On est amené quand on fait des analyses à regarder les dates de source, on constate que ces dates sont à null pour tous les objets de type ILE.
Vous avez une vue QSYS2.PROGRAM_INFO qui permet d’avoir ces informations sur les programmes, un peu comme la commande DSPPGM.
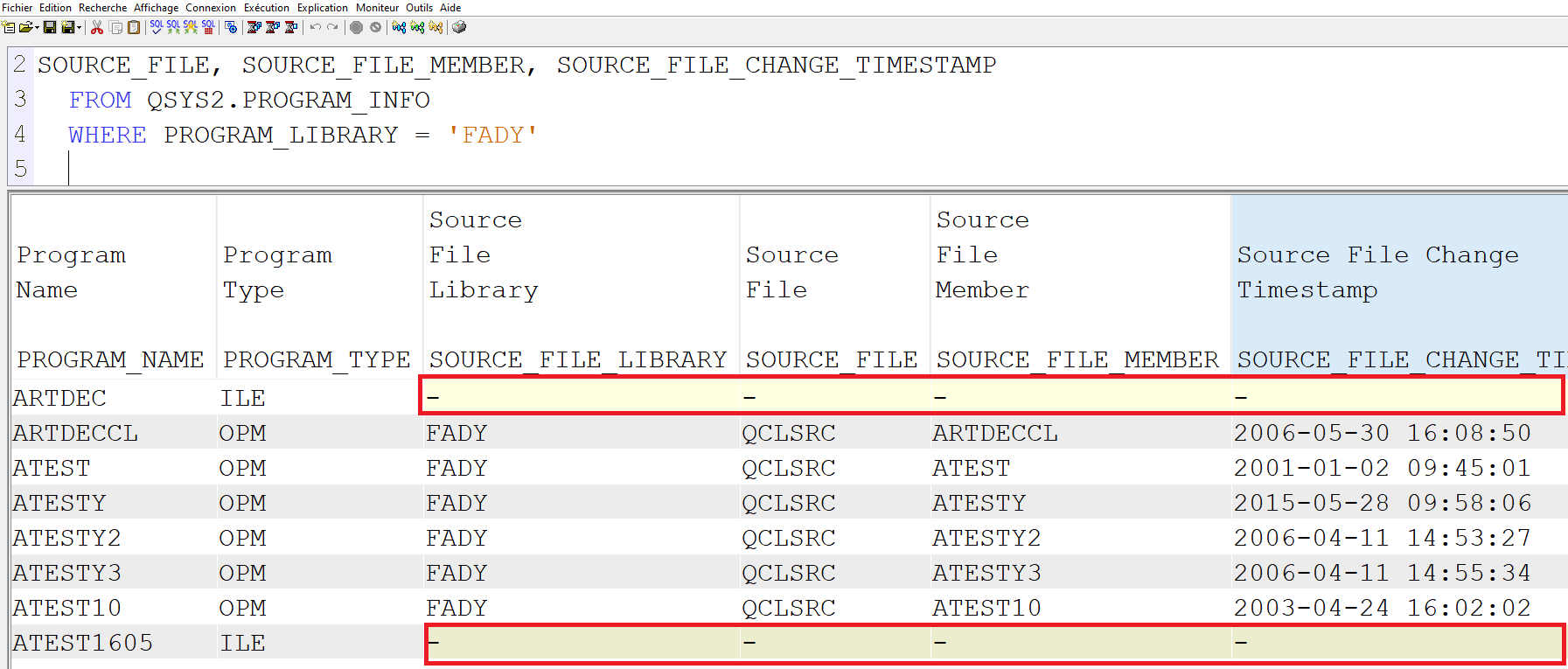
Voici pourquoi : quand vous travaillez en OPM vous compilez des sources qui deviennent des programmes; quand vous travaillez en ILE, vous compilez des sources qui deviennent des modules, puis vous les assemblez pour créer des programmes et du coup une date de source sur un programme ILE ne veut rien dire.
