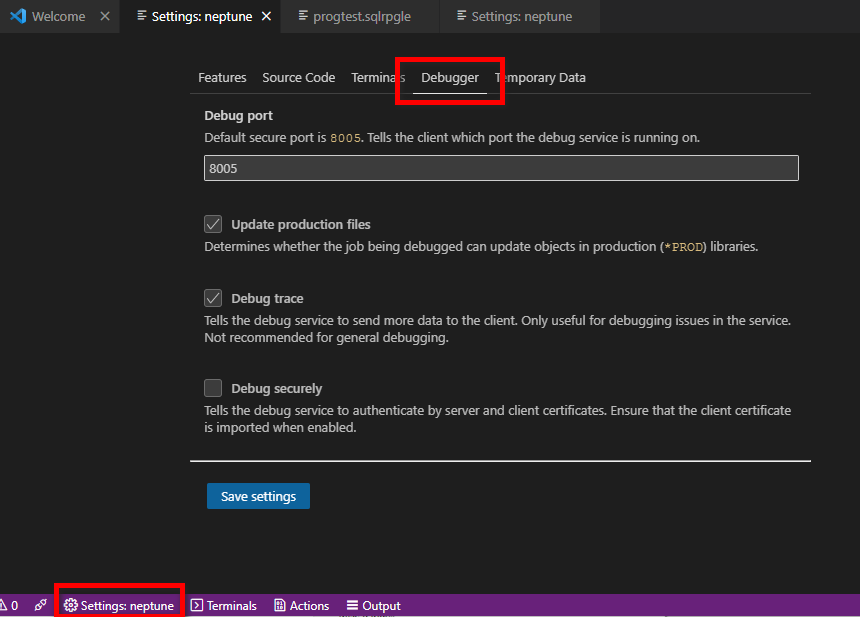
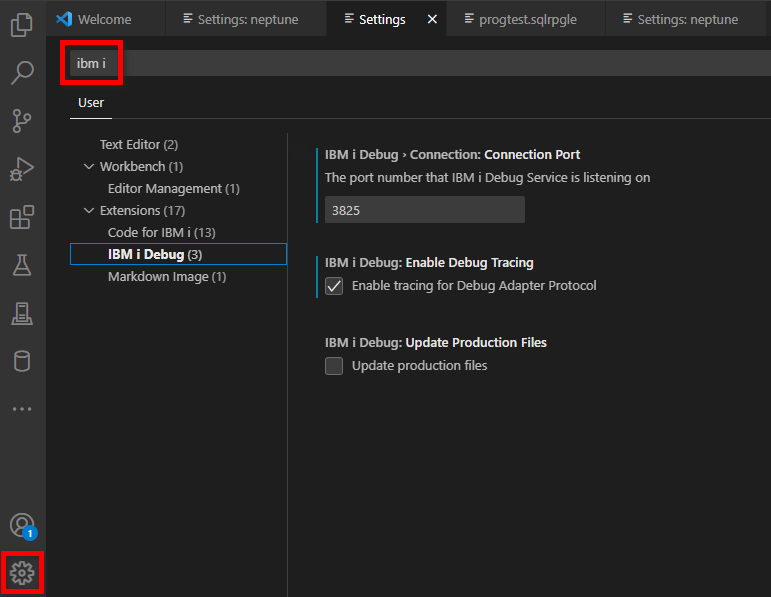
Une fois le service configuré et l’extension installée, il nous faut régler quelques options importantes.
Nous allons retrouver des options à deux endroits :
Au niveau de la connexion
Au niveau des options de l’extension :
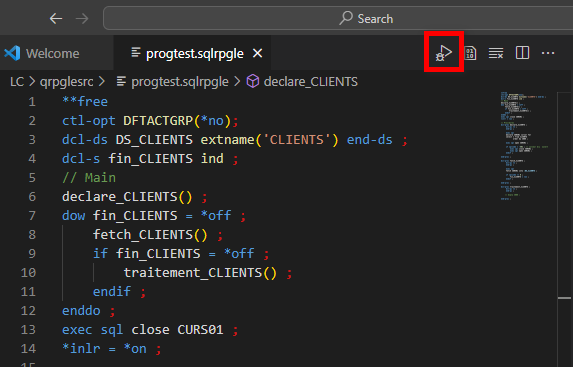
Déboguer avec VSCode
Il y a plusieurs possibilités dans l’éditeur, nous en choisissons une.
Ouvrez le source du programme à déboguer (on parlera ILE plus tard) :
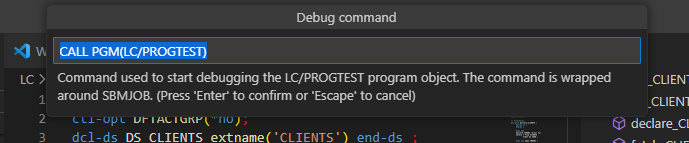
L’outil vous demande votre mot de passe sur l’IBM i pour valider votre profil, et prompte ensuite la commande d’appel du programme :
Vous basculez alors dans l’affichage du déboguer :
Voyons les outils :
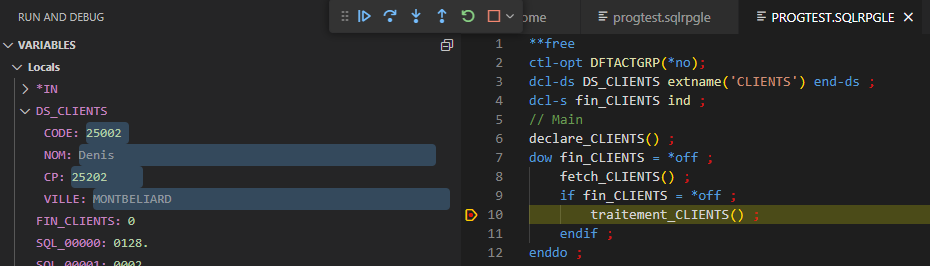
affichage des variables
Affiche les variables locales (quand vous êtes dans une procédure, vous ne voyez que les variables locales de la procédures, pas les variables globales du module).
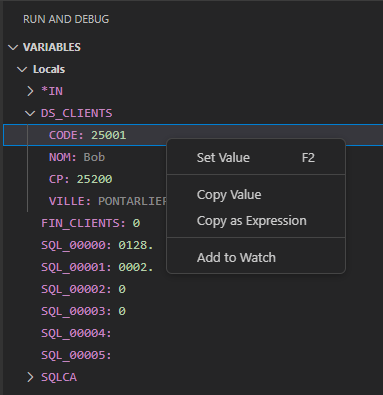
Vous pouvez copier les valeurs, les modifier, ajouter un guet
Guet (watch)
Affiche, et permet la saisie, de guets de variables.
