Vous avez assisté, ou non, à la Power Week coorganisée par IBM France et Common France :






Gaia-Volubis a été très heureux de participer à cette édition, riche en annonces. Avant de reprendre une vie normale, de retourner à notre quotidien, voici le retour de nos speakers !
Damien
C’est toujours un moment particulier pour nous dans notre calendrier, et cette année n’aura pas dérogée aux autres : beaucoup de participants, d’échanges que ce soit avec des clients ou des IBMers, quelques dépannages en direct ! 3 jours intenses.
Merci aux participants à nos sessions et à leurs retours. Il est toujours appréciables de savoir que nos choix de sujets correspondent à des attentes des participants à l’évènement.
Prochain évènement de masse : le Common Europe à Lyon en juin 2026…
Florian
Trois jours intenses et passionnants pour cette édition de la Power Week 2025 !
Au-delà du programme officiel, ce sont surtout les échanges directs avec nos clients, partenaires, IBMers et l’ensemble des participants qui ont marqué l’événement. Ces discussions spontanées, souvent en marge des sessions, sont celles qui font grandir notre réseau, ouvrent des perspectives et apportent des idées concrètes pour aller plus loin.
J’ai également pu présenter COMMON France et toutes les actions que nous avons menées cette année, notamment la Battle Dev que j’ai eu le plaisir de coorganiser avec Philippe Bourgeois et Jérôme Clément. J’espère que nous pourrons organiser une 4ᵉ édition l’année prochaine !
