

Date source de vos programmes
On est amené quand on fait des analyses à regarder les dates de source, on constate que ces dates sont à null pour tous les objets de type ILE.
Vous avez une vue QSYS2.PROGRAM_INFO qui permet d’avoir ces informations sur les programmes, un peu comme la commande DSPPGM.
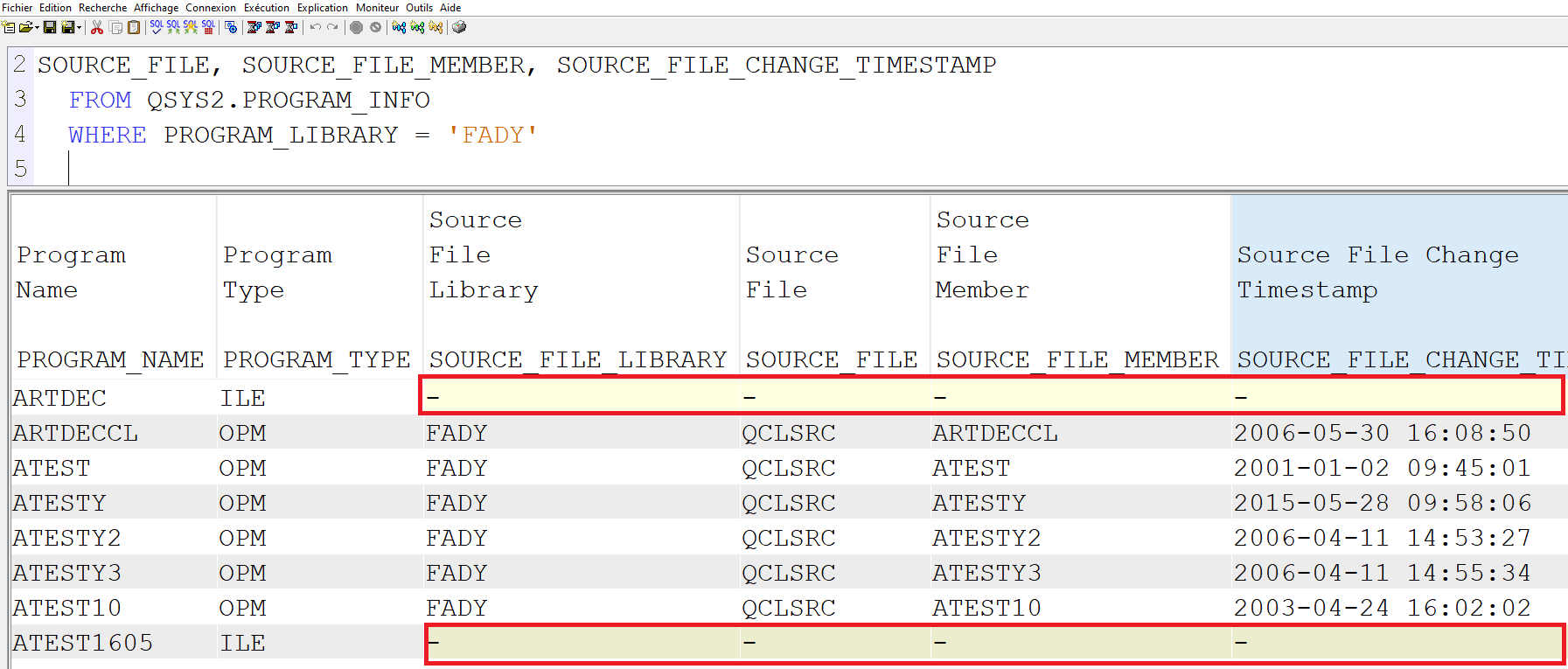
Voici pourquoi : quand vous travaillez en OPM vous compilez des sources qui deviennent des programmes; quand vous travaillez en ILE, vous compilez des sources qui deviennent des modules, puis vous les assemblez pour créer des programmes et du coup une date de source sur un programme ILE ne veut rien dire.
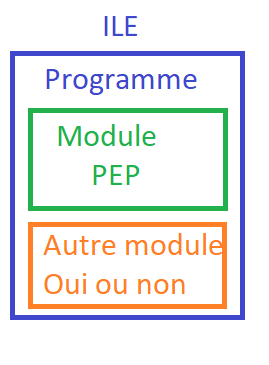
En réalité un programme a un module qui s’appelle point d’entrée programme qui, quand on travaille en BND (CRTBND*), est le seul module placé dans qtemp qui est assemblé pour créer votre programme.
On voit donc que si on veut, on peut assimiler la date du source du programme à la date du module PEP, qui dans plus de 99 % des cas a le même nom que le programme.
On a une deuxième vue permet d’avoir les modules par programme, QSYS2.BOUND_MODULE_INFO.
Il faudra donc combiner les 2 vues.
par exemple :
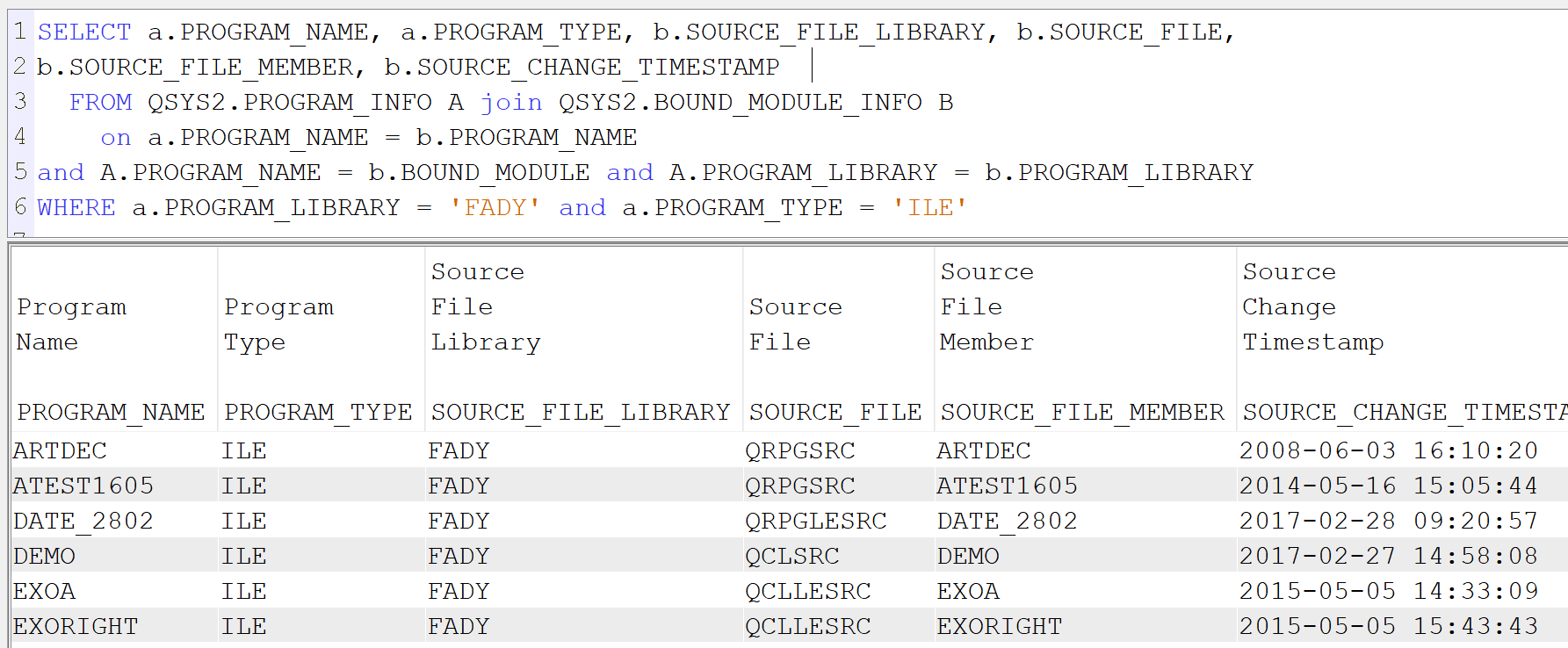
- Pour les programmes ILE
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, b.SOURCE_FILE_LIBRARY, b.SOURCE_FILE,
b.SOURCE_FILE_MEMBER, b.SOURCE_CHANGE_TIMESTAMP
FROM QSYS2.PROGRAM_INFO A join QSYS2.BOUND_MODULE_INFO B
on a.PROGRAM_NAME = b.PROGRAM_NAME
and A.PROGRAM_NAME = b.BOUND_MODULE and A.PROGRAM_LIBRARY = b.PROGRAM_LIBRARY
WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘ILE’
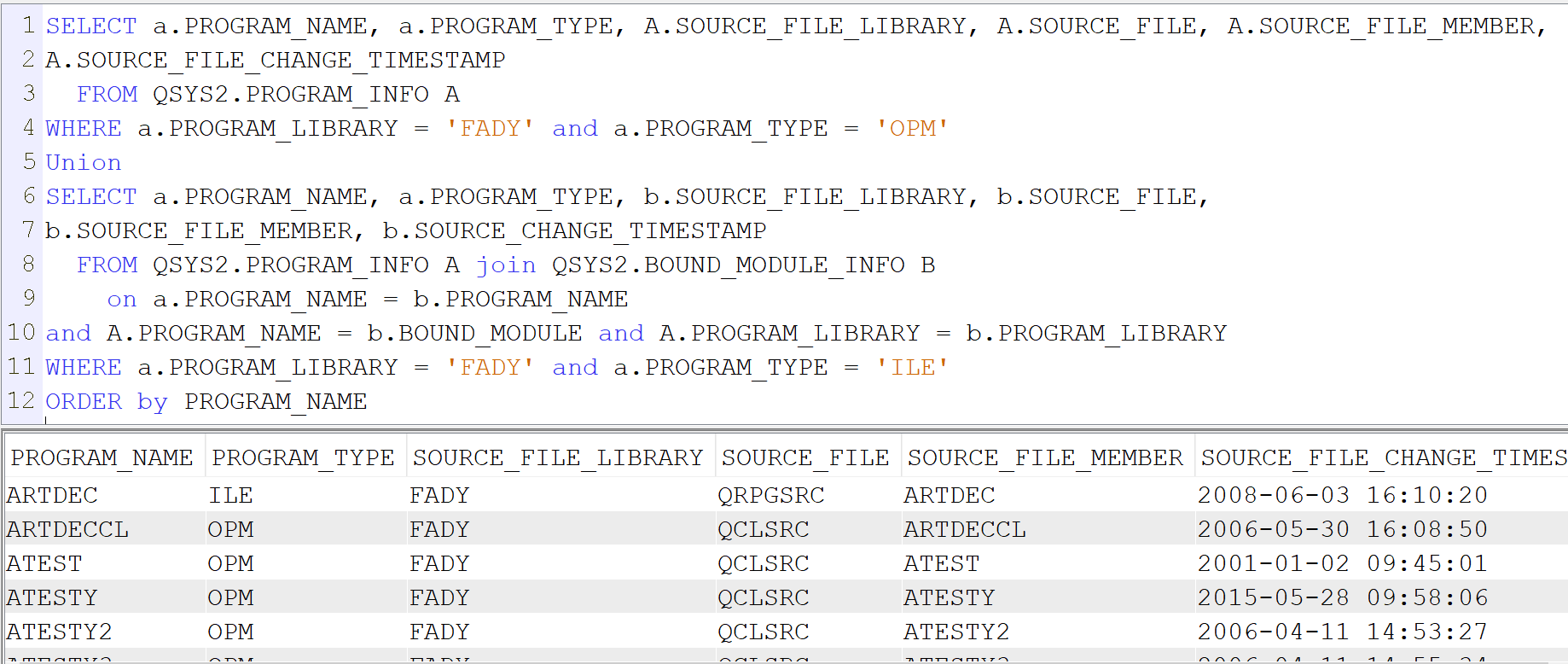
