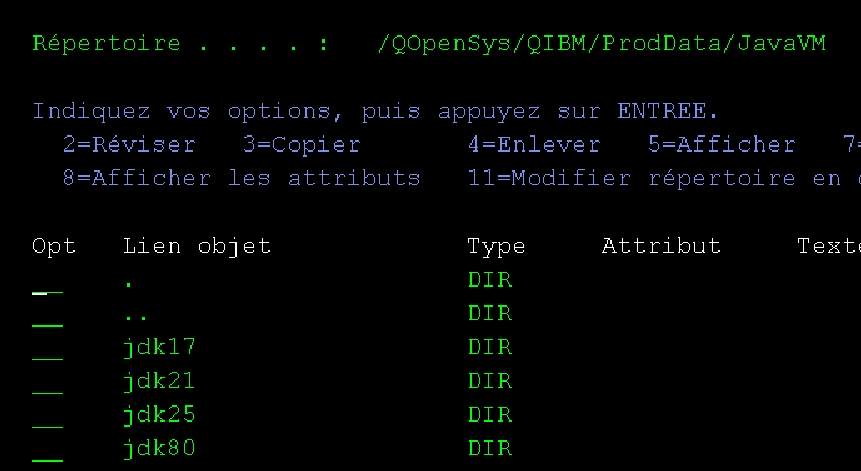
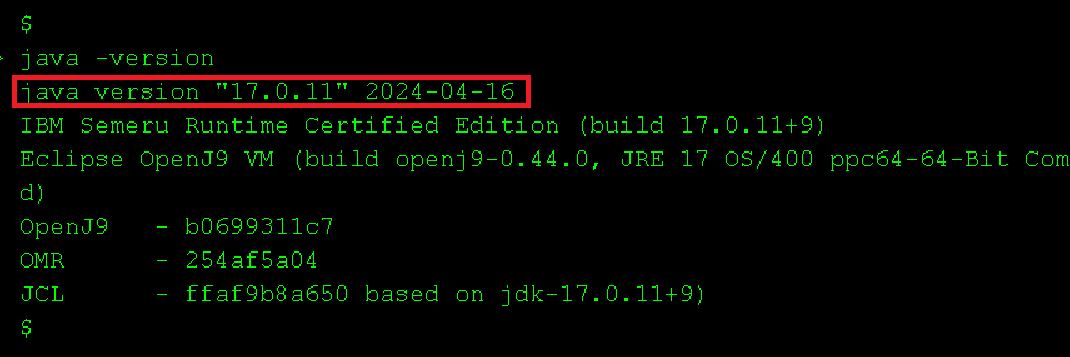
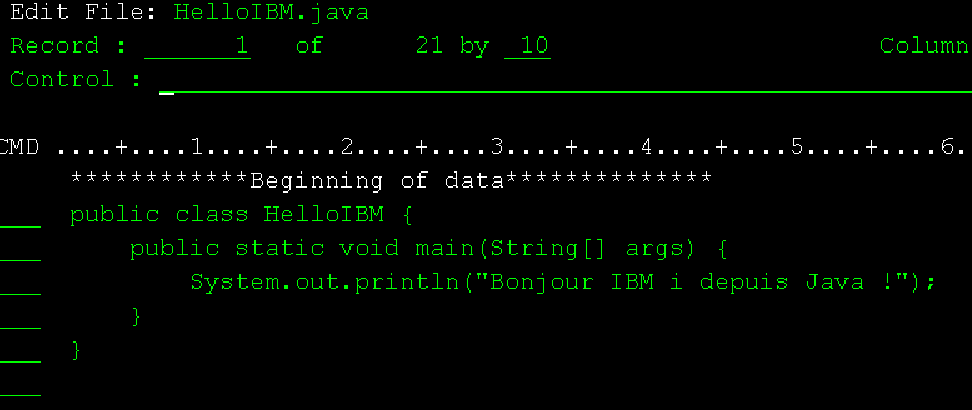
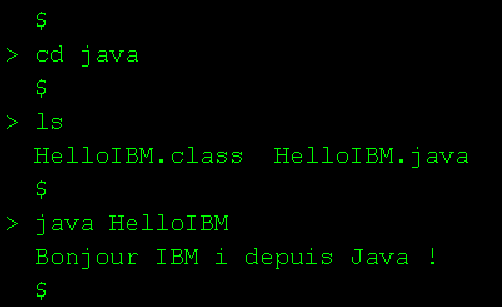
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2025-08-19 16:40:022025-08-19 16:40:03Débuter en java sur ibmi
Nous sommes de plus en plus nombreux à utiliser Code for IBM i !
