pgm parm(&type)
dcl &type *char 4
dclf qsys/QADSPFFD
/* Recupération du ccsid de la première zone de qadbxref */
DSPFFD FILE(QSYS/QADBXREF) OUTPUT(*OUTFILE) +
OUTFILE(QTEMP/WADSPFFD) /* w */
OVRDBF FILE(QADSPFFD) TOFILE(QTEMP/WADSPFFD) +
LVLCHK(*NO)
RCVF
/* Changement du job au bon CCSID */
chgjob ccsid(&WHCSID)
/* Pour contrôler les objets fournis par IBM qui sont manquants */
if cond(&type = '*CHK') then(do)
CALL QSYS/QSQIBMCHK
enddo
/* Pour corriger */
if cond(&type = '*FIX') then(do)
CALL QSYS/QSQSYSIBM
enddo
dltovr FILE(QADSPFFD)
endpgm
Pour contrôler
==>CTLSRVSQL *CHK
Vous allez avoir ces messages dans la LOG
QSQXRLF OBJECTS FOUND = 55 QSQXRLF OBJECTS UNKNOWN = 0 QSQXRLF OBJECTS MISSING = 0 QSQSYSIBM OBJECTS FOUND = 716 QSQSYSIBM OBJECTS UNKNOWN = 0 QSQSYSIBM OBJECTS MISSING = 0 SYSTOOLS OBJECTS FOUND = 105 SYSTOOLS OBJECTS UNKNOWN = 0 SYSTOOLS OBJECTS MISSING = 0 TOTAL IBM OBJECTS FOUND = 876 TOTAL IBM OBJECTS UNKNOWN = 0 TOTAL IBM OBJECTS MISSING = 0 QSQIBMCHK – OBJECT VERIFICATION COMPLETE
Si vous avez des erreurs par exemple 1 dans OBJECTS UNKNOWN vous devrez corriger
Pour corriger
==>CTLSRVSQL *FIX
Vous allez avoir ces messages dans la LOG
QSQSYSIBM ASNEEDED PROCESSING SUCCESSFUL FOR 1236 COMPONENTS.
Ps Vous n’avez pas besoin d’être en mode restreint Mais vous devez être *SECADM et *ALLOBJ
Pour en savoir plus https://www.ibm.com/support/pages/qsqibmchk-tool
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-04-18 13:44:082025-04-18 13:44:09Contrôler la cohérences des services SQL
Le pivot est une technique que vous permet de faire pivoter la sortie d’une requête de ligne à colonne et inversement.
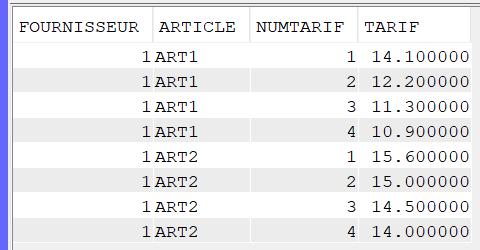
Comme par exemple transformer ce résultat :
Par ce résultat :
Commençons par la création des tables
Imaginons que nous avons un ancien fichier des tarifs contenant 4 tarifs (dans 4 colonnes pour la table TARIF_H et 4 enregistrements pour la table TARIF_V)
TARIF_H : Table avec des tarifs sur une seule ligne mais dans plusieurs colonnes
Utilisation du mot clé LATERAL pour faire une jointure LATERAL et afficher les tarifs sur plusieurs lignes. Nous allons la combiner avec la fonction VALUE ce qui nous permettra d’ajouter une colonne avec la position du tarif (Tarif colonne 1 = position tarif 1, Tarif colonne 2 = position tarif 2 etc…).
select T.fournisseur, T.article, V.POSITIONTARIF, V.VALEURTARIF
from FG.TARIF_H as T,
LATERAL(VALUES (1, T.TARIF1),
(2, T.TARIF2),
(3, T.TARIF3),
(4, T.TARIF4)) as V(POSITIONTARIF, VALEURTARIF)
where FOURNISSEUR = 1;
ps : La clause where n’est pas indispensable pour notre cas.
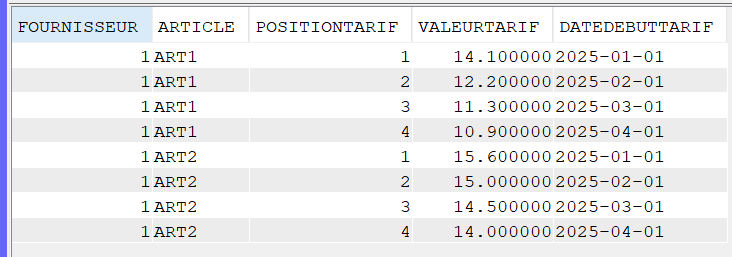
Résultat :
Imaginons que nous avons pour chaque tarif une colonne « date début tarif » (et certainement fin de tarif 🙂 ).
alter table TARIF_H add column DATEDEBUTTARIF1 date;
alter table TARIF_H add column DATEDEBUTTARIF2 date;
alter table TARIF_H add column DATEDEBUTTARIF3 date;
alter table TARIF_H add column DATEDEBUTTARIF4 date;
Il faudra simplement l’ajouter dans la jointure LATERAL ainsi que dans la sélection des zones à afficher :
select T.fournisseur, T.article, V.POSITIONTARIF, V.VALEURTARIF, V.DATEDEBUTTARIF
from FG.TARIF_H as T,
LATERAL(VALUES (1, T.TARIF1, T.DATEDEBUTTARIF1),
(2, T.TARIF2, T.DATEDEBUTTARIF2),
(3, T.TARIF3, T.DATEDEBUTTARIF3),
(4, T.TARIF4, T.DATEDEBUTTARIF4)) as V(POSITIONTARIF, VALEURTARIF, DATEDEBUTTARIF)
where FOURNISSEUR = 1;
Résultat :
Passage d’un affichage vertical à horizontal
Cette fois-ci nous allons utiliser la fonction d’agrégation MAX (même si nous savons qu’il n’y aura qu’un tarif avec le numéro 1, 2, 3 etc…) avec un groupage sur le fournisseur et numéro d’article.
select fournisseur, article,
max(case when numtarif = 1 then tarif end) as Tarif1,
max(case when numtarif = 2 then tarif end) as Tarif2,
max(case when numtarif = 3 then tarif end) as Tarif3,
max(case when numtarif = 4 then tarif end) as Tarif4
from TARIF_V
group by fournisseur, article;
Résultat :
Nous sommes d’accord qu’il existe d’autres méthodes pour faire pivoter des données (listagg etc…).