- Pour les programmes OPM
SELECT a.PROGRAM_NAME, a.PROGRAM_TYPE, A.SOURCE_FILE_LIBRARY, A.SOURCE_FILE, A.SOURCE_FILE_MEMBER,
A.SOURCE_FILE_CHANGE_TIMESTAMP
FROM QSYS2.PROGRAM_INFO A
WHERE a.PROGRAM_LIBRARY = ‘FADY’ and a.PROGRAM_TYPE = ‘OPM’
en faisant l’union des deux requêtes vous aurez les dates de tous vos programmes ILE et OPM.
Il y a sans doute d’autres solutions mais celle-ci est très simple à utiliser.

RDi : configurer et déployer les Actions de l’utilisateur

Les actions utilisateur vous permettent d’exécuter des commandes préformatées sur les objets ou sur les membres de vos filtres, en utilisant le clic droit pour exécuter l’action.
Elles sont équivalentes aux options définies par l’utilisateur que l’on peut gérer par F16 sous PDM.
Gérer les actions de l’utilisateur
La gestion des actions utilisateur est accessible par clic droit sur les objets ou membres des filtres.
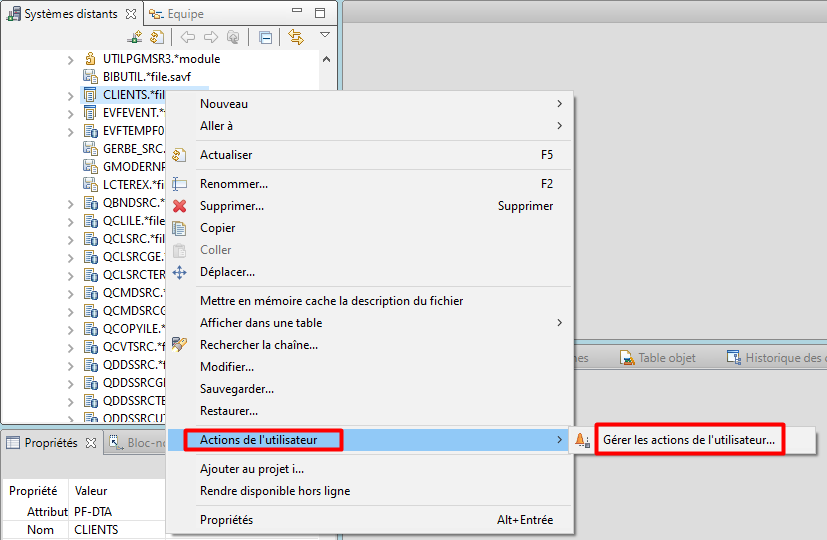
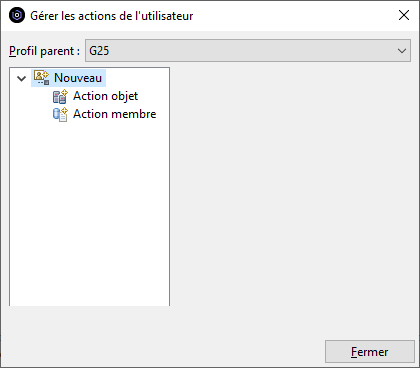
Créer une action objet
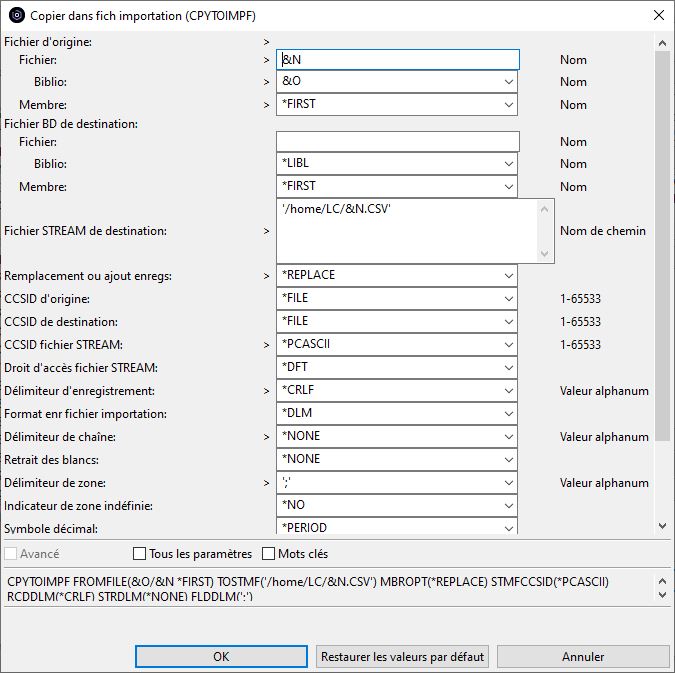
Nous allons créer une action pour exporter une table vers l’IFS au format CSV.
L’action utilisera la commande CPYTOIMPF que nous allons préformater.
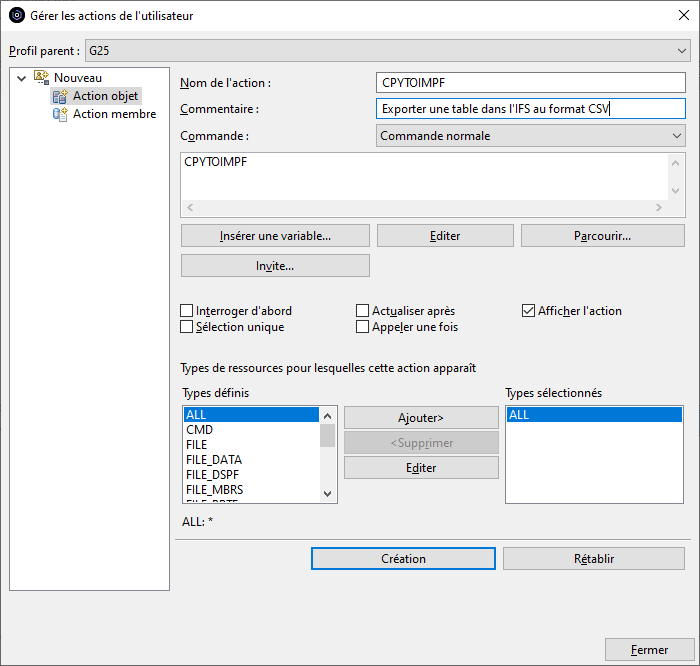
Le bouton « Insérer une variable » affiche la liste des variables que nous allons pouvoir utiliser dans les paramètres de la commande pour substituer les attributs de l’objet sur lequel l’action s’exécute :

Le bouton « Invite » permet d’afficher l’invite de commande pour compléter les paramètres :
La case « Interroger d’abord » permettra d’afficher l’invite de commande lors de l’utilisation de l’action.