Merci à tous d’être venus !
Julien
Merci à toutes et à tous pour ces trois journées intenses à la Power Week 2025 !
J’ai particulièrement apprécié la qualité des échanges avec nos clients, partenaires et IBMers. Ces moments informels, toujours très enrichissants, sont essentiels pour nourrir notre réseau et nos perspectives.
J’ai également été heureux de présenter deux sessions orientées sécurité et bonnes pratiques sur IBM i, des sujets au cœur des préoccupations de nombreux clients. Merci pour votre participation et vos questions !
L’événement a une nouvelle fois confirmé sa convivialité, et la troisième édition de la Battle Dev a été remarquablement organisée.
Ravi de vous avoir retrouvés en nombre, et déjà impatient de vous revoir au Common Europe à Lyon en juin 2026 !
Betty
Ces trois jours au cœur de la communauté IBM étaient d’une richesse incroyable.
Ils m’ont permis d’avoir une vue plus globale et plus synthétique de la puissance, des possibilités et de l’avenir du power et de ses applications.
Mais le futur s’écrit aussi avec la jeune génération de programmeurs, et la présence des participants à la pépinière de cette année m’a permis de voir que la relève était assurée grâce à ces formations.
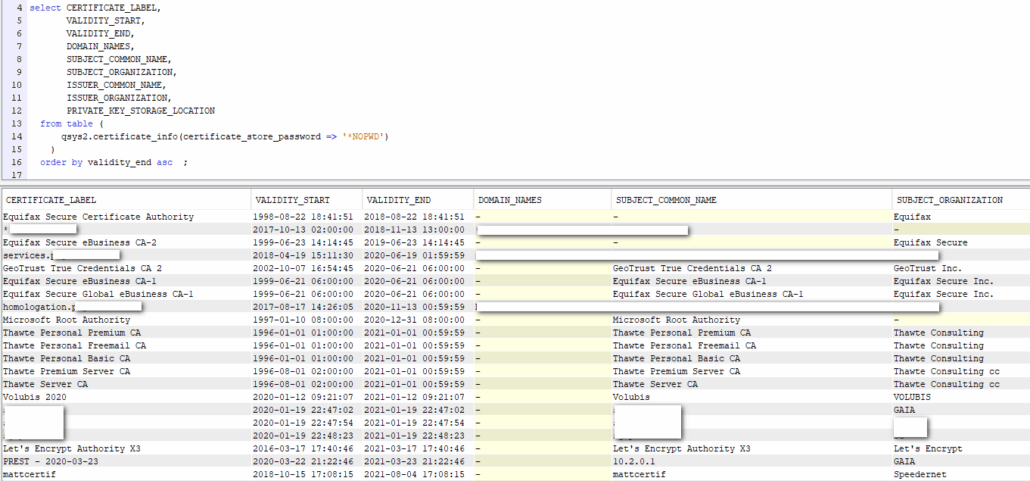
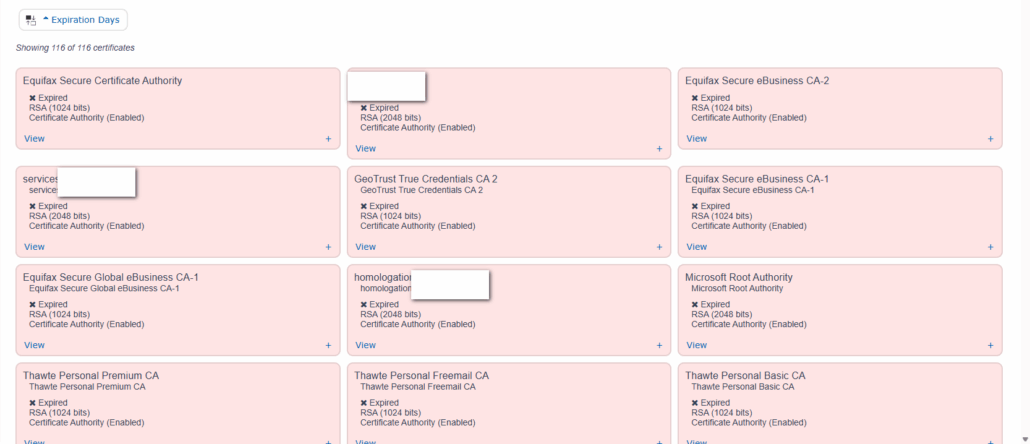
