AdministrationContrôler la taille des résultats de QUERY400
Vous utilisez encore les QUERY/400 et vous souhaitez contrôler la taille du fichier en sortie ? Cette astuce peut vous être utile.
Lorsque vous choisissez en type de sortie un fichier base de données, par défaut, le fichier est taillé en *NOMAX. Il peut arriver qu’avec une mauvaise jointure que l’on atteigne le million d’enregistrements (voir le milliard). Si vous souhaitez limiter la taille de ce fichier en sortie, il vous suffit de créer une DTAARA dans QGPL avec comme nom QQUPRFOPTS puis de définir le nombre d’enregistrements maximum.
/wp-content/uploads/2017/05/logogaia.png00Florian Gradot/wp-content/uploads/2017/05/logogaia.pngFlorian Gradot2024-11-08 08:15:392024-11-12 10:17:10Contrôler la taille des résultats de QUERY400
Sur un formulaire de saisie, on va différencier 3 type de contrôles
1) de valeur
exemple doit contenir 1, 2, 3
2) de cohérence
exemple date de fin > date de debut
3) applicatifs
qui nécessite un accès à une ressource externe
exemple
controler que le client existe
Sur une application de type web, on a un formulaire de saisie et les contrôles 1 et 2 sont faits par javascript et la partie 3 est faite applicativement
Si on considère maintenant un applicatif 5250, on peut faire une grande partie des contrôles 1 directement dans l’écran , la partie 2 et 3 seront faites applicativement
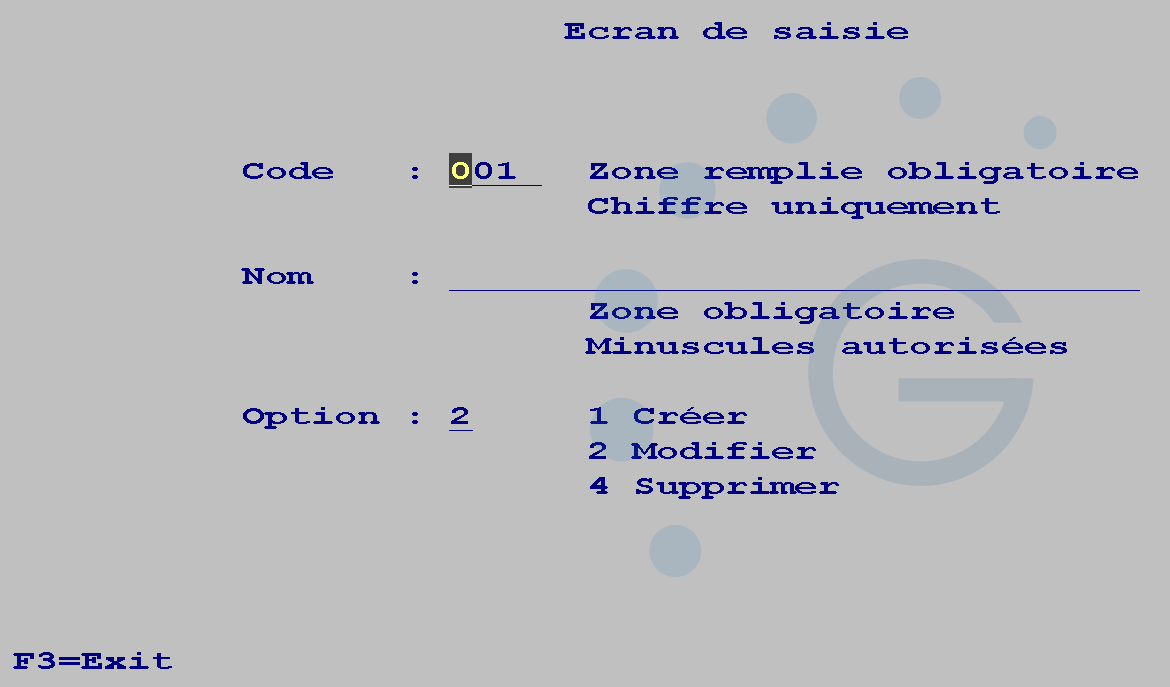
Nous allons prendre un DSPF et faire des controles directement dedans
l’écran DSPF
A*%%TS SD 20241104 105842 PLB REL-V7R4M0 5770-WDS
A*%%EC
A DSPSIZ(24 80 *DS3)
A CA03(03)
A R FMT01
A*%%TS SD 20241104 105842 PLB REL-V7R4M0 5770-WDS
A 4 29'Ecran de saisie'
A 8 15'Code :'
A CODE 4A B 8 24DSPATR(MDT)
A N45 DFTVAL('001')
A CHECK(MF)
A RANGE('0001' '9999')
A 8 30'Zone remplie obligatoire'
A 11 15'Nom :'
A NOM 30A B 11 24CHECK(LC)
A DSPATR(MDT)
A COMP(NE ' ')
A 12 30'Zone obligatoire '
A 13 30'Minuscules autorisées'
A 15 15'Option :'
A OPTION 1N B 15 24VALUES('1' '2' '4')
A N45 DFTVAL('2')
A 15 30'1 Créer'
A 16 30'2 Modifier'
A 17 30'4 Supprimer'
A 22 5'F3=Exit'
A 9 30'Chiffre uniquement'
Nous allons contrôler que la zone CODE est remplie la zone NOM n’est pas vide la zone OPTION doit prendre comme valeur 1, 2 et 4