Nous avons de nombreuses questions sur cet outil, en constante évolution.
Cette semaine, nous avons choisi de parler des profils, et de la confusion entre le profiles Visual Studio Code et les profils Code for IBM i.
Et les profils IBM i ?
Nous n’en parlerons pas ici !
Un profil IBM vous permet de vous connecter à la machine et n’existe que côté serveur.
La notion de profils dans Visual Studio Code (noté VSCode pour la suite) concerne la configuration des environnements de travail dans l’IDE.
Profil Code for IBM i
A la connexion à votre IBM i, VSCode établi une communication via un job SSH. Ensuite, l’interface propose plusieurs éléments de configuration et de navigation :
User Library List (partie utilisateur de la liste de bibliothèque) + current library (bibliothèque en cours)
Object browser (filtres sur objets / membres)
IFS shortcuts (filtres sur répertoires / fichiers)
Une fois connecté, la liste de bibliothèque affichée est celle utilisée à votre dernière connexion.
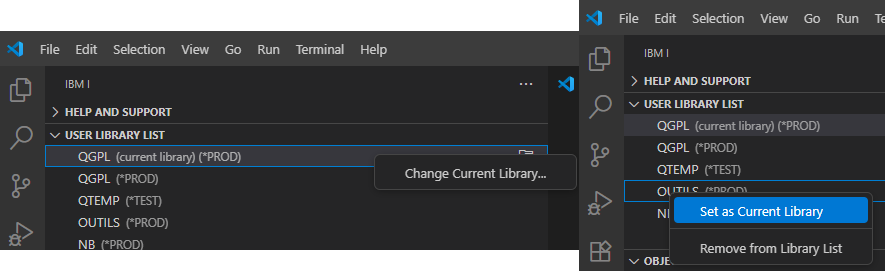
Vous pouvez modifier la bibliothèque en cours par click droit sur current library (ouvre un prompt) ou sur click droit sur une bibliothèque à définir comme en cours :