SQL_DB2Contrôler la liste des utilisateurs inscrits à SMTP via sql
Petits rappels en préambule :
SNA n’est plus à utiliser, on le retrouve pourtant encore très souvent en usage sur de nombreux IBM i. Il faut passer au SMTP.
Les utilisateurs SMTP sont inscrits à un registre.
Pour accéder à ce registre on peut passer par la commande 5250 : WRKSMTPUSR – Work with All SMTP Users.
Si vous ne souhaitez pas inscrire tous vos profils au registre SMTP, il est d’usage de créer un profil NOREPLY afin de l’ajouter au registre, puis de soumettre les envois de mail, exemple :
SBMJOB CMD(SNDSMTPEMM RCP(('julien.laurier@gaia.fr')) SUBJECT(TEST) NOTE('This is not a test.')) USER(NOREPLY)
Lors de l’utilisation de la commande SNDSMTPEMM dans un programme, il est préférable de commencer par contrôler la présence du profil dans le registre SMTP. Ce registre est stocké non pas dans une table mais dans un fichier de configuration dans l’ifs : ‘/QTCPTMM/CONFIG/USERS.DAT’. C’est cette liste qui est affichée par WRKSMTPUSR, malheureusement, ces informations ne sont pas adressables directement via SQL. Il nous revient alors de créer nous même de quoi accéder à ces informations pour simplifier ces usages.
Voici une requête SQL qui permet de parser les informations présentes dans le fichier :
SELECT MAX(CASE WHEN entries.ordinal_position = 1 THEN entries.element END) AS "User profile",
MAX(CASE WHEN entries.ordinal_position = 2 THEN entries.element END) AS "SMTP mailbox alias",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 1 THEN details.element END) AS "Domain index",
MAX(CASE WHEN entries.ordinal_position = 3 AND details.ordinal_position = 2 THEN details.element END) AS "Domain Name",
MAX(CASE WHEN entries.ordinal_position = 4 THEN entries.element END) AS "SDD name compatibility",
MAX(CASE WHEN entries.ordinal_position = 5 THEN entries.element END) AS "SDD address compatibility",
MAX(CASE WHEN entries.ordinal_position = 6 THEN entries.element END) AS "Forwarding to",
MAX(CASE WHEN entries.ordinal_position = 7 THEN entries.element END) AS "Originating from",
MAX(CASE WHEN entries.ordinal_position = 8 THEN entries.element END) AS "Data1",
MAX(CASE WHEN entries.ordinal_position = 9 THEN entries.element END) AS "Data2"
FROM TABLE (qsys2.ifs_read_utf8(path_name => '/QTCPTMM/CONFIG/USERS.DAT',
maximum_line_length => 1024)) AS lines,
TABLE (systools.split(input_list => CAST(lines.line AS VARCHAR(1024)),
delimiter => ' ')) AS entries,
TABLE (systools.split(input_list => CAST(entries.element AS VARCHAR(1024)),
delimiter => ':')) AS details
WHERE line_number > 1
GROUP BY lines.line_number);
Voici un exemple de résultat obtenu :
User profile
SMTP mailbox alias
Domain index
Domain Name
SDD name compatibility
SDD address compatibility
Forwarding to
Originating from
Data1
Data2
FORM01
*NONE
00
*NONE
FORM01
NEPTUNE
*NONE
*NONE
Y
9132
FORM02
*NONE
00
*NONE
FORM02
NEPTUNE
*NONE
*NONE
Y
9134
Pour simplifier encore plus votre usage, je vous propose une vue, ainsi qu’une fonction table :
/wp-content/uploads/2017/05/logogaia.png00Julien/wp-content/uploads/2017/05/logogaia.pngJulien2025-04-07 21:27:092025-04-08 09:47:08Contrôler la liste des utilisateurs inscrits à SMTP via sql
Retour sur une problématique récurrente et souvent mal comprise, donc mal gérée … Et qui pourrait bien s’amplifier avec l’usage plus intensif de l’Open Source.
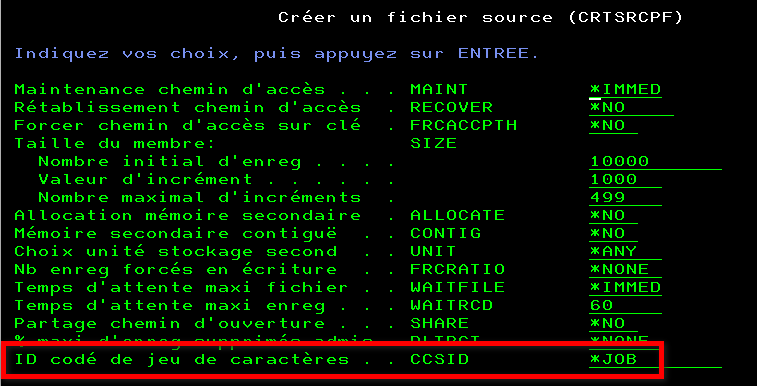
Vous utilisez historiquement des fichiers sources (objet *FILE attribut PF-SRC) pour stocker vos sources : ces fichiers sont créés avec un CCSID, par défaut le CCSID du job dans lequel vous exécutez la commande CRTSRCPF
Usuellement vous obtiendrez des fichiers sources avec un CCSID 297 ou 1147 pour la France. Si vos machines sont « incorrectement » réglées, un CCSID 65535 (hexadécimal).
Mais également, par restauration d’autres produits, certainement des fichiers avec un CCSID 37 (US).
Pour les langages de programmation (dont le SQL), le CCSID du fichier source est important pour les constantes, qui peuvent par définition êtres des caractères nationaux quelconques. Quant aux instructions, la grammaire des langages les définis sans ambiguïtés.
Caractères spéciaux / nationaux
Pour toutes les commandes, instructions, éléments du langage, pas de soucis d’interprétation
A la compilation, les constantes sont interprétées suivant le CCSID du job, pas celui du source !
En général, les deux CCSID sont identiques.
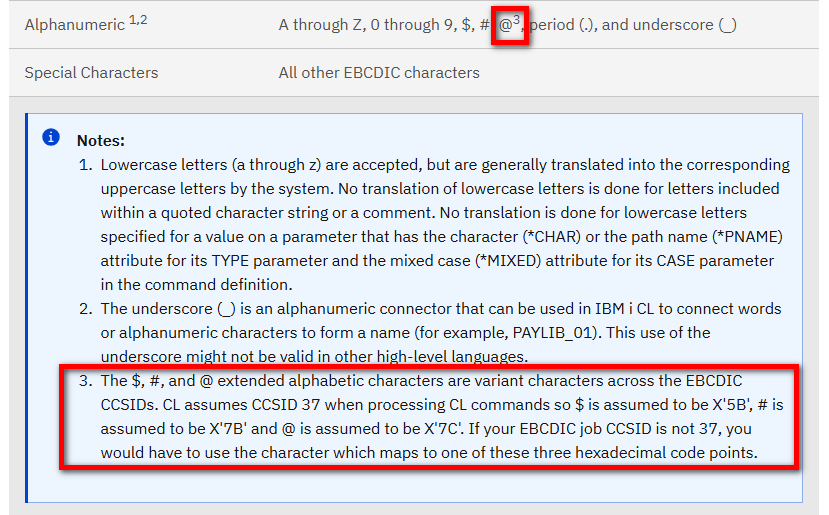
Par contre, pour les caractères spéciaux utilisés, si l’on regarde de plus près le cas du CL, la documentation indique :
Voilà qui explique les fameuses transformations de @ en à !