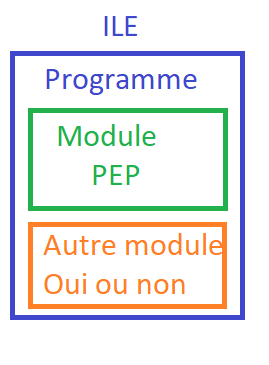
En réalité un programme a un module qui s’appelle point d’entrée programme qui, quand on travaille en BND (CRTBND*), est le seul module placé dans qtemp qui est assemblé pour créer votre programme.
On voit donc que si on veut, on peut assimiler la date du source du programme à la date du module PEP, qui dans plus de 99 % des cas a le même nom que le programme.
On a une deuxième vue permet d’avoir les modules par programme, QSYS2.BOUND_MODULE_INFO.
Il faudra donc combiner les 2 vues.
par exemple :
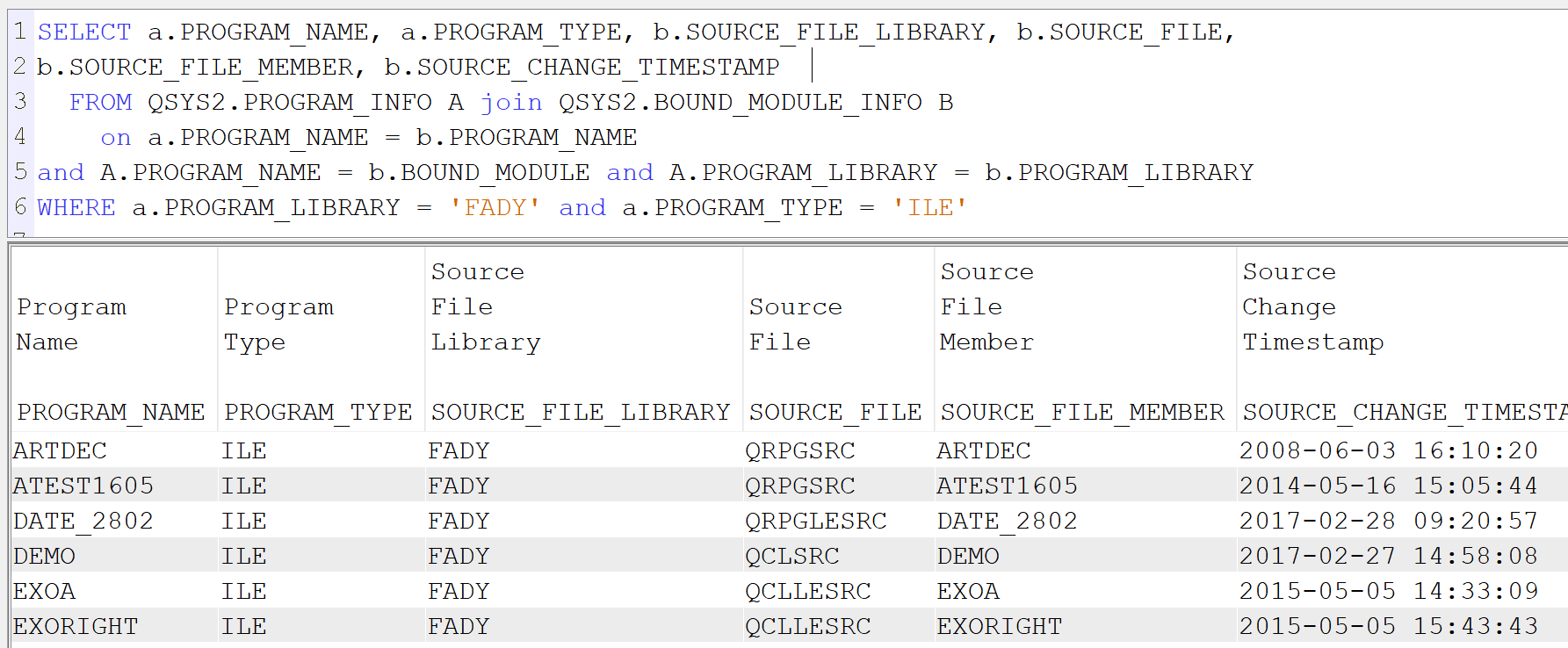
- Pour les programmes ILE
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, b.SOURCE_FILE_LIBRARY, b.SOURCE_FILE,
