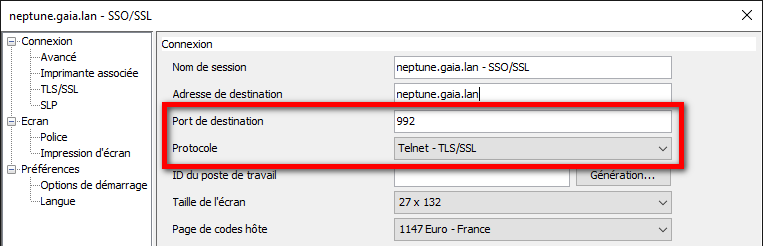
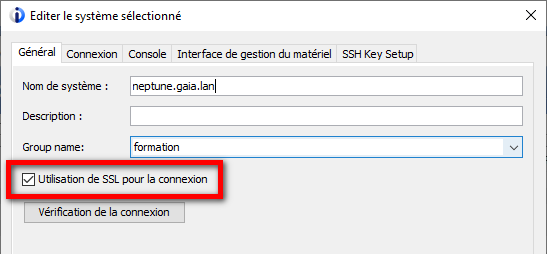
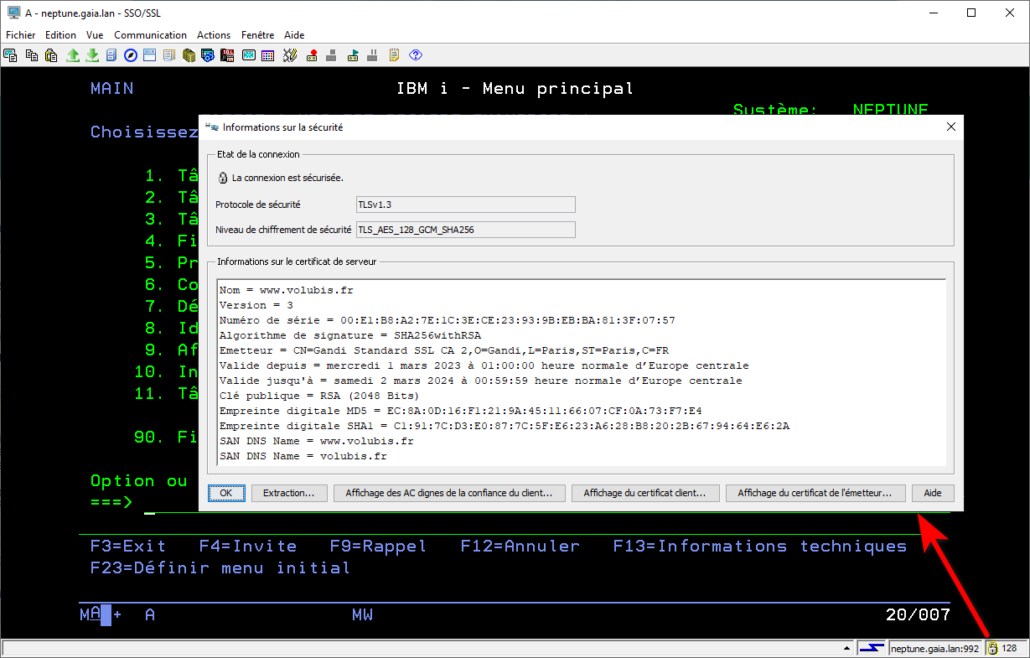
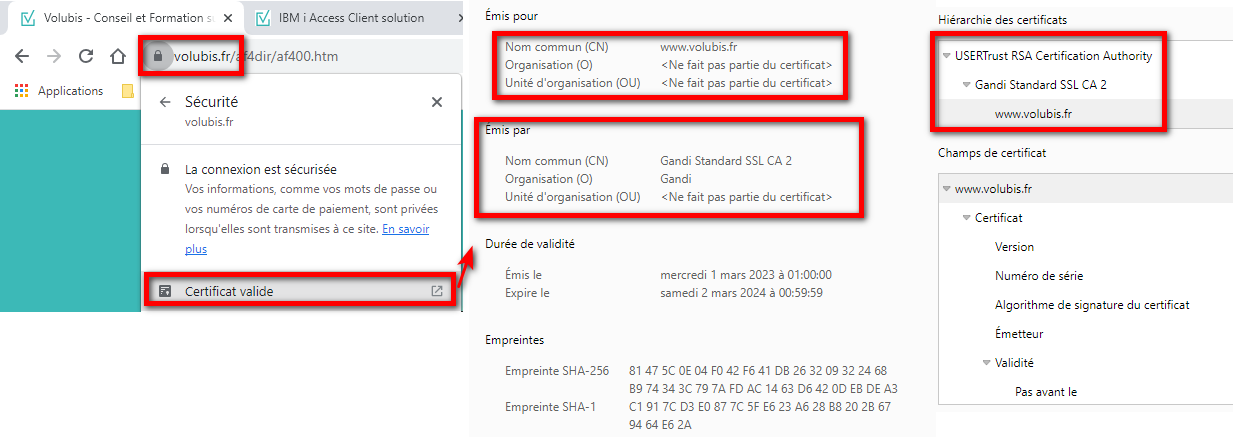
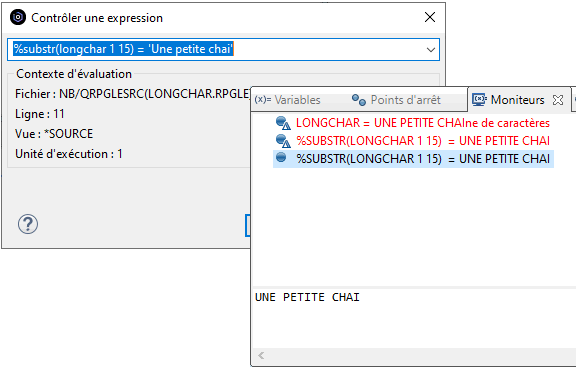
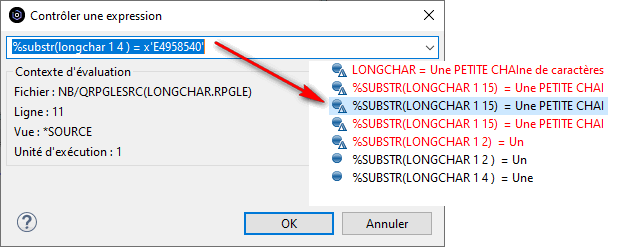