En synthèse : le compilateur considère tous les éléments du langage comme étant en CCSID 37, hors les constantes alphanumériques et les quelques caractères listés ici.
Pour le CL : impossible d’utiliser les opérateurs symboliques |> (*BCAT), |< (*TCAT) et || (*CAT)
Le caractère | est mal interprété. Vous devez le remplacer par un !, ou utiliser les opérateurs non symboliques (*BCAT, *TCAT et *CAT).
Pour le SQL : impossible d’utiliser l’opérateur || (même raison).
Vous devez le remplacer par un !!, ou utiliser l’opérateur concat.
Evolution du RPG
Le principe est le même.
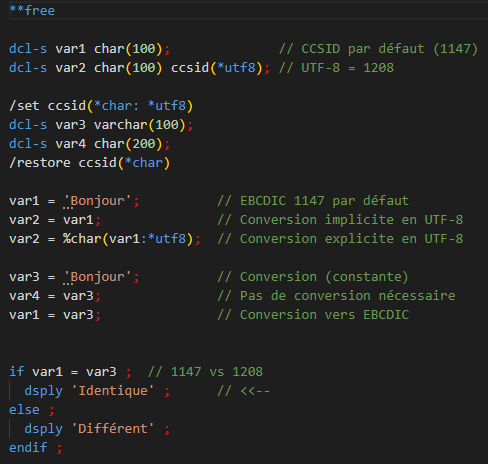
Toutefois le langage vous permet également de contrôler le CCSID des variables déclarées. Et depuis la 7.2, de nouvelles directives de pré-compilation permettent d’indiquer des valeurs de CCSID par défaut par bloc de source :
Et pour l’IFS ?
Sur l’IFS, chaque fichier (source ou non) dispose également d’un CCSID. Sa valeur dépend principalement de la façon de créer le fichier (par un éditeur type RDi/VSCode, partage netserver, transfert FTP …).
Premier point d’attention : l’encodage du contenu du fichier doit correspondre à son attribut *CCSID !
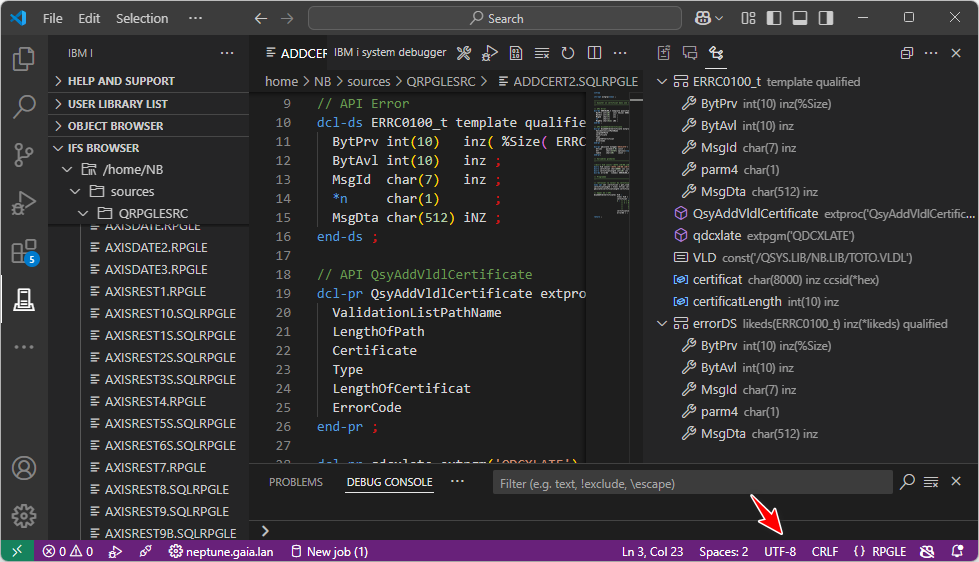
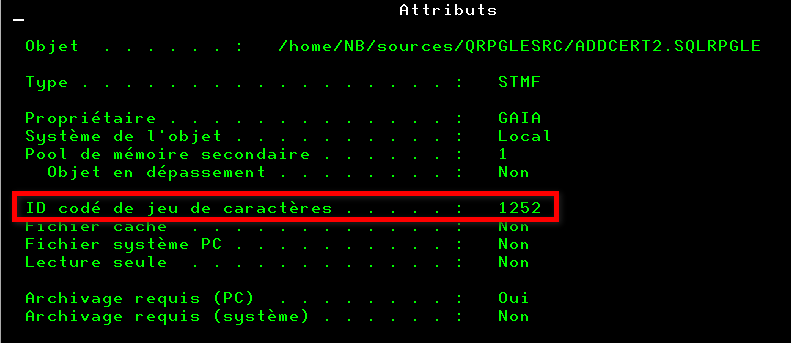
VSCode vous indique le CCSID de la donnée, par exemple :
Mais :
1252 = Windows occidental (proche de l’UTF-8 mais pas identique). La raison est que VSCode travaille naturellement en UTF-8.
RDi gère correctement l’encodage/décodage par rapport à la description du fichier.
Pour les autres outils, à voir au cas par cas !
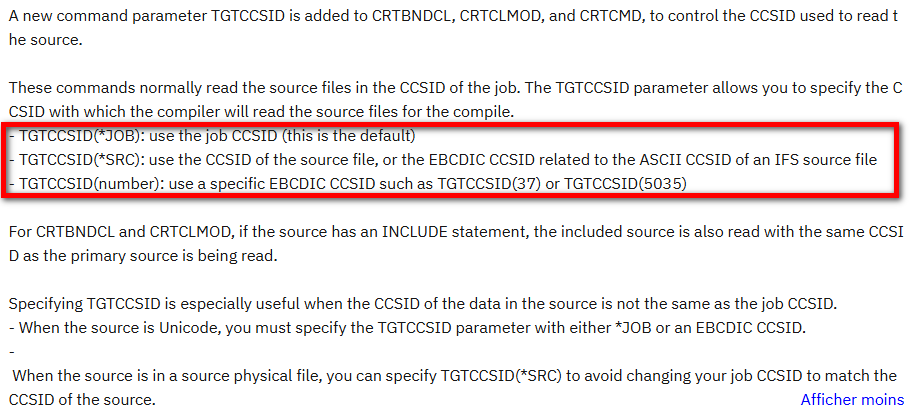
Evolution des compilateurs
Les compilateurs C, CPP, CL, RPG, COBOL supportent désormais (PTF en fonction des compilateurs) un paramètre TGTCCSID :
En réalité ce paramètre a été ajouté pour permettre la compilation plus facilement depuis l’IFS, principalement depuis des fichiers IFS en UTF-8.
