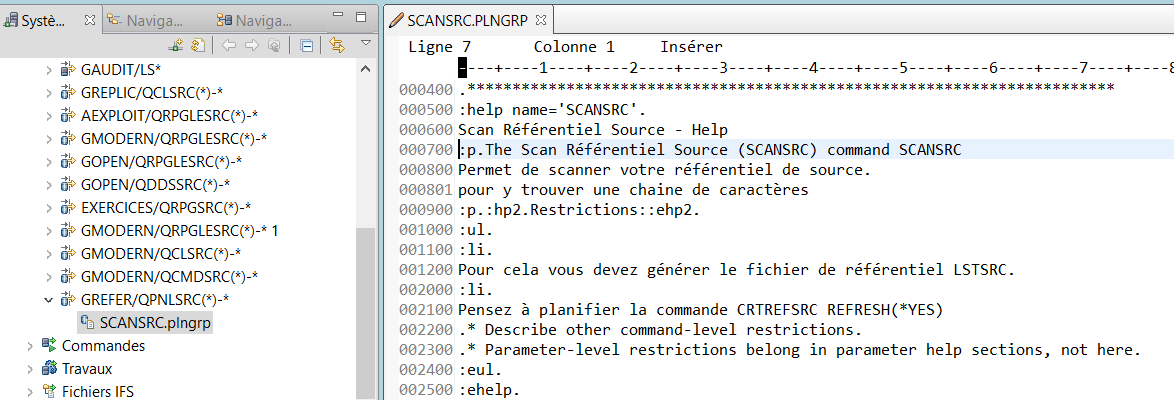
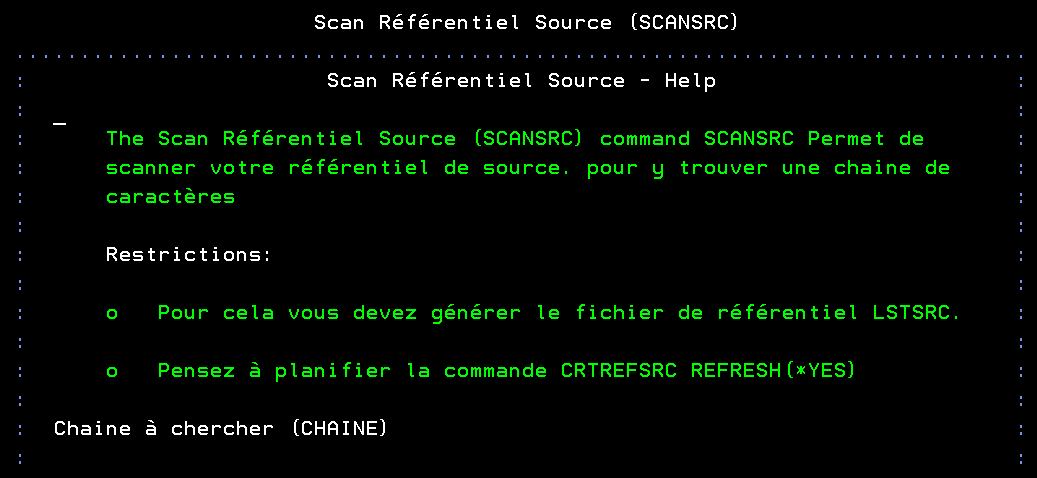
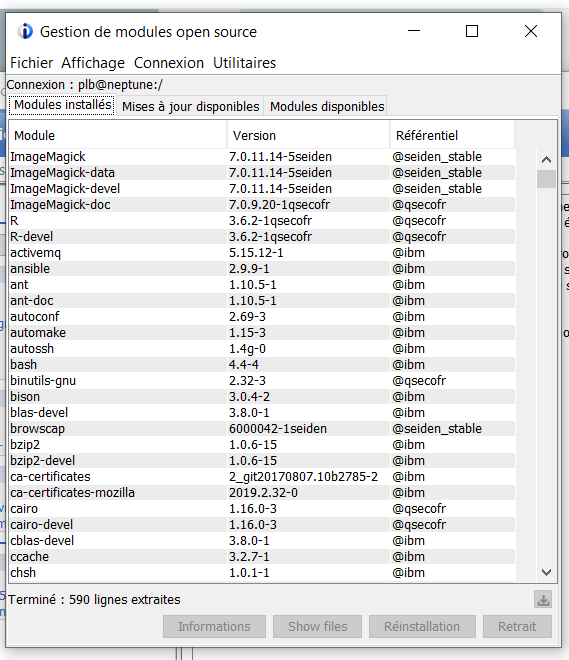
Les produits open-source sur IBM i sont gérés par un gestionnaire de paquet qui s’appelle yum :
Sur ACS il est possible de gérer ces produits en sélectionnant l’option Gestion de modules open source depuis le menu Outils :
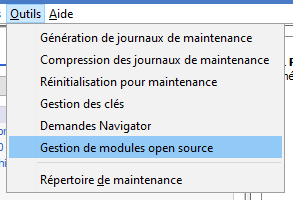
Cette interface a ses limites et ne permet pas d’automatiser la recherche et l’installation des mises à jour de vos produits open-source.
