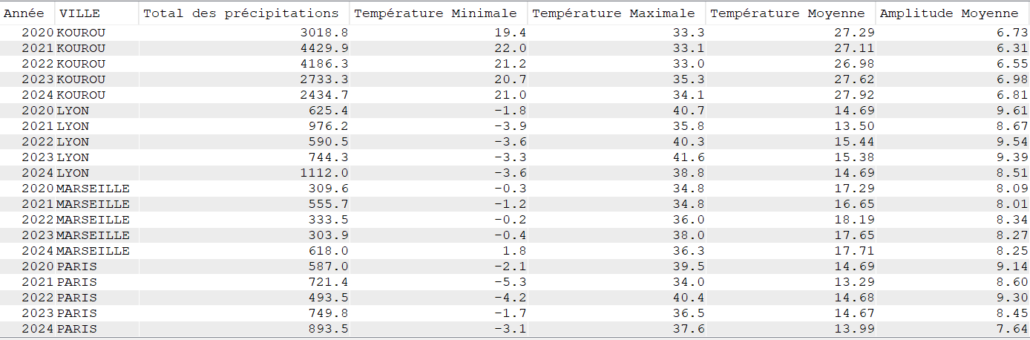
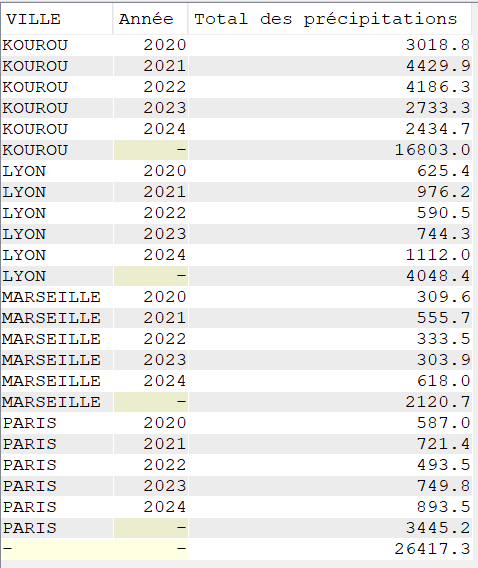
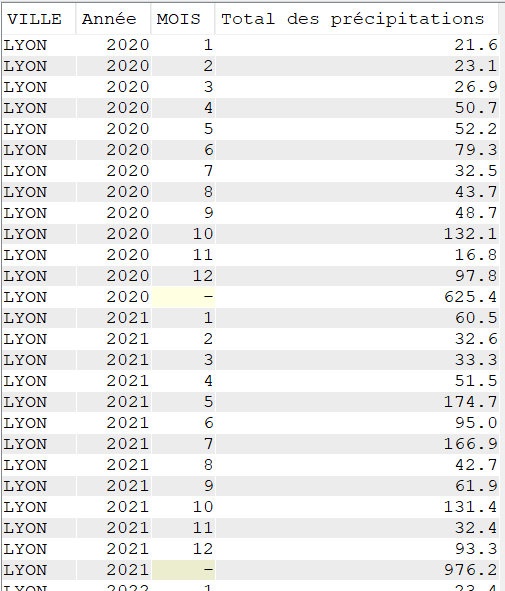
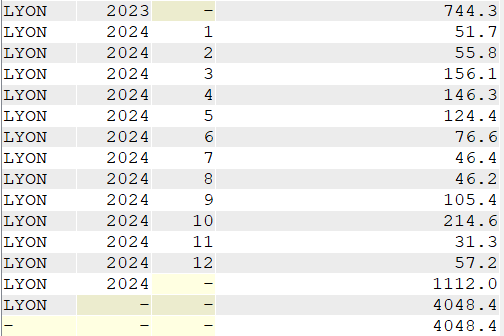
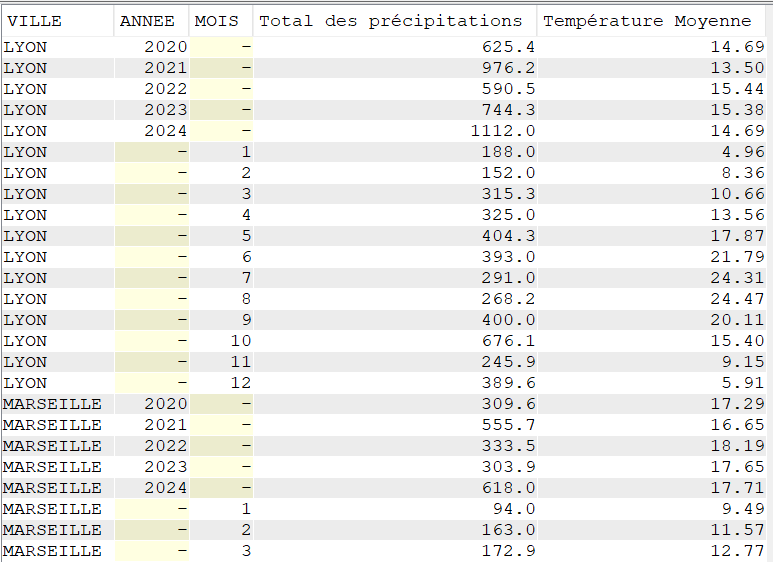
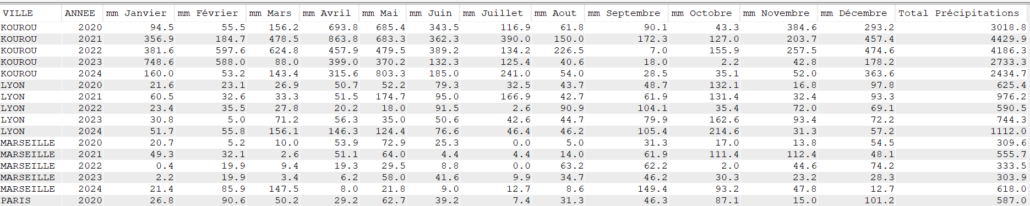
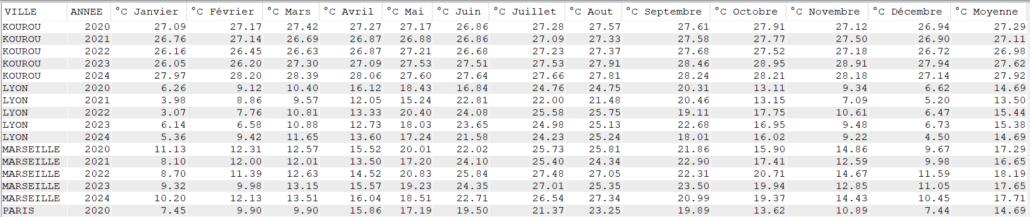
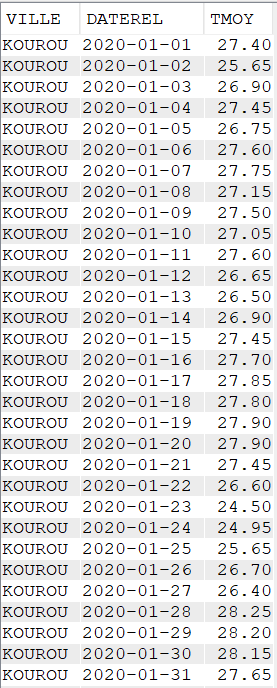
Cette semaine c’est un article un peu spéciale c’est notre ami Jérôme Clément qui nous livre ses réflexions éclairées sur la modernisation de vos applications #ibmi et ses enjeux , merci à lui pour ce partage .
Objectifs
Cet article a pour objectif de démystifier la modernisation IBMi et surtout de mettre en évidence toutes les actions de modernisation réalisables aisément qui faciliteront grandement les actions d’envergure qui seront à réaliser ensuite.