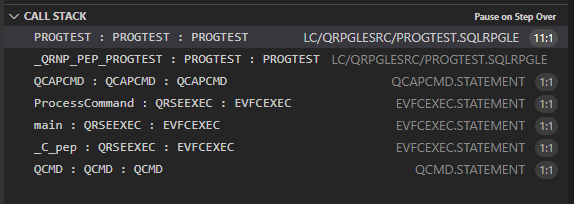
Pile d’appel
Permet de voir la procédure en cours d’exécution :
L’ordre d’affiche est : procédure / module / programme (de service)
Points d’arrêt
Liste les points d’arrêt, permet la création de nouveaux points et la suppression :
Contrôle de l’avancement
Permet d’avancer dans le débogage :
Dans l’ordre :
Avancer jusqu’au prochain point d’arrêt (équivalent F12 dans STRDBG)
Avancer et entrer en débogage dans la procédure ou programme appelé (équivalent F22 dans STRDBG)
Continuer jusqu’à ressortir de la procédure en cours
restart : non supporté pour l’IBM i
Arrêt du débogage (équivalent F3 dans STRDBG)
Editeur
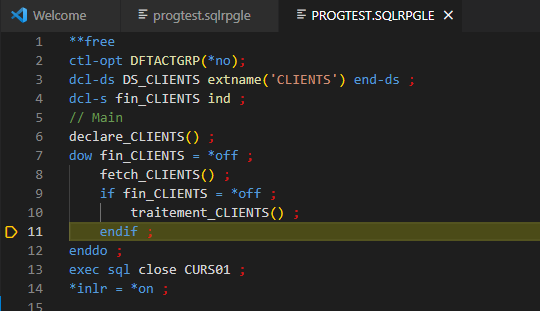
Identification visuelle de la ligne en cours de débogage (non encore exécutée) :
Point d’arrêt
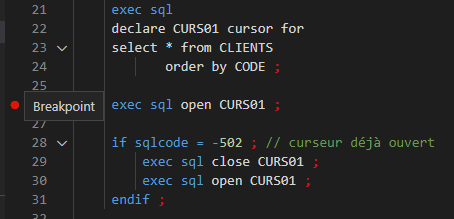
Pour ajouter un point d’arrêt :
Soit clique gauche dans la marge
Le débogueur s’arrête sur le point d’arrêt au prochain passage.
Les variables modifiées par la dernière instruction sont mises en évidence.
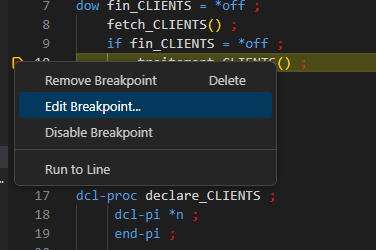
Point d’arrêt conditionné
Commencer par définir le point d’arrêt, puis clique droit -> Editer sur le point :
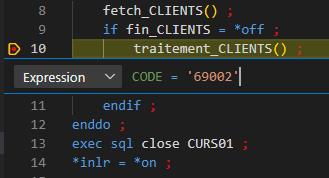
Puis indiquer votre condition avec la même syntaxe qu’avec STRDBG :
On ne s’arrêtera que lorsque la condition sera vraie !
Par rapport à RDi, le debug de VSCode ne permet pas, pour le moment, les points d’entrée de service ! Il faut donc que VSCode déclenche lui même l’exécution du programme à déboguer ! Gageons la situation évoluera très vite …
Une fois que vous êtes habitués au débogage, regardez les options de couverture de code …
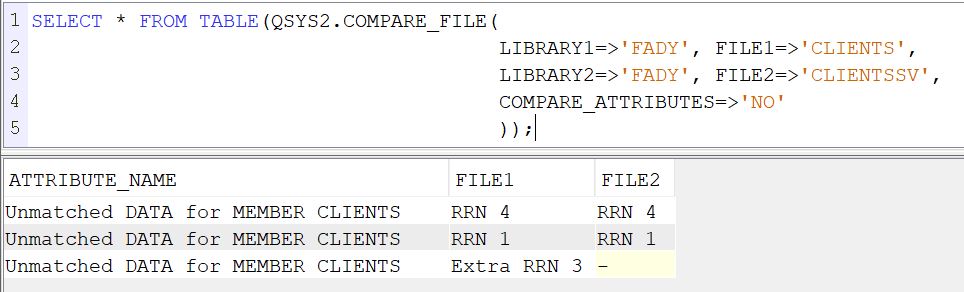
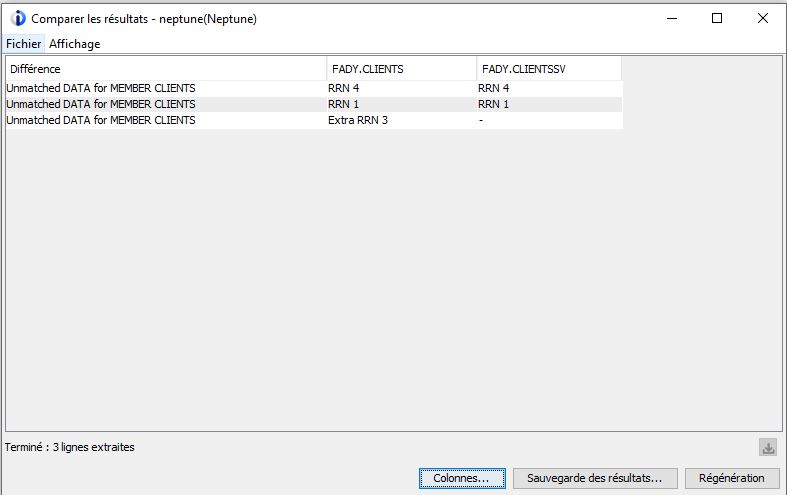
Elle se base également sur la fonction table COMPARE_FILE
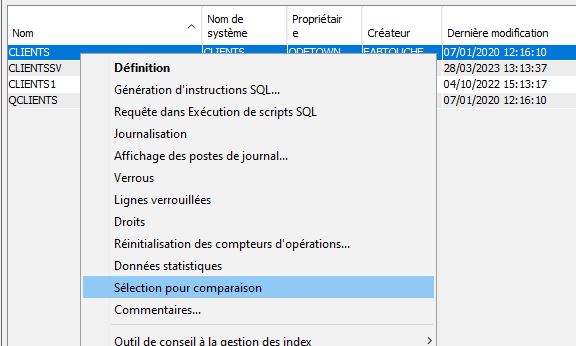
Sélectionner le premier fichier à comparer
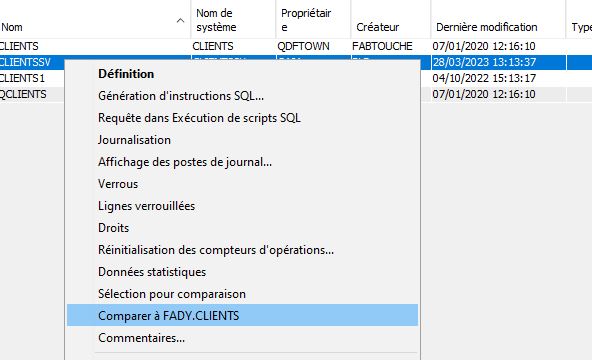
sélectionner le deuxième fichier à comparer
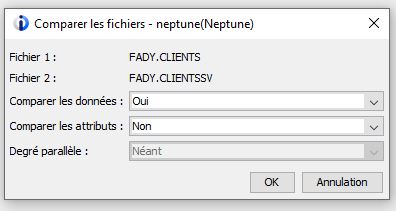
Choisissez l’option uniquement les datas
Vous pouvez exporter votre résultat au format csv par exemple
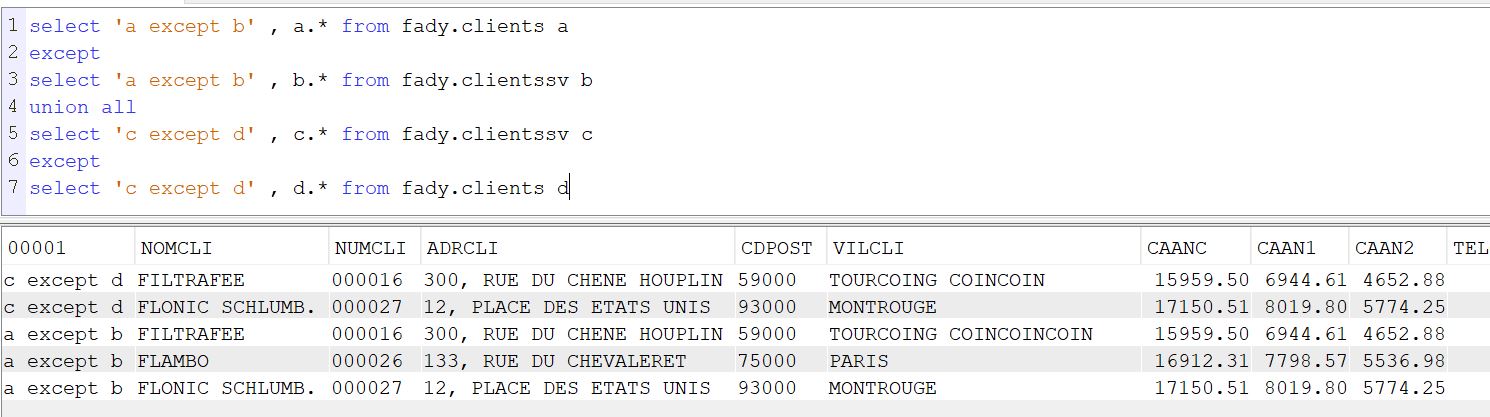
Troisième solution
Un petit script maison
select ‘a except b’ , a.* from fady/clients a except select ‘a except b’ , b.* from fady/clientssv b union all select ‘c except d’ , c.* from fady/clientssv c except select ‘c except d’ , d.* from fady/clients d
Conclusion :
A vous de choisir la solution qui vous convient
Attention cependant au COMPARE_FILE qui se base sur le RRN et un enregistrement recrée à l’identique avec un rrn différent sera considéré comme nouveau !