Voilà le but de GOPEN, qui est disponible ici sur Github.
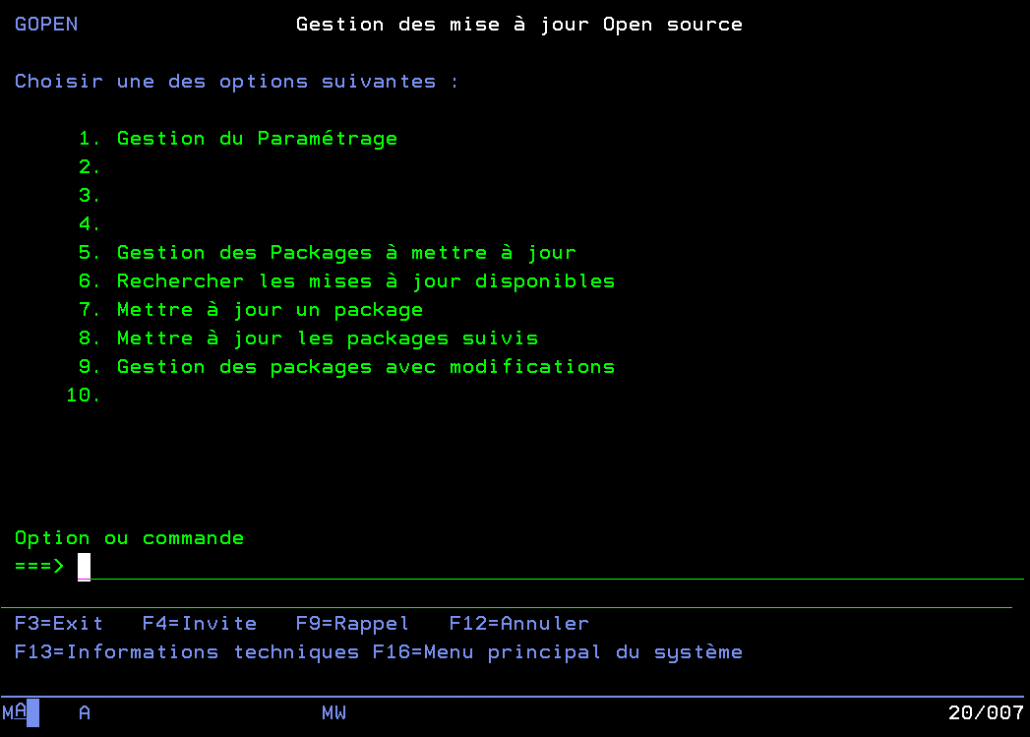
GOPEN fournit une interface en 5250 pour gérer les mises à jour des produits open-source.
