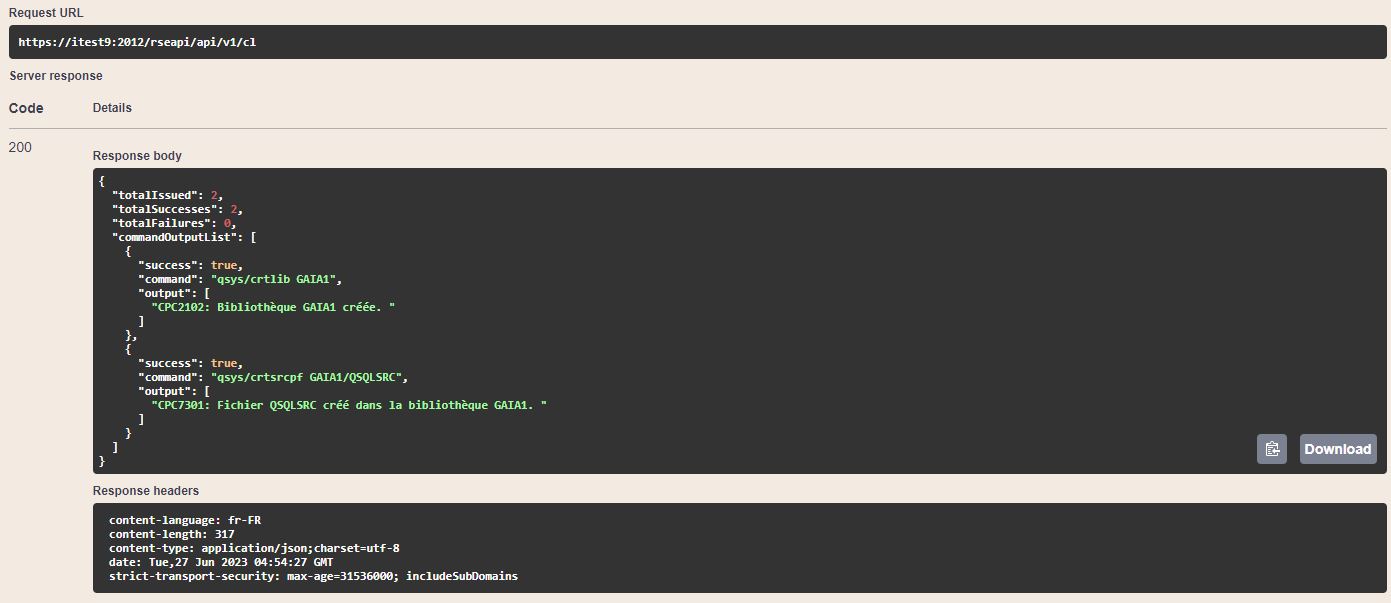
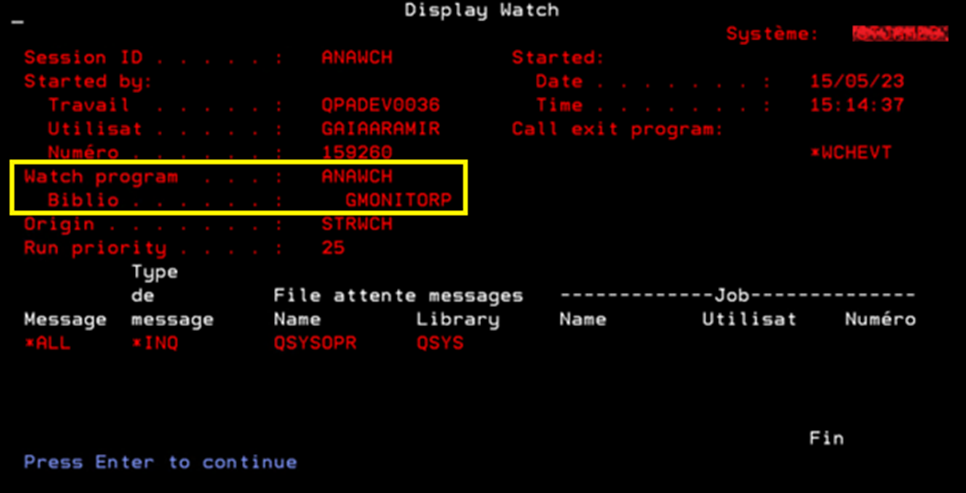
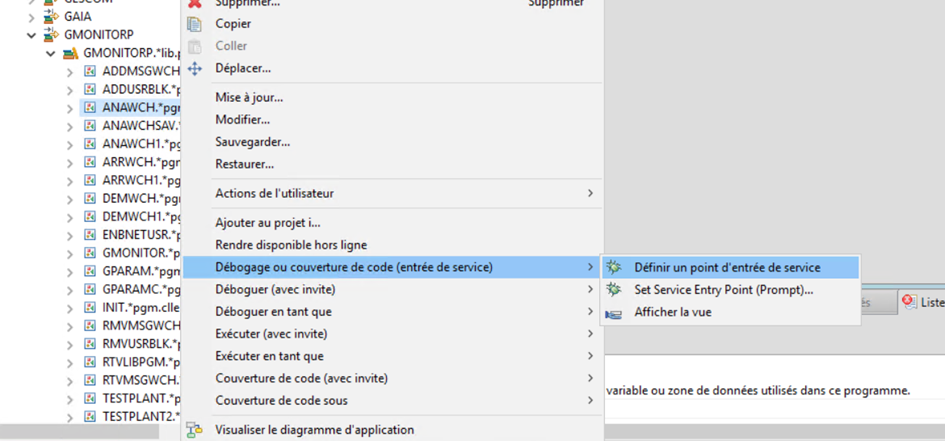
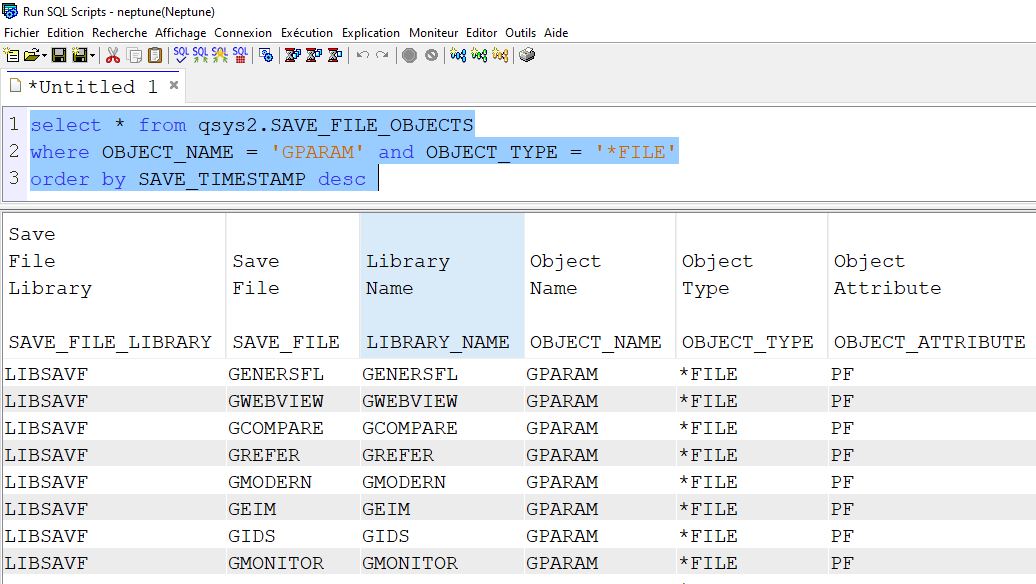
Vous voulez savoir immédiatement quand un fichier PF ou table est créé dans votre bibliothèque
4 principales techniques sont à votre disposition,
La première, les programmes d’exit
QIBM_QCA_CHG_COMMAND pour
CRTPF
CRTDUPOBJ
CPYF
MOVOBJ
RSTOBJ
QIBM_QZDA_SQL1 ou QIBM_QZDA_SQL2
Pour les create table SQL
Attention sera appelé pour chaque requête SQL sur votre système
et la syntaxe peut être compliqué
La deuxième technique consiste à utiliser la journalisation
Si votre bibliothèque est journalisée
— Mise en plage des règles d’héritages
— pour avoir tous les événnements, ce qui n’est pas le cas par défaut
ENDJRNLIB LIB(votre bib)
STRJRNLIB LIB(votre bib)
JRN(votre bib/votre journal)
INHRULES((*ALL *ALLOPR *INCLUDE *BOTH *OPNCLO))
Protocole de test
CREATE TABLE
code D Type CT
CRTPF
code D Type CT
CRTDUPOBJ
code D Type CT
MOVOBJ OBJ(GAIA/APF3) OBJTYPE(*FILE) TOLIB(GDATA)
Pas de poste est le fichier n’est pas journalisé
CPYF
code D type CT
RSTOBJ
Pas de poste et le fichier n’est pas journalisé
il est journalisé que si c’est une restauration de lui même, paramètre du RSTOBJ … STRJRN(*YES)
vous pourrez faire un programme d’exit sur le journal pour les code D type CT
mais attention donc
donc pas de poste pour les MOVOBJ et les RSTOBJ
La troisième technique est d’utiliser le journal d’audit
s’il est démarré et qu’il a la valeur *CREATE, vous allez avoir des postes code T type CO pour les créations
et OR, RA, RO pour les restaurations
Vous pourrez faire un programme d’exit sur le journal d’audit pour les postes vues ci dessous,
remarque les outils de replication logiciel utilise cette techno.