Merci a ceux qui m’ont aidé pour cette publication
Vous savez peut-être déjà comment créer un point d’arrêt conditionné en Débogage RPG 5250 (commande STRDBG).
Le mode Débogage RDi offre la même possibilité.
Cette fonctionnalité est particulièrement intéressante pour réaliser un Débogage ciblé dans un programme batch qui traite un gros volume de données.
Nous allons le vérifier avec l’exemple ci-dessous :
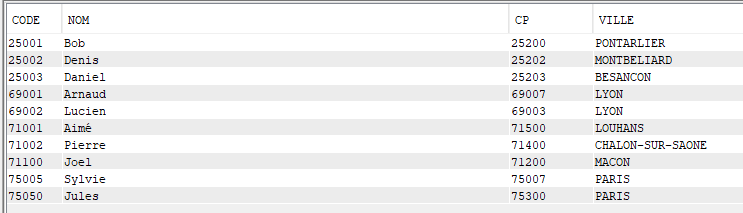
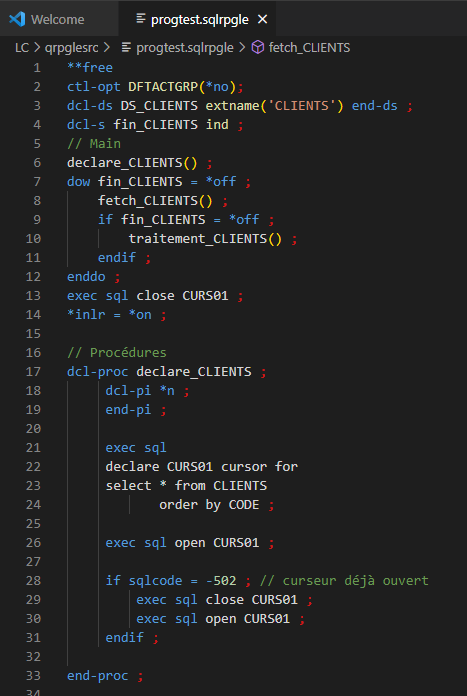
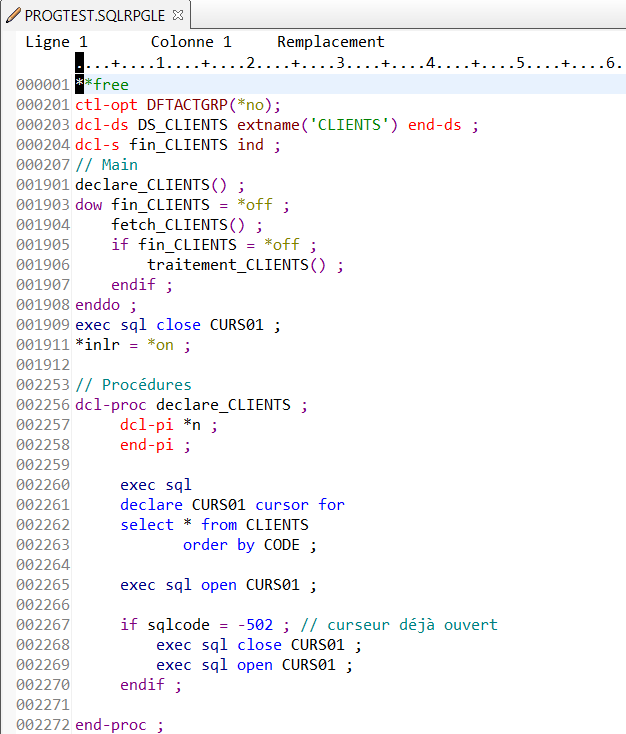
Considérons une table CLIENTS contenant les colonnes et lignes suivantes :
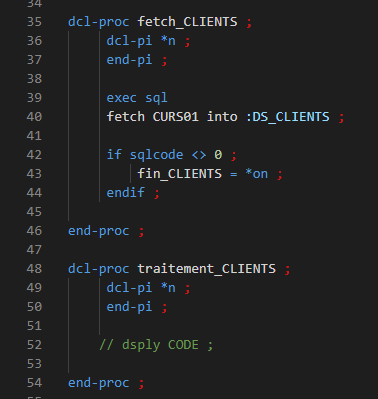
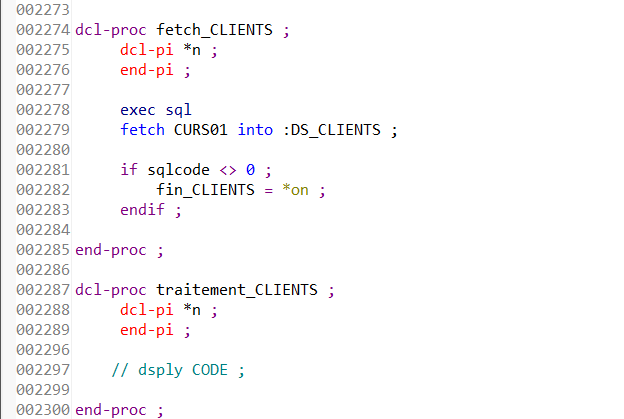
Le programme PROGTEST lit la tables CLIENTS et exécute la procédure traitement_CLIENTS pour chacun des clients de la table :
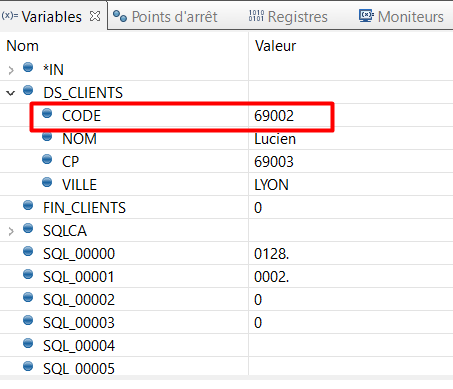
Nous allons utiliser le Débogage pour créer un point d’arrêt conditionné sur la ligne d’exécution de la procédure traitement_CLIENTS, afin de pouvoir déboguer ce traitement uniquement pour le client dont le code est 69002.