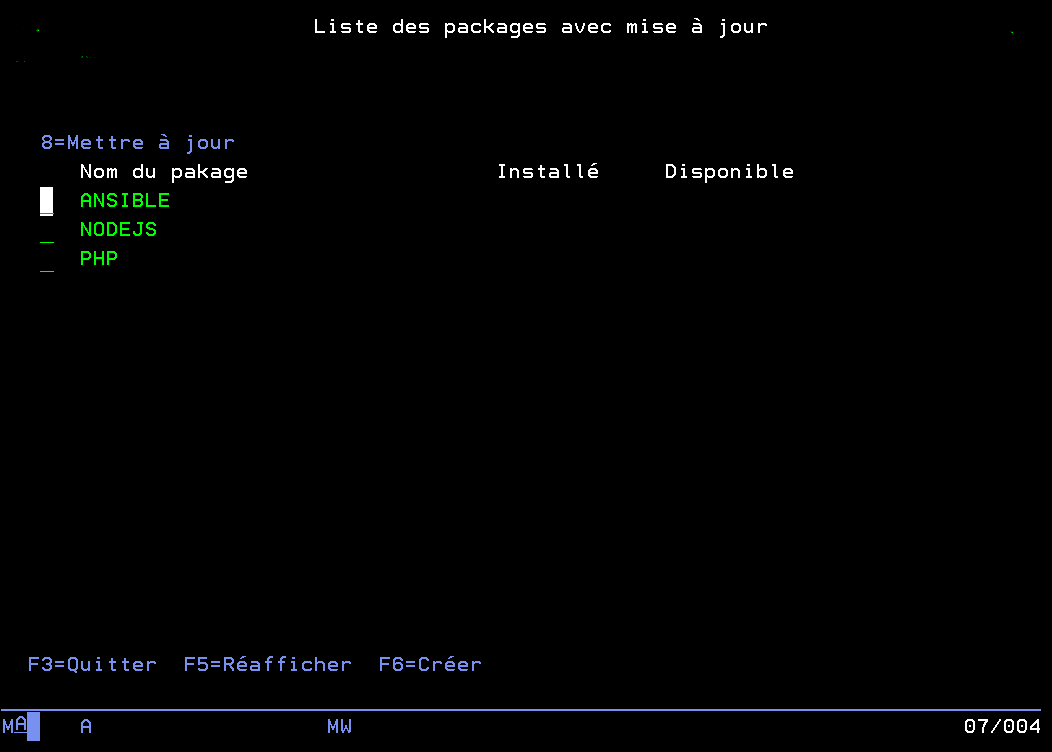
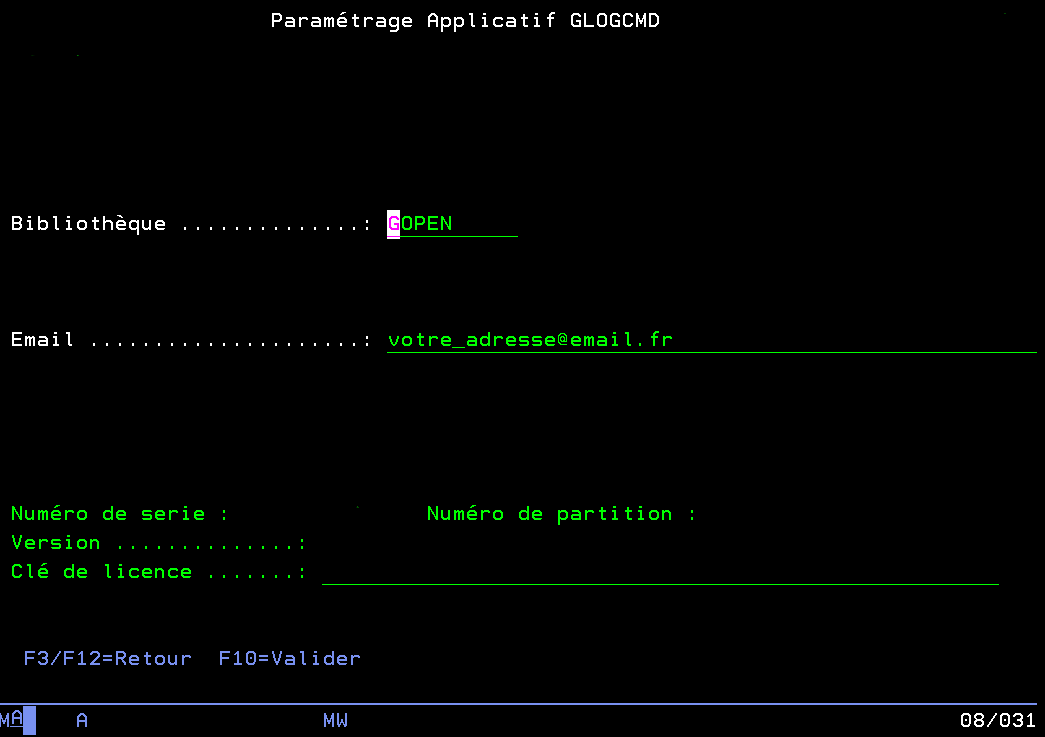
Après paramétrage d’une adresse email pour recevoir toutes les notifications de GOPEN vous pourrez commencer par ajouter des produits open-source à surveiller. Lorsque des mises à jour seront disponibles pour un ou plusieurs des produits surveillés vous recevrez un email résumant tous les produits à mettre à jour en pièce jointe (fichier CSV).