Enfin, il est conseillé d’indiquer les types de ressources pour lesquelles cette action sera proposée dans le clic droit :
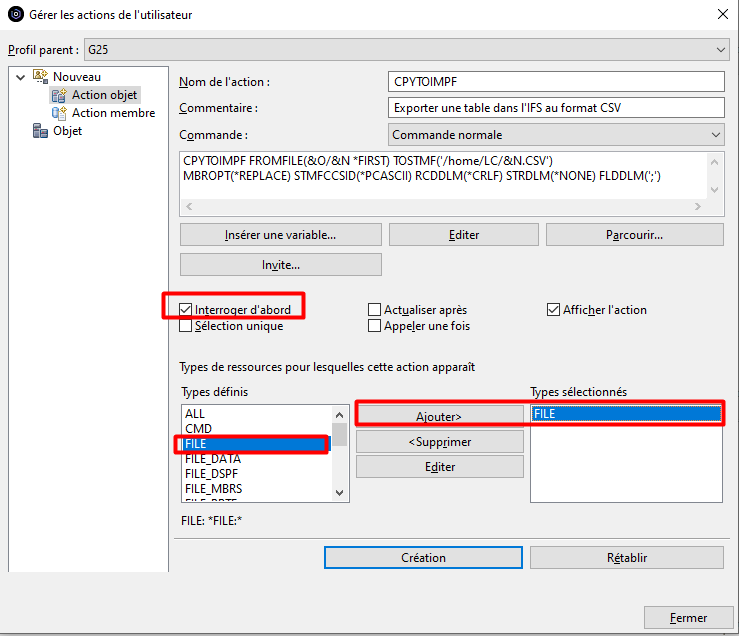
Une fois créée, l’action apparait dans le catalogue des actions Objet :
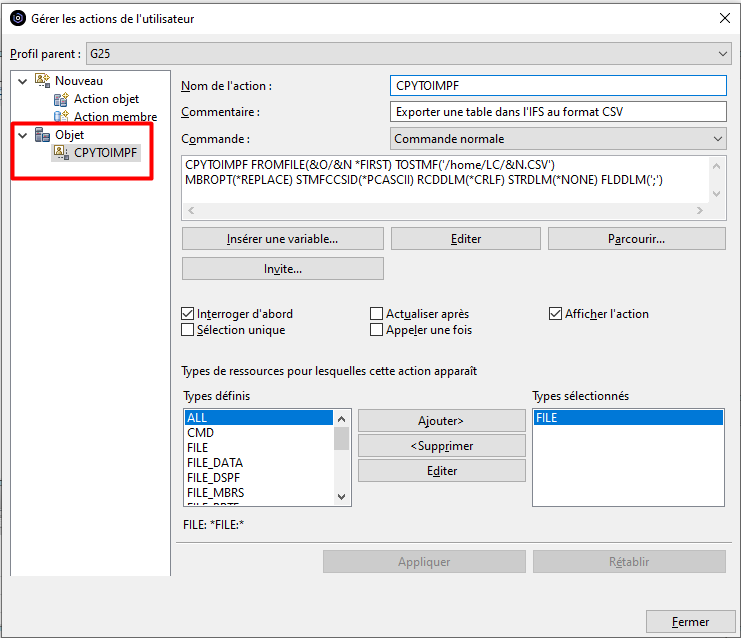
Elle peut être utilisée par clic droit sur un objet de type fichier :
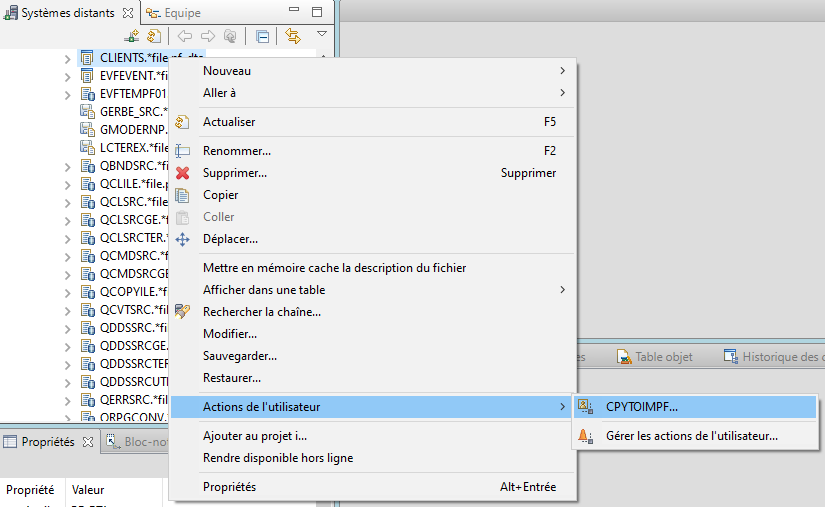
L’invite de commande est affichée avec les valeurs de substitution des variables utilisées :
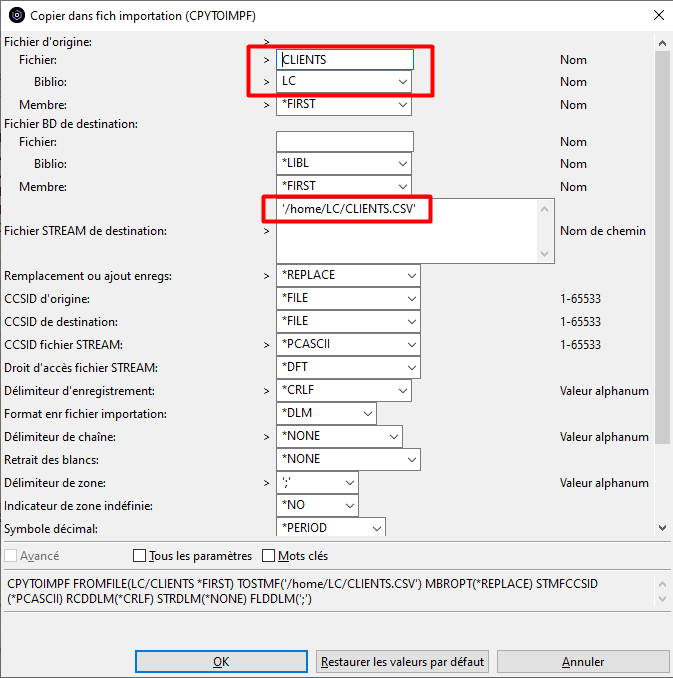
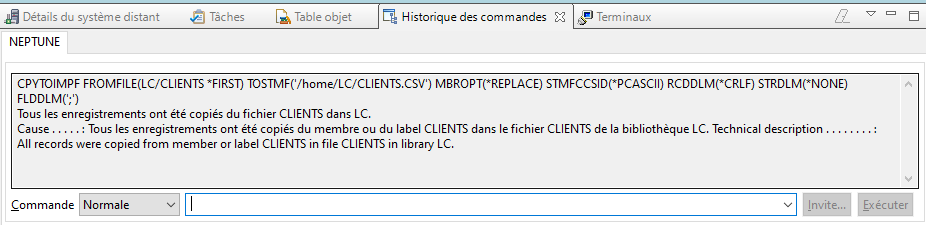
Le fichier CSV est créé dans l’IFS :
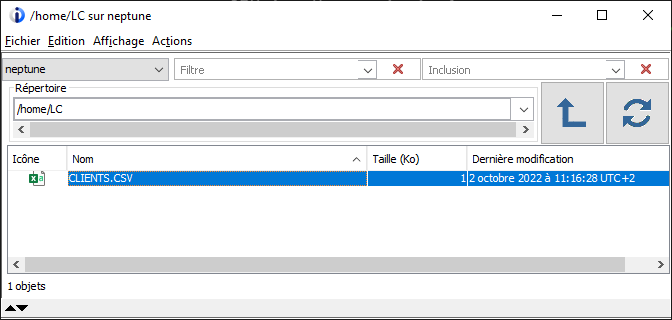
Créer une action membre
Nous allons créer une action permettant de convertir un membre source RPG 4 en RPG FREE.
Pour cela, nous avons créé une commande CVTRPGFREE basée sur un convertisseur Open Source auquel GAIA contribue.