Le concept de Modernisation de l’IBMi est, certes, très vaste et peut paraitre très difficile à mettre en œuvre mais nous allons voir que cette modernisation repose aussi sur de nombreuses étapes qui peuvent, elles, être réalisées facilement et rapidement par les équipes internes à l’entreprise.
En plus d’être indispensables à la modernisation, ces étapes apporteront une meilleure maîtrise des applicatifs IBMi existants, ce sont des prérequis aux chantiers plus conséquents que sont, par exemple :
- La mise en place de solutions DEVOPS
- La conversion automatisée des bases DB2 en bases SQL
- La transformation des programmes RPG en programmes FREEFORM
Voici quelles sont ces différentes étapes, que je détaillerai ensuite :
- Adhésion à la démarche
- Normalisation des développements
- Définition des bonnes pratiques
- Documentation et centralisation de la documentation
- Etat des lieux des applicatifs
- Modularisation et utilisation des programmes de service
- Migration progressive d’une base de données DB2 vers une base de données SQL
- Accès aux données avec SQL
- Implication des équipes de développement
Adhésion à la démarche
Il est primordial que la démarche de modernisation soit partagée par tous. C’est-à-dire :
- Par la direction de votre entreprise
- Par la DSI
- Par les équipes de développement
Pour être efficace, cette démarche doit être comprise de tous et avoir l’adhésion de chacun.
Cela car elle nécessite des moyens (essentiellement du temps), de la rigueur et l’implication de tous les acteurs.
Il est important que la direction de votre entreprise ait conscience que :
- La modernisation est nécessaire au bon fonctionnement et aux évolutions futures des applications qui reposent sur l’IBMi.
- L’IBMi est une machine moderne, en phase avec son époque, capable de s’interfacer avec tous les autres systèmes actuels. Robuste, rapide, économique l’IBMi porte actuellement le cœur de l’activité de votre entreprise, il est primordial de maintenir ce système à niveau.
La dette technique accumulée au fil des années peut être « remboursée », et cela doit être fait pour pouvoir profiter encore longtemps des investissements déjà réalisés dans la mise en place des applications spécifiques à votre entreprise et spécifiques à votre activité.
- Quitter l’IBMi pour un autre système peut être une solution. Mais c’est une opération longue, couteuse et risquée. C’est une solution sur laquelle de nombreuses entreprises se sont déjà « cassés les dents ».
- Il est, selon moi, nettement plus judicieux et beaucoup plus économique de capitaliser sur vos acquis en modernisant vos applicatifs plutôt que de chercher à les remplacer à l’identique ou presque sur un autre support.
- Moderniser les applicatifs IBMi est un investissement qui ne pourra être mener à bien que s’il est appuyé par la direction de l’entreprise et uniquement si celle-ci donne les moyens à ses équipes de se lancer pleinement dans cette démarche.
Il est important que la DSI ait conscience que :
- La modernisation nécessite du temps et qu’il va donc falloir en accorder à ses équipes pour la mettre en œuvre.
En effet, une équipe sous pression d’échéances de livraison de projets ne prendra pas le temps de faire « bien », elle se contentera de faire « vite ». Elle vivra la démarche de modernisation comme une contrainte lui demandant du temps dont elle ne dispose déjà pas. Elle ne percevra pas cette démarche comme un investissement, et cherchera à s’y soustraire à la moindre occasion plutôt que de la porter.
- La modernisation réduira les coûts des développement futurs.
La maitrise et la connaissance des applicatifs, la mise en place de services évitant la redondance de code, l’homogénéisation des méthodes de développements, la suppression des programmes obsolètes : toutes ces étapes, une fois réalisées, permettront de gagner du temps dans la réalisation de vos projets.
Le temps nécessaire à la modernisation sera donc récupéré par la suite.
- Certains développeurs peuvent aussi se montrer réfractaires à l’idée de sortir de leur zone de confort en devant changer leurs habitudes de développement. C’est pourquoi la démarche de modernisation doit être portée par la DSI. Il va falloir contrôler que tous les développeurs y participent et la mettent en œuvre. En effet, il est contreproductif de résorber la dette technique d’un côté si c’est pour continuer à la générer d’un autre.