Note : Les produits à surveiller n’ont pas besoin d’être le nom complet du produit, par exemple pour surveiller les mises à jour des produits NodeJS qui a un produit par release (nodejs12 et nodejs14) vous pouvez simplement surveiller nodejs. Toutes les versions installées de NodeJS qui pourront être mises à jour seront incluses.
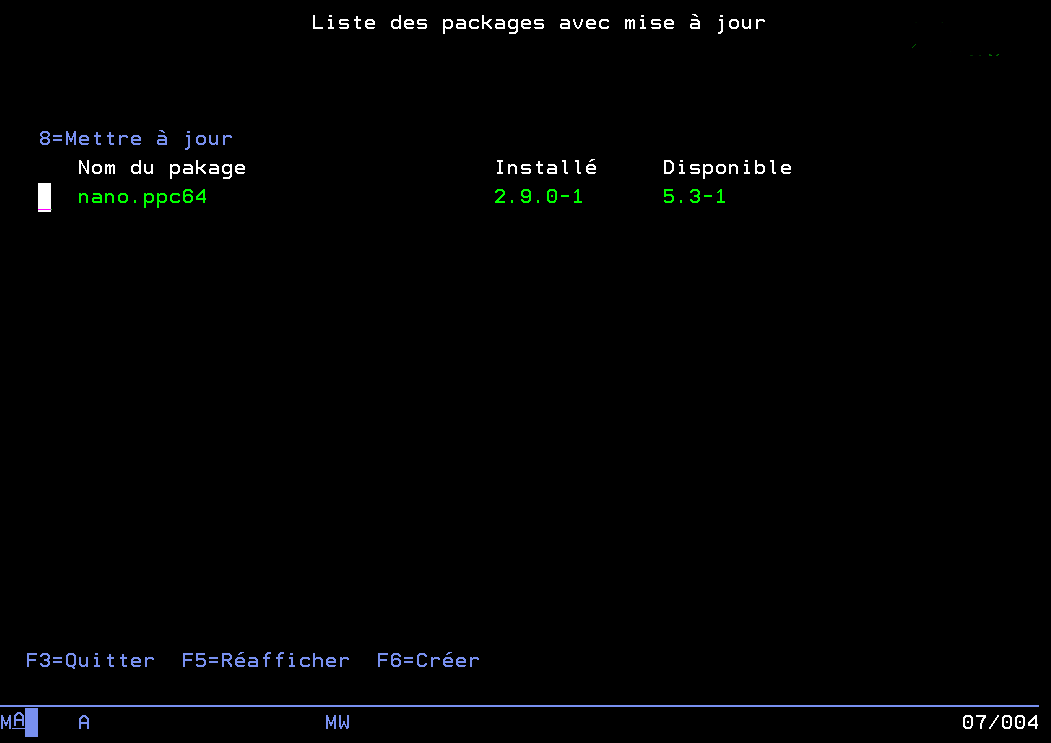
Pour effectuer ces mises à jour il ne reste qu’à retourner sur l’interface 5250 et choisir l’option qui vous convient pour effectuer les mises à jour disponibles.
Il y a une option pour effectuer toutes les mises à jour disponibles parmi les produits surveillés, vous pouvez également choisir quels produits mettre à jour parmi ceux qui peuvent l’être pour un contrôle plus fin.