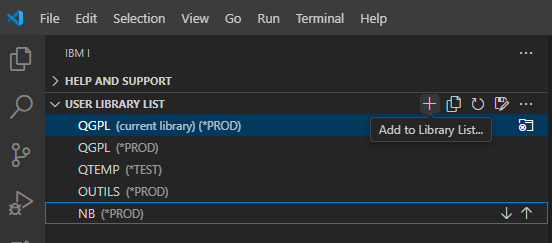
De même pour la liste de bibliothèque : ajout / suppression / réorganisation :
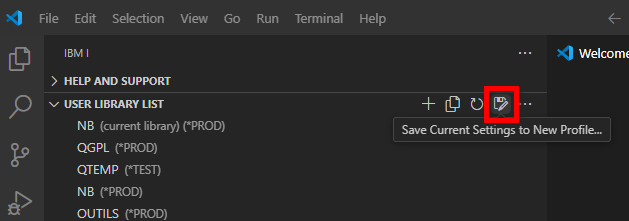
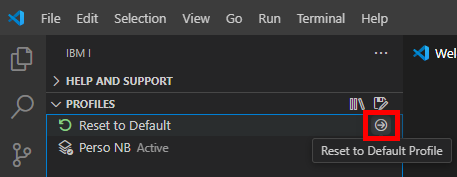
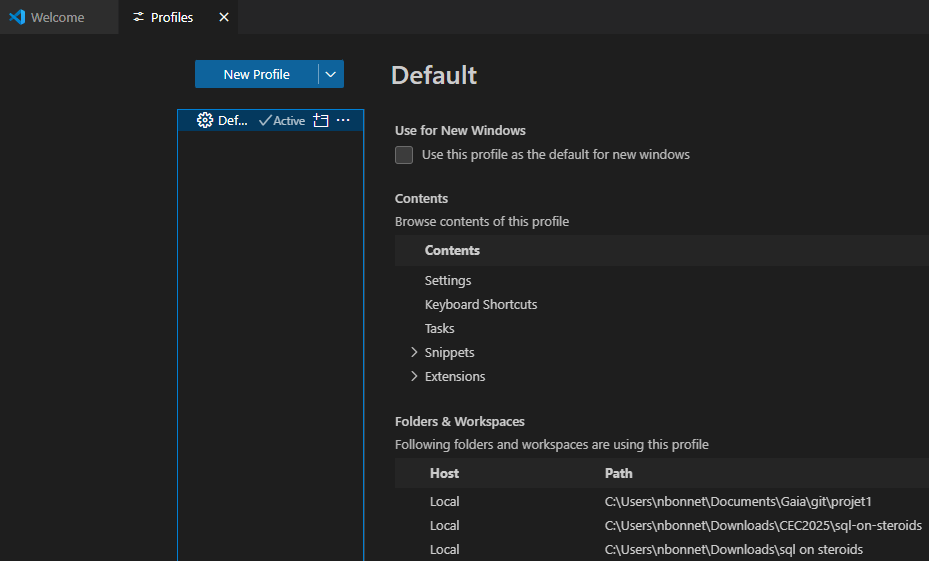
Une fois votre environnement configuré, la sauvegarde sous forme de profil vous permet de mémoriser cette configuration et de pouvoir revenir dessus plus rapidement par la suite :
Donner un nom à l’enregistrement :
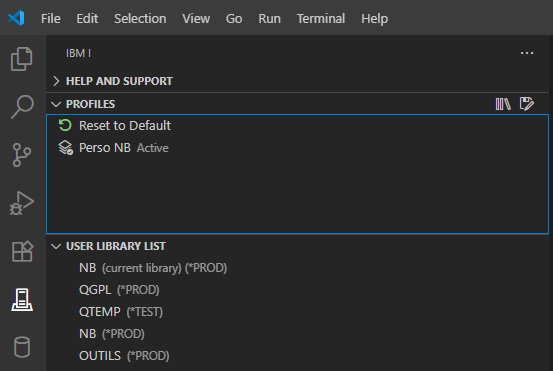
Une nouvelle option de gestion des profils est alors affichée :
Elle vous permet de revenir à la situation d’origine de votre profil (si vous avez ajouter/supprimer des bibliothèques par exemple) :
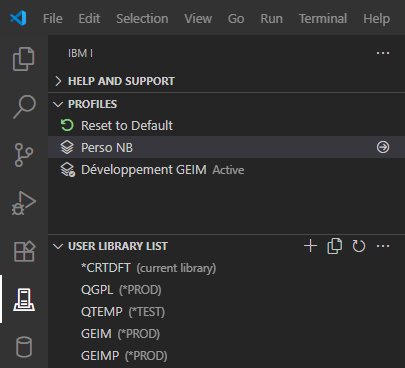
Mais surtout vous pouvez créer d’autres profils, correspondants à d’autres situations :
Développement projet 1
Développement projet n …
Tests projet 1
Production
…
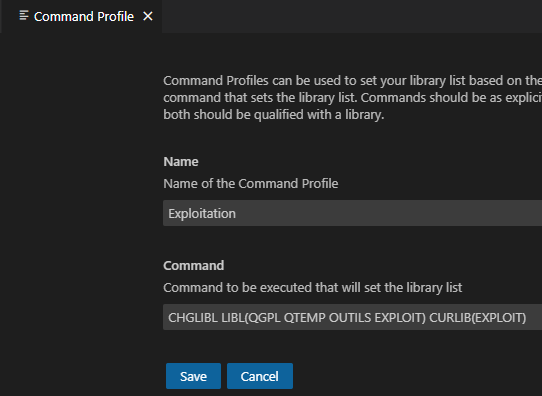
Vous pouvez aussi créer un profil directement en indiquant une commande de mise en place de l’environnement, basiquement un CHGLIBL :