On dispose des contrôles de saisie souvent des CHECK de validité, COMP, RANGE, VALUE
Pour que le contrôle soit déclenché, la zone devra être modifiée ou on forcera le DSPATR(MDT), pour faire comme si c’était le cas.
Remarque Les contrôles de saisie sont effectués dans tous les cas (CFXX, ENTER, CAXX) Les contrôles de validité sont effectués uniquement dans cas (CFXX, ENTER)
Le programme RPGLE pour tester
**free
ctl-opt DFTACTGRP(*NO) ;
dcl-f Controle WORKSTN ;
dou *in03 ;
exfmt fmt01 ;
if not *in03;
endif ;
// Contrôle des zones
*in45 = *on ;
enddo ;
*inlr = *on ;
Remarque : Dans cet exemple, on utilisera l’indicateur 45 pour ne plus affecter de valeur par défaut
Vous pouvez ainsi simplifier votre application d’une grande partie des contrôles basics
Vous pouvez indiquer , un message différent par le mot clé CHCKMSGID()
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-11-04 13:50:242024-11-04 13:50:24Mettre des contrôles dans un DSPF
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-11-03 11:53:522024-11-04 09:11:40Utilisez de l’Unicode en 5250
zip archive.zip analyse.csv adding: analyse.csv (deflated 84%) $
et par défaut si vous zippez sur une archive existante il ajoute
zip archive.zip xmlversion.txt adding: xmlversion.txt (stored 0%) $
pour voir le résultat
unzip -l archive.zip Archive: archive.zip Length Date Time Name ——— ———- —– —- 9934 2019-03-29 23:44 analyse.csv 17 2019-02-13 10:49 xmlversion.txt ——— ——- 9951 2 files $
Pour vous aider nous proposons une commande ADDTOARCF que vous pouvez retrouver ici https://github.com/Plberthoin/PLB/tree/master/GTOOLS/ un CLLE + un CMD
Remarque :
Vous pouvez ajouter une un fichier à un zip généré par CPYTOARCF Par défaut il créera la l’archive Vous pouvez indiquer des options si elles sont valides dans la commande Zip Vous avez un fichier stdout.log dans votre répertoire courant
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-10-25 11:05:562024-10-25 11:07:21Ajouter des fichiers à une archive ZIP
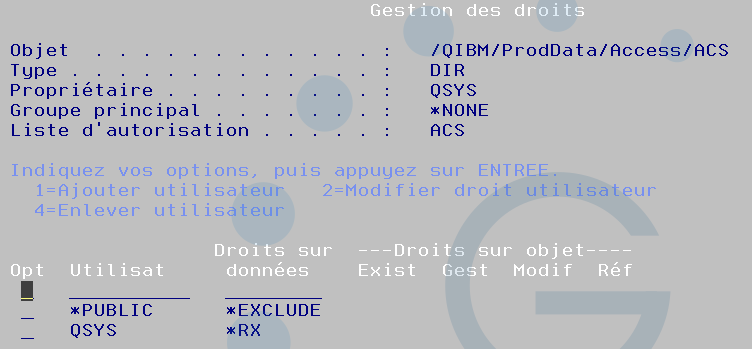
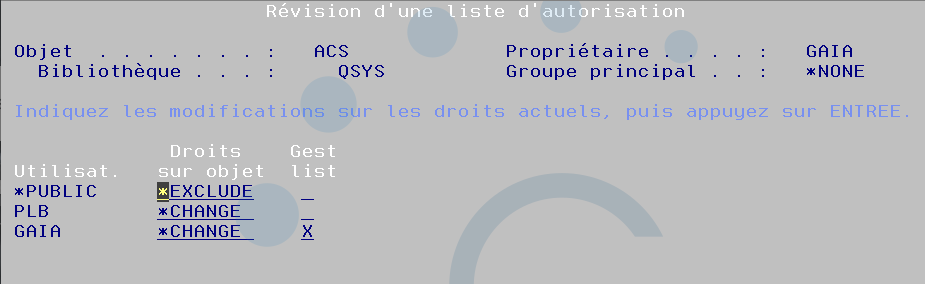
Le répertoire /QIBM/ProdData/Access/ACS est en *PUBLIC *EXCLUDE par défaut. Voici une solution pour ouvrir en gardant la main sur les utilisateurs qui auront droit à cette possibilité