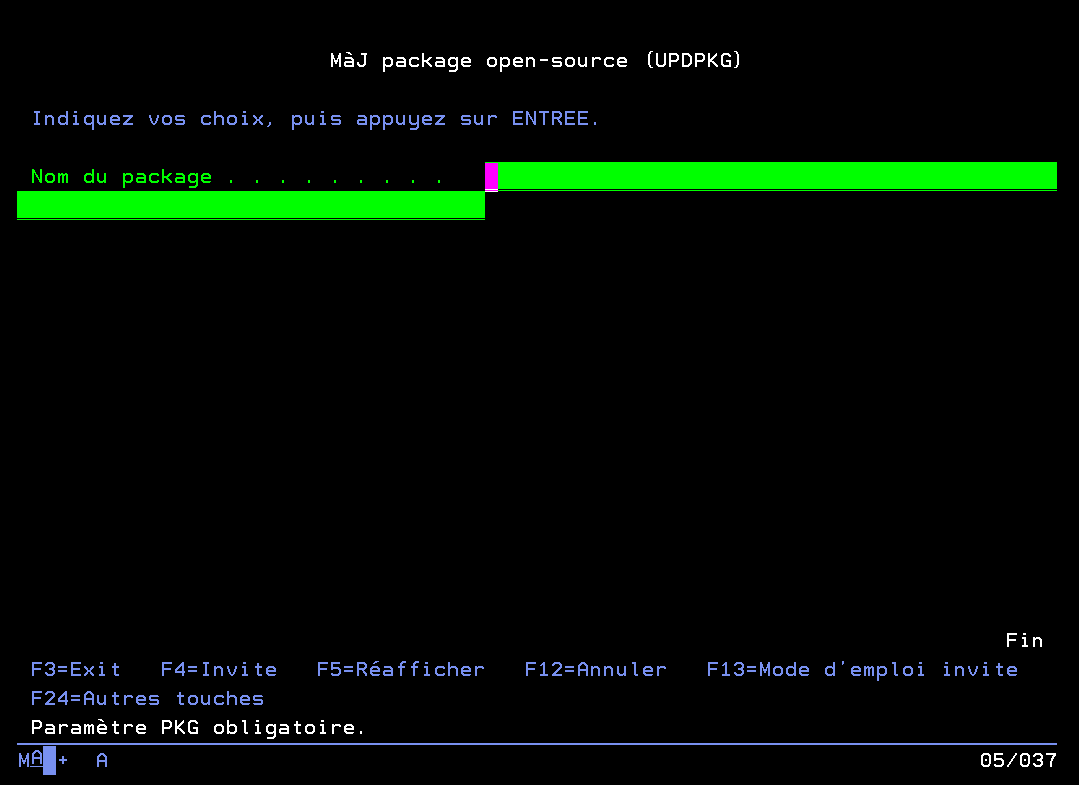
Il est possible aussi de demander la mise à jour de produits en mode batch, ou de procéder à toutes les mises à jour disponibles pour tous les produits (y compris ceux qui ne sont pas surveillés).
Dans tous les cas lorsque des mises à jour sont effectuées avec GOPEN vous recevrez un email résumant tous les changements apportés (cela permet de savoir lorsque des dépendances sont mises à jour en même temps que les produits eux-mêmes).
Pour automatiser la recherche de mises à jour et leur application, vous pouvez planifier des tâches depuis le 5250 à la fréquence qui vous convient avec la commande wrkjobscde :
- La commande
RTVLSTUPDfait la recherche des mises à jour et envoie un email résumant les mises à jour disponibles parmi les produits surveillés. Il est possible de lui donner le paramètresilentavec la valeur de'1'pour ne pas envoyer d’email suite à la recherche. - La commande
UPDPKGfait les mises à jour qu’on lui demande. Elle accepte différents paramètres :*ALLpour effectuer toutes les mises à jour disponibles (y compris des produits qui ne sont pas surveillés)*LSTPKGpour effectuer les mises à jour disponibles des produits surveillés- Le nom du produit directement. N’importe quel autre paramètre sera utilisé comme nom de produit et donné à la commande de
yum update
Pour résumer, GOPEN vous permet de gérer les mises à jour de vos produits open-source à partir d’une interface familière en 5250 et également d’automatiser ce processus.