b.SOURCE_FILE_MEMBER, b.SOURCE_CHANGE_TIMESTAMP
FROM QSYS2.PROGRAM_INFO A join QSYS2.BOUND_MODULE_INFO B
on a.PROGRAM_NAME = b.PROGRAM_NAME
and A.PROGRAM_NAME = b.BOUND_MODULE and A.PROGRAM_LIBRARY = b.PROGRAM_LIBRARY
WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘ILE’
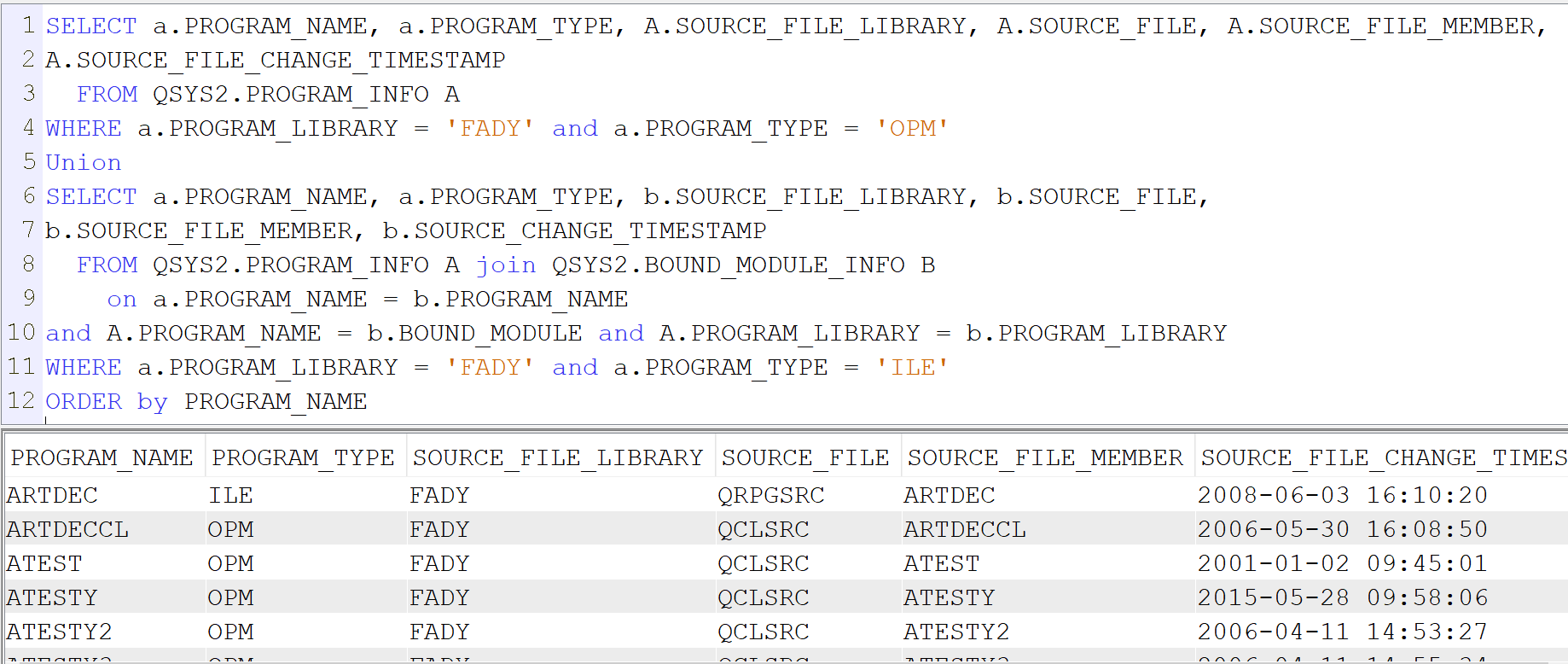
- Pour les programmes OPM
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, A.SOURCE_FILE_LIBRARY, A.SOURCE_FILE, A.SOURCE_FILE_MEMBER,
A.SOURCE_FILE_CHANGE_TIMESTAMP
FROM QSYS2.PROGRAM_INFO A
WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘OPM’
en faisant l’union des deux requêtes vous aurez les dates de tous vos programmes ILE et OPM.
Il y a sans doute d’autres solutions mais celle-ci est très simple à utiliser.