Il existe un produit sur #IBMi qui permet d’indexer des fichiers DB (zones), des spools, des membres sources et l’IFS.
De plus en plus vous utilisez l’IFS et il peut être intéressant d’indexer les fichiers utilisateurs dans /HOME par exemple,
voici ce qu’il vous faudra faire pour démarrer avec cette solution.
Vous devez avoir le produit (gratuit) 5733OMF

la page IBM est ici
https://www.ibm.com/support/pages/omnifind-ibm-i
Vous avez plusieurs services SQL qui vont vous permettre d’administrer ce serveur
1) Vous devrez d’abord le démarrer
Vous avez un server par défaut c’est le 1
call sysproc.systs_start(1)
Pour voir si votre server est démarré vous avez un service SQL
SELECT substr(SERVERNAME, 1, 30) as serveur
, SERVERSTATUS FROM QSYS2.SYSTEXTSERVERS
Attention 0 indique démarré et 1 arrêté
vous pouvez lui donner un nom comme ceci
UPDATE QSYS2/SYSTEXTSERVERS SET SERVERNAME = ‘NOM_SERVEUR’ WHERE
SERVERID = 1
2) Vous devez créer une collection qui contiendra les éléments nécessaires à l’administration et les index par exemple
create collection omnifind
CALL SYSPROC.SYSTS_CRTCOL(‘OMNI_COL’,‘FORMAT INSO’)
Vous pouvez indiquer la fréquence de mise à jour, par défaut, pas de mise à jour automatique.
3) Vous allez ensuite créer un index, ici un index sur l’IFS
Si vous voulez indexer /HOME et les sous répertoires vous devrez utiliser la procédure suivante
SET schema pour mettre OMNI_COL comme collection par défaut
CALL MYCOLLECTION.ADD_IFS_STMF_OBJECT_SET(‘/home/’);
3) Vous allez devoir lancer la mise à jour de l’indexation
call SYSPROC.SYSTS_UPDATE(‘OMNI_COL’ , ‘IFS_OMNI_COL’)
ca peut prendre du temps
4) Vous avez une procédure qui permet de rechercher SEARCH
Vous devrez être autorisé à cette procédure
SET CURRENT SCHEMA OMNI_COL
GRANT EXECUTE ON PROCEDURE SEARCH(VARCHAR) TO QPGMR
set schema omni_col ;
CALL SEARCH(‘TEXT’)
la procédure vous renvoi un result SET que vous pouvez intégrer dans un programme RPGLE par exemple
5) Vous pouvez utiliser un dictionnaire de synonyme
Le fichier modèle se trouvera ici
/QOpenSys/QIBM/ProdData/TextSearch/server1/config/spell/Synonymes.xml
<?xml version="1.0" encoding="UTF-8"?>
<synonymgroups version="1.0">
<synonymgroup>
<synonym>cheval</synonym>
<synonym>chevaux</synonym>
</synonymgroup>
...
</synonymgroups>
Pour importer
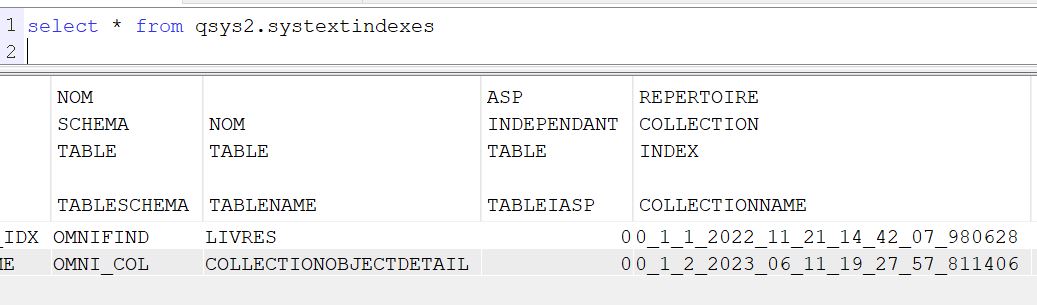
Vous devrez connaitre le nom de la collection
select * from qsys2.systextindexes
Puis passer le scripte sh suivant pour faire l’importation
QSH
cd /Qopensys/QIBM/ProdData/TextSearch/server1/bin
synonymTool.sh importSynonym
-synonymFile /QOpenSys/QIBM/ProdData/TextSearch/server1/config/spell/Synonymes.xml
-collectionName ‘nom_votre_collection’ true
-configPath /QOpenSys/QIBM/ProdData/TextSearch/server1/config
Quand vous rechercherez cheval, vous aurez les fichiers qui ont également chevaux dans le texte
Conclusion:
Ca peut être intéressant d’utiliser ce type d’index pour améliorer la performance de recherche
le produit est gratuit testez le !