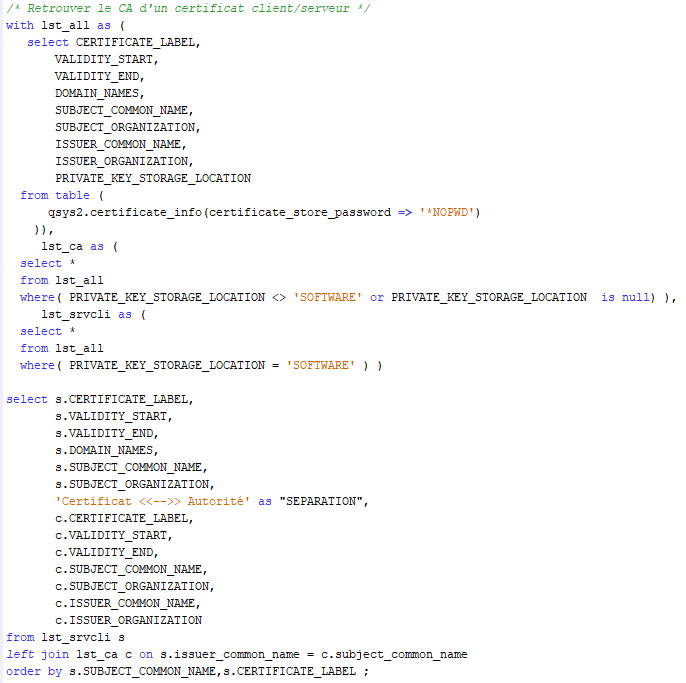
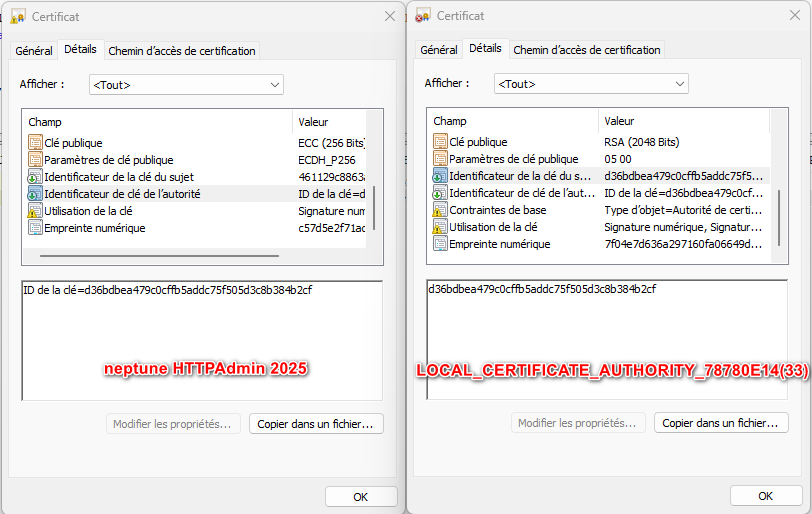
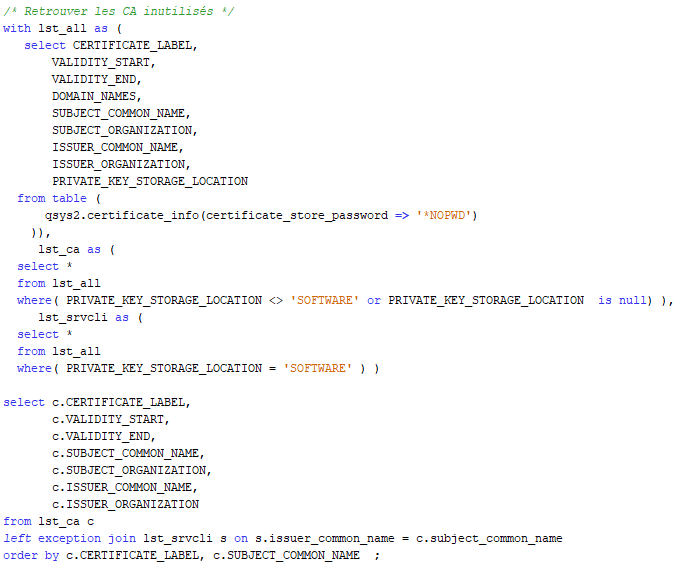
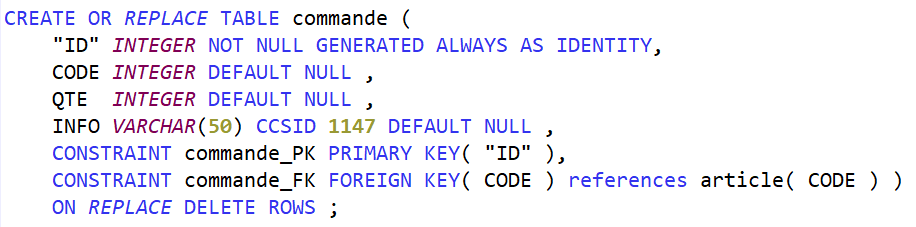
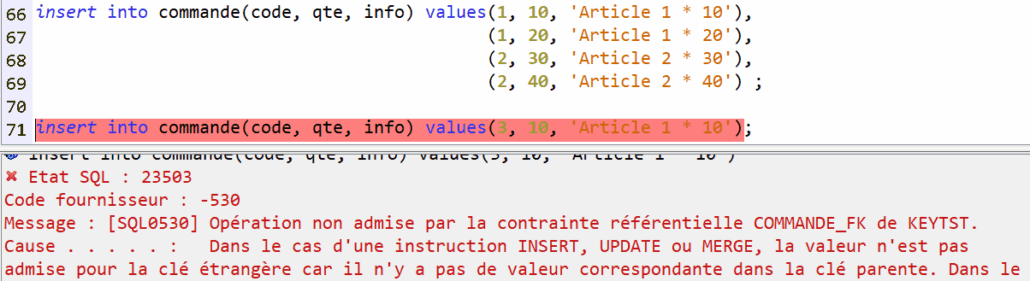
J’ai eu l’occasion de faire une première présentation qui concernait la modernisation via SQL, et je n’ai aucun doute que les équipes hybrides qui se construisent actuellement avec des jeunes et des personnes plus expérimentées sauront trouver des méthodes de travail permettant d’aller vers cette modernisation, nécessaire, et souhaitée.
Eric
3 jours intenses de rencontres, des visages connus et des nouveaux venus. 3 jours de sessions intéressantes. Toutes les personnes rassemblées ont en commun un grand intérêt, voire même une passion pour leur système favori. Une communauté IBMi toujours aussi active.
J’ai pu cette année présenter la session « Modernisation avec SQL : comment Intégrer l’existant », avec BETTY et LUCAS. Notre première session. Ce fut intense à préparer, et à présenter.
Les outils open source ont suscité mon intérêt cette année. La présentation de BOB a été très instructive, bien qu’il reste de nombreuses questions encore sans réponse.
Merci à tous pour votre énergie et votre participation!
Pierre Louis
C’est avec plaisir que comme chaque année, on retrouve la communauté IBMi, cette année pour la première fois les gens du monde Power nous ont rejoint.