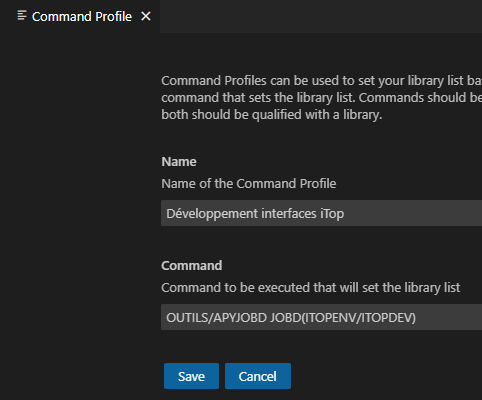
Pour plus de souplesse, surtout lors de travail en équipe, nous vous conseillons de créer une *JOBD par « projet » côté serveur, avec une commande qui met en place les bibliothèque de la *JOBD. Cela vous permet de modifier la *JOBD sans intervenir sur l’ensemble des clients :
En réalité, le profil permet de stocker l’ensemble des éléments suivants :
Le profil Visual Studio Code vous permet d’avoir plusieurs configurations de VSCode avec une installation unique : des attributs de l’environnement peuvent être modifiés via un fichier de configuration.
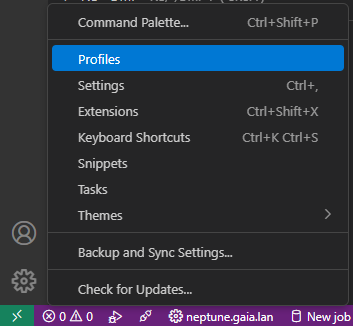
Depuis le menu des paramètres, aller dans les profils :
Nous pouvons alors gérer les profils, en créer/supprimer, modifier les attributs :
Il est par exemple possible de créer un profil :
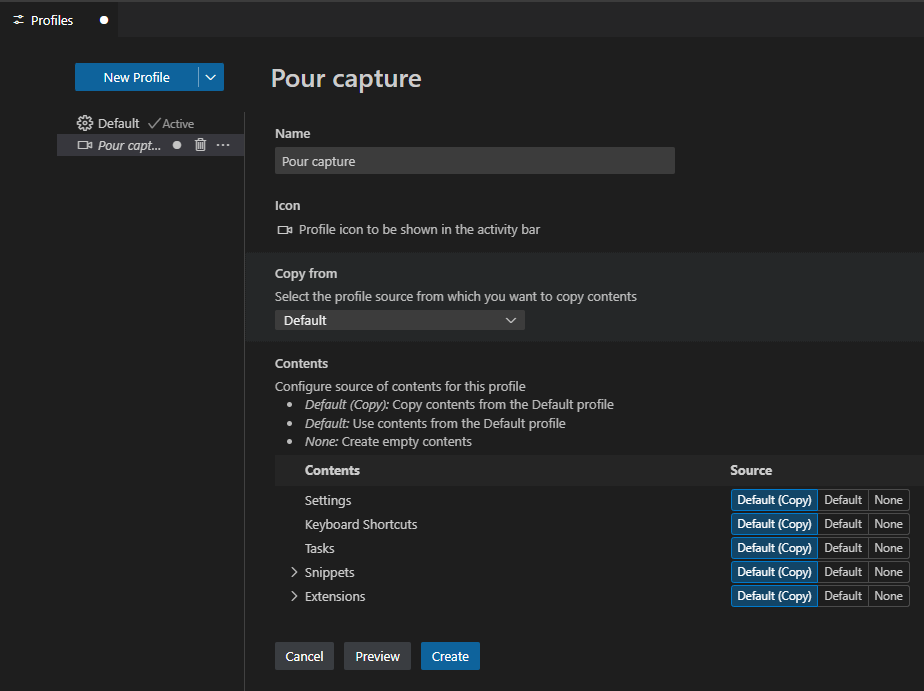
Par copie d’un profil existant, ou totalement vide. Et lors de la copie, vous choisissez les éléments de paramétrages, de personnalisation de clavier etc … Une icône spécifique peut être attribuée pour identifier rapidement les profils.
