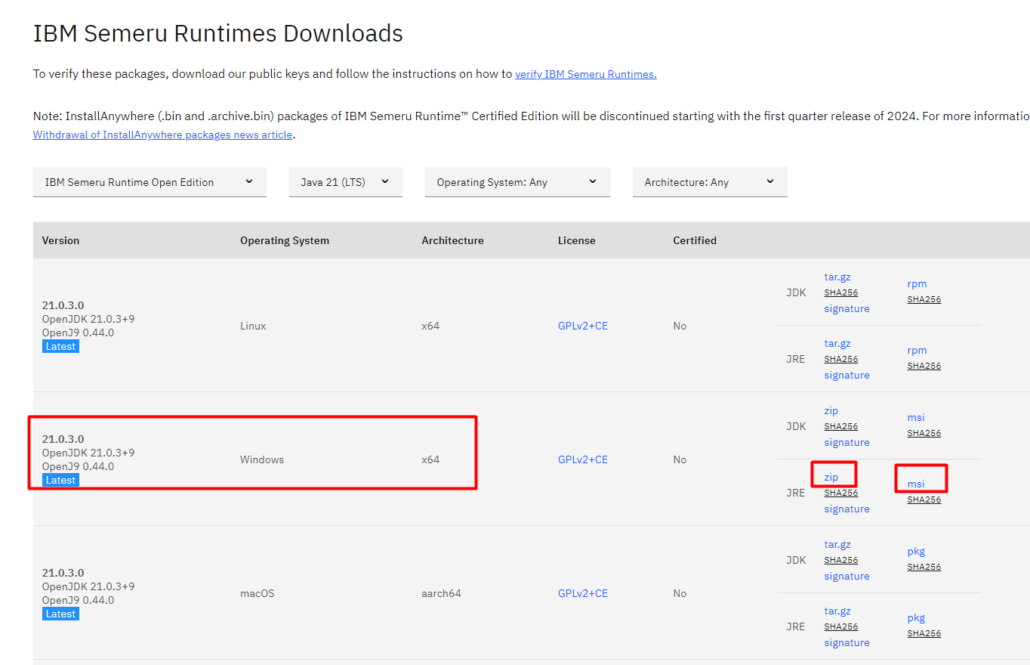
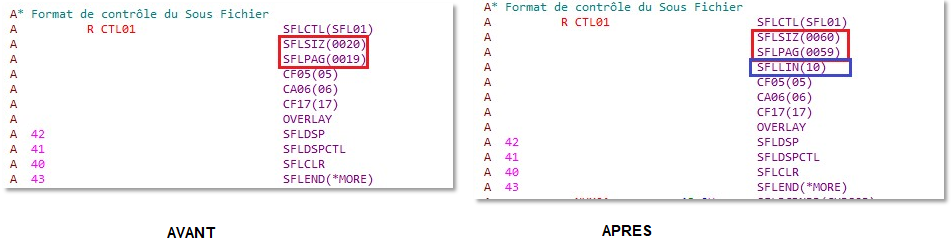
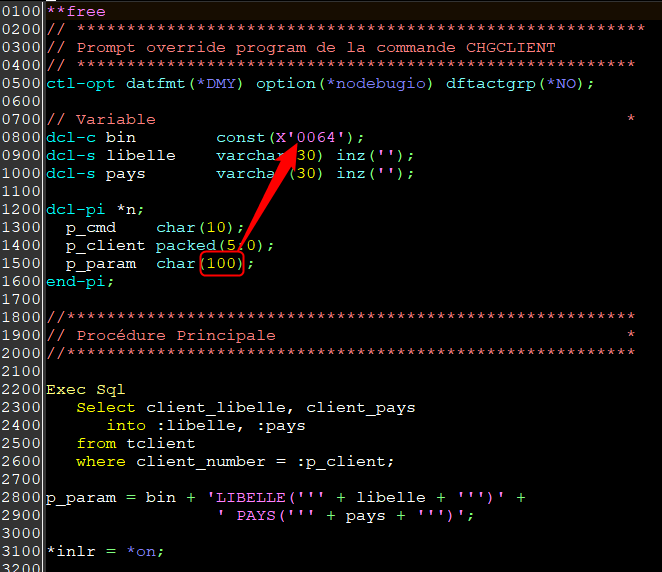
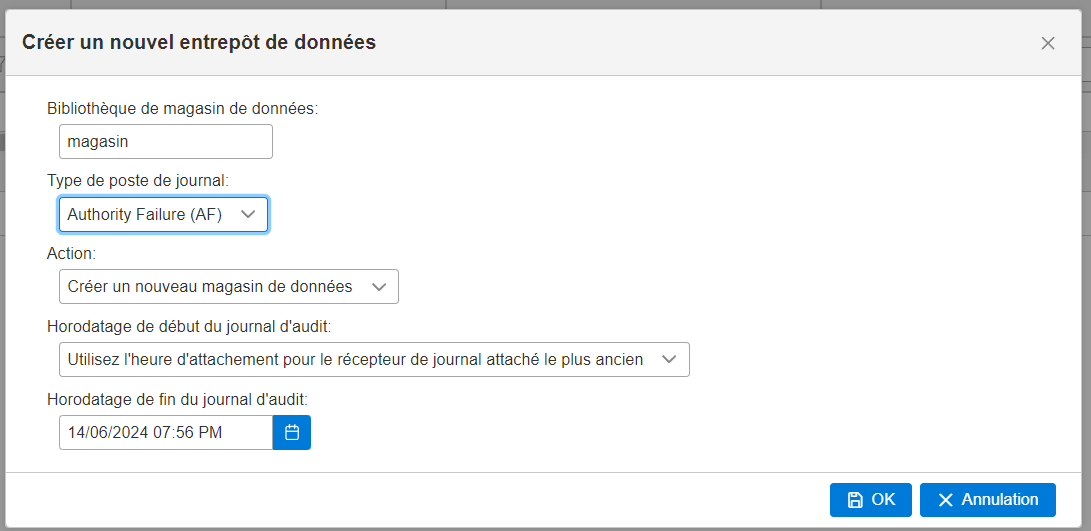
Vous voulez créer un trigger qui vous indique la création d’un enregistrement dans un fichier par exemple pour superviser, dans notre exemple on enverra un email , il est conseillé de faire un fichier de paramétrage
En CLLE soit le programme Alerte_msg
PGM PARM(&BUFFER &BUFLEN)
/* Paramètres */
DCL VAR(&BUFFER) TYPE(*CHAR) LEN(200)
DCL VAR(&BUFLEN) TYPE(*CHAR) LEN(4)
/* Variables de travail */
DCL VAR(&USR) TYPE(*CHAR) LEN(10)
DCL VAR(&JOB) TYPE(*CHAR) LEN(10)
DCL VAR(&NBR) TYPE(*CHAR) LEN(06)
DCL VAR(&EMAIL) TYPE(*CHAR) LEN(50)
DCL VAR(&SUJET) TYPE(*CHAR) LEN(100)
DCL VAR(&NOTES) TYPE(*CHAR) LEN(200)
RTVJOBA JOB(&JOB) USER(&USR) NBR(&NBR)
CHGVAR VAR(&EMAIL) VALUE('votre@mail.fr')
CHGVAR VAR(&SUJET) VALUE('Enregistrement crée')
CHGVAR VAR(&NOTES) VALUE('Job :' +
*BCAT &NBR *TCAT '/' *TCAT &USR *TCAT '/' +
*TCAT &USR)
SNDSMTPEMM RCP((&EMAIL)) SUBJECT(&SUJET) NOTE(&NOTES) +
CONTENT(*HTML)
MONMSG MSGID(CPF0000) EXEC(GOTO CMDLBL(ERREUR))
goto fin
/* Gestion des erreurs */
erreur:
SNDUSRMSG MSG('Envoi email impossible pour msgint ' +
*bcat &job *bcat &usr *bcat &nbr ) +
MSGTYPE(*INFO)
fin:
ENDPGM Pour attacher votre programme et enregistrer votre trigger