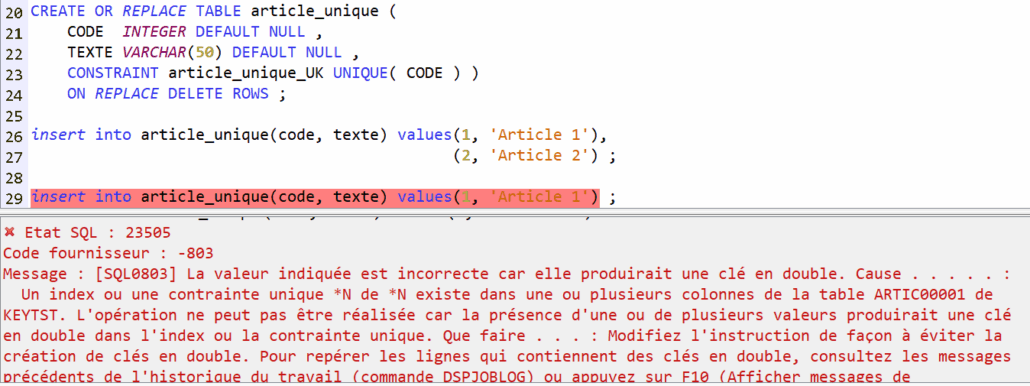
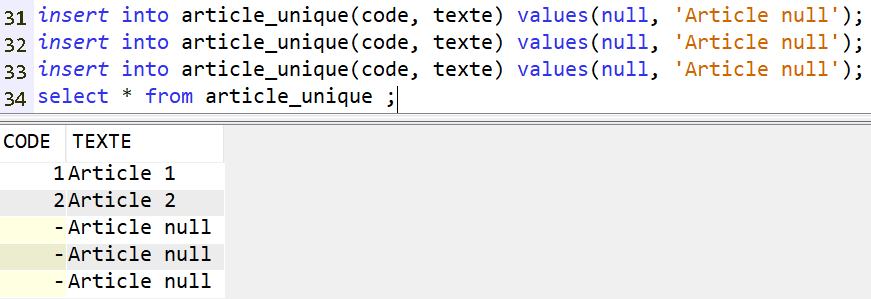
On a pu assister à des présentations techniques intéressantes, beaucoup était basées sur l’IA, comme BOB , dont la présentation a été très prometteuse …
Pour ma part j’ai trouvé très intéressant le produit MANZAN qui permet de supervisé votre IBMi et qui a l’air simple et efficace.
Cette année, j’ai présenté 2 sessions en duo avec Gautier Dumas, sur le chemin de modernisation et avec Florian Gradot sur, comment donner une seconde vie à vos application 5250, merci a eux de m’avoir supporté, ce fut une expérience intéressante.
J’ai pu échangé sur des thèmes différents, avec des clients et des partenaires, ce qui est toujours enrichissant.
Merci à IBM et à Common pour cette organisation, merci à ceux qui sont venus, et l’année prochaine !
Nathanaël
3 jours très intenses pour ma part, mais très enrichissants !
Les meilleurs moments : ceux que l’on ne peut pas mettre en photo 😉
J’ai particulièrement apprécié de pouvoir échanger de façon libre et informelle avec nos clients, partenaires, IBMers et de façon plus globale toutes les personnes présentes. C’est important, c’est la construction d’un réseau, un réseau qui apporte des perspectives, des solutions.
Donc merci à vous d’être venu, nombreux, y compris dans non sessions, de poser des questions. C’est ce qui nous donne l’énergie pour les mois à venir jusqu’au prochain grand rassemblement !
Retrouvez toutes les informations
👉 Consultez le programme complet ici avec les supports de présentation https://powerweek2025.sched.com/
👉 Les sessions de Gaia-Volubis téléchargement
Vers le prochain grand rendez-vous : Common Europe Congress à Lyon
La Power Week est aussi une étape vers un autre événement majeur : le Common Europe Congress, qui se tiendra à Lyon du 14 au 17 juin prochain. Ce congrès réunira la communauté IBM i européenne autour de conférences, ateliers, et moments conviviaux. Une occasion unique de faire rayonner notre territoire et notre expertise.
C’est la première fois en France depuis 1997, une autre ère !
Common Europe – A pan-European IT Community of IBM based solutions