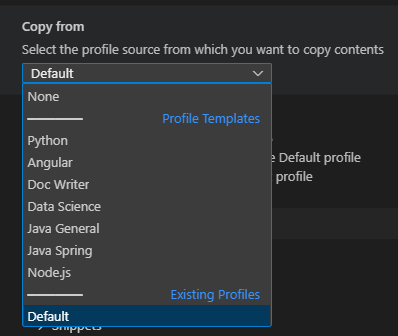
Certains profils types sont également fournis :
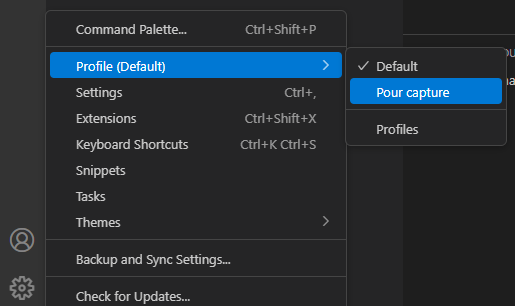
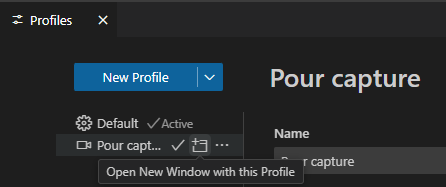
Une fois le profil créé, vous pouvez passer de l’un à l’autre :
Ou bien ouvrir une autre fenêtre avec un profil différent :
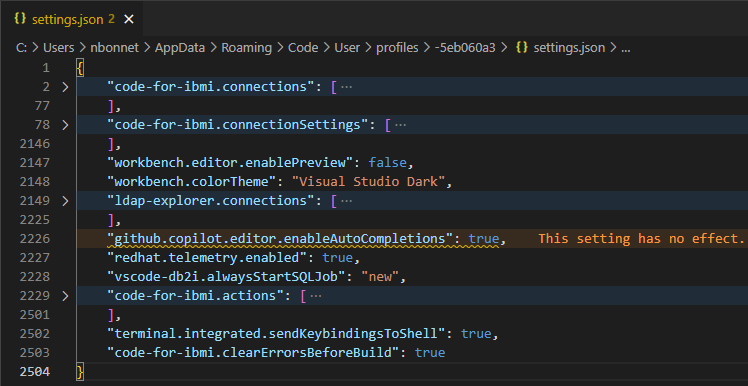
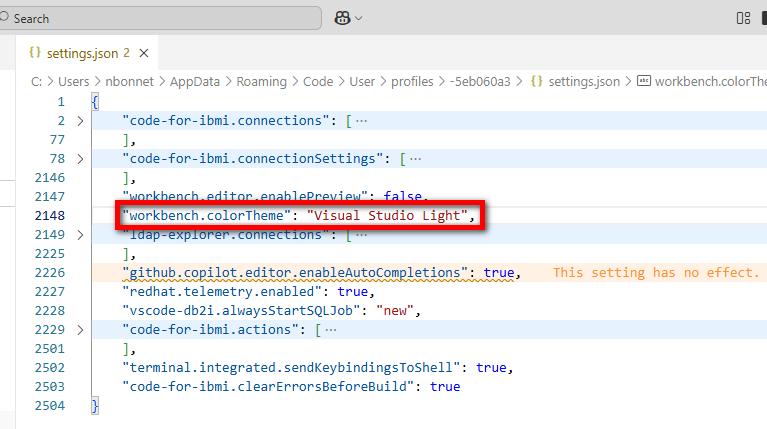
Depuis les propriétés du profil, les différentes catégories (Settings, keyboard shortcuts etc …) correspondent à des fichiers de configuration différents. Lorsque vous double-cliquer sur « Settings » :
Vous pouvez modifier les propriétés en direct, le changement est pris en compte à l’enregistrement du fichier :
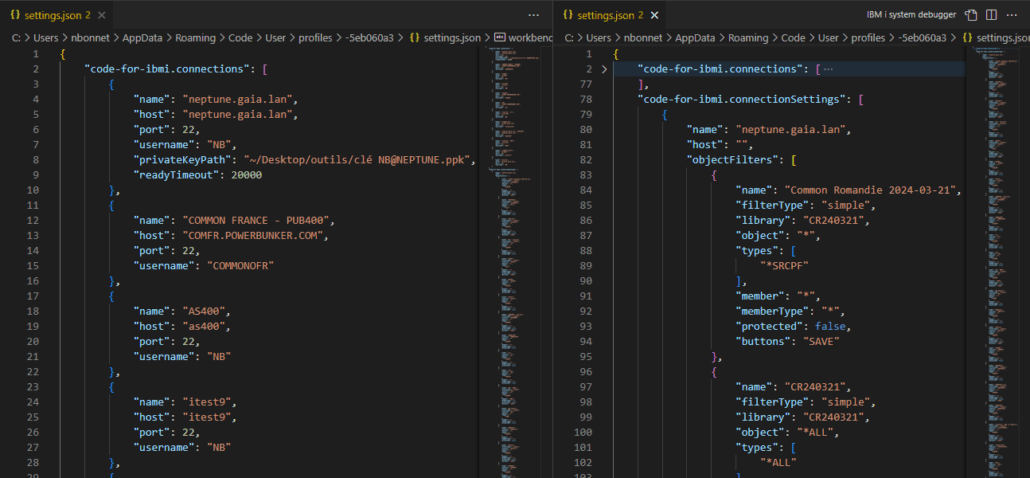
Vous remarquez que l’ensemble des informations des profils Code for IBM i sont stockés ici, dans les profils Visual Studio Code :
Vous pouvez donc facilement éditer, modifier, échanger (regarder les options d’import/export) toutes les configurations afférentes.
Avec un peu d’habitude, vous pouvez ouvrir différentes instances pour différents usage.
https://www.gaia.fr/wp-content/uploads/2017/02/team1.png600600Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2025-06-23 22:04:512025-06-23 22:04:52Visual Studio Code et Code for IBM i : profils
Nouveau venu dans les bibliothèques middleware pour IBMi, MAPEPIRE est un outil simple pour récupérer des données de votre serveur et les travailler sur de applications tierces, telles que des outils d’analyse de données, de la bureautique, etc.
Nous allons vous présenter la possibilité d’installer et d’utiliser le produit simplement
sur le serveur
sur votre client, en fonction du langage que vous souhaitez utiliser.
Les langages disponibles pour l’instant sont :
JAVA, NODE.JS, PYTHON
Ici, l’exemple détaillé sera effectué avec le langage PYTHON.
Nous n’intervenons pas dans cet article sur les différents paramétrages de l’outil. Nous y reviendrons dans un article suivant. (exit points, ports, etc.)
