
1) Choisir le mode de production
C’est essentiellement fixé par 2 valeurs système
La première valeur système est QLOGOUTPUT
*JOBEND L’historique du travail sera généré par le travail lui-même. Si l’historique du travail ne peut pas générer son propre historique du travail, celui-ci sera généré par un serveur d’historique du travail.
*JOBLOGSVR L’historique du travail sera généré par un serveur d’historique du travail.
*JOBEND est la valeur historique, cette valeur est beaucoup moins performante sur les nouveaux systèmes que *JOBLOGSVR.
Il est donc conseillé de mettre en place la valeur *JOBLOGSVR.
la deuxième valeur système est QJOBMSGQFL
*NOWRAP
La file d’attente de messages du travail ne fait pas l’objet d’un bouclage.
*WRAP
La file d’attente de messages du travail fait l’objet d’un bouclage.
*PRTWRAP
La file d’attente de messages du travail fait l’objet d’un bouclage et les messages écrasés sont imprimés.
il est conseillé pour éviter d’avoir des messages bloquants de mettre *WRAP, ce qui permettra d’avoir les dernières informations loguées.
2) Choisir le niveau de log adapté
C’est les paramètres LOG() LOGCLPGM() du travail. ils sont fixés par JOBD ou par les paramètres de la commande SBMJOB.
On divise généralement en trois les types les travaux de votre IBM i :
- Les travaux sensibles qui devront avoir le niveau de log maximum
LOG(4 00 SECLVL) LOGCLPGM(YES)
- Les travaux communs , batchs traditionnels sessions interactives
LOG(3 00 SECLVL) LOGCLPGM(NO)
- Les travaux qui ne doivent pas avoir de log, pour des questions de sécurité, ou des travaux trop nombreux et souvent très courts
LOG(0 99 NOLIST) LOGCLPGM(NO)
le niveau peut être ajusté par programme, CHGJOB LOG( ) LOGCLPGM( )
3) Choix du mode d’épuration
La meilleur solution est d’utiliser le cleanup standard de la machine.
Vous pouvez voir les paramètres par la commande ==> go cleanup
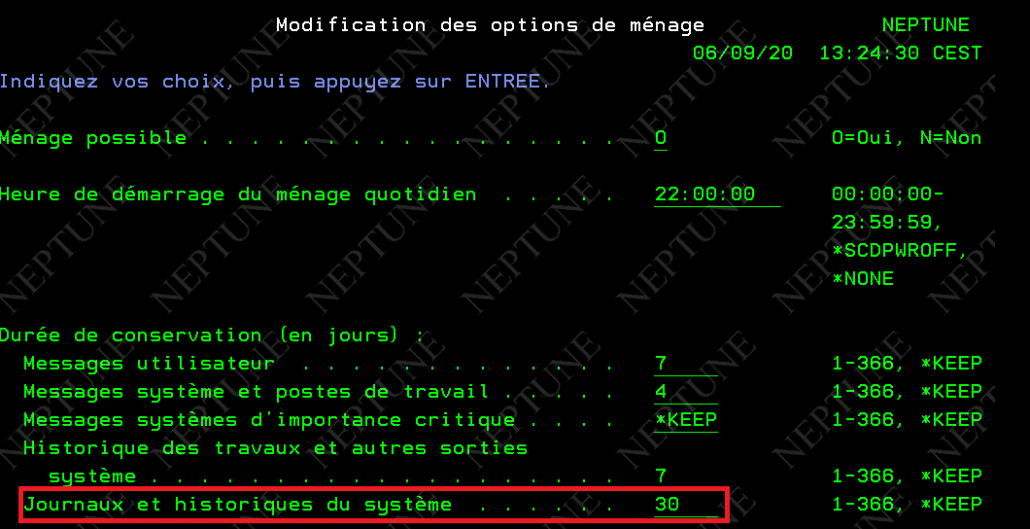
par l’option 1 vous voyez le paramétrage
si le ménage est possible, l’heure de démarrage et la durée.
Le plus souvent on est réglé à 30 jours.
Pour démarrer le ménage c’est la commande STRCLNUP , il est conseillé de la mettre dans le programme STRUP de votre partition.
Les spools de log sont placés dans l’outq QEZJOBLOG, vous pouvez éventuellement épurer des spools particuliers, le mieux étant de ne pas les produire.
4) Nouveautés de SQL AS A Service
Il y a plusieurs vues, et fonction table qui peuvent, vous aidez, voici les 2 principales :
La fonction table QSYS2.JOBLOG_INFO() permet de voir le contenu d’une joblog.
Exemple :
SELECT * FROM TABLE(QSYS2.JOBLOG_INFO(‘378809/QUSER/QZDASOINIT’)) A
pour voir la log du job identifié
La vue QSYS2.OUTPUT_QUEUE_ENTRIES permet de voir la liste des spools d’une OUTQ.
Exemple
select * from QSYS2.OUTPUT_QUEUE_ENTRIES where OUTPUT_QUEUE_NAME = ‘QEZJOBLOG’
pour voir les spools de l’outq des joblogs
5) Remarques générales
Il est souvent inutile de sauvegarder des spools de log, sauf à avoir une réelle raison … et un moyen de suivi !
Un surveillance quotidienne est plus efficace qu’une recherche hypothétique dans un spool de 10 mois
Attention, un spool qui reste est une place de travail occupé dans la table des travaux.
Vous pouvez décorréler les spools des travaux mais ce n’est pas culturel et ça peut compliquer vos recherches futures.
Attention au programme en mode debug avec du SQL, l’optimiseur rempliera rapidement la log.
L’ILE produit plus de log que l’OPM, c’est normal vous avez un niveau de plus à gérer, ca peut doubler les lignes écrites !!!
Pour avoir une vue de des spools de log, pensez à la commande, WRKJOBLOG
Un travail n’a pas forcément de log , la seule qu’il laisse dans tous les cas c’est un message CPF1124 pour son démarrage et un message CPF1164 pour indiquer sa fin.
