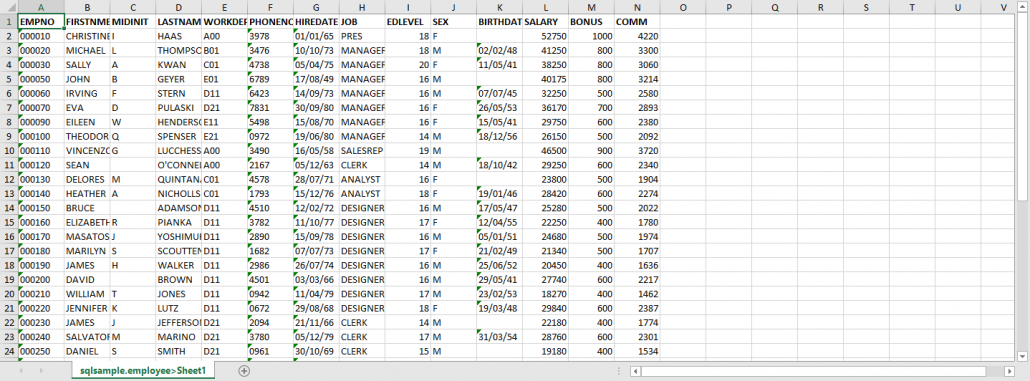
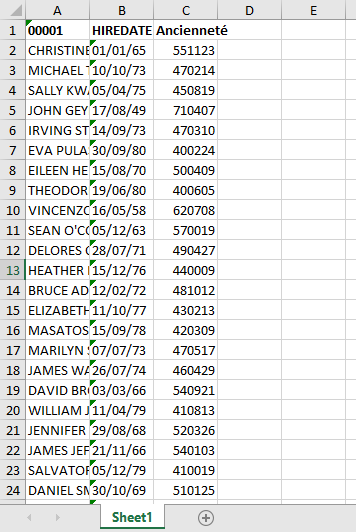
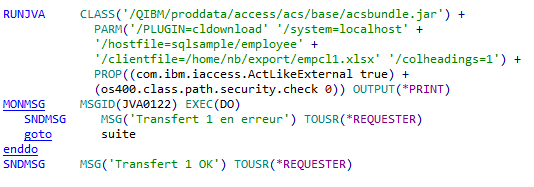
Vous utilisez de plus en plus les fichiers dans l’IFS pour échanger vos csv , PDF etc … ou par des connexions qui utilisent l’open source.
.
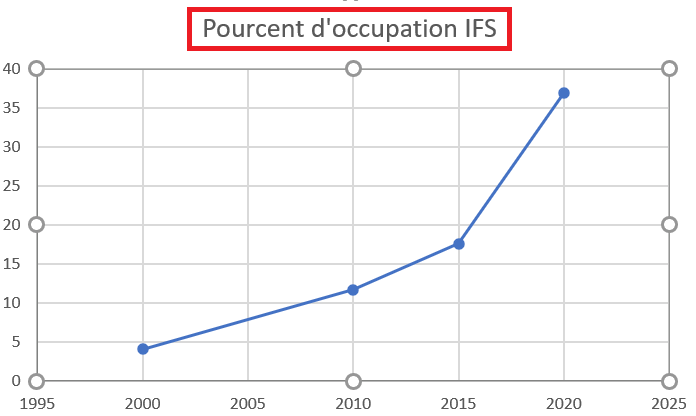
Ces chiffres sont ceux , constatés sur les clients du groupe Gaia Volubis et incluent la partie complètes des fichiers de l’IFS (/home et le reste).
Par défaut quand vous créer un profil par la commande CRTUSRPRF, vous avez le paramètre HOMEDIR( *USRPRF) ce qui indique un répertoire par défaut /home/USRPRF.
Le Homedir correspond au répertoire par défaut comme la *Curlib du coté de QSYS.LIB.
Attention il n’y a pas de contrôle d’existence et si le répertoire n’existe pas l’utilisateur va travailler à la racine ce qui peut créer des fichiers indésirables à la racine de votre système, et qui contribue à une désorganisation de l’IFS !
De même si certains utilisateurs ont un répertoire par défaut différent de cela peut complexifier vos procédures de ménage. Les répertoires homedir de vos users devant servir le plus souvent à des échanges et non pas du stockage.
Voici quelques requêtes pour vous aider à analyser cela
Liste des répertoires utilisateurs avec leur répertoire théorique
Select AUTHORIZATION_NAME as user_profile, home_directory from QSYS2.USER_INFO
Liste des utilisateurs avec leur répertoire associé existant
create table exploit.usr_dir as(
WITH TEMP_A AS(
SELECT cast(substr(PATH_NAME , 1 , 132) as char(132)) as path_name, ALLOCATED_SIZE
FROM TABLE(IFS_OBJECT_STATISTICS(
START_PATH_NAME => ‘/HOME’ ,
OBJECT_TYPE_LIST => ‘*ALLDIR’))
where
LOCATE_IN_STRING(path_name, ‘/’, 1 , 2) > 1
)
select * from temp_a join QSYS2.USER_INFO on ucase(‘/home/’ concat authorization_name) = ucase(path_name)
) with data
dans ce cas je crée un fichier temporaire, mais vous pouvez le faire en une seule requête
Voici donc 2 principales erreurs à surveiller
Liste des utilisateurs avec un homedir qui n’est pas dans /home
select * from QSYS2.USER_INFO
where ucase(home_directory) not like(‘/HOME/%’)
Liste des utilisateurs avec une homedir inexistante
select a.AUTHORIZATION_NAME, a.HOME_DIRECTORY from QSYS2.USER_INFO as a exception join exploit.usr_dir as b on ucase(trim(a.Home_directory)) = ucase(trim(b.Path_name))
Liste des partages avec sur /home
SELECT SERVER_SHARE_NAME, PATH_NAME, PERMISSIONS FROM QSYS2.SERVER_SHARE_INFO
where ucase(path_name) like(‘/HOME%’) and SHARE_TYPE = ‘FILE’
Vous devez en avoir un seul avec *RW
Rappel , par contre vous ne devez pas partager la racine pour contrôler passez la requête suivante,
SELECT SERVER_SHARE_NAME, PATH_NAME, PERMISSIONS FROM QSYS2.SERVER_SHARE_INFO
where path_name = ‘/’
Remarque :
Dans cette partie de l’ifs pas de différentiation majuscule minuscule
Si vous avez beaucoup de fichiers à la racine, regardez les propriétaires, vous avez surement un homedir mal paramétré.
Rappel, vous ne devez pas partager la racine