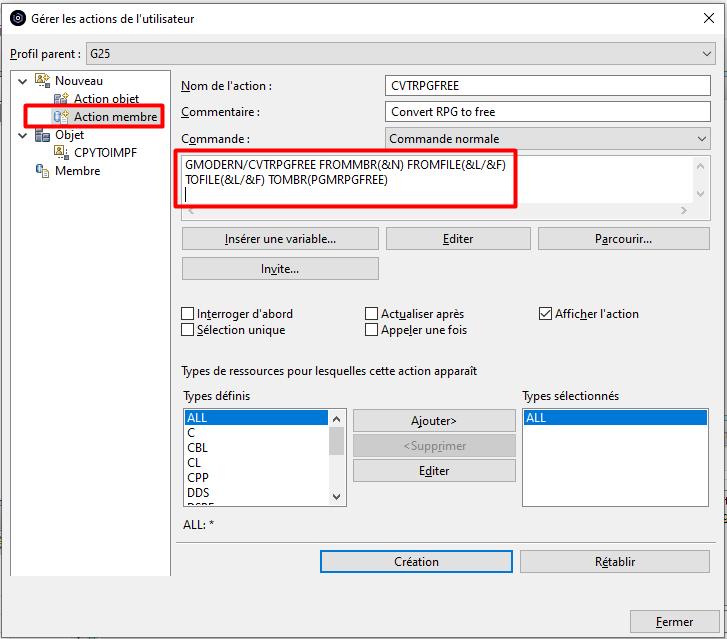
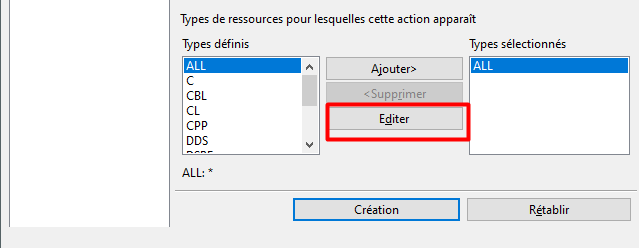
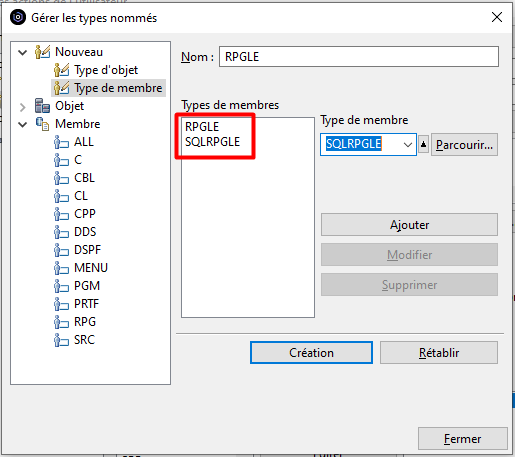
Pour limiter l’action au membres sources de type RPGLE et SQLRPGLE, nous allons Editer la liste des Types définis et créer un Type défini que nous nommerons RPGLE et qui rassemblera les types de membre RPGLE et SQLRPGLE :
Le fenêtre « Gérer les types nommés » s’ouvre :
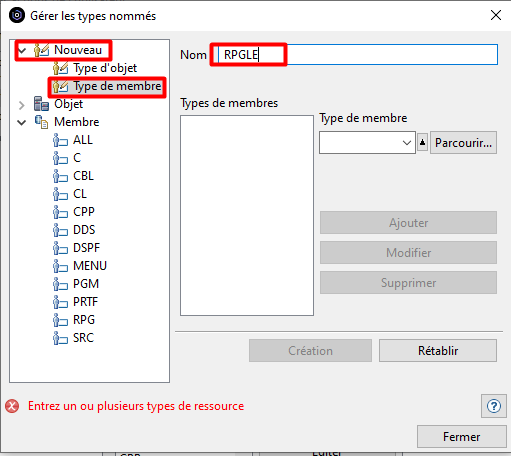
Le bouton « Parcourir » permet de choisir les types de membre existants pour les ajouter à la liste :
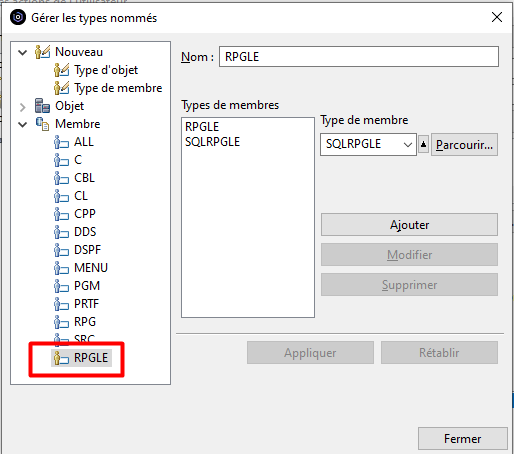
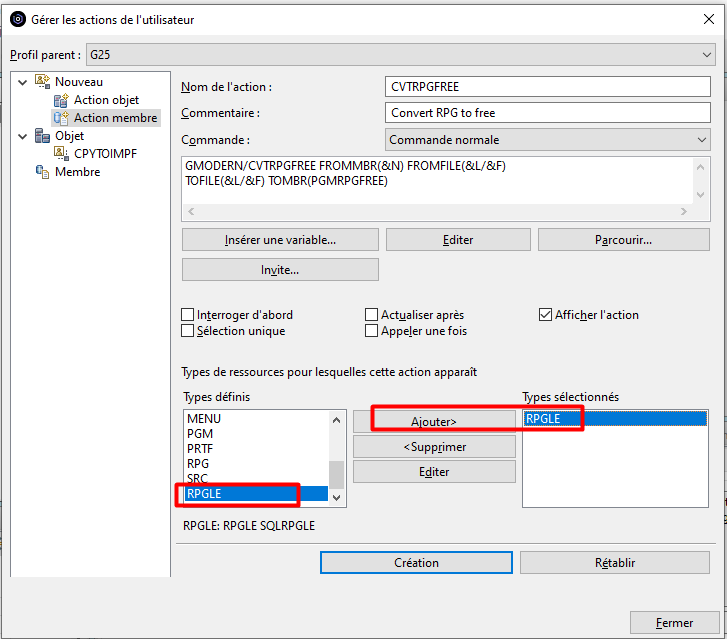
Une fois créée, l’action apparait dans le catalogue des actions Membre :
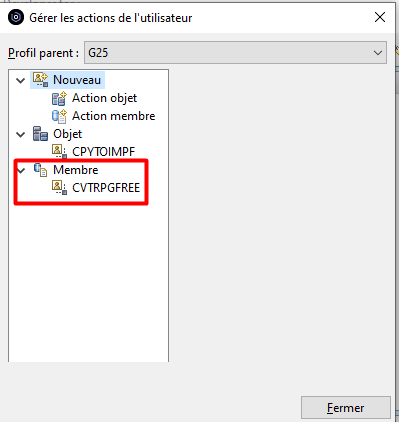
Elle peut être utilisée par clic droit sur un membre de type RPGLE ou SQLRPGLE pour le convertir en RPG FREE :
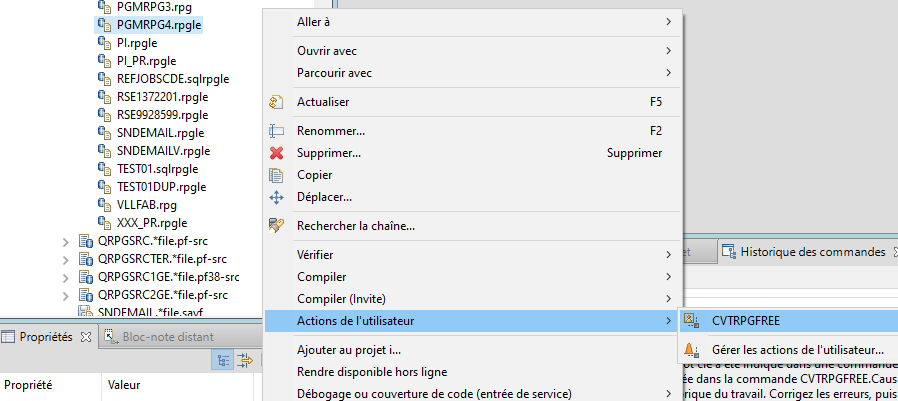
Notons qu’en effectuant une sélection de plusieurs ressources dans un filtre, on peut exécuter une action utilisateur sur toutes ces ressources par un seul clic droit.
Exemple ci-dessous : on peut exporter 4 fichiers vers l’IFS au format CSV en un seul clic
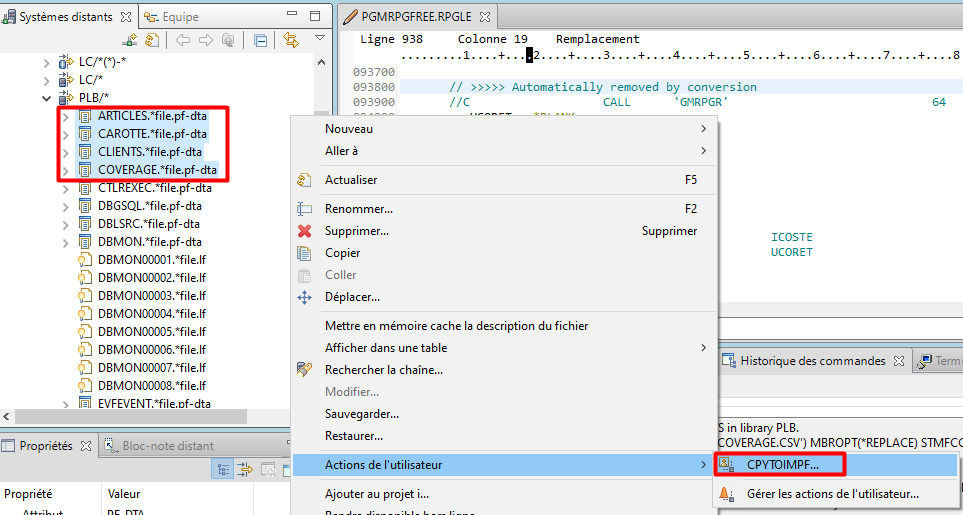
Exporter/Importer les actions utilisateur
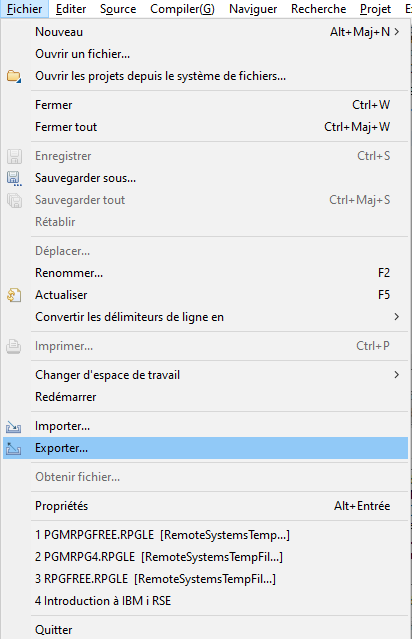
Les actions utilisateur peuvent être exportées vers un fichier de configuration à partir du menu
Fichier > Exporter > Rational Developer for i :
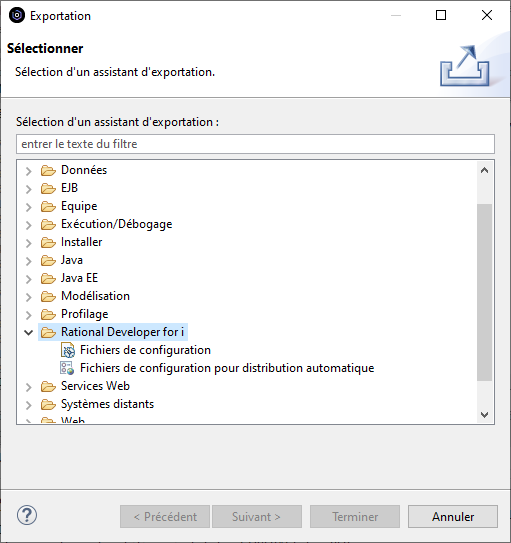
2 modes d’exportation sont possibles :
- l’export « Fichier de configuration » permet d’exporter la configuration vers un fichier local, qui pourra si on le souhaite être partagé et importé par d’autres utilisateurs vers leur Workspace.