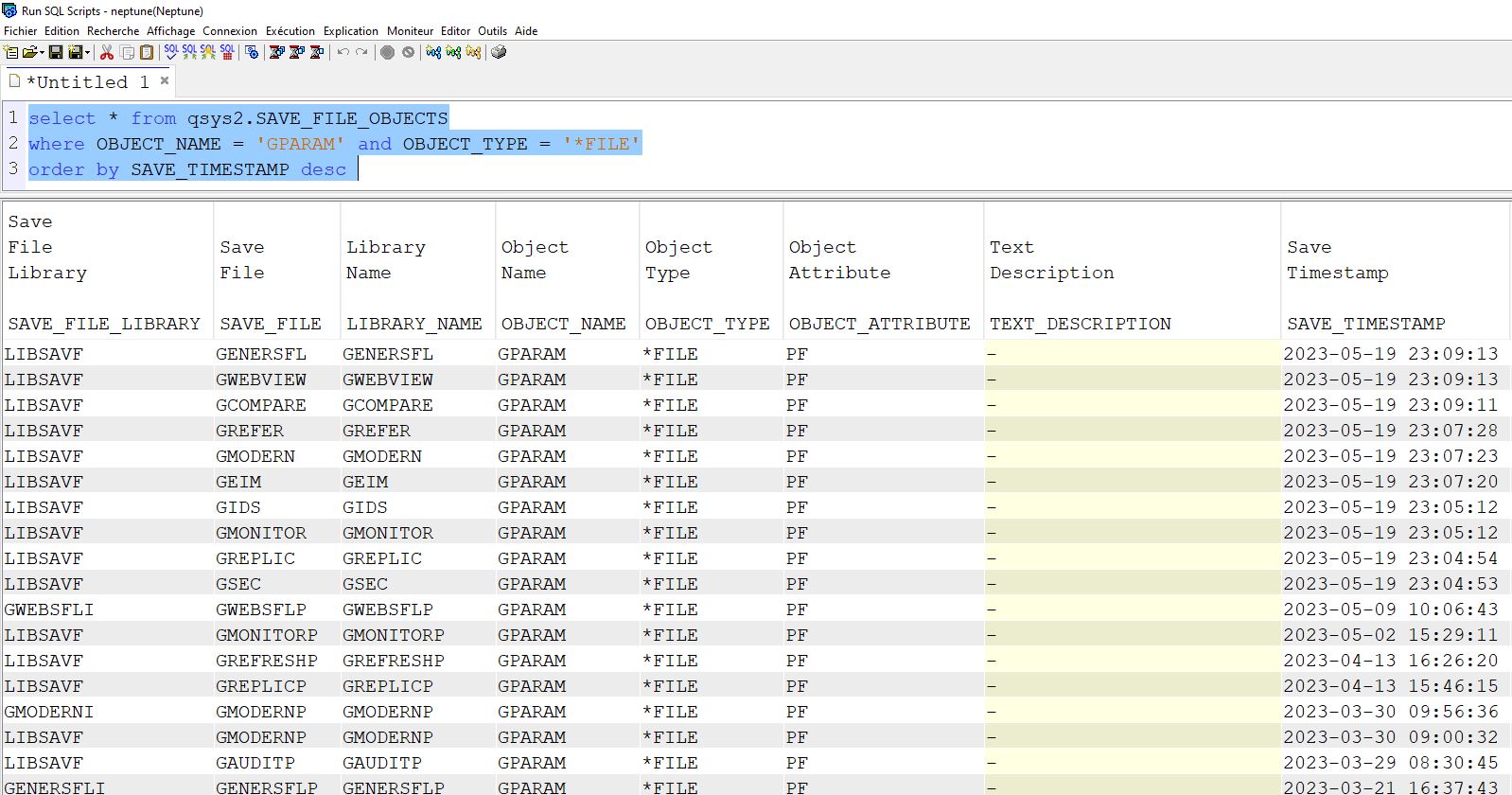
La quatrième, le journal du catalogue DB2
Le catalogue bénéficie de son propre journal, QDBJRNFILE de la Bibliothèque QRECOVERY
Quand vous créez une table ou un PF, vous avez un poste code R type PT ou PX qui sont générés
Vous pouvez mettre en place un programme d’exit journal sur celui ci
C’est une solution simple et efficace
Conclusion
Pas de solution miracle
si votre base est journalisée utiliser la solution 2 semble la plus simple
surtout que dans certain cas on ne voudra pas tracer les MOVOBJ et les RSTOBJ