Cela ne règle pas nos problèmes précédents, les éléments du langage n’étant pas concernés : nous auront toujours le problème d’interprétation du |
Par contre, c’est utile pour la bonne interprétation des constantes lorsque le job de compilation a un CCSID du source. Et cela permet une meilleure intégration dans les outils d’automatisation.
Le script propose d’indiquer un CCSID pour les fichiers sources. Mais la seule solution viable est de compiler avec un job en CCSID 37 :
soit CHGJOB CCSID(37) avant de lancer le script
soit vous pouvez vous créer un profil dédié en CCSID 37 si ces opérations sont récurrentes
Tant que vous n’avez pas de caractères nationaux dans le codes !
Retrouver le CCSID de ses fichiers sources
SELECT f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA, c."CCSID" FROM qsys2.systables f JOIN qsys2.syscolumns c ON (c.SYSTEM_TABLE_NAME, c.SYSTEM_TABLE_SCHEMA) = (f.SYSTEM_TABLE_NAME, f.SYSTEM_TABLE_SCHEMA) WHERE f.file_type = 'S' AND LEFT(f.system_table_name, 8) <> 'EVFTEMPF' AND c.SYSTEM_COLUMN_NAME = 'SRCDTA' ORDER BY c."CCSID", f.SYSTEM_TABLE_SCHEMA, f.SYSTEM_TABLE_NAME;
Nouveau venu dans les bibliothèques middleware pour IBMi, MAPEPIRE est un outil simple pour récupérer des données de votre serveur et les travailler sur de applications tierces, telles que des outils d’analyse de données, de la bureautique, etc.
Nous allons vous présenter la possibilité d’installer et d’utiliser le produit simplement
sur le serveur
sur votre client, en fonction du langage que vous souhaitez utiliser.
Les langages disponibles pour l’instant sont :
JAVA, NODE.JS, PYTHON
Ici, l’exemple détaillé sera effectué avec le langage PYTHON.
Nous n’intervenons pas dans cet article sur les différents paramétrages de l’outil. Nous y reviendrons dans un article suivant. (exit points, ports, etc.)
Serveur
Installation de MAPEPIRE sur le serveur
yum install mapepire
mapepire sera installé dans le répertoire
/qOpenSys/pkgs/bin
Démarrage
Note : dans cet article, on ne détaille ps le démarrage automatique
nohup /qopensys/pkgs/bin/mapepire &
Client
Notre exemple consiste à lister tous les travaux actifs en cours, les répertorier dans une trame PANDAS, puis de sauvegarder les données dans une feuille EXCEL
Pré requis
Python 3 installé et fonctionnel
un répertoire pour le code
Facultatif : un environnement virtuel
EXCEL
librairies installées :
pandas
openpyxl (factultatif)
installation MAPEPIRE
sous l’environnement virtuel (si configuré) ou sur l’environnement global
pip install mapepire-python
le code de notre exemple TEST.PY
#mapepire
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
#--------------------------------------------------
creds = DaemonServer(
host="serveuràcontacter",
port=8076,
user="utilisateur",
password='motdepasse',
ignoreUnauthorized=True,
)
job = SQLJob()
res = job.connect(creds)
#
# Travaux actifs
#
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
countjobs = result['data'][0]['TOTALTRAVAUX']
startT = datetime.now()
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
endT = datetime.now()
delta = endT - startT
print(f"travaux actifs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframActj = pd.DataFrame(result['data'])
#print(dframActj)
#
#récupération des utilisateurs dans une 2ème Frame (dframUsesrs)
#
startT = datetime.now()
result = job.query_and_run("""
WITH USERS AS (
SELECT
CASE GROUP_ID_NUMBER
WHEN 0 THEN 'USER'
ELSE 'GROUP'
END AS PROFILE_TYPE,
A.*,
CAST(TEXT_DESCRIPTION AS VARCHAR(50) CCSID 1147)
AS TEXT_DESCRIPTION_CASTED
FROM (
SELECT *
FROM QSYS2.USER_INFO
) AS A
)
SELECT *
FROM USERS
""",
rows_to_fetch=500)
endT = datetime.now()
delta = endT - startT
print(f"Utilisateurs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframUsers = pd.DataFrame(result['data'])
#print(dframUsers)
print("Sauvegarde vers Excel")
with pd.ExcelWriter('/users/ericfroehlicher/Documents/donnes_dataframe.xlsx') as writer:
dframActj.to_excel(writer, sheet_name='ACTjobs')
dframUsers.to_excel(writer, sheet_name='Utilisateurs')
Un peu d’explications
1 – Import des resources dont on a besoin
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
2 – Déclaration des données de connexion (serveur, utilisateur, mot def passe)
CONSEIL: pour l’instant, toujours laisser le port 8076
Ici, on crée un travail simple, synchrone (SQLJob)
4 – les requêtes synchrones
#comptage des travaux (pour l'exemple de l'utilisation du json)
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
# je récupère directement la valeur lue
countjobs = result['data'][0]['TOTALTRAVAUX']
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
A
Les données obtenues sont au format JSON. (voir plus bas les données brutes)
5 – Insertion des données dans un frame PANDAS et sauvegarde vers EXCEL
#insertion des résultats dans un Frame PANDAS
dframe = pd.DataFrame(result['data'])
print(dframe)
print("Sauvegarde vers Excel")
dframe.to_excel(
"/users/ericfroehlicher/Documents/travaux_actifs.xlsx",
sheet_name="Travaux actifs",
index=False
)
Retour de mapepire
Le flux de données renvoyé par MAPEPIRE contient l’ensemble des données et méta données au format JSON.
Voici un extrait du flux retourné (exemple sur 5 travaux)
/wp-content/uploads/2017/05/logogaia.png00Eric Froehlicher/wp-content/uploads/2017/05/logogaia.pngEric Froehlicher2025-03-14 16:52:362025-03-14 16:52:37Générer des données avec MAPEPIRE en PYTHON
Vous devez surveiller l’IFS de votre partition et plus particulièrement la partie /home/ ou vous retrouvez les fichiers générés par vos utilisateurs et y faire le ménage régulièrement est une bonne pratique.