Création de la liste d’autorisation
CRTAUTL AUTL(ACS) TEXT(‘Exécution ACS sur IBMi’)
On considère que votre installation est par défaut, on applique la liste dessus
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-10-16 15:30:142024-10-25 11:11:27Exécuter ACS à partir de votre partition
Vous êtes en train d’analyser votre data base et vous voulez mettre en place des relations sur celle-ci.
Je vais vous re présenter les contraintes d’intégralité référentielles et plus précisément pour voir et comprendre les données en attente de validation .
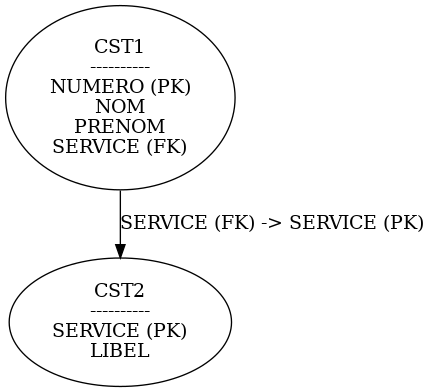
Voici un petit exemple pour illustrer : Considérons un fichier pour les employés et un pour les services services :
Création du fichier des services CREATE OR REPLACE TABLE GDATA.CST2 ( SERVICE CHAR(3) CCSID 1147 NOT NULL DEFAULT » , LIBEL CHAR(30) CCSID 1147 NOT NULL DEFAULT » , CONSTRAINT GDATA.Q_GDATA_CST2_SERVICE_00001 PRIMARY KEY( SERVICE ) )
RCDFMT CST2F ;
1/ Création du fichier des employés avec une contrainte
CREATE OR REPLACE TABLE GDATA.CST1 (
NUMERO DECIMAL(5, 0) NOT NULL DEFAULT 0 , NOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » , PRENOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » , SERVICE CHAR(3) CCSID 1147 NOT NULL DEFAULT » , PRIMARY KEY( NUMERO ) , CONSTRAINT GDATA.Q_GDATA_CST1_SERVICE_00001 FOREIGN KEY( SERVICE ) REFERENCES GDATA.CST2 ( SERVICE ) ON DELETE NO ACTION ON UPDATE NO ACTION )
RCDFMT CST1F ;
Vous pouvez ajouter la contrainte ultérieurement avec
ALTER TABLE GDATA.CST1 ADD CONSTRAINT GDATA.Q_GDATA_CST1_SERVICE_00001 FOREIGN KEY( SERVICE ) REFERENCES GDATA.CST2 ( SERVICE ) ON DELETE NO ACTION ON UPDATE NO ACTION ;
2/ Alimentation des données
Création des services
INSERT INTO GDATA/CST2 VALUES(‘COM’, ‘Comptabilité’) INSERT INTO GDATA/CST2 VALUES(‘PRO’, ‘Production ‘)
Création des employés
INSERT INTO GDATA/CST1 VALUES(01, ‘Berthoin’, ‘Pierre-Louis’, ‘COM’) INSERT INTO GDATA/CST1 VALUES(02, ‘Berthoin’, ‘Younes ‘, ‘PRO’)
Sur une insertion avec service inexistant, un message d’erreur est produit
INSERT INTO GDATA/CST1 VALUES(03, ‘Berthoin’, ‘Yasmine ‘, ‘CRP’)
ID message . . . . . . : SQL0530
Message . . . . : Opération non admise par la contrainte référentielle Q_GDATA_CST1_SERVICE_00001 de GDATA.