- l’export « Fichier de configuration pour distribution automatique » permet d’exporter la configuration pour la distribuer automatiquement aux autres utilisateurs
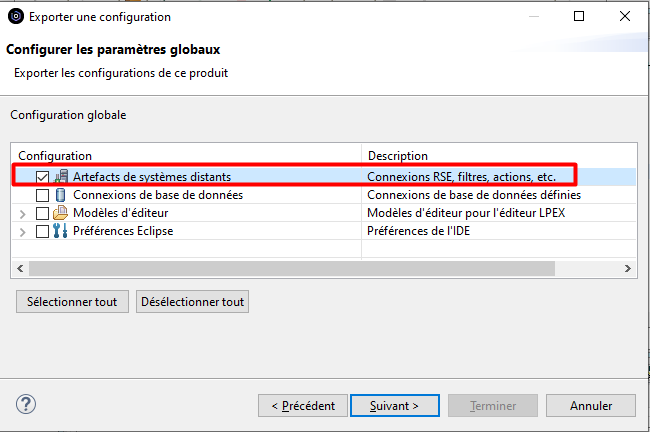
Exporter Fichier de configuration pour distribution automatique
Pour exporter les actions utilisateur, décocher toutes les cases et ne conservez que la configuration « Artefacts de systèmes distants ».
Les filtres sont exportés, lors de l’import vous perdrez donc les filtres de votre Workspace.
Ca peut être gênant, mais ça peut aussi être l’occasion de faire du ménage dans vos filtres….
Le fichier de configuration sera généré dans le répertoire suivant de l’IFS :
/QIBM/ProdData/Devtools/clientconfig
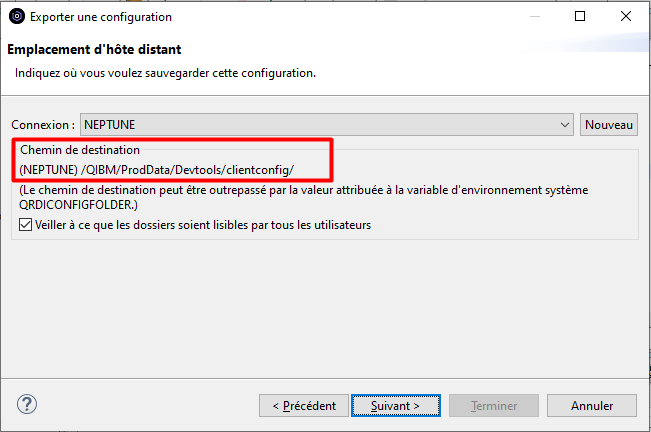
Choisissez un numéro de version pour identifier le fichier de configuration :
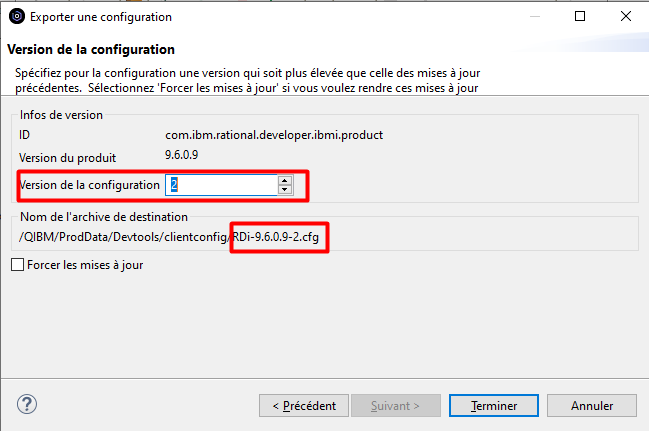
Avant de Terminer, assurez-vous d’avoir les droits d’écriture dans le répertoire de destination.
Le fichier de configuration est généré dans l’IFS pour une distribution automatique de cette configuration :
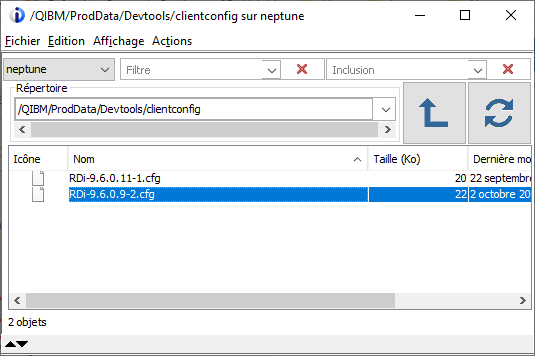
Lorsque les utilisateurs se connecteront à l’IBM i, une fenêtre d’importation leur sera automatiquement proposée :
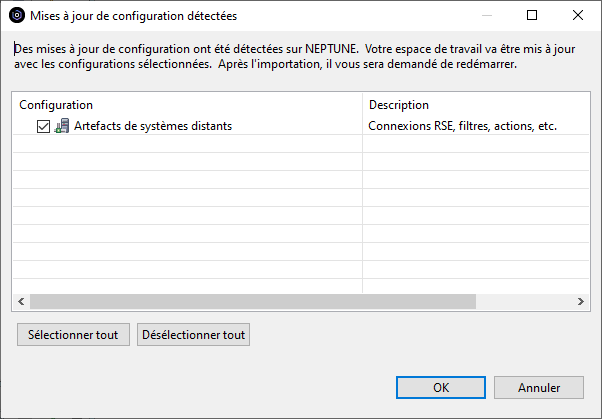
L’import peut être accepté (OK) ou pas (Annuler) mais tant qu’il n’aura pas été accepté, il sera reproposé à chaque connexion à l’IBM i par RDI.
C’est terminé !
PS :
Si le fichier de configuration a été exporté vers un fichier local par l’export Fichier de configuration au lieu de Fichier de configuration pour distribution automatique, il peut être importé de la même manière par le menu Fichier > Importation > Rational Developer for i > Fichiers de configuration. Il suffit d’indiquer l’emplacement du fichier de configuration, ensuite la procédure est identique à celle de la distribution automatique :

CONTROLER IBAN & RIB
L’International Bank Account Number, généralement nommé sous l’acronyme IBAN, est un système international de numérotationLe numéro IBAN, ou code IBAN, est affiché sur votre Relevé d’Identité Bancaire (RIB). Formalisé par une suite de chiffres et de lettres pas toujours compréhensibles pour les usagers bancaires, l’IBAN est une norme internationale ISO qui a été mise en place pour sécuriser et faciliter les échanges et transferts bancaires internationaux sur tous les continents.
Dans cet article nous allons voir comment vérifier si la clé d’un IBAN est correcte. Ensuite nous effectuerons la vérification de la clé d’un RIB. Les exemples sont basés sur un compte bancaire français.
Contrôler la clé IBAN
Structure de l’IBAN
FRKK BBBB BGGG GGCC CCCC CCCC CKK
B = code banque
G = code guichet
C = numéro de compte
K = clef
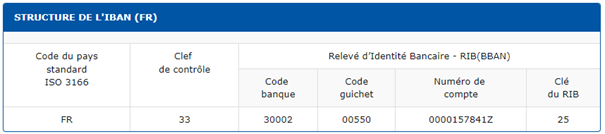
Le RIB (ou BBAN) comprend les informations suivantes :
– Le nom de la banque et de l’agence;
– Le code banque à 5 chiffres;
– Le code guichet à 5 chiffres ;
– Le numéro du compte à 11 chiffres ou lettres au maximum;
– La clé RIB, à 2 chiffres.
Le calcul de la clé IBAN est fonction de l’enchaînement entre le BBAN, le code pays (transformé en données chiffrées) et 00.
Concernant la conversion du code pays, il faut savoir que la lettre A équivaut au nombre 10, B = 11, C = 12, D = 13… jusqu’à la dernière lettre de l’alphabet Z qui vaut 35.
La formule arithmétique pour résoudre l’équation et déterminer une clé IBAN est :
Clé IBAN = 98 – ((Valeur numérique) modulo 97).