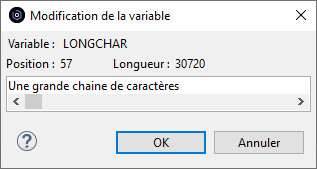
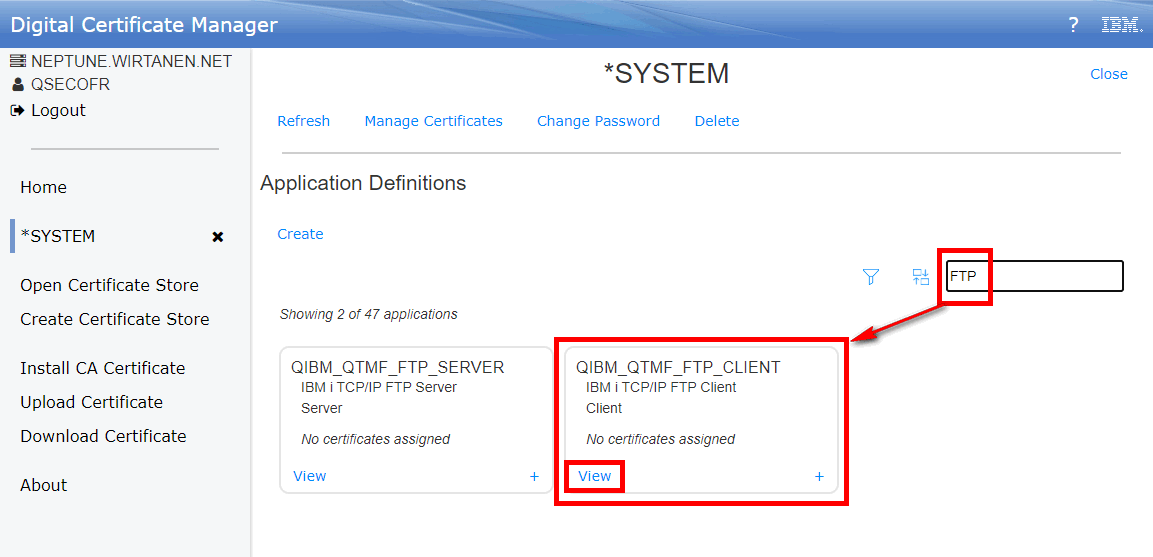
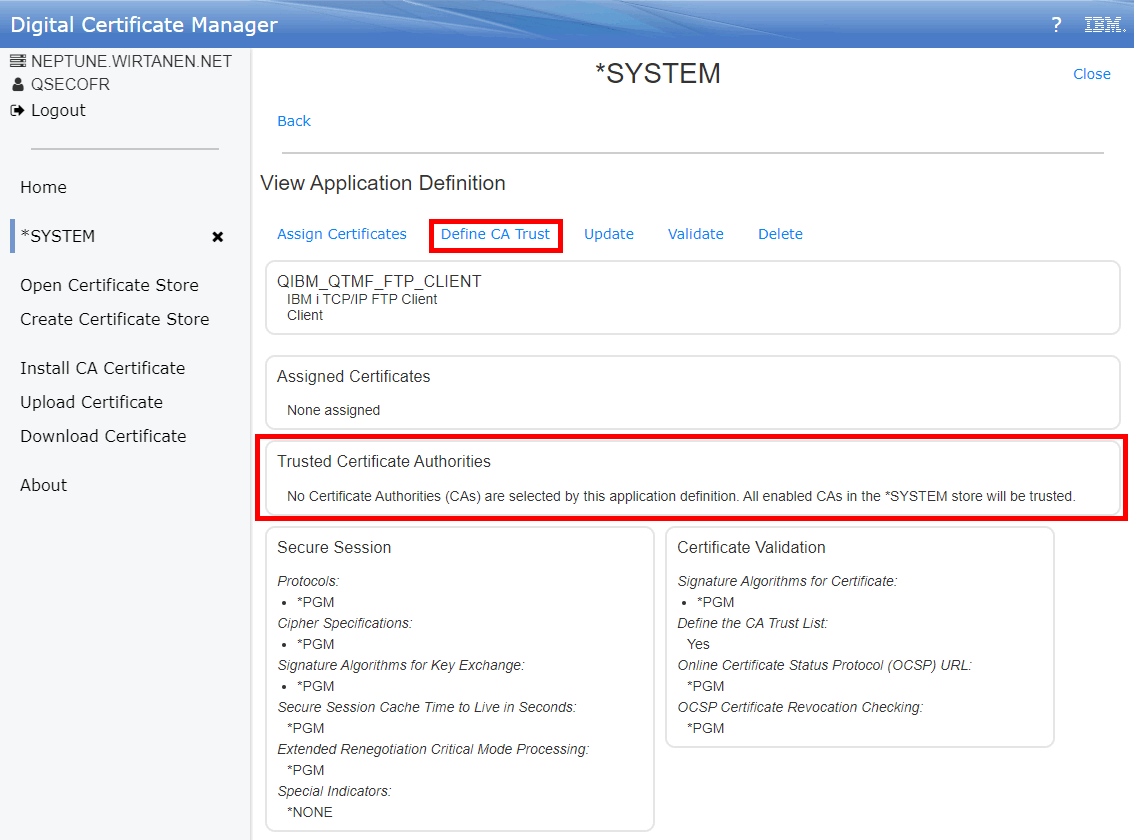
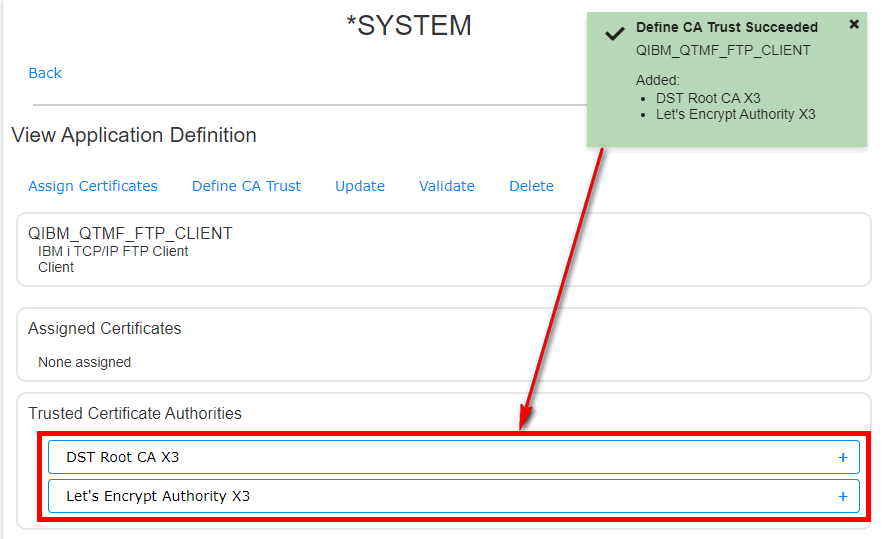
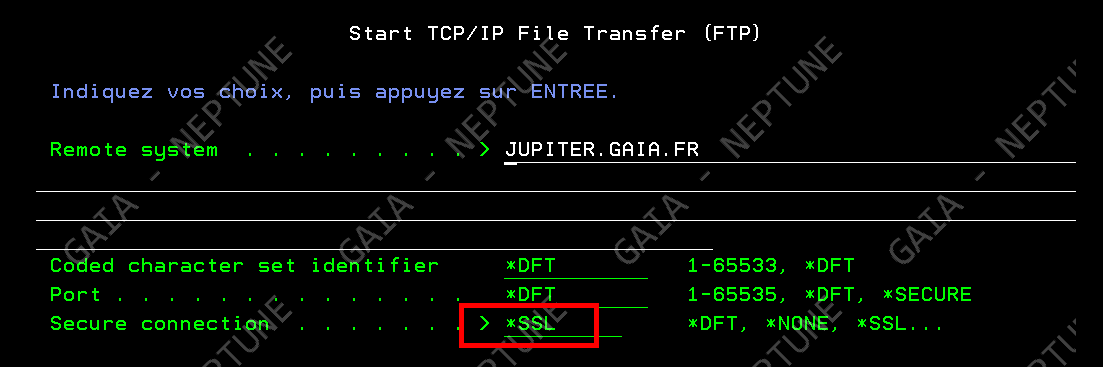
Dans la suite logique des annonces de la disponibilité de l’IBM i en mode abonnement pour les Power9 et Power10, IBM continue le déplacement des licences de l’offre perpétuelle à l’offre abonnement. Tout le détail ici https://www.ibm.com/docs/en/announcements/i-operating-system-now-offers-subscription-licensing-all-software-tiers-power9-power10-processors.
Bien entendu cela favorise la capacité à proposer des offres Cloud !
De ce point de vue c’est une opportunité importante dans la modernisation des infrastructures, et surtout la perspective d’avoir à terme un parc (plus) à jour.