Il est important que les développeurs aient conscience que :
- La modernisation est nécessaire et qu’elle pérennise la présence de l’IBMi au cœur de l’infrastructure technique de l’entreprise et par conséquent leur présence en tant que développeurs spécialisés sur ce système au sein de l’entreprise.
- La modernisation est formatrice et donc très positive.
Cette démarche va probablement changer les habitudes des développeurs. Mais il est, me semble-t-il, particulièrement motivant d’avoir à appréhender de nouvelles façons de développer lorsque celles-ci sont plus efficaces et plus performantes. Les développeurs ont tout à gagner à se mettre au RPG FREEFORM, à utiliser au mieux SQL, à développer des programmes de services. C’est un plus pour l’entreprise mais également un plus personnel pour chaque d’entre eux.
Ce qui a pour conséquence une grande disparité dans la façon de nommer les objets comme dans la façon d’écrire les programmes.
Normalisation des développements
Avec les années, le turnover des développeurs internes et les interventions de prestataires externes, on constate bien souvent que chacun a laissé son empreinte, son style, sa façon de développer dans les applicatifs de l’entreprise.
C’est une lapalissade mais il faut normaliser tout ça.
Mettre en place des normes de développement a pour objectifs :
- De rendre le code homogène afin qu’il soit facilement appréhendable par chaque membre vos équipes.
- D’identifier facilement les différents objets qui composent vos applications.
Définissez, ensemble, avec tous les membres de vos équipes :
- Les normes de nommage des objets.
- Les normes de codification à utiliser dans les sources de vos programmes.
Rédiger un document récapitulatif clair, consultable par chaque membre de vos équipes. Ce document doit devenir une référence, il devra être mis à disposition de chaque nouvelle personne qui rejoindra vos équipes (en interne comme en prestation). Il contribuera à sa bonne intégration et facilitera le respect et la mise en œuvre de ces normes par les nouveaux arrivants.
Définition des Bonnes Pratiques
Là aussi c’est une lapalissade mais c’est très important.
Définissez ces bonnes pratiques, ensemble, en restant à l’écoute des uns et des autres mais en finalisant la réflexion en statuant ces règles dans un document de référence (comme pour les normes de développement).
Et surtout veillez à ce ces bonnes pratiques soient respectées, quitte à développer, si nécessaire, des process de contrôle qui bloqueraient chaque mise en production ne respectant pas les préconisations établies.
Voici quelques exemples de règles de bonnes pratiques classiques dans le cadre de la modernisation :
- Respecter les normes de développement et les bonnes pratiques définies.
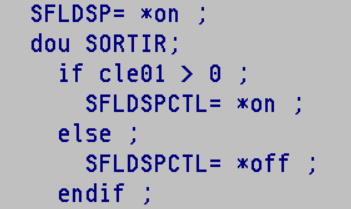
- Ecrire les nouveaux programmes en RGP FREEFORM.
- Proscrire les SELECT * dans le SQL EMBEDDED.
- Gérer les accès à la base de données par SQL.
- Ne pas créer de nouveaux fichiers physiques ou logiquesDB2, mais créer des tables, index et vues SQL.
- Convertir chaque programme RPG modifié en programmes RPGLE.
- Commenter les sources de façon claires et réfléchies en évitant les commentaires inutiles.
- Utiliser des noms de variables parlant.
- Ne jamais faire d’accès aux index dans les requêtes SQL, laisser SQL choisir ses modes d’accès aux données.
- …
Documentation et Centralisation des documents
Là aussi, cela semble évident, mais nombre d’entreprise ne documentent pas leurs traitements et s’étonnent ensuite de ne pas maîtriser leurs propres applications.
On constate fréquemment que chaque développeur s’est construit sa propre petite documentation, détaillant telle ou telle chaine de traitement, mais que ces documents ne sont ni partagés, ni à jour.