Il faut donc procéder en deux étapes :
- Reconstituer l’IBAN sous la forme BBAN + [Code Pays ISO2] + « 00 »
- Remplacer toutes les lettres de l’IBAN par le nombre qui leur correspond (entre 10 et 35)
Voici une procédure, écrite dans un programme de service, qui permet la vérification de la clé d’un IBAN.
dcl-proc checkIban export;
dcl-pi *n ind;
numIban char(27) const;
end-pi;
dcl-s count int(3) ;
dcl-s index int(3) ;
dcl-s posit int(3) ;
dcl-s stringToCalculate varchar(50) ;
dcl-c letters 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' ;
stringToCalculate = %subst(numIban:5) + %subst(numIban:1:2) + '00';
for count = 1 to %len(%trim(stringToCalculate)) ;
index = %scan(%subst(stringToCalculate:count:1):letters) ;
if index > 0 ;
posit = count - 1 ;
index += 9 ;
stringToCalculate = %subst(stringToCalculate : 1 : posit)
+ %trim(%char(index))
+ %subst(stringToCalculate : posit + 2) ;
endif ;
endfor;
return (98 - %rem(%DEC(%trim(stringToCalculate) : 50 : 0):97)
= %DEC(%SUBST(numIban : 3 : 2) : 2 : 0)) ;
end-proc;
Ajouter le code suivant dans le source de liage
EXPORT SYMBOL("CHECKIBAN")
Utilisation du contrôle
// Déclaration
dcl-PR checkIban ind ;
P_Iban char(27) const;
end-pr ;
// Appel
retour = checkIban('FR3330002005500000157841Z25');
if retour;
dsply 'IBAN Correct' ;
else ;
dsply 'IBAN Faux' ;
endif;
Contrôler la clé RIB
Structure du RIB (voir paragraphe précédent, c’est un composant de l’IBAN)
Le numéro de RIB permet l’identification du compte pour une utilisation Nationale. C’est le numéro à transmettre pour effectuer un virement en France.
La clé RIB est une formule mathématique, qui ne peut s’appliquer que sur des valeurs numériques. Il convient donc de remplacer les éventuelles lettres présentes dans les données du RIB avant de pouvoir en calculer la clé.
Chaque lettre est remplacée par son équivalent numérique :
A,J = 1
B,K,S = 2
C,L,T = 3
D,M,U = 4
E,N,V = 5
F,O,W = 6
G,P,X = 7
H,Q,Y = 8
I,R,Z = 9
La clé peut alors être calculée avec la formule suivante :
Clé RIB = 97 – ( ( 89 x Code banque + 15 x Code guichet + 3 x Numéro de compte ) modulo 97 )
Voici une procédure, écrite dans un programme de service, qui permet la vérification de la clé d’un RIB.
dcl-proc checkRib export;
dcl-pi *n ind;
numRib char(23) const ;
end-pi;
dcl-s count int(3) ;
dcl-s index int(3) ;
dcl-s posit int(3) ;
dcl-s stringToCalculate varchar(23) ;
dcl-c letters 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' ;
stringToCalculate = numRib ;
for count = 1 to %len(%trim(stringToCalculate)) ;
index = %scan(%subst(stringToCalculate:count:1) : letters) ;
if index > 0;
posit = count - 1 ;
select ;
when index >= 10 and index <= 18 ;
index -= 9 ;
when index >= 19 ;
index -= 17 ;
endsl ;
stringToCalculate = %subst(stringToCalculate : 1 : posit)
+ %trim(%char(index))
+ %subst(stringToCalculate : posit + 2) ;
endif ;
endfor ;
return (97 - %rem(
(%DEC(%subst(stringToCalculate:1:5) : 5 : 0)*89
+ %DEC(%subst(stringToCalculate:6:5) : 5 : 0)*15
+ %DEC(%subst(stringToCalculate:11:11) : 11 : 0)*3)
:97)
= %DEC(%SUBST(stringToCalculate : 22 : 2) : 2 : 0)) ;
end-proc;
Ajouter le code suivant dans le source de liage
EXPORT SYMBOL("CHECKRIB")
Utilisation du contrôle
// Déclaration
dcl-PR checkRib ind ;
P_Rib char(23) const ;
end-pr ;
// Appel
retour = checkRib('3000200550044AB57O41Z68') ;
if retour;
dsply 'RIB Correct' ;
else ;
dsply 'RIB Faux' ;
endif;

/Include contre /Copy
On entend beaucoup de choses, je vais essayer de vous clarifier un peu les choses
Les directives /COPY et /INCLUDE sont identiques sauf qu’elles sont gérées différemment par le précompilateur SQL, en gros si vous codez avec un Source en SQLRPGLE.
Sur la commande CRTSQLRPGI vous avez le paramètre RPGPPOPT
Permet d’indiquer si le compilateur ILE RPG va être appelé pour prétraiter le membre source avant lancement de la
précompilation SQL. Cette étape sur le membre source SQL permet de traiter certaines instructions de compilation
avant la précompilation SQL. Le source prétraité est placé dans le fichier QSQLPRE de la bibliothèque QTEMP.
Il servira à la précompilation SQL. puis à la complilation RPGLE
3 valeurs possibles sont :
*NONE
Le compilateur n’est pas appelé pour le prétraitement.
*LVL1
Le compilateur est appelé pour le prétraitement afin de développer /COPY et traiter les instructions de compilation conditionnelles à l’exception de /INCLUDE.
*LVL2
Le compilateur est appelé pour le prétraitement afin
de développer /COPY et /INCLUDE et traiter les instructions de compilation conditionnelles
voici un exemple
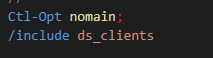
Un module utilise la description d’un fichier qui est dans un include
le source à inclure

sa déclaration dans le programme ou le module
. 
Compile avec *NONE
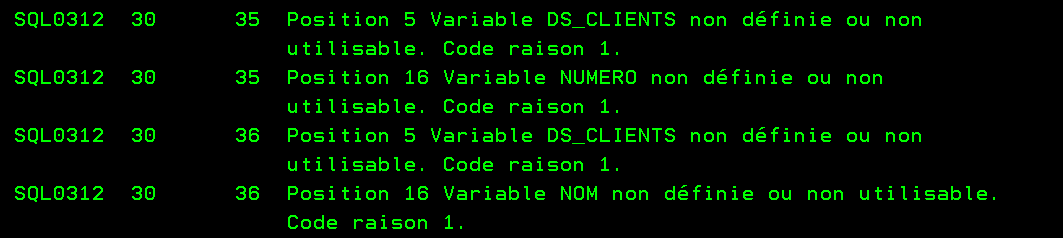
Compile avec *LVL2
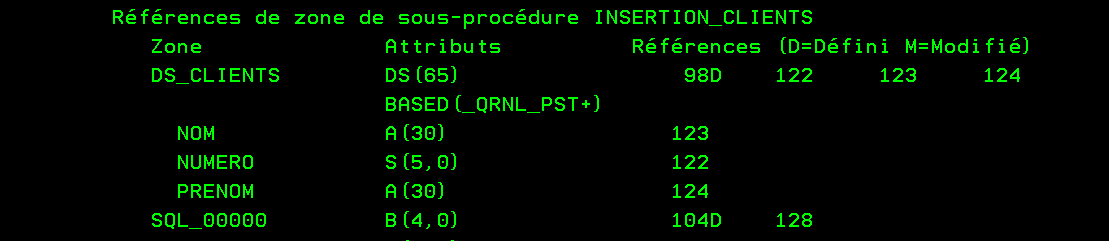
Remarque
Si vous faites du SQLRPGLE, ce qui est fortement recommandé à ce jour forcer cette valeur *LVL2 comme ca pas de doute !
Conversion RPG FREE
Il existe de nombreuses méthodes pour convertir du code RPGLE colonné vers du RPG FREE.
La plupart des conversions se passent sans problème, mais on constate que le code RPG ou RPG IV colonné pouvait être plus permissif et permettre des choses que le FREE ne tolère pas.
Voici un exemple qu’on a rencontré récemment, on est d’accord il résulte d’une incohérence dans le développement initial,
mais jusque la ça passait à l’exécution.
En RPGIV colonné
c z-add 9999999 zone7 7 0
c z-add zone7 zone5 5 0
c eval *inlr = *on
Quand vous exécutez ce code, il n’y a pas d’erreur, on est d’accord le résultat est faux …
En RPGIV FREE
**free
Dcl-S zone5 Zoned(5:0);
Dcl-S zone7 Zoned(7:0);
ZONE7 = 9999999 ;
ZONE5 = ZONE7 ;
*inlr = *on ;
Quand vous exécutez ce code, il y a un plantage, ce qui est normal
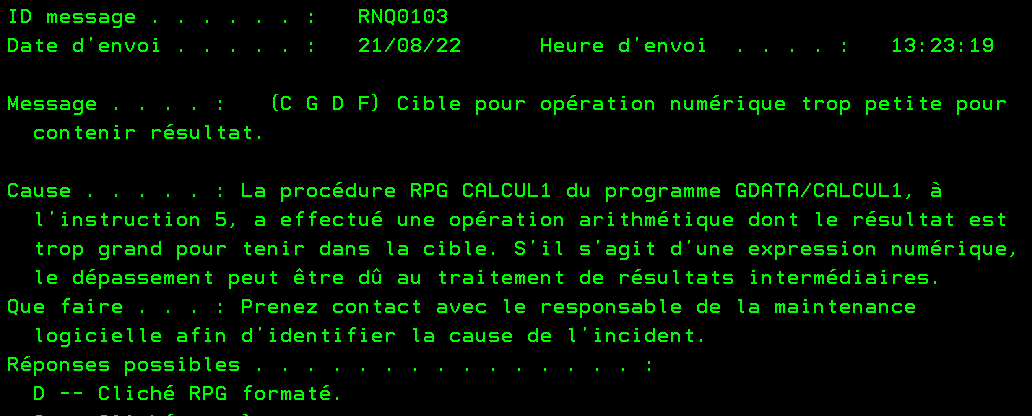
Conclusion
On peut donc tomber sur quelques cas que le RPG III ou IV acceptait mais que le nouveau code ne permet plus.
C’est bien sûr du code de mauvaise qualité, et la réécriture peut s’avérer nécessaire surtout si on rencontre des instructions déstructurantes comme des GOTO par exemple.