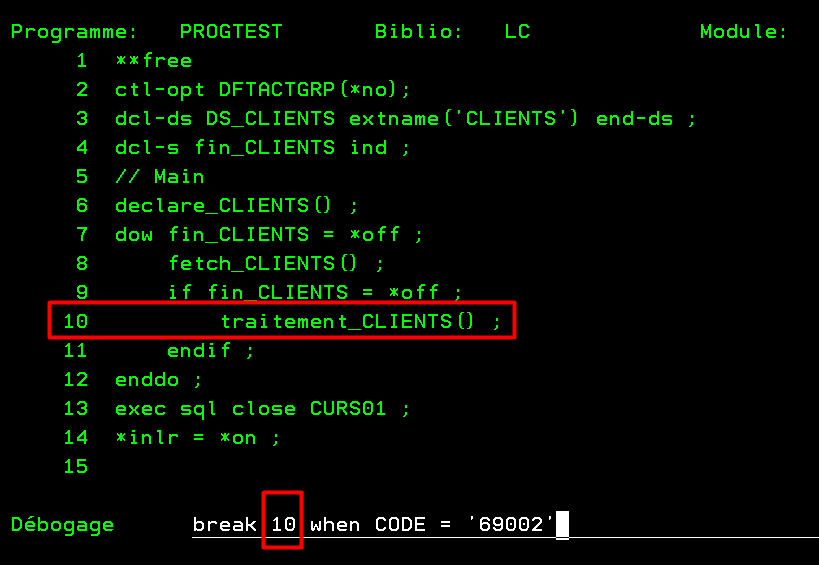
Point d’arrêt conditionné en Débogage 5250
On crée un point d’arrêt conditionné par une commande BREAK n°ligne WHEN condition
La condition peut utiliser toutes les variables connues du programme, ici le code client = variable CODE
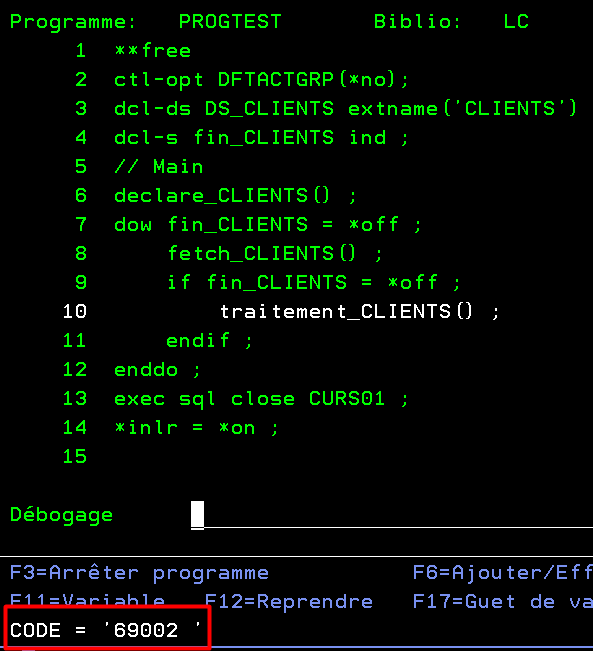
On exécute le programme :
Point d’arrêt juste avant le traitement du client souhaité :
Si on demande la reprise par F12, le programme se poursuit et se termine sans autre point d’arrêt
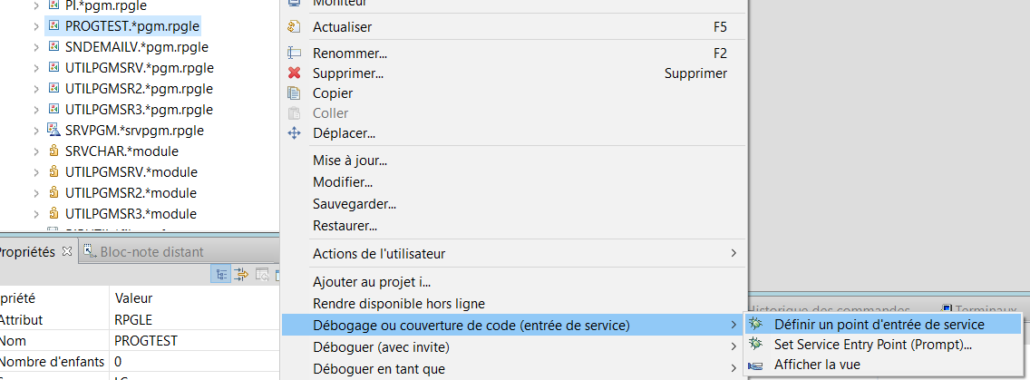
Point d’arrêt conditionné en Débogage RDi
On crée notre point d’entrée de service pour le programme PROGTEST
On ouvre la perspective Débogage sous RDi puis on exécute le programme en 5250 :
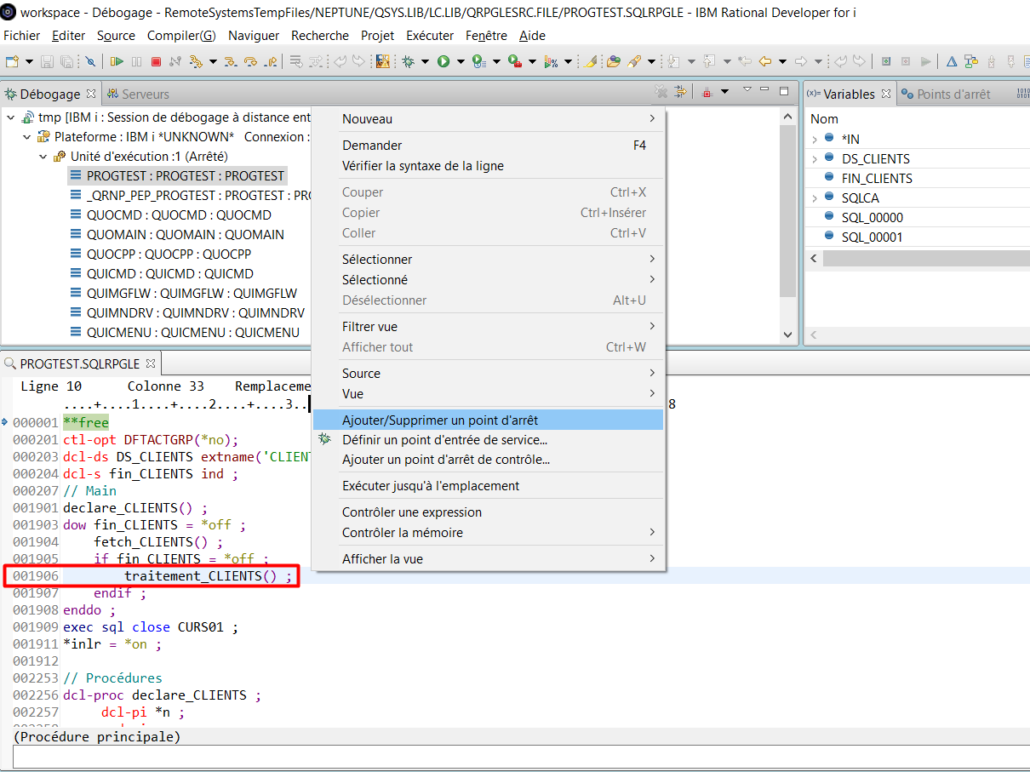
On crée tout d’abord notre point d’arrêt :
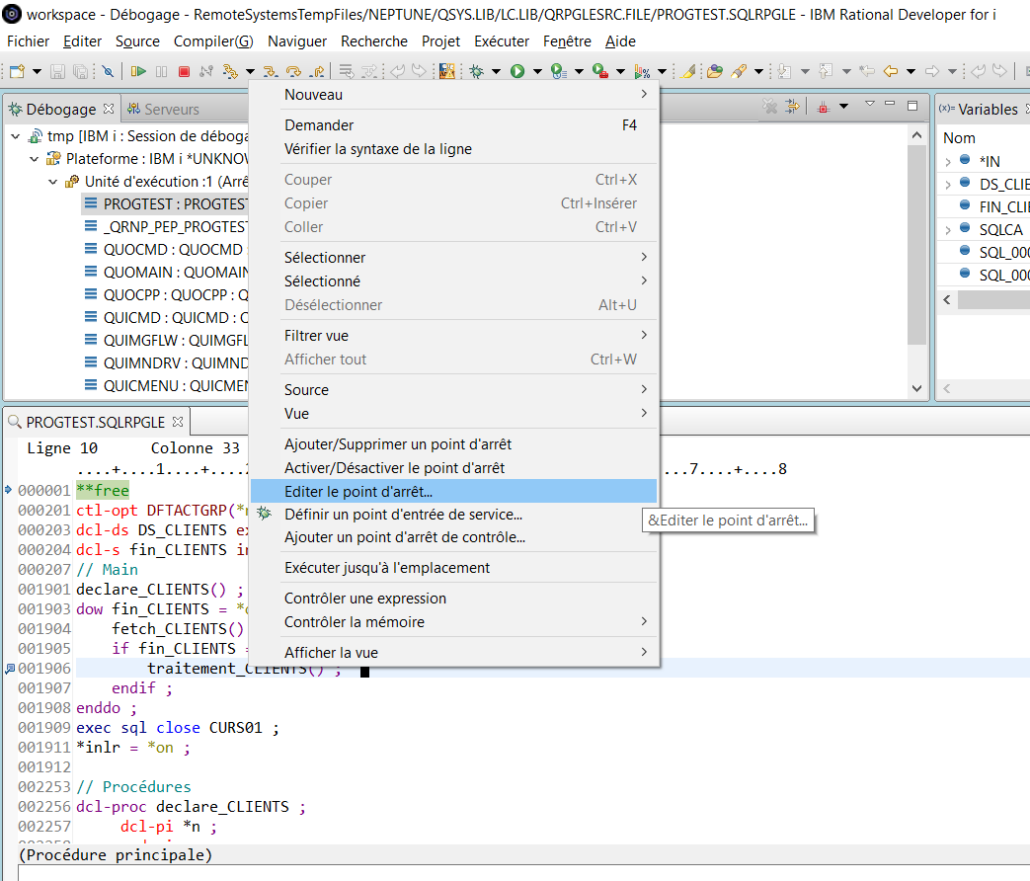
Clic droit sur le point d’arrêt + Editer le point d’arrêt :
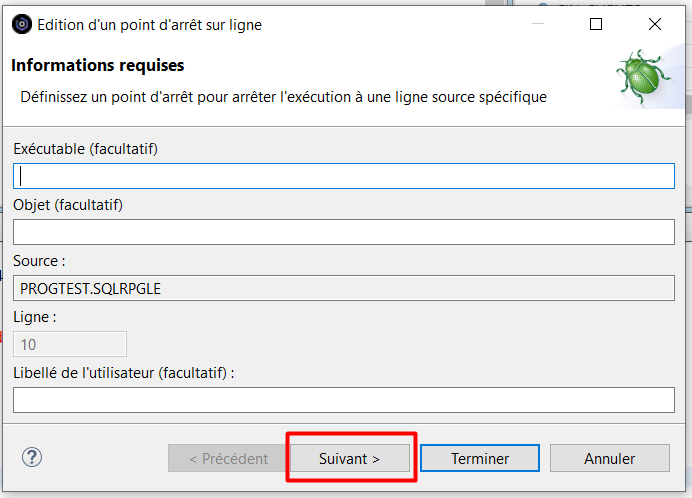
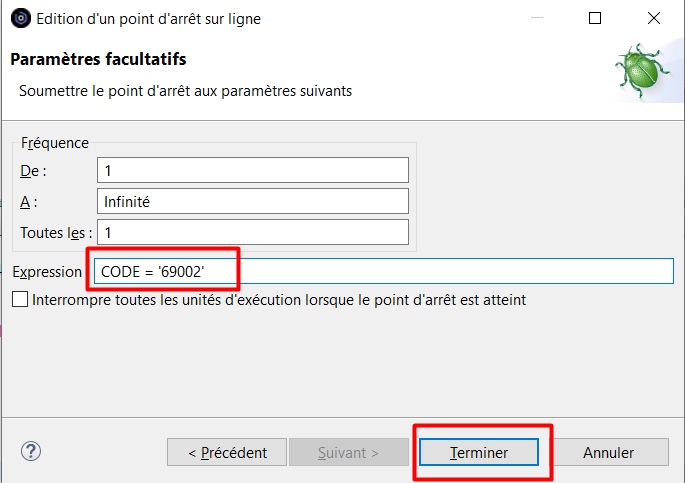
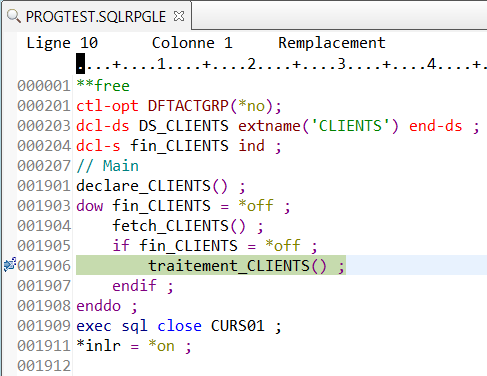
La condition d’arrêt doit être indiquée sur la ligne « Expression » :
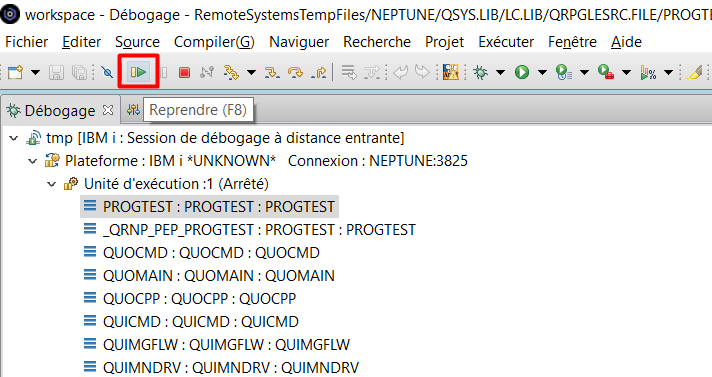
On reprend ensuite l’exécution du programme :
Le programme s’arrête sur notre point d’arrêt pour le client 69002 :