D’autres raisons peuvent être sous-jacentes : la capacité à planifier et prédire un chiffre d’affaire par exemple. Du côté du client cela impacté également les budgets IT (amortissement vs consommation). Laissons cela de côté pour l’instant.
Comment
En synthèse, IBM travaille sur la proposition d’un abonnement IBM i + SWMA (maintenance logicielle). Le parti-pris est une équivalence de budget à 4 ans.
Cf https://www.itjungle.com/2023/09/18/the-subscription-pricing-for-the-ibm-i-stack-so-far/
Ainsi, si vous conservez vos machines 4 ans ou moins : pas de budget supplémentaire. Si vous conservez vos systèmes plus longtemps, le coût augmente. De même, il deviendra difficile de conserver des systèmes hors maintenance (mais quel intérêt ?).
D’un autre côté, IBM rend gratuit un grand nombre de produits sous licence : pour les clients les utilisant c’est également une source d’économie. Pour les autres, c’est l’opportunité de disposer de fonctions supplémentaires.
Logiciels sous licence désormais inclus avec la licence IBM i
- Administration Runtime Expert, also called Application Runtime Expert (5733-ARE)
- CICS Transaction Server (5770-DFH)
- HTTP Server (5770-DG1)
- Facsimile Support for i (5798-FAX)
- Developer Kit for Java (5770-JV1)
- Managed System Services (5770-MG1)
- Network Authentication Enablement (5770-NAE)
- System Manager (5770-SM1)
- TCP/IP Connectivity Utilities (5770-TC1)
- Transform Services (5770-TS1)
- Universal Manageability Enablement (5770-UME)
Logiciels sous licence gratuit (à commander à part)
- Web Enablement: includes selected versions of WebSphere Application Server (5733-WE3, 5722-WE2)
- Cryptographic Device Manager (5733-CY3)
- OmniFind Text Search Server for DB2 for I (5733-OMF)
Logiciels sous licence payants
- BRMS (5770-BR1)
- Rational Development Studio (5770-WDS)
- PowerHA SystemMirror for i (5770-HAS)
- Cloud Storage Solutions (5733-ICC)
- Db2 Mirror (5770-DBM)
- Rational Developer for i
- ARCAD Observer for IBM i (5733-AO1)
- ARCAD RPG Converter for IBM i (5733-AC1)
- IBM i Modernization Engine for Lifecycle Integration (“Merlin” via Passport Advantage)
- IBM i Optional Features: Db2 Data Mirroring – Opt 48
Retrouver les détails chez IBM : https://www.ibm.com/docs/en/announcements/continues-simplify-i-portfolio-licensed-software-withdrawal-selected-i-lpps-i-optional-features?region=EMEA
Cas de DB2 Web Query
Une nouvelle plus surprenant : fin de la commercialisation de DB2 Web Query depuis le 10 octobre 2023 ! Cf https://www.ibm.com/docs/en/announcements/db2-webquery-eom
Alors même qu’une nouvelle version est disponible depuis fin 2022 : https://www.ibm.com/docs/en/announcements/db2-web-query-i-24
DB2 Web Query a en réalité été initialement développé par Information Builders sous le nom WebFOCUS. En 2020, il a été racheté par TIBCO (https://www.tibco.com/press-releases/2021/tibco-completes-acquisition-information-builders). Il semble donc que la relation commerciale entre IBM et TIBCO ne permette plus cette participation.
Malheureusement, ce sont les utilisateurs de DB2 Web Query qui en pâtissent, IBM ne proposant pas de produit aux fonctionnalités équivalentes.
Ce sera également un manque aux possibilités de l’IBM i : DB2 Web Query est la solution de BI, d’exploitation des données métier. Or les plus fortes valeurs ajoutées de l’IBM i sont aujourd’hui sa base de donnée DB2 et la capacité à traiter des workload business.
Même si le nombre d’utilisateurs de DB2 Web Query était limitée, c’est assurément une mauvaise nouvelle.