Grâce à sa flexibilité il est possible de tout automatiser (recherche et application des mises à jour) à la fréquence de votre choix, ou de laisser certaines actions manuelles (recherche de mises à jour automatique, mais application manuelle).
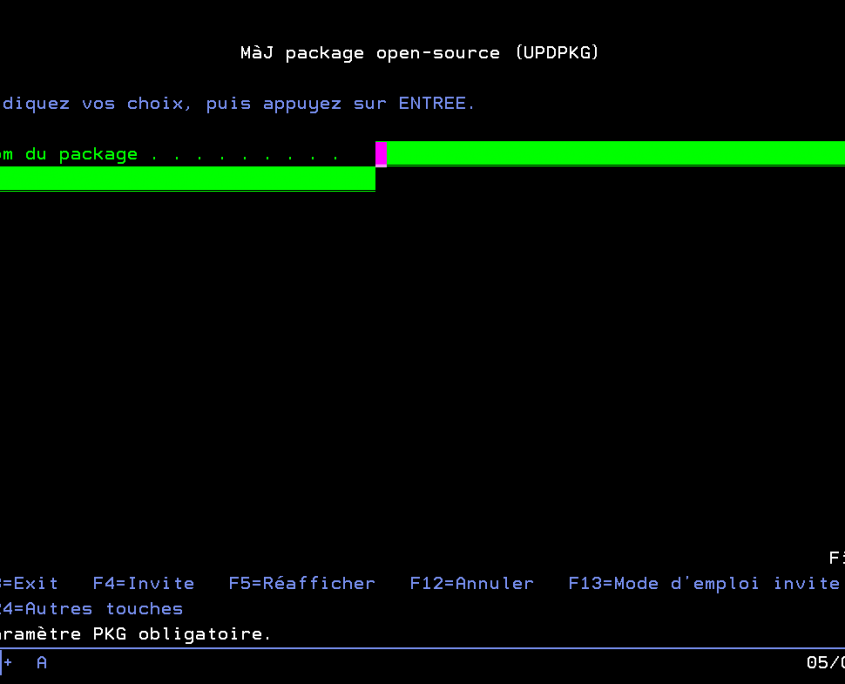
Commande UPDPKG pour effectuer les mises à jour 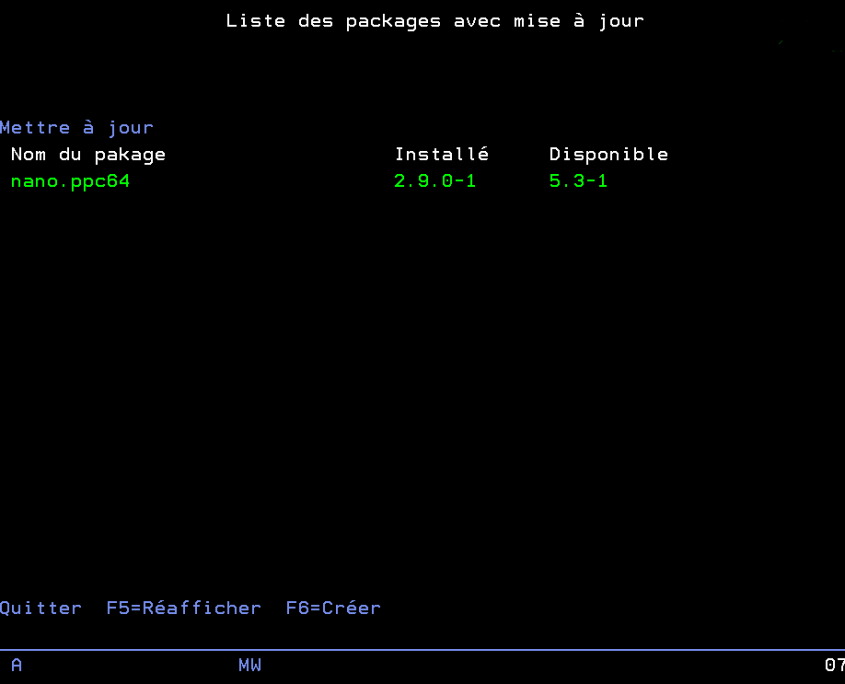