F8=Reprendre –> le programme s’exécute jusqu’à la fin sans nouveau point d’arrêt
Il existe un comcept dans SQL sur les tables qui s’appelle les zones cachées. Je vais essayer de vous expliquer ce que c’est.
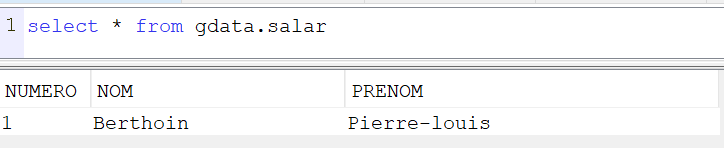
Exemple :
CREATE TABLE SALAR ( NUMERO CHAR(6) CCSID 1147 NOT NULL DEFAULT » , NOM CHAR(20) CCSID 1147 NOT NULL DEFAULT » , PRENOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » , SALAIRE DECIMAL(5, 0) NOT NULL DEFAULT 0 IMPLICITLY HIDDEN )
Pour faire simple ces des zones qui n’apparaîtront pas si vous faites un select *
Il y plusieurs buts à cette démarche , caché sommairement des informations ou simplifier des requêtes en cachant des informations utiles et enfin les zones complétables automatiquement les bien connues date, heure et utilisateur de modification. Maintenant que vous savez ce que c’est je vais vous expliquer l’impact sur vos développements existants. D’abord bien sûr si vous avez des select * dans vos développements ça produira une erreur si vous respectez les règles de développement vous ne devriez pas en avoir. Ensuite sur les insert , par défaut il ne connait que les zones non cachées vous devrez indiquer explicitement les zones cachées que vous voulez alimenter.