Sur une suppression de service avec des employés liés, un message d’erreur est produit
DELETE FROM GDATA/CST2 WHERE SERVICE = ‘PRO’
ID message . . . . . . : SQL0532
Message . . . . : Suppression impossible à cause de la contrainte référentielle Q_GDATA_CST1_SERVICE_00001 de GDATA.
Pas de service SQL mais un peu d’astuce et c’est ok
Il suffit de chercher les employés avec un service inexistant
CREATE TABLE QTEMP.ATTENTES AS (SELECT * FROM GDATA.CST1 A WHERE NOT EXISTS ( SELECT * FROM GDATA.CST2 B WHERE A.SERVICE = B.SERVICE AND B.SERVICE IS NOT NULL)) WITH DATA;
Remarque :
Vous pouvez passer cette commande avant de mettre en œuvre votre contrainte ! Vous pourrez ainsi mettre des relations dans votre application sans risque
Vous pouvez ensuite utiliser, un outil de modélisation :
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-10-14 14:55:212024-10-15 10:27:15Mettez des relations dans votre DB
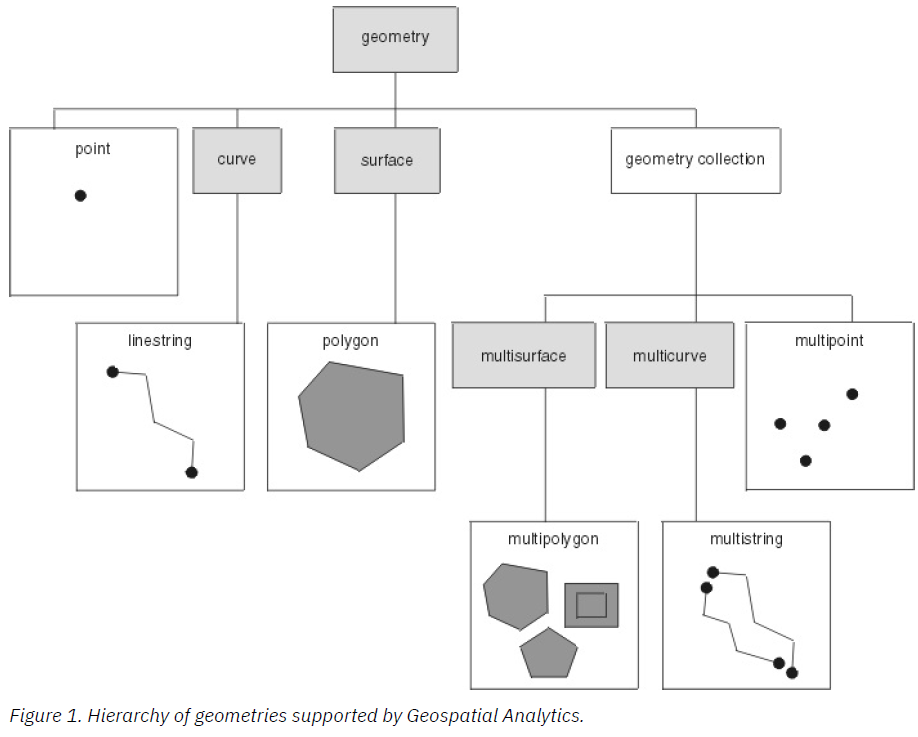
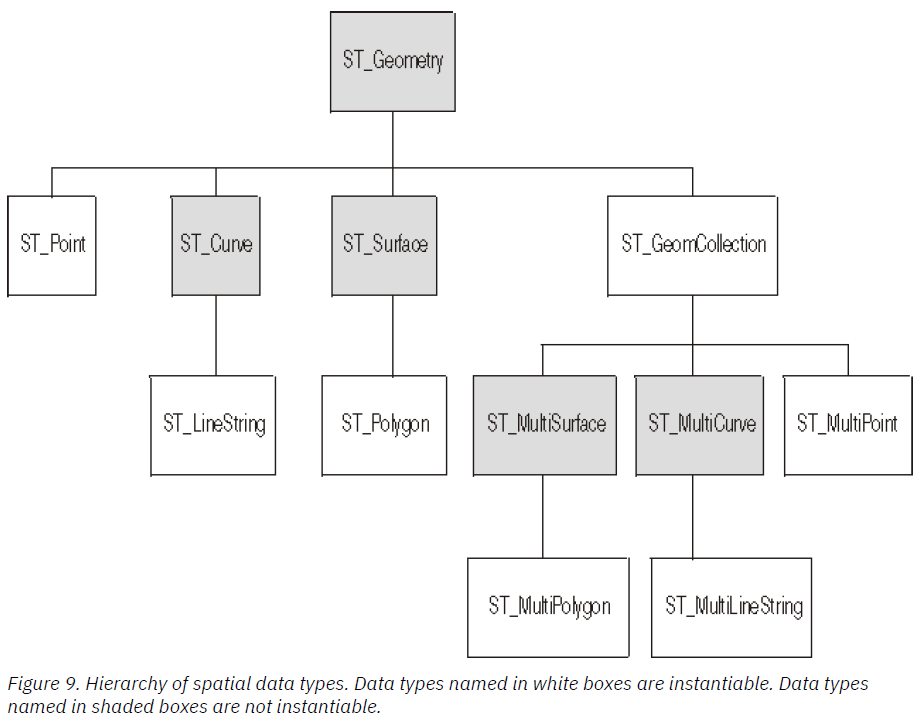
Concernant les fichiers JSON, on observe plusieurs types de géométries, principalement POLYGON et MULTIPOLYGON. C’est pourquoi il nous faut définir dans nos fichiers, une colonne qui puisse englober plusieurs types de géométries. Pour ce faire, le document Database Geospatial Analytics nous fournit quelques informations …