Menu de sélection des mises à jour à effectuer 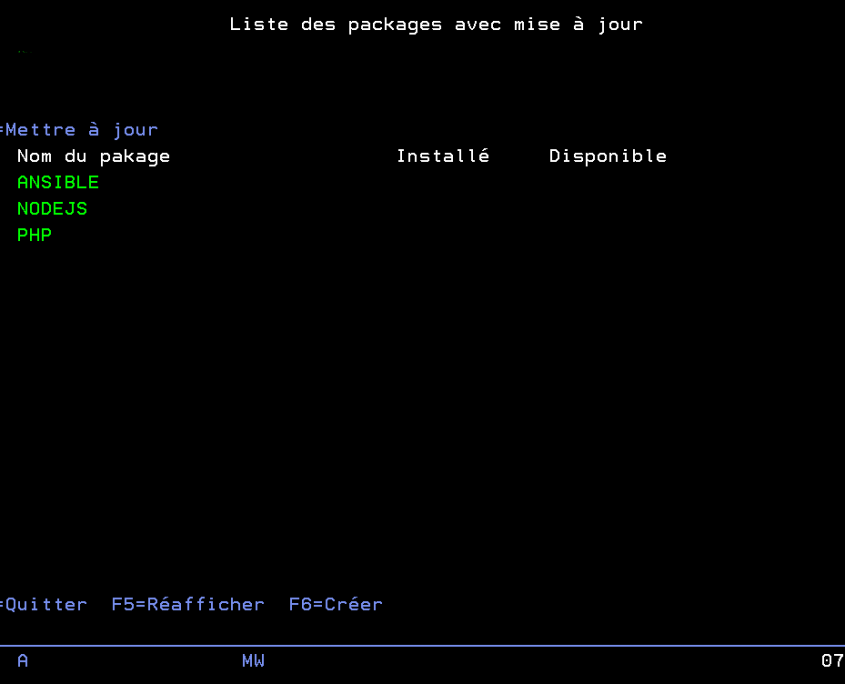
Liste des produits à surveiller 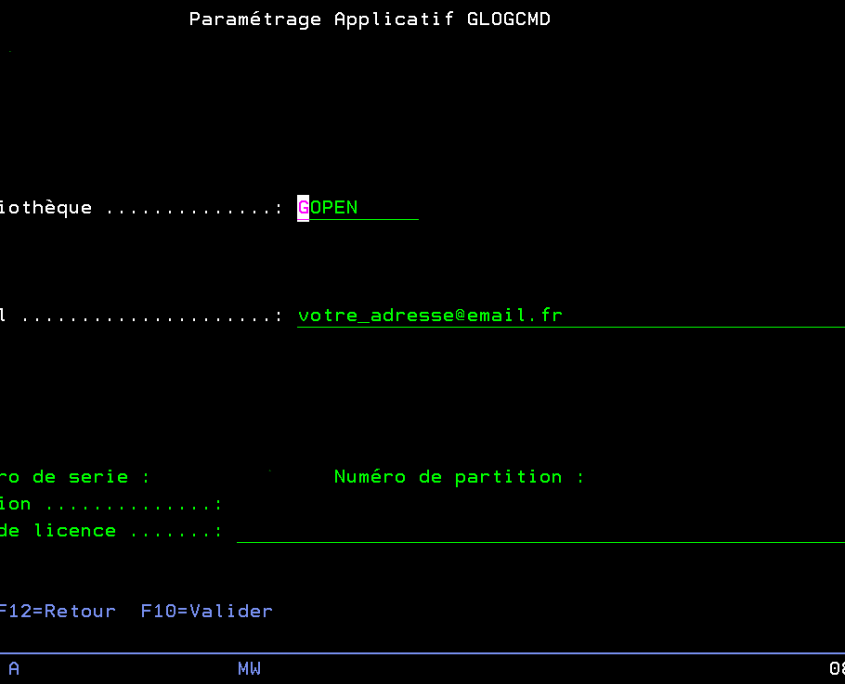
Menu de paramétrage
L’open-source est un passage obligatoire pour vos orientations futures et GOPEN vous fournit une solution pour faciliter l’apprentissage de ces nouvelles approches.