Conclusion Ça peut être intéressant dans certains cas pour éviter une vue qui aurait juste pour fonction de limiter les zones. Attention toutefois, si voulez utiliser cette possibilité toutes les zones sont visibles dans les invites Sql …
Et enfin une zone ajoutée même en hidden change le niveau de format puisqu’il est calculé sur l’ensemble des zones.
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-03-15 10:00:392023-03-21 07:01:33Les zones HIDDEN en SQL
L’utilisateur doit avoir un répertoire initial dans l’IFS. (C’est lui qui sera indiqué par le ~ dans les commandes ci-dessous) Produits Open Sources : OpenSSL SFTP
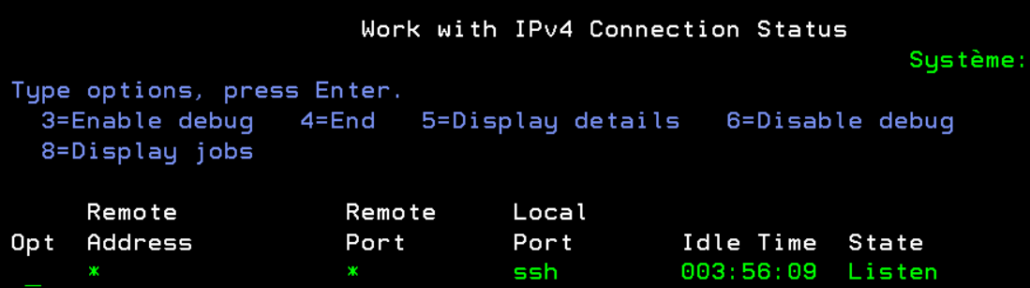
S’assurer que le service SSH est démarré :
Démarrage du service SSH
S’assurer que le service SSH est démarré :
WRKTCPSTS OPTION(*CNN)
S’il n’est pas démarré, via 5250 :
STRTCPSVR SERVER(*SSHD)
Génération des clefs SSH
En 5250 (QSH ou QP2TERM) :
CALL PGM(QP2TERM)
S’il n’exsite pas, on crée le répertoire .ssh, via la commande mkdir, dans le répertoire par défaut de l’utilisateur, on lui attribue les droits de lecture, écriture et execution via la commande chmod, puis on execute la commande ssh-keygen :
Generating public/private rsa key pair.
Your identification has been saved in /home/exploit/.ssh/sftp_key.
Your public key has been saved in /home/exploit/.ssh/sftp_key.pub.
The key fingerprint is:
SHA256:pDxRGtx4YBKbsHTVLpDg8OXyF5VcSBKgfpX4eGXqaGY
The key's randomart image is:
+---[RSA 2048]----+
|. +.**BO++. |
| = Bo*oBB |
| * =.*o+ |
| . o =.O. |
| . + O.S |
| . = . |
| E . |
| + |
| |
+----[SHA256]-----+
Informations supplémentaires :
Options
-t Type de clef créée.
-b Nombres de bits dans la clef créée.
-f Fichier de sortie.
-N Phrase de chiffrement.
Mise en place de la configuration des clefs
Côté client
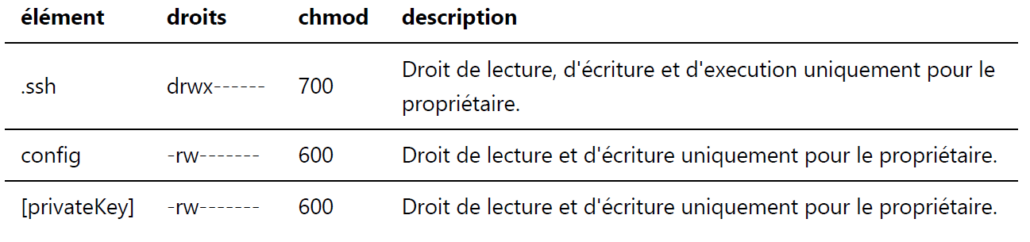
ATTENTION aux droits des fichiers contenus dans le dossier /.ssh qui ne doit contenir, en principe, que les clefs privées et le fichier config (qui est optionnel).
Côté serveur
S’il n’exsite pas, on crée le répertoire .ssh sur le serveur, via la commande mkdir, dans le répertoire par défaut de l’utilisateur, on lui attribue les droits de lecture, écriture et execution via la commande chmod :
mkdir ~/.ssh
chmod 700 ~/.ssh
Déposer la clef publique sur le serveur distant puis, ajouter la clef publique au fichier authorized_keys :
cat [sshKey.pub] >> authorized_keys
Puis vérifier le propriétaire et les droits du fichier authorized_keys:
Les tables de conversion sont des objets de type *TBL
Vous en trouvez un grand nombre dans QSYS ou QUSRSYS les 2 plus connues sont
QEBCDIC *TBL QSYS ASCII TO EBCDIC TRANSLATE TO ASCII QASCII *TBL QSYS EBCDIC TO ASCII TRANSLATE TO EBCDIC
elles servent à convertir une donnée, elle sont utilisées dans certaines commandes FTP ou QUERY Etc …
Vous pouvez également les utiliser vous dans vos développements (bien qu’aujourd’hui SQL semble une meilleur alternative)
Imaginons que vous voulez crypter quelque chose par exemple dans une field proc et que pour vous l’utilisation des API Qc3EncryptData et Qc3DecryptData soit un peu compliqué.
Vous pouvez utiliser cette solution c’est pas le top mais la multiplication des moyens de cryptage ralenti les hackers …
Vous devrez donc créer votre table de conversion dans un fichier source le plus souvent QTBLSRC
Vous devez alors compiler votre table par la commande CRTTBL …
j’ai choisi pour mon exercice de faire une table alternative, la première fois elle crypte la deuxième elle decrypte
il existe une API système qui s’appelle QCDXLATE qui a un format très simple
On se demande souvent comment gérer les paramètres de compile sur les PRTF et les DSPF, il existe plusieurs solutions comme créer des CL de compile par exemple, ou utiliser des ALM qui intègrent cette possibilité. Mais comment faire pour que ca marche tout le temps sans avoir à modifier les commandes de compile
Voici une solution qui a été mise au point pour nos clients du centre de service.
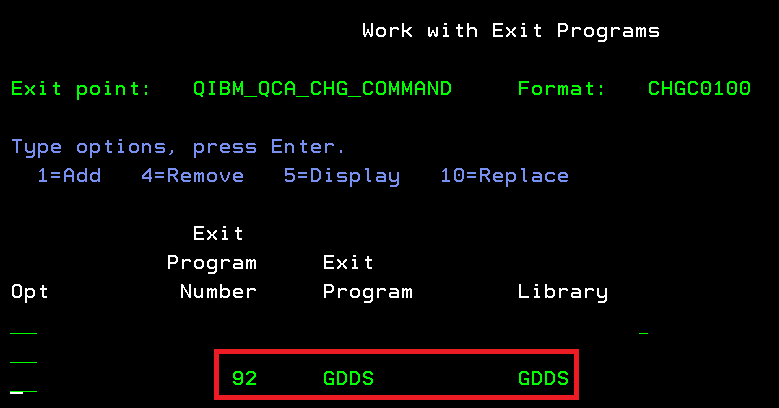
On va utiliser le programme d’exit QIBM_QCA_CHG_COMMAND qui, à chaque fois qu’il verra un CRTPRTF l’interceptera.
Pour éviter que cela ne boucle on devra dupliquer la commande CRTPRTF dans une autre bibliothèque et renvoyer sur celle de QSYS quand on aura fait le paramétrage complémentaire.
