Une des problématiques, quand on fait du SQL, est d’identifier rapidement une requête qui serait trop gourmande.
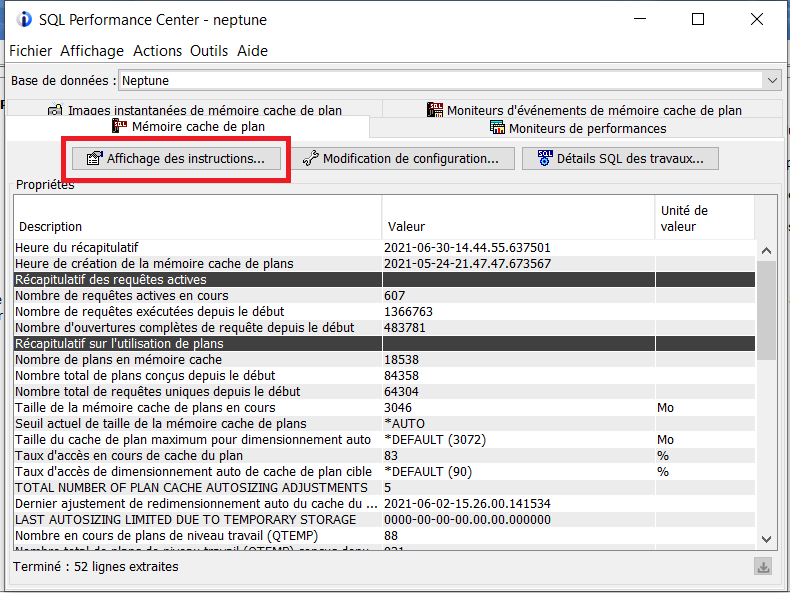
Dans un post précédent j’indiquais comment avoir ces éléments en utilisant le cache SQL, mais ça peut être long pour une première analyse !
La TR5 version 7/4, TR11 version 7/3 apporte une nouvelle fonction table (QSYS2.ACTIVE_QUERY_INFO( )) qui va nous permettre de répondre à cette problématique !
page de référence IBM
https://www.ibm.com/docs/en/i/7.4?topic=services-active-query-info-table-function
Pour l’utiliser, vous devez avoir *JOBCTL dans votre profil ou être ajouté dans la fonction USAGE QIBM_DB_SQLADM .
Exemple :
Une demande qui donne à un instant donné, les 10 requêtes les plus consommatrices de votre IBMi
SELECT QUALIFIED_JOB_NAME as travail , query_type as type_requete, File_Name as fichier , Library_name as bibliotheque,
current_runtime as temps_execution , CURRENT_TEMPORARY_STORAGE as memoire_utilisee
FROM
TABLE(QSYS2.ACTIVE_QUERY_INFO())
where current_runtime is not null
ORDER BY current_runtime desc
fetch first 10 row only
Vous pourrez alors agir en ayant le nom du travail, et utiliser la vue ACS prévue à cet effet par exemple !
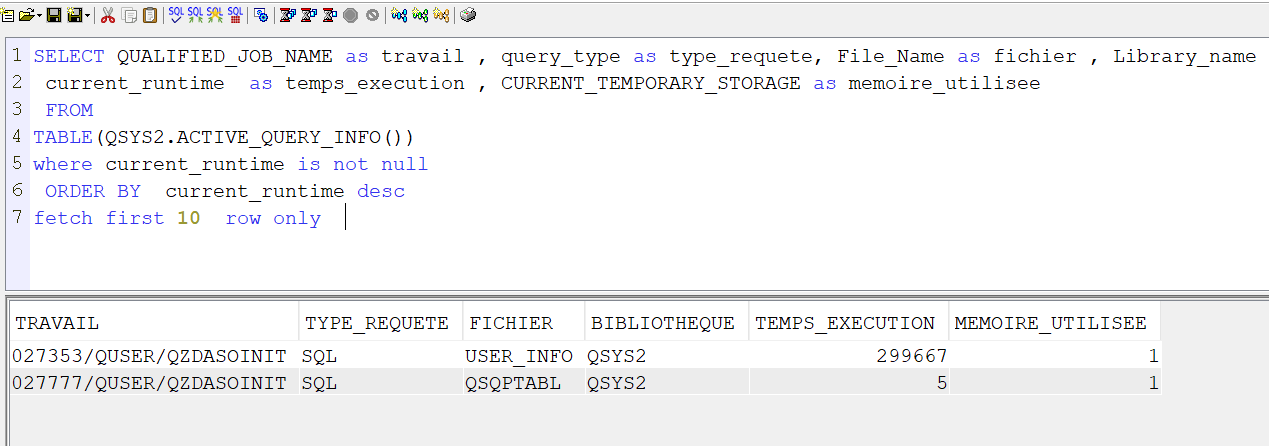
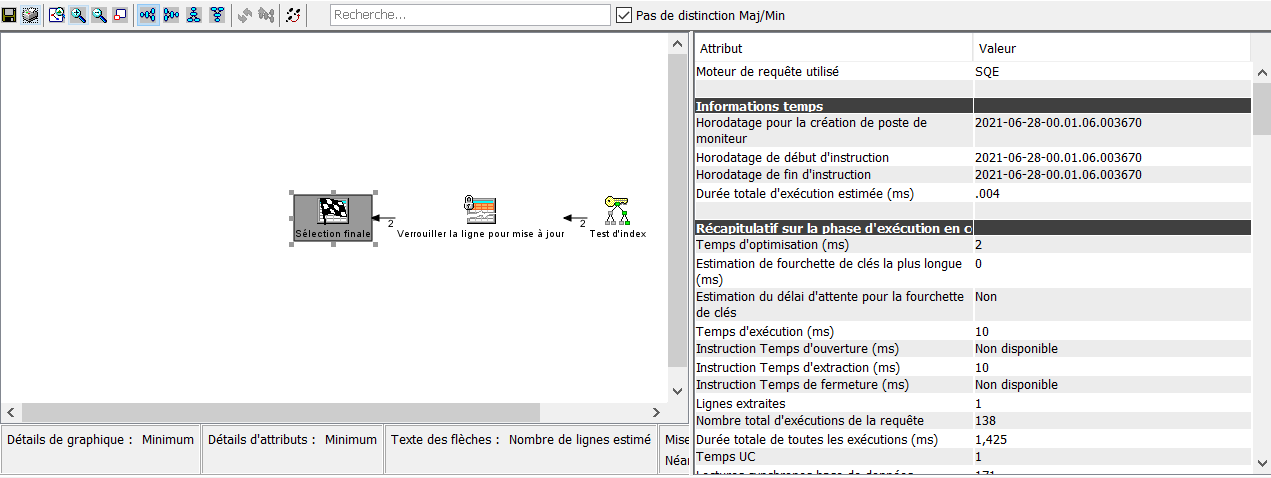
On indique le premier fichier spécifié dans la requête (vue ou table), attention QSQPTABL indique que c’est une fonction table.