Une épuration à 30 jours semble un bon compromis
Voici 2 techniques pour réaliser cette opération
La première est à base d’un script UNIX
Voici un exemple, dans le répertoire /home/maurice/OUT on supprime les fichiers CSV de plus de 10 jours
Cet article est librement inspiré d’une session animée par Birgitta HAUSER lors des universités de l’IBMi du 19 et 20 novembre 2024. Je remercie également Laurent CHAVANEL avec qui j’ai partagé une partie de l’analyse.
Présentation
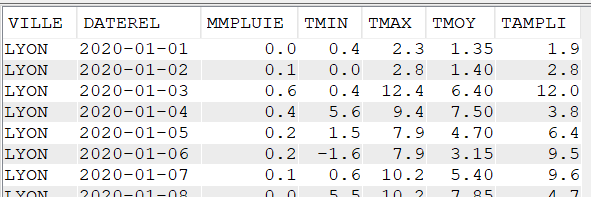
Pour réaliser cet article, nous avons créé un fichier de données météorologiques quotidiennes de quatre villes françaises pendant cinq années (de 2020 à 2024).
Les données contenues dans le fichier CLIMAT sont :
La ville
Le jour (AAAA-MM-JJ)
Les précipitations en mm
La température minimale du jour (en °C)
La température maximale du jour (en °C)
La température moyenne du jour (en °C)
L’amplitude de température du jour (en °C)
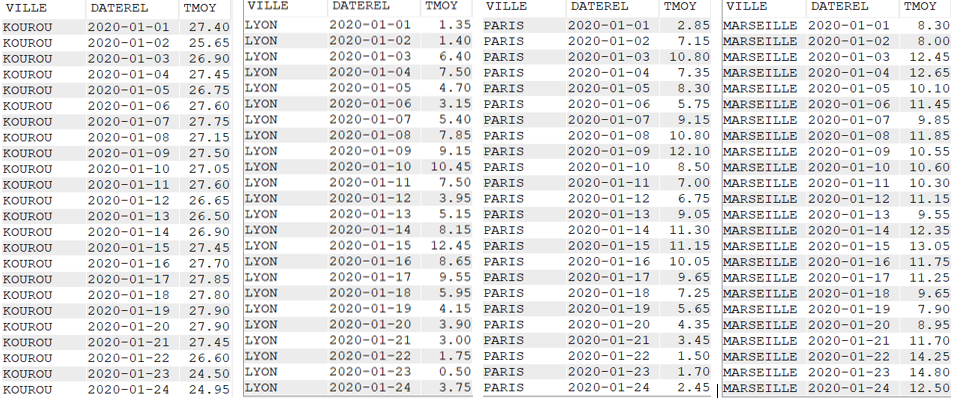
Agréger les données avec LISTAGG
Cette fonction permet de rassembler dans un seul champ, les données issues de plusieurs lignes
SELECT VILLE,
YEAR(DATEREL) Annee,
MONTHNAME(DATEREL) Mois,
LISTAGG(TMOY || '°C', ', ') "Températures moyennes du Mois"
FROM CLIMAT
WHERE YEAR(DATEREL) = 2020
AND MONTH(DATEREL) = 1
GROUP BY VILLE,
YEAR(DATEREL),
MONTHNAME(DATEREL)
Données brutes
Données avec la fonction LISTAGG
Agréger les données avec GROUP BY
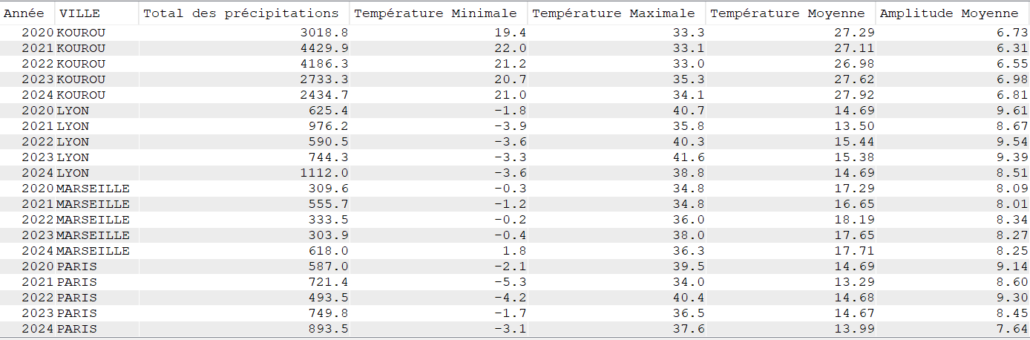
Comme première analyse, on souhaite faire des statistiques annuelles pour chaque ville sur chaque année.
On utilise les fonctions :
SUM qui va nous permettre de faire le total des précipitations
MIN pour extraire la température minimale
MAX pour extraire la température maximale
AVG pour faire une moyenne (de la température ainsi que de l’amplitude des températures)
On notera que TOUTES les colonnes sans fonction d’agrégation doivent être regroupées dans un GROUP BY et nous ajoutons un ORDER BY pour classer nos données.