Utilisation du MD5 sur votre IBM i
Bien que le MD5 ne soit plus utilisé pour l’encryption, il est toujours utilisé pour valider l’authenticité et la conformité des fichiers.
Qu’est-ce qu’un MD5
Un md5 est une chaine de 16 caractères composée de symboles hexadécimaux. Il s’agit en réalité du nom de l’algorithme utilisé pour générer la chaine.
Comme indiqué précédemment son usage est le contrôle d’intégrité des fichier, par exemple lors du partage d’un fichier, on peut mettre à disposition le MD5 afin de contrôler que le téléchargement du fichier s’est bien passé ou que le fichier n’a pas été modifié entre temps.
Pour la suite nous aurons besoin d’un fichier, par simplicité j’utiliserai un simple .txt qui contient la phrase « This is not a test! » présent dans mon répertoire de l’ifs.
| Fichier dans l’ifs | /home/jl/file.txt |
| Contenu du fichier | This is not a test! |
| md5 | EDA20FB86FE23401A5671734E4E55A12 |
QSH – md5sum
La première méthode pour générer le MD5 d’un fichier est d’utiliser la commande unix md5sum via QSH :
$ /QOpenSys/pkgs/bin/md5sum /home/jl/file.txt
eda20fb86fe23401a5671734e4e55a12 /home/jl/md5.txtLa fonction retourne le hash et le chemin du fichier.
RPGLE – _cipher
Il est également possible de générer le MD5 via RPG en exploitant la procédure externe cipher.
Je ne m’épancherai pas sur son implémentation complète ici, car bien plus complexe que les deux autres méthodes présentées. De plus, passer par cette méthode, n’est plus le sens de l’histoire.
// Déclaration de la procédure
dcl-pr cipher extproc('_cipher');
*n pointer value;
*n pointer value;
*n pointer value;
end-pr;
// Appel de la procédure
cipher(%ADDR(receiver) : %ADDR(controls) : %ADDR(source));Lien vers la documentation IBM pour plus d’informations :
https://www.ibm.com/docs/en/i/7.4?topic=ssw_ibm_i_74/rzatk/CIPHER.htm
SQL – hash_md5
En sql on retrouve la fonction hash_md5, qui retourne le hash d’une chaine de caractère passée en paramètre.
❗ Attention à l’encodage de votre chaine de caractères. ❗
Pour que le résultat soit cohérent entre différents systèmes il faut commencer par convertir la chaine de caractère en UTF-8 :
VALUES CAST('This is not a test!' AS VARCHAR(512) CCSID 1208); -- 1208 = UTF-8
-- Retour : This is not a test!Le résultat est plutôt flagrant ! D’accord pas vraiment… Par contre si on regarde la valeur hexadécimale de la chaine avec et sans conversion :
VALUES HEX('This is not a test!');
-- Retour : E38889A24089A2409596A3408140A385A2A34F
VALUES HEX(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : 54686973206973206E6F742061207465737421Le hachage se fait en hexadécimal, donc le résultat ne serait pas le même sans conversion préalable.
Il suffit maintenant de hacher notre chaine de caractères :
VALUES HASH_MD5(CAST('This is not a test!' AS VARCHAR(512) CCSID 1208));
-- Retour : EDA20FB86FE23401A5671734E4E55A12On obtient donc la même valeur que celle que l’on a obtenu précédemment (puisque que le contenu de notre fichier est strictement égale à cette chaine de caractère).
La dernière étape est de générer le MD5 directement à partir du fichier, pour cela il suffit d’utiliser la fonction GET_BLOB_FROM_FILE :
VALUES HASH_MD5(GET_BLOB_FROM_FILE('/home/jl/file.txt')) WITH CS;
-- Retour : EDA20FB86FE23401A5671734E4E55A12Autres algorithmes de hash
Il existe d’autres algorithmes de hash qui permettent de hacher du texte et des fichiers.
Trois autres algorithmes sont généralement disponibles :
- sha1 (qui génère une chaine de 20 de long)
- sha256 (qui génère une chaine de 32 de long)
- sha512 (qui génère une chaine de 64 de long)
QSH
| Commande | Résultat |
| /qopensys/pkgs/bin/sha1sum /home/jl/file.txt | 10e2e89feb9287eea7a4b7b849b7a380d95c05b9 /home/jl/file.txt |
| /qopensys/pkgs/bin/sha256sum /home/jl/file.txt | ff8fb31c076b42fd63377e7ea4747f98c34291ac6e5f53cfd3940913bc9d7d37 /home/jl/file.txt |
| /qopensys/pkgs/bin/sha512sum /home/jl/file.txt | 658efb990d2765ca65adb570daa198ef6bee55e39d3a7b7fa31270c35fdf9ee523ce638dea4796ea8923a2ad428e23d23b62175b26494fa8fdca49d5e85ce502 /home/jl/file.txt |
SQL
| Syntaxe | Résultat |
| VALUES HASH_SHA1(CAST(‘This is not a test!’ AS VARCHAR(512) CCSID 1208)); | 10E2E89FEB9287EEA7A4B7B849B7A380D95C05B9 |
| VALUES HASH_SHA256(CAST(‘This is not a test!’ AS VARCHAR(512) CCSID 1208)); | FF8FB31C076B42FD63377E7EA4747F98C34291AC6E5F53CFD3940913BC9D7D37 |
| VALUES HASH_SHA512(CAST(‘This is not a test!’ AS VARCHAR(512) CCSID 1208)); | 658EFB990D2765CA65ADB570DAA198EF6BEE55E39D3A7B7FA31270C35FDF9EE523CE638DEA4796EA8923A2AD428E23D23B62175B26494FA8FDCA49D5E85CE502 |
Pour plus de détails
MD5 : https://fr.wikipedia.org/wiki/MD5
md5sum : https://fr.wikipedia.org/wiki/Md5sum
Fonction sql HASH() : https://www.ibm.com/docs/en/i/7.4?topic=sf-hash-md5-hash-sha1-hash-sha256-hash-sha512
Fonction sql BLOB() : https://www.ibm.com/docs/en/i/7.4?topic=functions-get-blob-from-file
CCSID : https://www.ibm.com/docs/en/i/7.4?topic=information-ccsid-values-defined-i
cypher : https://www.ibm.com/docs/en/i/7.4?topic=ssw_ibm_i_74/rzatk/CIPHER.htm
Utilisation du catalogue DB2
Il existe de nombreuses tables dans QSYS qui constituent le catalogue DB2,
Ces tables sont accessibles par des vues qui se trouvent dans QSYS2 de manière globale et dans les bibliothèques de vos collections SQL.
On utilise pas assez ces informations pour analyser la base de données, elles contiennent une multitude d’informations
On va faire une petit exemple:
Imaginons que nous voulons savoir ou est utilisée une zone
Nous fixerons la database par set schema , pour éviter les qualifications
exemple de manière globale
SET SCHEMA QSYS2
On va utiliser une vue qui s’appelle SYSCOLUMNS qui contient les zones de votre database
SELECT
A.SYSTEM_COLUMN_NAME,
A.SYSTEM_TABLE_NAME,
A.SYSTEM_TABLE_SCHEMA
FROM SYSCOLUMNS A
WHERE COLUMN_NAME = ‘NUMCLI’
Vous obtenez une liste de tous les fichiers (tables, vue, PF, LF) etc …
Imaginons ensuite que vous ne vouliez que les tables ou PF vous pouvez utiliser la vue SYSTABLES
SELECT a.SYSTEM_COLUMN_NAME,
A.SYSTEM_TABLE_NAME,
A.SYSTEM_TABLE_SCHEMA
FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME
and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in(‘T’ , ‘P’)
WHERE COLUMN_NAME = ‘NUMCLI’
Vous limitez ainsi votre recherche aux tables et PF
Imaginons maintenant que vous ne vouliez que les tables et PF qui ont été utilisées sur l’année flottante (13 mois), on va utiliser la vue SYSTABLESTAT
SELECT a.SYSTEM_COLUMN_NAME,
A.SYSTEM_TABLE_NAME,
A.SYSTEM_TABLE_SCHEMA
FROM SYSCOLUMNS a join SYSTABLES b on A.SYSTEM_TABLE_NAME=b.SYSTEM_TABLE_NAME
and a.SYSTEM_TABLE_SCHEMA = b.SYSTEM_TABLE_SCHEMA and B.TABLE_TYPE in( ‘T’ , ‘P’)
join SYSTABLESTAT c on A.SYSTEM_TABLE_NAME=c.SYSTEM_TABLE_NAME
and a.SYSTEM_TABLE_SCHEMA = c.SYSTEM_TABLE_SCHEMA and c.LAST_USED_TIMESTAMP >
(current date – 13 months)
WHERE COLUMN_NAME = ‘NUMCLI’
Cette exemple n’est pas parfait, mais il vous montre qu’avec le catalogue db2 et un peu de SQL vous pouvez avoir de nombreuses informations pertinentes sur cette dernière .
Vous pouvez par exemple avoir des informations statistiques sur vos colonnes par la vue SYSCOLUMNSTAT et une vue globale avec la vue SYSFILES qui permet d’avoir un bon résumé de vos fichiers
https://www.ibm.com/support/pages/node/6486897
Voici un lien qui vous présente les vues disponibles,
https://www.ibm.com/docs/en/i/7.5?topic=views-i-catalog-tables
Contrôlez un numéro de sécu
Voici une fonction RPGLE pour contrôler un numéro de sécurité sociale.
Elle reçoit une variable caractère de 15 de long qui contient le numéro de sécu + sa clé
et renvoie un booléen indiquant si la clé calculée est différente ou égale de la clé passée.