Nous choisirons donc, pour nos fichiers, une colonne basée sur la fonction ST_GEOMETRY, qui nous permet d’englober les deux type nommés ci-dessus. Voici donc comment nous constituerons nos tables.
-- Table des états américains
CREATE TABLE GGEOLOC.US_STATES (
STATE_ID CHAR(2) PRIMARY KEY,
STATE_FULL_NAME VARCHAR(50),
STATE_GEO QSYS2.ST_GEOMETRY);
-- Table des pays
CREATE TABLE GGEOLOC.COUNTRIES (
CODE_ISO VARCHAR(3) PRIMARY KEY,
NAME VARCHAR(50),
CNTRY_GEO QSYS2.ST_GEOMETRY);
-- Table des villes
CREATE TABLE GGEOLOC.MYCITIES (
CTY_NAME VARCHAR(50) ,
CTY_GEO QSYS2.ST_GEOMETRY);
Cet article étant dédié aux fonctions géospatiales, nous n’expliciterons pas la récupération des données.
Bienvenue à bord
ST_ISSIMPLE & ST_GEOMETRYTYPE …
… attachez vos ceintures
ST_ISSIMPLE nous permet de savoir si la géométrie de la figure sélectionnée est simple (valeur 1) ou bon (valeur 0).
SELECT STATE_FULL_NAME,
CASE QSYS2.ST_ISSIMPLE(STATE_GEO)
WHEN 0 THEN 'Geometry is not simple'
WHEN 1 THEN 'Geometry is simple'
END
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
Geometry is not simple
Hawaii
Geometry is simple
Illinois
Geometry is simple
Indiana
Geometry is simple
Wisconsin
Geometry is simple
ST_GEOMETRYTYPE nous permet de savoir de quel type de géométrie nous parlons, et nous pouvons donc constater que la simplicité de la géométrie n’a pas de lien avec le caractère « MULTI » de la figure.