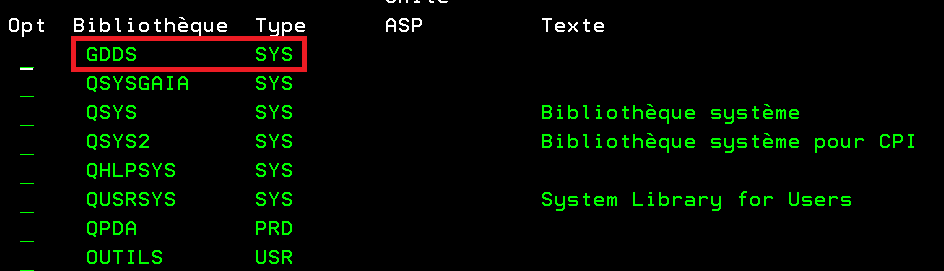
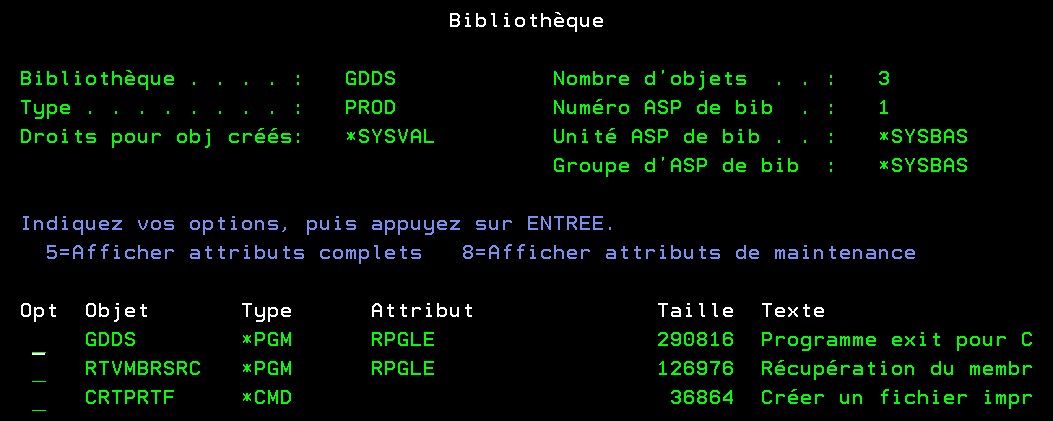
Cette bibliothèque devra donc être devant QSYS dans la liste des bibliothèques, imaginons que cette bibliothèque s’appelle GDDS.
CHGSYSLIBL LIB(GDDS)
soit DSPLIBL
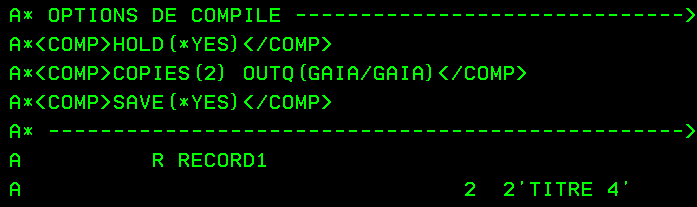
dans le source de votre PRTF vous allez indiquer des lignes commençant par A*<COMP> et terminées par </COMP>
+ votre mot clé exempleSAVE(*YES) Vous pouvez indiquer plusieurs paramètres sur une seule ligne.
Nous avons 2 programmes que vous pouvez retrouver ici, il vous suffit des les compiler et de les ajouter à la bibliothèque GDDS que vous avez placée en tête de liste
Vous avez donc dans votre bibliothèque 2 programmes et une duplication de la commande CRTPRTF et (du CRTDSPF si vous l’ajoutez)
RTVMBRSRC qui va retrouver à partir de la commande le membre source à compiler GDDS qui prendra la commande et qui lui ajoutera les informations lues dans le fichier source c’est ce programme qu’on devra ajouter au programme d’exit comme ceci : ADDEXITPGM EXITPNT(QIBM_QCA_CHG_COMMAND) FORMAT(CHGC0100) PGMNBR(92) PGM(GDDS/GDDS) TEXT(‘Paramétrage GDDS’) PGMDTA(*JOB 20 ‘CRTPRTF GDDS ‘)
Attention au paramètre PGMDTA, la commande fois faire 10 de long pour que le système la trouve
Vous avez un programme CLLE INITGDDS qui peut vous aider dans le répertoire CLP
==>WRKREGINF QIBM_QCA_CHG_COMMAND puis option 8
Avec cette commande, on prendra en compte désormais les CRTPRTF. A partir de ce moment là, quand vous passerez la commande CRTPRTF, vos paramètres indiqués dans le sources seront ajoutés à la commande.
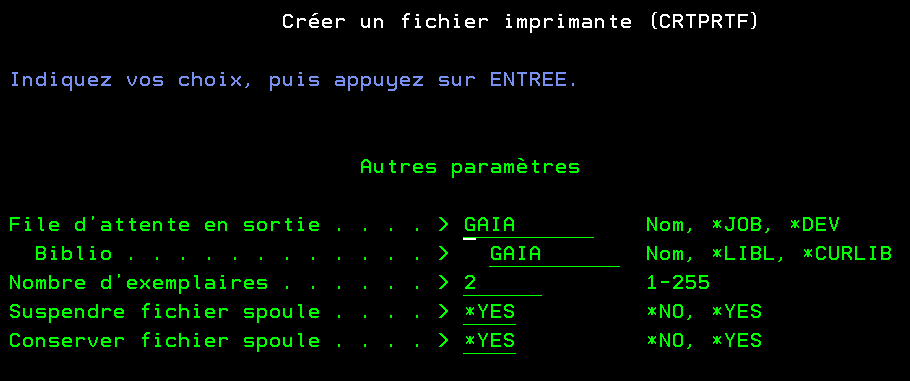
Par exemple en demandant l’invite sur la commande : CRTPRTF FILE(GDATA/PRTF198) SRCFILE(GDATA/QDDSSRC) SRCMBR(*FILE) Vous aurez vos paramètres
Remarque : Vous pouvez indiquer un programme d’exit pour les DSPF (CRTDSPF), et même si vous avez encore quelque PF (CRTPF), les LF (CRTLF) Bien sûr, tous les mots clés que vous indiquez doivent syntaxiquement être justes et correspondre au type de fichier que vous créez. Cette solution marche en interactif, en batch, par RDI et par Vs Code, dans vos CL de compile etc …
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-03-07 05:34:002023-03-07 14:28:16Comment gérer les options de compile des PRTF
Quand on fait des développements, il est parfois nécessaire de verrouiller un programme afin d’empêcher son utilisation par d’autres utilisateurs pendant qu’il est exécuté.
Cependant, il n’est pas possible de verrouiller un programme.
Lorsque on saisit :
Le programme &MONRPG peut être exécuté par un autre utilisateur. Cette commande va verrouiller la description d’objet du programme, mais pas son utilisation.
Alors, comment peut-on gérer le verrouillage d’un programme ?
Une solution possible est d’utiliser une data area qui sera allouée au début du programme avec la commande ALCOBJ. Tant que cette data area sera verrouillée par le travail, aucun autre travail ne pourra se l’allouer.
ATTENTION ! Il est possible de verrouiller à plusieurs reprises le même objet du même travail.
Cette data area restera verrouillée jusqu’à la fin du travail ou jusqu’à ce que on désalloue l’objet avec la commande DLCOBJ (l’objet doit être désalloué autant de fois qu’il a été alloué).