C’est une fonction que vous pouvez inclure dans un programme de service par exemple !
Voici le code à inclure dans votre programme de service :
dcl-proc Check_Numero_Secu export;
dcl-pi *n ind;
numSecu char(15) const;
end-pi;
select;
when %SUBST(numSecu : 6 : 2) = '2A';
numSecu = %SUBST(numSecu : 1 : 5) + '19' + %SUBST(numSecu : 8 : 7);
when %SUBST(numSecu : 6 : 2) = '2B';
numSecu = %SUBST(numSecu : 1 : 5) + '18' + %SUBST(numSecu : 8 : 7);
endsl;
return (97 - (%DEC(%SUBST(numSecu : 1 : 13) : 13 : 0)
- %DEC(%DEC(%SUBST(numSecu : 1 : 13) : 13 : 0) / 97 : 13 : 0) * 97)
= %DEC(%SUBST(numSecu : 14 : 2) : 2 : 0));
end-proc; Voici le code à inclure dans source de liage :
EXPORT SYMBOL(« CHECK_NUMERO_SECU »)
Voici le code a ajouter dans dans votre programme pour pouvoir utiliser votre contrôle :
dcl-PR Check_Numero_Secu ind ;
W_Num_Sec char(15);
end-pr ;
// dans votre code
if Check_Numero_Secu ind(‘16403323470623’) ;
dsply ‘error’ ;
endif;
Remarque :
Vous pouvez améliorer le code en mettant votre code sous monitor pour éviter les numéros de sécu incomplets
Verrouiller vos sources pour VSCODE
Une des difficultés, quand on développe avec VSCE sur IBMi ,
C’est que si on est 2 deux à modifier le même source, c’est le dernier qui a raison avec perte de modification du premier même s’il a sauvegardé
Voici comment on peut améliorer les choses.
On va créer un fichier base de données qui liste les sources qui sont en cours de maintenance, un peu comme un ALM.
Avec GIT on peut arriver à des mécanismes identiques, et surtout, il faut commencer à mettre vos sources dans l’IFS directement
Voila comment, vous pouvez faire pour améliorer les choses
CREATE TABLE DB_OPENLCK (FICHIER CHAR ( 10) NOT NULL WITH
DEFAULT, BIBLIO CHAR ( 10) NOT NULL WITH DEFAULT, MEMBRE CHAR ( 10)
NOT NULL WITH DEFAULT, PARTAGE CHAR ( 3) NOT NULL WITH DEFAULT,
PUSER CHAR ( 10) NOT NULL WITH DEFAULT, PDATE DATE NOT NULL WITH
DEFAULT, PTIME TIME NOT NULL WITH DEFAULT)
Pour ajouter un source à verrouiller
INSERT INTO DB_OPENLCK VALUES(‘QRPGLESRC’, ‘GDATA’, ‘AAAA’,
‘NON’, ‘PLB’, current date, current time)
Et parmi les programmes d’exit il en a un qui va nous permettre de mettre en œuvre ce contrôle
C’est le QIBM_QDB_OPEN
On va donc écrire un programme, ici en SQLRPGLE
**free
//
// ce programme permet d'éviter de travailler à 2 sur un même source
//
Dcl-Pi *N;
DS_parm likeds(ds_parm_t) ;
reponse int(10);
End-Pi;
// dsprogramme
dcl-ds *N PSDS ;
nom_du_pgm CHAR(10) POS(1);
init_user CHAR(10) POS(254);
enc_user CHAR(10) POS(358);
End-ds ;
// ds format DBOP0100
Dcl-DS ds_parm_t qualified template ;
taille_entete Int(10);
format Char(8);
offset_liste Int(10);
nbr_fichiers Int(10);
taille_liste Int(10);
job Char(10);
profil Char(10);
jobnbr Char(6);
cur_profil Char(10);
reste Char(1024);
End-DS;
// liste des fichiers dans notre cas un seul
Dcl-DS liste ;
fichier Char(10);
biblio Char(10);
membre Char(10);
filler Char(2);
typefichier Int(10);
sous_jacent Int(10);
access Char(4);
End-DS;
// variable de travail
Dcl-S partage char(4);
Dcl-S puser char(10);
ds_parm.offset_liste += 1;
dsply enc_user ;
liste = %subst(ds_parm : ds_parm.offset_liste :
ds_parm.taille_liste);
ds_parm.offset_liste += ds_parm.taille_liste;
// lecture des informations dans le fichier de verrouillage explicite
// le verrouillage est donc par utilisateur
exec sql
SELECT PARTAGE, PUSER into :partage , :puser
FROM DB_OPENLCK WHERE FICHIER = :FICHIER and BIBLIO
= :BIBLIO and MEMBRE = :MEMBRE ;
//
// La régle mise en oeuvre ici
// on autorise
// si même utilisateur
// si non trouvé en modification
// Si on on a dit partage à oui
//
if (sqlcode = 100 or partage = 'OUI' or puser = enc_user) ;
reponse = 1 ;
else ;
reponse = 0 ;
endif ;
// fin de programme
*inlr = *on; ici notre règle est la suivante
on autorise
Si le source n’est pas présent dans le fichier
Si l’utilisateur est le même que celui en cours
Si on a accepté le partage et donc le risque
Pour ajouter votre pgm exit
SYSTEM/ADDEXITPGM EXITPNT(QIBM_QDB_OPEN)
FORMAT(DBOP0100)
PGMNBR(1)
PGM(GDATA/OPENSRC)
REPLACE(*NO)
Quand on essaye d’accéder par VSCDE à notre source
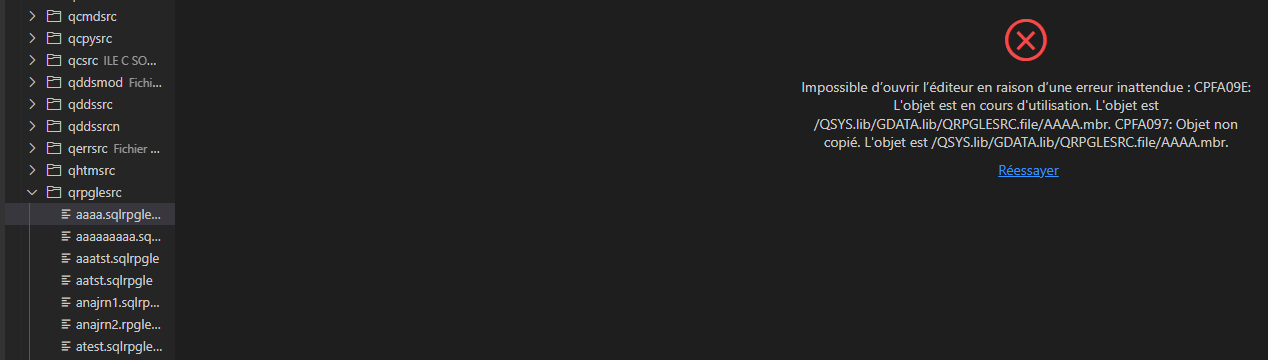
Remarque
Le contrôle marche aussi avec RDI
Il marche également pour SEU, parfois on préfère un contrôle spécifique SEU, vous devrez utiliser le programme d’exit
QIBM_QSU_ALW_EDIT en utilisant le même fichier par exemple !
**free
//
// Ce programme eviter de travailler à 2 sur un même source
//
Dcl-Pi *N;
biblio char(10);
fichier char(10);
membre char(10);
reponse char(1);
End-Pi;
// dsprogramme
dcl-ds *N PSDS ;
nom_du_pgm CHAR(10) POS(1);
init_user CHAR(10) POS(254);
enc_user CHAR(10) POS(358);
End-ds ;
Dcl-S partage char(4);
Dcl-S puser char(10);
// lecture des informations dans le fichier de verrouillage explicite
// le verrouillage est donc par utilisateur
exec sql
SELECT PARTAGE, PUSER into :partage , :puser
FROM DB_OPENLCK WHERE FICHIER = :FICHIER and BIBLIO
= :BIBLIO and MEMBRE = :MEMBRE ;
//
// La règle mise en œuvre ici
// on autorise
// si même utilisateur
// si non trouvé en modification
// Si on on adit partage à oui
//
if (sqlcode = 100 or partage = 'OUI' or puser = enc_user) ;
reponse = '1' ;
else ;
reponse = '0' ;
endif ;
// fin de programme
*inlr = *on; On ajoute comme ca
SYSTEM/ADDEXITPGM EXITPNT(QIBM_QSU_ALW_EDIT)
FORMAT(EXTP0100)
PGMNBR(1)
PGM(GDATA/OPENSRCE)
REPLACE(*NO)
Ca ne fait pas tout, que faire si on est 2 sur le même source ? peut être faut il avoir un source de référence pour éviter le versionnage
Remarque :
Pour diminuer le nombre d’appels du programme d’exit , vous pouvez limiter le déclenchement aux fichiers qui sont audités.
Vous devez indiquer le paramètre PGMDTA(*JOB *CALC ‘*OBJAUD’) sur les commandes ADDEXITPGM ou CHGEXITPGM.
Exemple :
ADDEXITPGM EXITPNT(QIBM_QDB_OPEN)
…
PGMDTA(*JOB *CALC ‘*OBJAUD’)
Vous devez ensuite indiquer les fichiers à auditer :
Exemple :
CHGOBJAUD OBJ(GDATA/QRPGLESRC)
OBJTYPE(FILE) OBJAUD(CHANGE)
A partir de ce moment la, seuls les fichiers audités déclencheront l’appel du programme d’exit QIBM_QDB_OPEN