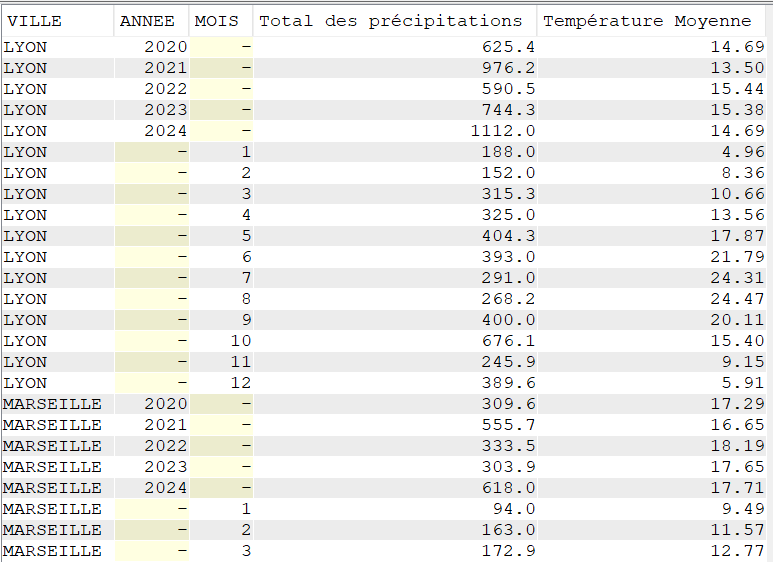
SELECT YEAR(DATEREL) "Année",
VILLE,
SUM(MMPLUIE) "Total des précipitations",
MIN(TMIN) "Température Minimale",
MAX(TMAX) "Température Maximale",
CAST(AVG(TMOY) AS DEC(4, 2)) "Température Moyenne",
CAST(AVG(TAMPLI) AS DEC(4, 2)) "Amplitude Moyenne"
FROM CLIMAT
GROUP BY YEAR(DATEREL),
VILLE
ORDER BY VILLE,
"Année";
Utilisation de ROLLUP
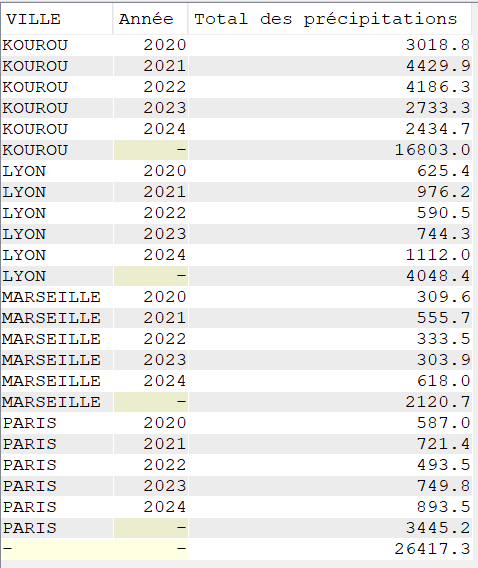
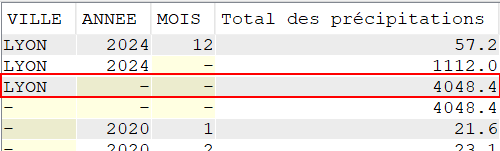
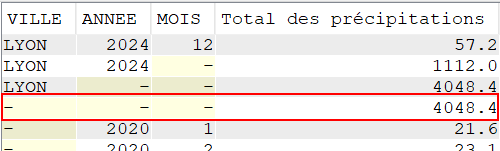
Nous voulons réaliser un total des précipitations sur les cinq dernières années, pour chaque commune de notre fichier tout en conservant un total pour chaque année observée
SELECT VILLE,
YEAR(DATEREL) "Année",
SUM(MMPLUIE) "Total des précipitations"
FROM CLIMAT
GROUP BY ROLLUP (VILLE, YEAR(DATEREL))
ORDER BY VILLE,
"Année";
L’extension ROLLUP apportée au GROUP BY, nous permet d’avoir des sous totaux par :
VILLE / ANNEE
VILLE
Ainsi qu’un total général (ce qui, dans le cas présent n’a que peu d’intérêt, je vous l’accorde)
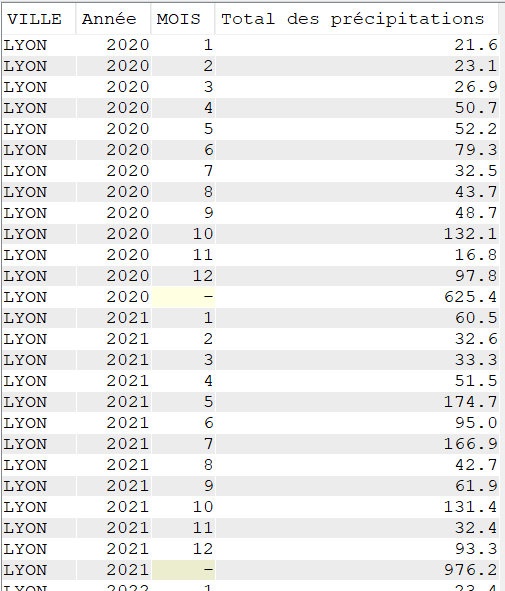
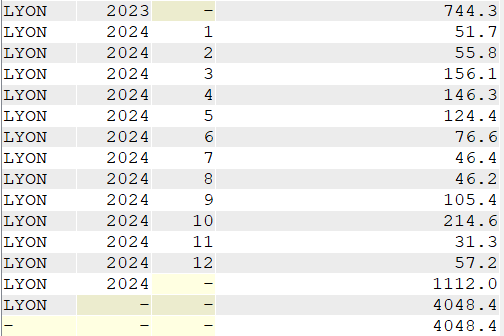
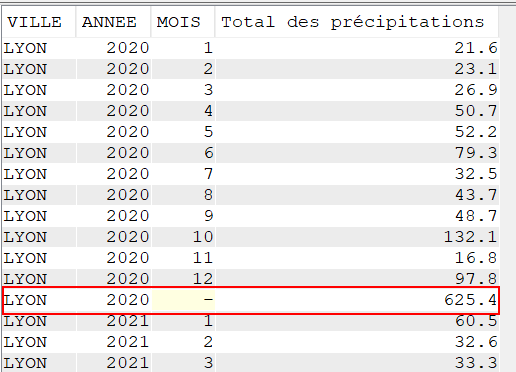
Autre exemple, le total des précipitations par mois pour une seule ville.
SELECT VILLE,
YEAR(DATEREL) "Année",
MONTH(DATEREL) Mois,
SUM(MMPLUIE) "Total des précipitations"
FROM GG.CLIMAT
WHERE VILLE = 'LYON'
GROUP BY ROLLUP (VILLE, YEAR(DATEREL), MONTH(DATEREL));
…
…
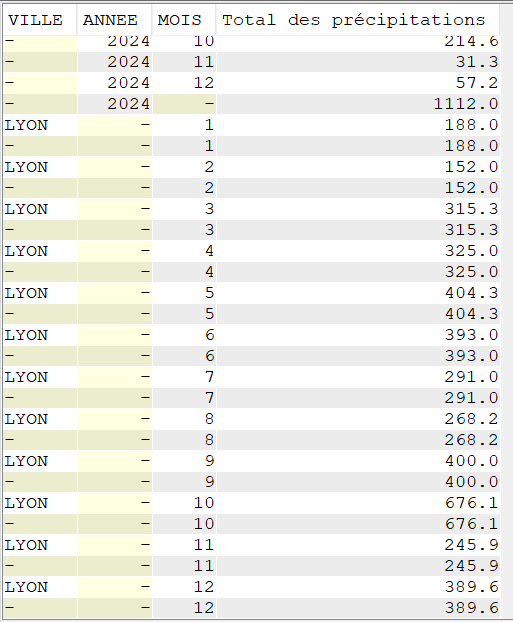
Utilisation de CUBE
Cette extension nous permet d’obtenir plusieurs type de sous-totaux dans une même extraction
SELECT VILLE, YEAR(DATEREL) Annee, MONTH(DATEREL) Mois, SUM(MMPLUIE) "Total des précipitations" FROM CLIMAT WHERE VILLE = 'LYON' GROUP BY CUBE (VILLE, YEAR(DATEREL), MONTH(DATEREL));
Par VILLE et ANNEE
Par VILLE et sur la période de mesure
Sur la période de mesure (valeur identique à la précédente car une seule ville sélectionnée ici)
Par VILLE pour chaque mois de la période sélectionnée (ou simplement pour chaque mois de la période sélectionnée)
Pour Lyon, on a, par exemple, un total de précipitations de 188.00 mm pour tous les mois de janvier ou 400.00 mm pour tous les mois de septembre entre 2020 et 2024
Utilisation de GROUPING SETS
Cette extension permet de faire des regroupements choisis. Cela permet de faire une sélection des regroupements plus fine que celle réalisée avec CUBE.