Il faut donc impérativement :
- Documenter vos applications.
Cela peut se mettre en place progressivement, en profitant de chaque nouveau projet, de chaque nouveau développement pour mettre en place cette documentation.
- Définir des modèles de document qui seront utilisables par tous.
Cela facilitera la création des documentations suivantes.
- Centraliser ces documents.
Pour que chacun puisse y accéder, que chacun puisse y ajouter sa contribution mais surtout pour que toute personne sache où rechercher ces informations.
- Faire vivre ces documents en les maintenant à jour.
Etat des lieux de vos applicatifs
Faire un état des lieux des applications qui tournent sur l’IBMi permet de quantifier la dette technique à résorber.
Les services SQL permettent en quelques requêtes d’obtenir de très nombreuses informations sur les objets de vos applications.
Elles permettent par exemple :
- D’identifier les programmes qui n’ont pas été exécutés depuis des années.
Ces programmes alourdissent vos développements alors qu’ils ne servent plus.
En effet, chaque analyse d’impact, chaque modification de base de données les prennent en compte ce qui augmente inutilement la charge de travail.
Identifier ces programmes permet de les sauvegarder leurs sources puis de les supprimer.
C’est autant de programme qui ne seront plus à moderniser.
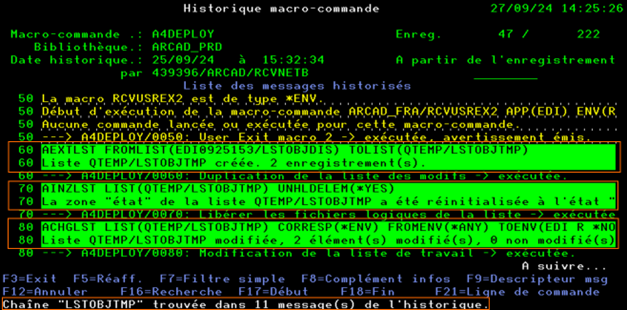
- Contrôler l’unicité des sources des programmes, de façon à n’avoir qu’un seul référentiel de sources. Avoir différentes versions de sources d’un même programme dans différentes bibliothèques est très dangereux. Les développeurs ne doivent pas avoir à s’interroger pour savoir quel est le source à modifier pour ne pas risquer d’écraser les modifications précédemment livrées en production.
- Vérifier la cohérence entre vos objets de production et votre référentiel de source.
Il est impératif de pouvoir avoir une totale confiance en son référentiel de source.
Avoir des objets de production qui ne correspondent pas aux sources du référentiel est très inquiétant. Il faut profiter de la modernisation pour vérifier et remettre la situation à plat.
- Vérifier et optimiser les requêtes SQL, identifier les plus consommatrices, vérifier et éventuellement créer les index proposés.
- Mettre en évidence les ratios suivants :
- Nombre de fichiers DB2 / Nombre de tables SQL
- Nombre de programme RPG / nombre de programmes RPGLE
- Identifier le nombre de procédures de services mises en place.
Encapsuler ces requêtes dans des programmes de façon à pouvoir les relancer régulièrement et stocker les résultats obtenus est une idée intéressante.
Cela permettra de mettre en place des métriques pouvant être remontés à la direction pour montrer que le process de modernisation est en œuvre et progresse régulièrement.
Modularisation et utilisation des programmes de service
Convertir les programmes en RPG en RPGLE : c’est bien.
Mais appréhender et mettre en place le concept de programmes de service : c’est mieux.
L’idée qui se cache derrière ce concept est de développer de petits programmes de service, facilement maintenables puisque répondant chacun à une et une seule fonctionnalité bien spécifique. Ces services pourront être ensuite consommés, à chaque instant, par les différents traitements.
Cela permet :
- D’éviter le code redondant. Puisque le code de la fonctionnalité n’est présent que dans le service et non plus dans chaque chaine de traitement qui utilise sa fonction.