SELECT STATE_FULL_NAME, QSYS2.ST_GEOMETRYTYPE(STATE_GEO)
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
ST_MULTIPOLYGON
Hawaii
ST_MULTIPOLYGON
Illinois
ST_POLYGON
Indiana
ST_POLYGON
Wisconsin
ST_POLYGON
ST_ASTEXT & ST_ASBINARY …
… briefing avant décollage
Si nous exécutons une extraction brute de nos données, on ne comprend pas immédiatement
select STATE_ID, STATE_FULL_NAME, STATE_GEO
from GGEOLOC.US_STATES where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'CO');
ST_AREA nous donne la surface en m² d’une aire géographique (POLYGON ou MULTIPOLYGON)
on ajoute une colonne ici pour avoir une idée de l’aire en km²
select STATE_ID, STATE_FULL_NAME, QSYS2.ST_AREA(STATE_GEO), integer(QSYS2.ST_AREA(STATE_GEO)/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'HI');
AL
Alabama
1.3409800288446873E11
134098
AR
Arkansas
1.3838751120399905E11
138387
HI
Hawaii
1.4748657954505682E10
14748
OK
Oklahoma
1.8250255202012402E11
182502
TX
Texas
6.886199875225208E11
688619
ST_BUFFER nous donne les coordonnées d’une surface élargie du nombre de mètres voulus
voici un exemple de calcul de surfaces en élargissant de 1000 m les frontières de deux états
select STATE_ID, STATE_FULL_NAME, integer(QSYS2.ST_AREA(STATE_GEO)/1000000), integer(QSYS2.ST_AREA(QSYS2.ST_BUFFER(STATE_GEO, 1000))/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'AL');
AL
Alabama
134098
135822
OK
Oklahoma
182502
184806
ST_DISJOINT & ST_WITHIN …
… garder le cap
ST_DISJOINT retourne 1 si deux figures n’ont rien en commun.
select CTY_NAME, CODE_ISO
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where QSYS2.ST_DISJOINT(CTY_GEO, CNTRY_GEO) = 0 ;
HELSINKI
FIN
TEGUCIGALPA
HND
NAIROBI
KEN
GUADALAJARA
MEX
COPENHAGEN
DNK
LYON
FRA
NANTES
FRA
OSLO
NOR
ROCHESTER
USA
ST_WITHIN retourne 1 si la première figure est complètement dans la seconde.
Exemple : Une ville est-elle contenue dans un pays ? Un pays est-il contenu dans une ville ?
select CTY_NAME, CODE_ISO, QSYS2.ST_WITHIN(CTY_GEO, CNTRY_GEO), QSYS2.ST_WITHIN(CNTRY_GEO, CTY_GEO)
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where CTY_NAME in ('LYON', 'ROCHESTER') and CODE_ISO in ('FRA', 'USA') ;
LYON
FRA
1
0
ROCHESTER
FRA
0
0
LYON
USA
0
0
ROCHESTER
USA
1
0
ST_INTERSECTS & ST_INTERSECTION …
… passer la frontière
ST_INTERSECTS nous permet de savoir si deux figures ont une intersection (la fonction retourne 1 si tel est le cas)
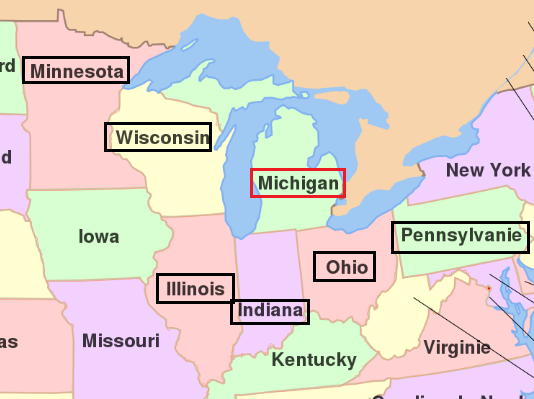
Dans l’exemple suivant, on cherche parmi une liste d’états, à savoir si ceux-ci sont directement voisins du Michigan
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN') ;
Michigan
Illinois
Etats éloignés
Michigan
Indiana
Etats Voisins
Michigan
Minnesota
Etats éloignés
Michigan
Ohio
Etats Voisins
Michigan
Pennsylvania
Etats éloignés
Michigan
Wisconsin
Etats Voisins
Il suffisait de voir la carte pour s’en rendre compte !! Heureusement, ST_INTERSECTION nous en dit beaucoup plus puisqu’elle nous indique la forme de l’intersection entre deux figures géométriques.