Select VILLE, Year(DATEREL) Annee, month(DATEREL) Mois,
sum(MMPLUIE) "Total des précipitations",
Cast(Avg(TMOY) as Dec(4, 2)) "Température Moyenne"
From CLIMAT
WHERE VILLE in ('LYON', 'MARSEILLE', 'PARIS')
Group By GROUPING SETS((VILLE, YEAR(DATEREL)), (VILLE, month(DATEREL)))
ORDER BY VILLE, YEAR(DATEREL), month(DATEREL);
Dans cet exemple, on fait des regroupements par VILLE/ANNEES et VILLE/MOIS dans une seule extraction
Tableau Croisé avec Agrégation et CASE
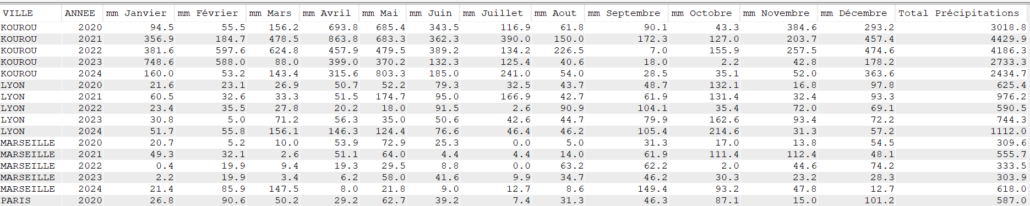
Avec SUM
Select VILLE, Year(DATEREL) Annee,
sum(case when month(DATEREL)= 1 then MMPLUIE else 0 end) as "mm Janvier",
sum(case when month(DATEREL)= 2 then MMPLUIE else 0 end) as "mm Février",
sum(case when month(DATEREL)= 3 then MMPLUIE else 0 end) as "mm Mars",
sum(case when month(DATEREL)= 4 then MMPLUIE else 0 end) as "mm Avril",
sum(case when month(DATEREL)= 5 then MMPLUIE else 0 end) as "mm Mai",
sum(case when month(DATEREL)= 6 then MMPLUIE else 0 end) as "mm Juin",
sum(case when month(DATEREL)= 7 then MMPLUIE else 0 end) as "mm Juillet",
sum(case when month(DATEREL)= 8 then MMPLUIE else 0 end) as "mm Aout",
sum(case when month(DATEREL)= 9 then MMPLUIE else 0 end) as "mm Septembre",
sum(case when month(DATEREL)=10 then MMPLUIE else 0 end) as "mm Octobre",
sum(case when month(DATEREL)=11 then MMPLUIE else 0 end) as "mm Novembre",
sum(case when month(DATEREL)=12 then MMPLUIE else 0 end) as "mm Décembre",
sum(MMPLUIE) as "Total Précipitations"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
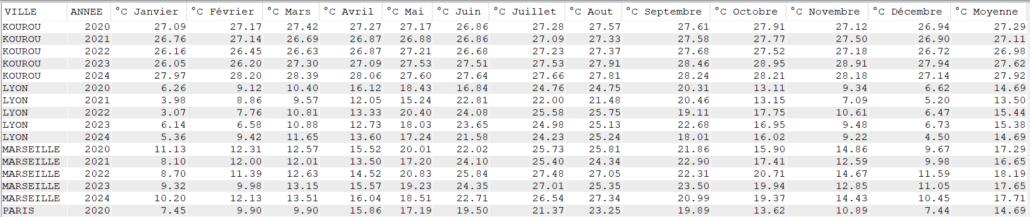
Avec AVG
Select VILLE, Year(DATEREL) Annee,
cast(avg(case when month(DATEREL)= 1 then TMOY else NULL end) as Dec(4, 2)) as "°C Janvier",
cast(avg(case when month(DATEREL)= 2 then TMOY else NULL end) as Dec(4, 2)) as "°C Février",
cast(avg(case when month(DATEREL)= 3 then TMOY else NULL end) as Dec(4, 2)) as "°C Mars",
cast(avg(case when month(DATEREL)= 4 then TMOY else NULL end) as Dec(4, 2)) as "°C Avril",
cast(avg(case when month(DATEREL)= 5 then TMOY else NULL end) as Dec(4, 2)) as "°C Mai",
cast(avg(case when month(DATEREL)= 6 then TMOY else NULL end) as Dec(4, 2)) as "°C Juin",
cast(avg(case when month(DATEREL)= 7 then TMOY else NULL end) as Dec(4, 2)) as "°C Juillet",
cast(avg(case when month(DATEREL)= 8 then TMOY else NULL end) as Dec(4, 2)) as "°C Aout",
cast(avg(case when month(DATEREL)= 9 then TMOY else NULL end) as Dec(4, 2)) as "°C Septembre",
cast(avg(case when month(DATEREL)=10 then TMOY else NULL end) as Dec(4, 2)) as "°C Octobre",
cast(avg(case when month(DATEREL)=11 then TMOY else NULL end) as Dec(4, 2)) as "°C Novembre",
cast(avg(case when month(DATEREL)=12 then TMOY else NULL end) as Dec(4, 2)) as "°C Décembre",
cast(avg(TMOY) as Dec(4, 2)) as "°C Moyenne"
FROM CLIMAT
Group by Ville, Year(DATEREL)
order by Ville, Year(DATEREL);
Note sur l’utilisation de SUM vs AVG dans un tableau croisé
SUM totalise par mois, tandis que AVG calcule la moyenne.
Utilisation de ELSE NULL au lieu de ELSE 0 :
Avec ELSE 0, la fonction AVG prend en compte les zéros, ce qui fausse la moyenne si une valeur est absente.
NULL est ignoré par AVG, garantissant une moyenne correcte.