Si l’on ne fait pas DLCOBJ avant ALCOBJ, il peut arriver que :
1. On appelle un programme qu’on a verrouillé par une DTAARA.
2. Le programme plante.
3. L’utilisateur revient dans ce même programme.
4. Il verrouille une fois supplémentaire.
5. Quand il a fini sans problème, il va rester un verrouillage.
Il est donc important de faire DLCOBJ avant un ALCOBJ. Il désalloue ce témoin de verrouillage après usage pour laisser la place libre à un travail suivant.
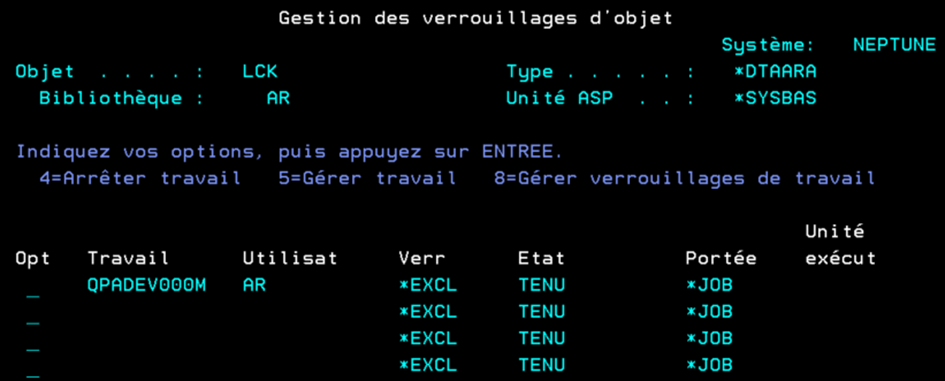
Et finalement, si l’on veut trouver le travail qui alloue, on peut utiliser la vue qsys2.object_lock_info :.
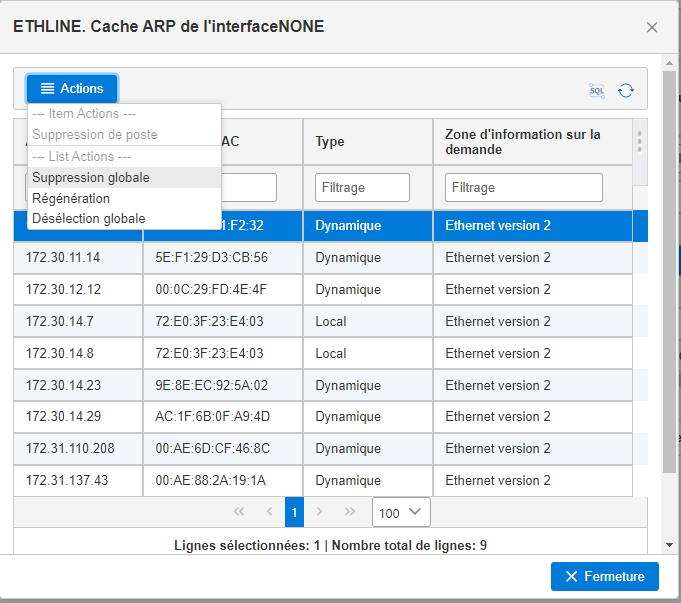
Le cache ARP (Address Resolution Protocol) est une table qui associe une adresse IP à une adresse mac, ces dernières sont utilisées pour les connexions
Le problème qui peut intervenir, c’est si vous changez une adresse IP sur une machine de votre SI, il est possible que cette information pollue votre connexion, n’étant pas mise à jour en temps réel.
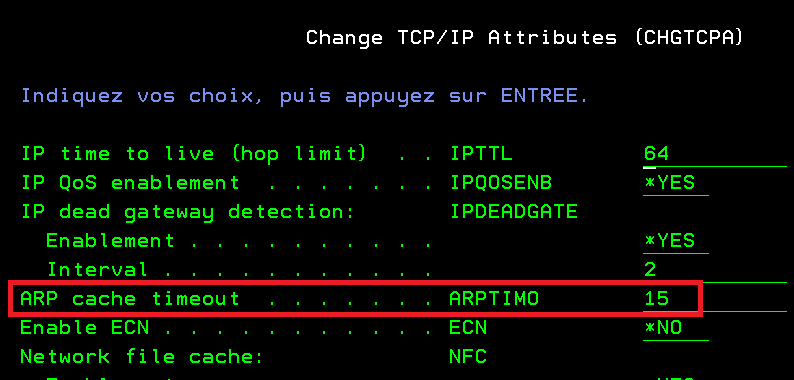
Vous pouvez régler cette fréquence par la commande CHGTCPA.
La valeur est exprimée en minutes et le plus souvent 15 minutes est un bon compromis !
Votre cache est réinitialisée par un IPL ou par un arrêt de TCP/IP c’est un peu brutal, on va voir comment le consulter et comment agir dessus.
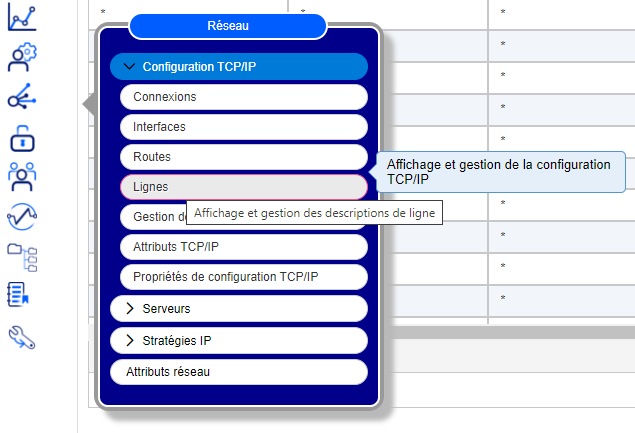
En utilisant navigator for i
Vous devez sélectionner Lignes dans le menu déroulant
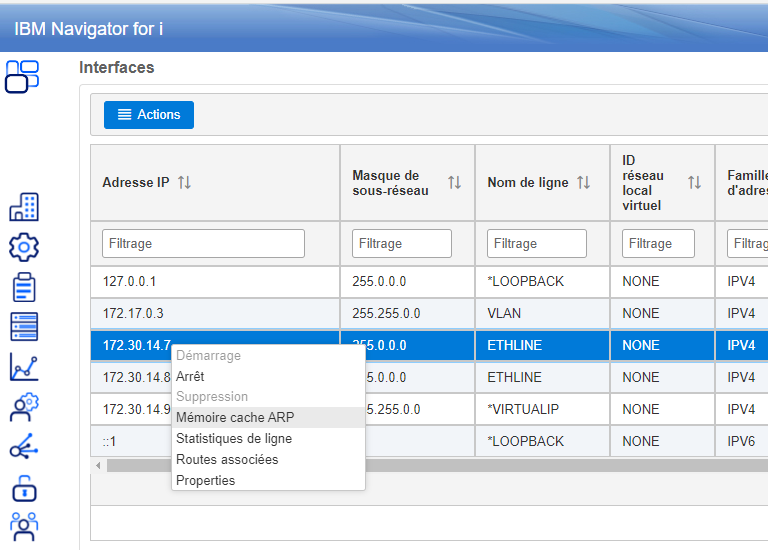
Vous pouvez voir votre cache en cliquant sur Mémoire cache ARP
Vous pouvez supprimer une entrée en cliquant dessus ou même supprimer toutes les entrées en cliquant sur suppression globale
Vous pouvez également intervenir en 5250
Vous pouvez clearer le cache en passant la commande CHGTCPDMN (sans paramètre) https://www.ibm.com/support/pages/dns-query-returning-old-ip-address
Pour le reste il existe des API
par exemple :
QtocRmvARPTblE pour clearer QtocLstPhyIfcARPTbl pour lister les entrées du cache dans un user space
Vous pouvez donc soit coder un outil, soit en récupérer un sur internet on vous met celui qu’on utilise sur mon github.