- De gagner énormément de temps en maintenance puisque seul le service est à modifier en cas d’évolution de la fonctionnalité concernée.
- De gagner en performance grâce aux groupes d’activation.
En effet les groupes d’activation permettent de garder en mémoire le service précédemment appelé au sein du même groupe d’activation. Contrairement à un appel de programme classique qui va être monté en mémoire puis déchargé à chaque appel.
- D’exposer, si nécessaire, ces programmes de services très simplement grâce au serveur intégré à l’IBMi via IWS (websphère), les rendant ainsi également accessibles à des applicatifs hors IBMi.
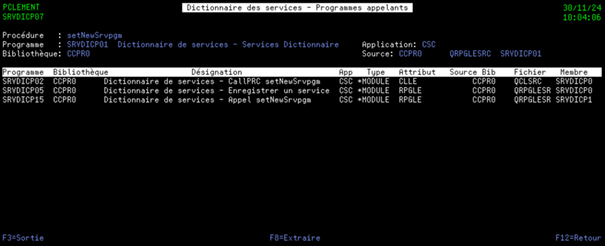
Ces programmes de services, une fois développés, doivent pouvoir être réutilisés par tous et il ne faut pas qu’une même fonctionnalité face l’objet de plusieurs programmes de service, c’est l’opposé du but recherché.
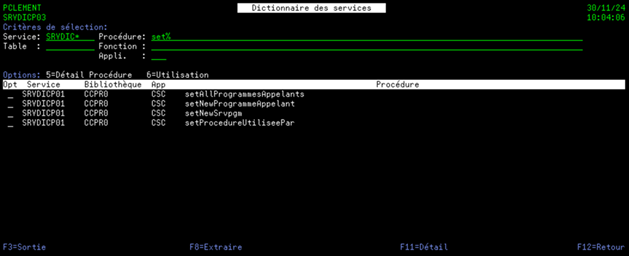
Pour cela, il est fortement conseillé de mettre en place un dictionnaire de service permettant de :
- Rechercher les services et les procédures exportées :
- par les tables mise à contribution
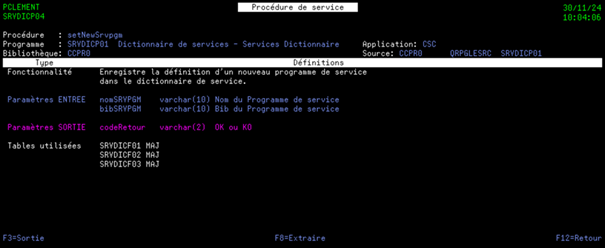
- D’identifier les paramètres en entrée et en sortie de chaque procédure exportée.
En indiquant leur rôle et leur format.
- De visualiser quelles tables sont utilisées par chaque procédure exportée.
Ceci permettra aux développeurs de trouver facilement le service qui répondra à leur besoin et évitera qu’une même fonctionnalité fasse l’objet de plusieurs services.
Migration progressive d’une base de données DB2 à une base de données SQL
Sans rentrer dés à présent dans le processus de conversion massive de toute la base de données DB2 en base SQL, il est possible de commencer à se dire que toute nouvelle création d’élément de la base de données se fera en SQL.
Ceci en remplaçant les créations de fichiers physiques ou logiques DB2, par des créations de tables, index ou vues SQL.
Ceci permettra de commencer progressivement la bascule de la base de données vers SQL, tout en permettant aux équipes à s’habituer à ce nouveau process.
Accès aux données avec SQL
Cette étape est un peu particulière car il ne s’agit pas juste de dire : il faut faire du SQL EMBEDDED. C’est-à-dire qu’accéder aux données, dans les programmes RPG, par SQL c’est une chose, mais il faut le faire bien.
En effet, cela ne consiste pas simplement à remplacer un CHAIN classique par un SELECT SQL. Cela va bien au-delà de ça.
Par exemple :
Utiliser un CURSEUR SQL, faire une boucle de lecture du curseur, pour ensuite faire différents SELECT à partir des données de chaque enregistrement lu dans le curseur est un non-sens.