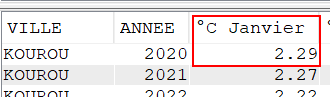
Par exemple, si nous écrivons
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE 0 END)
Alors la requête va additionner les températures moyennes de janvier MAIS aussi ajouter 0 pour tous les jours qui ne sont pas en janvier, le résultat sera donc faux au regard des températures mesurées… il en sera de même pour chaque mois.
La bonne pratique, pour l’utilisation de la fonction AVG est donc :
AVG(CASE WHEN MONTH(DATEREL)= 1 THEN TMOY ELSE NULL END)
Utiliser SQL pour faire une analyse
Nous pouvons également combiner différentes fonctions de SQL pour effectuer une analyse avec un rendu facilement lisible.
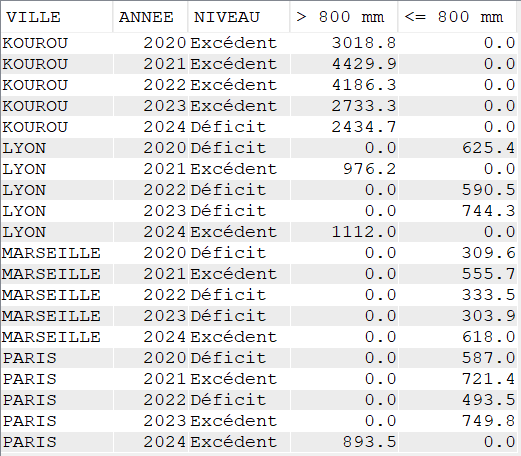
Dans le cas ci-dessous nous combinons CASE à différents niveaux, avec SUM afin de voir si les précipitations annuelles de chaque ville sont au-dessus ou en dessous des moyennes connues et les classer par rapport à un niveau de 800mm (choisi arbitrairement pour l’exercice)
SELECT VILLE,
YEAR(DATEREL) Annee,
CASE
WHEN VILLE = 'KOUROU' THEN
CASE
WHEN SUM(MMPLUIE) > 2560 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'LYON' THEN
CASE
WHEN SUM(MMPLUIE) > 830 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'MARSEILLE' THEN
CASE
WHEN SUM(MMPLUIE) > 453 THEN 'Excédent'
ELSE 'Déficit'
END
WHEN VILLE = 'PARIS' THEN
CASE
WHEN SUM(MMPLUIE) > 600 THEN 'Excédent'
ELSE 'Déficit'
END
END "NIVEAU",
CASE
WHEN SUM(MMPLUIE) > 800 THEN SUM(MMPLUIE)
ELSE 0
END "> 800 mm",
CASE
WHEN SUM(MMPLUIE) <= 800 THEN SUM(MMPLUIE)
ELSE 0
END "<= 800 mm"
FROM CLIMAT
GROUP BY Ville, YEAR(DATEREL)
ORDER BY Ville, YEAR(DATEREL);
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2025-03-04 09:03:202025-03-04 09:28:33Regroupements et Analyses avec SQL
Si vous avez mis en œuvre le journal vous pouvez et même devez analyser les refus de connexion. Le plus souvent c’est un mauvais mot de passe mais ca peut être aussi une attaque, ou un comportement douteux
Voici une requête simple qui permet cette analyse rapide
SELECT JOB_NAME, USER_NAME, FUNCTION, MESSAGE_ID, MESSAGE_TIMESTAMP FROM TABLE(QSYS2.DISPLAY_JOURNAL(‘QSYS’, ‘QAUDJRN’)) WHERE MESSAGE_ID IN (‘CPF2234’, ‘CPF1107’, ‘CPF1393’) ORDER BY MESSAGE_TIMESTAMP DESC;
Les messages traités ici CPF2234 Tentative de connexion échouée. CPF1107 Mot de passe incorrect. CPF1393 Accès refusé.
Remarque : Vous pouvez ajouter des filtres (plage horaire, autres messages de refus , etc …) Vous devrez découper vous même la zone entry data, vous pouvez également utiliser les fonctions table QSYS2.DISPLAY_JOURNALxx spécialiser par TYPE
Les indicateurs font parti intégrante des développements RPG, c’est des booléens dont le nom commence par *IN, certain ont plus ou moins disparu (remplacé par des %EOF, %FOUND, ou un SQLCODE ) , mais les indicateurs *IN01 à *IN99 continuent à être utilisé par exemple dans les DSPF.
On va essayer de voir une méthode qui rendra le code plus lisible pour les jeunes recrues qui devront faire de la maintenance
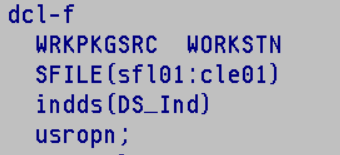
On va prendre un exemple à partir d’un DSPF
Votre écran devra avoir le mot clé INDARA qui indique qu’on va gérer les indicateurs dans un buffer séparé
Pour la déclaration de votre écran vous devrez lui indiquer le mot clé INDDS qui indiquera la DS qui contiendra le tableau de ces indicateurs.
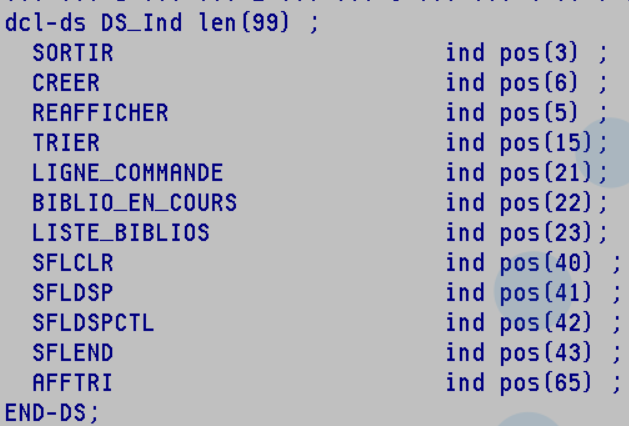
voici un exemple de DS avec les indicateurs nommé
Exemple :
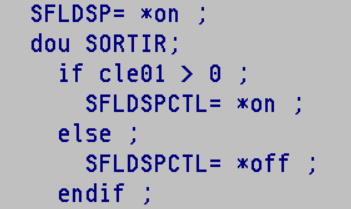
*IN03 / SORTIR
Voici ci dessus un exemple de code RPG FREE, utilisant les noms indiqués dans la DS, on voit tout de suite mieux ce qu’on fait
Remarque :
Vous pouvez mettre votre DS dans un include et le déclarer dans chaque programme , ce qui permettra d’uniformiser votre tableau des indicateurs
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-02-24 11:03:502025-02-25 09:31:53Nommez vos indicateurs en RPGLE