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_ASTEXT(QSYS2.ST_INTERSECTION(t1.STATE_GEO, t2.STATE_GEO)),
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
ST_DISTANCE va retourner la distance entre deux points, mais il est intéressant de l’utiliser sur des figures de type POLYGON …
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_DISTANCE(t1.STATE_GEO, t2.STATE_GEO)/1000
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
Michigan
Illinois
58.493941547601004
Michigan
Indiana
0.0
Michigan
Minnesota
33.60195301382611
Michigan
Ohio
0.0
Michigan
Pennsylvania
179.1488383130458
Michigan
Wisconsin
0.0
… pour lesquelles on se rend compte que la fonction retourne la distance (ramenée en km ici) entre les points les plus proches des deux figures comparées.
Atterrissage
Nous n’avons exploré ici qu’une partie des fonctions géospatiales disponibles. Il en existe bien d’autres pour savoir si une figure recouvre complètement une autre, si une figure est contenue dans une autre si une figure en traverse une autre, … Il existe également des fonctions de manipulation des GEOHASHES (système de géocodage basé sur la division d’une zone géographique en cellules).
Bref, tout une panoplie de fonctions que l’on peut combiner à l’infini et au-delà !
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2024-10-09 18:03:122026-01-15 15:04:38LE TOUR DU MONDE EN 10 (+1) FONCTIONS GEOSPATIALES
L’idée n’est pas de rester sur 5250, mais on voit bien que la transition sera longue et pas toujours indolore. il existe des solutions de rewamping chez plusieurs éditeurs
Mais il existe un produit méconnu chez IBM qui s’appelle IBM i Access – Mobile (5770XH2)
Vous pouvez le télécharger sur le site ESS d’IBM
Voici la procédure à suivre pour l’installer est ici
C’est une solution qui peut répondre pour quelques utilisateurs nomades, qui se connectent occasionnellement. Vous n’avez pas de clients à déployer et vous utilisez des mécanismes de gestion purement #IBMi
pgm parm(&return &data) /*---------------------------------------*/
/* ce programme vérifie que l'utilisateur de connexion n'est pas */
/* desactivé */
/* Mise en Oeuvre */
/* CHGNETA DDMACC(EXPLOIT/DRDAEXIT) */
/*---------------------------------------------------------------*/
DCLPRCOPT USRPRF(*OWNER)
dcl &return *char 1
dcl &data *char 200
dcl &status *char 10
DCL VAR(&USER) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&DATA 1)
DCL VAR(&APP ) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&DATA 11)
DCL VAR(&func) TYPE(*CHAR) STG(*DEFINED) LEN(10) +
DEFVAR(&DATA 21)
/* si profil desactivé on refuse */
RTVUSRPRF USRPRF(&USER) STATUS(&STATUS)
if cond(&user = '*DISABLED') then(do)