Le programme va effectivement accéder aux données par SQL mais sans profiter de la puissance offerte par SQL et les temps de réponses seront donc quasiment similaires à ceux obtenus par un accès « classique » à la base de données.
Alors que si le curseur est fait à partir d’une requête unique comportant des jointures sur les tables lues par les différents SELECT évoqués précédemment ; alors il est plus que probable qu’il y aura un gain de performance significatif.
Outre les gains de performance, SQL apporte également de nombreuses fonctions qui faciliteront les développements.
SQL est un langage qui évolue constamment, et c’est également le cas sur l’IBMi.
De nouvelles fonctions font leur apparition régulièrement.
Et ces fonctions permettent par exemple :
- De générer un fichier XML en quelques lignes
- De lire et intégrer un fichier JSON en une seule requête
- D’envoyer un mail avec le résultat de la requête sous forme de fichier Excel très simplement
Ce ne sont que quelques exemples parmi tant d’autres…
Il est aujourd’hui inconcevable de se passer de SQL même et surtout en tant que développeur IBMi.
Vos équipes auront peut-être, selon leur niveau, besoin de formations avancées sur SQL mais il est indispensable qu’elles sachent utiliser à bon escient les jointures, les tables temporaires, les fonctions SQL afin qu’elles puissent mettre en place des requêtes optimisées, performantes et maintenables facilement dans leurs programmes.
Sans quoi les gains en performance seront restreints alors qu’ils peuvent être tellement importants lorsque les requêtes tirent pleinement profit des possibilités offertes par SQL.
C’est pourquoi, il faudra également présenter aux équipes de développement les outils d’optimisation SQL mis à disposition sous ACS tels que :
- Visual Explain
- SQL Performance Center
- Le Conseil à la création d’index
Implication des équipes de développement
Ces étapes de modernisation sont réalisées par les équipes de développements.
Nous l’avons vu, elles vont avoir besoin de temps pour les mettre en œuvre, mais pas seulement. Il va falloir, si nécessaire, les impliquer en les faisant monter en compétence.
Ceci en :
- Les formant au RPG FREEFORM si elles ne le connaissent pas déjà
- Les formant aux concepts des programmes de services
- Les formant au SQL avancé
- Les incitant à assister aux événement IBMi qui sont si riches, si formateurs et desquels elles retiendront de nombreuses nouveautés à mettre en pratique.
La démarche de modernisation peut être perçue comme une contrainte mais si c’est le cas c’est que :
- soit elle a été mal introduite,
- soit les développeurs n’ont pas les moyens (le temps toujours le temps) de les mettre en pratique et d’en tirer profit.
Si on lui laisse la possibilité de profiter de la modernisation pour monter en compétence, il n’y a aucune raison pour qu’un développeur perçoive la démarche comme une contrainte et n’y adhère pas. Ou alors il est totalement réfractaire au changement mais ça c’est une autre histoire…
Pour conclure
Ces premières actions ne règleront pas tout, il vous faudra certainement vous outiller ou faire appel à des spécialistes pour répondre à la mise en place du DEVOPS, pour convertir de façon automatique tous vos sources RPG/RPGLE en FREEFORM et pour transformer toutes vos bases DB2 en bases SQL. C’est un fait.
Mais ces actions sont, elles, à la portée de tous et constituent un grand pas dans la démarche de modernisation.
Je détaillerai dans de futures publications comment réaliser telles ou telles étapes abordées de façon synthétique dans ce premier post.
N’hésitez pas à me faire part de vos remarques et/ou de vos questions, je me ferai un plaisir d’y répondre.
Je remercie, encore une fois Pierre-Louis BERTHOIN et Nathanaël BONNET pour la tribune qu’ils m’ont offerte.
J’espère que cet article vous a intéressé et qu’il apportera sa contribution à vos différents projets de modernisation.
Je vous remercie et vous dit à bientôt…