ADDPFTRG FILE(&LIB/REP_VALID) TRGTIME(*AFTER)
TRGEVENT(*INSERT) PGM(&LIB/ALERT_MSG)
TRGLIB(&LIB) &lib sera le nom de votre bibliothèque
En SQL ca créera un programme CEE et ca l’associera au trigger
CREATE OR REPLACE TRIGGER ALERTE_MSG
AFTER INSERT ON REP_VALID
REFERENCING NEW AS N
FOR EACH ROW
MODE DB2ROW
-- email destinataire
BEGIN
DECLARE W_EMAIL CHAR(50);
DECLARE W_SUJET CHAR(100);
DECLARE W_NOTES CHAR(200);
DECLARE EXIT HANDLER FOR SQLSTATE '38501'
RESIGNAL SQLSTATE '38501' SET MESSAGE_TEXT = 'ENVOI MAIL IMPOSSIBLE.';
SET W_NOTES = 'Job : ' concat trim(N.REPNBR)
concat '/' concat trim(N.REPUSER) concat '/' concat trim(N.REPJOB) ;
SET W_EMAIL = 'votre@email.fr' ;
SET W_SUJET = 'Enregistrement crée' ;
CALL QCMDEXC('SNDSMTPEMM RCP((''' concat trim(w_email) concat
''')) SUBJECT(''' concat trim(replace(w_sujet , '''', '"'))
concat ''') NOTE('''
concat trim(replace(W_NOTES , '''' , '"')) concat''') CONTENT(*HTML)') ;
END;
Remarques :
Dans les 2 cas si l’utilisateur n’est pas inscrit à la liste de distribution votre email ne sera pas envoyé
c’est plus simple de gérer l’erreur en CLP.
Si vous devez accéder aux données du buffer ca sera plus rapide et plus simple en SQL ici n.zone
C’est des triggers après , puisque l’information doit être écrite dans tous les cas .