chgvar &return '0'
enddo
else do
chgvar &return '1'
enddo
endpgm
Remarque :
Vous pourrez ajouter d’autres contrôles , par exemple, par rapport au planning d’activation des profils Votre programme devra être compiler en adoption de droit, avec un profil de droit *SECADM pour avoir droit à la commande RTVUSRPRF
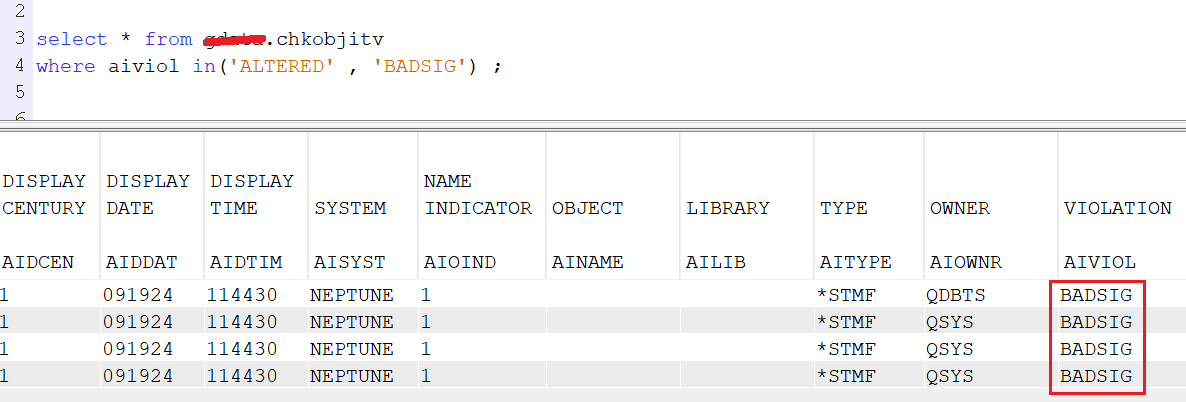
Vous pouvez retrouver ces violations c’est la zone aiviol
Sur les programmes , programmes de service etc …
ALTERED – L’objet a été falsifié. BADSIG – L’objet a une signature numérique qui n’est pas valide. DMN – Le domaine n’est pas correct pour le type d’objet. PGMMOD – L’objet exécutable a été falsifié. BADLIBUPDA – L’attribut de protection de la bibliothèque n’est pas défini correctement. SCANFSFAIL – L’objet a été analysé par un programme de sortie lié à l’analyse et, au moment de cette dernière demande d’analyse, l’objet a échoué à l’analyse. Si une violation est enregistrée pour un module de microcode sous licence, le nom de l’objet sera le nom RU à 8 caractères, où le nom RU est le nom d’unité remplaçable du module de microcode sous licence, le nom de la bibliothèque sera vide et le type d’objet sera *LIC. Si une violation de ce type est rencontrée, contactez votre représentant de service pour récupérer.
Sur les fichiers
NOSIG – L’objet peut être signé mais ne possède pas de signature numérique. NOTCHECKED – L’objet ne peut pas être vérifié, il est en mode débogage, enregistré avec de l’espace de stockage libéré ou compressé. NOTTRANS – L’objet n’a pas été converti au format actuel ou n’est pas compatible avec la version, la version et le niveau de modification actuels.
Si après votre analyse vous avez des objets ALTERED ou BADSIG essayez de comprendre ce que c’est Vous aurez beaucoup de NOTTRANS, ils ne sont pas très grave ?
Comment s’en prémunir pour ne plus injecter d’objet non conformes ?
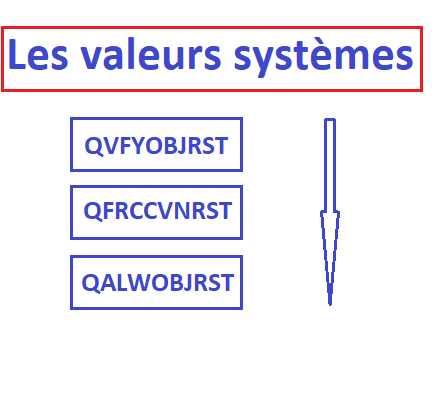
il y a 3 valeurs systèmes à régler
QVFYOBJRST Vérification de l’objet à la restauration
QFRCCVNRST Forçage de la conversion à la restauration
QALWOBJRST Option de restauration des objets sensibles
Voici l’ordre dans lequel , elles s’enchainent
Attention faites des tests
Vous pourrez alors suivre par les audits ces violations par exemple les types GR,OR,RA,RJ,RO,RP,RQ,RU,RZ sur les restaurations mais pas que …
Conclusion:
Pas de panique, mais on peut trouver des choses bizarres demandez des explications à vos fournisseurs de logiciels et attention cependant aux objets de domaine *SYSTEM, si vous en avez dans la liste vous devez agir
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-09-22 09:17:572024-09-23 08:37:54Intégrité des objets sur votre partition