Serveur
Installation de MAPEPIRE sur le serveur
yum install mapepire
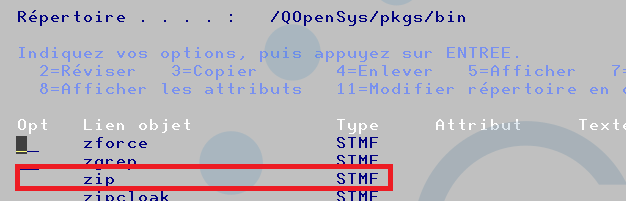
mapepire sera installé dans le répertoire
/qOpenSys/pkgs/bin
Démarrage
Note : dans cet article, on ne détaille ps le démarrage automatique
nohup /qopensys/pkgs/bin/mapepire &
Client
Notre exemple consiste à lister tous les travaux actifs en cours, les répertorier dans une trame PANDAS, puis de sauvegarder les données dans une feuille EXCEL
Pré requis
Python 3 installé et fonctionnel
un répertoire pour le code
Facultatif : un environnement virtuel
EXCEL
librairies installées :
pandas
openpyxl (factultatif)
installation MAPEPIRE
sous l’environnement virtuel (si configuré) ou sur l’environnement global
pip install mapepire-python
le code de notre exemple TEST.PY
#mapepire
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
#--------------------------------------------------
creds = DaemonServer(
host="serveuràcontacter",
port=8076,
user="utilisateur",
password='motdepasse',
ignoreUnauthorized=True,
)
job = SQLJob()
res = job.connect(creds)
#
# Travaux actifs
#
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
countjobs = result['data'][0]['TOTALTRAVAUX']
startT = datetime.now()
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
endT = datetime.now()
delta = endT - startT
print(f"travaux actifs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframActj = pd.DataFrame(result['data'])
#print(dframActj)
#
#récupération des utilisateurs dans une 2ème Frame (dframUsesrs)
#
startT = datetime.now()
result = job.query_and_run("""
WITH USERS AS (
SELECT
CASE GROUP_ID_NUMBER
WHEN 0 THEN 'USER'
ELSE 'GROUP'
END AS PROFILE_TYPE,
A.*,
CAST(TEXT_DESCRIPTION AS VARCHAR(50) CCSID 1147)
AS TEXT_DESCRIPTION_CASTED
FROM (
SELECT *
FROM QSYS2.USER_INFO
) AS A
)
SELECT *
FROM USERS
""",
rows_to_fetch=500)
endT = datetime.now()
delta = endT - startT
print(f"Utilisateurs récupérés en {str(delta)} secondes")
#insertion des résultats dans un Frame PANDAS
dframUsers = pd.DataFrame(result['data'])
#print(dframUsers)
print("Sauvegarde vers Excel")
with pd.ExcelWriter('/users/ericfroehlicher/Documents/donnes_dataframe.xlsx') as writer:
dframActj.to_excel(writer, sheet_name='ACTjobs')
dframUsers.to_excel(writer, sheet_name='Utilisateurs')
Un peu d’explications
1 – Import des resources dont on a besoin
#mapepire
from mapepire_python.client.sql_job import SQLJob
from mapepire_python import DaemonServer
#pandas
import pandas as pd
2 – Déclaration des données de connexion (serveur, utilisateur, mot def passe)
CONSEIL: pour l’instant, toujours laisser le port 8076
Ici, on crée un travail simple, synchrone (SQLJob)
4 – les requêtes synchrones
#comptage des travaux (pour l'exemple de l'utilisation du json)
result = job.query_and_run("\
SELECT \
count(*) as totaltravaux\
FROM TABLE (QSYS2.ACTIVE_JOB_INFO()) \
")
# je récupère directement la valeur lue
countjobs = result['data'][0]['TOTALTRAVAUX']
result = job.query_and_run("SELECT \
JOB_NAME, JOB_TYPE, JOB_STATUS, \
SUBSYSTEM, MEMORY_POOL, THREAD_COUNT \
FROM TABLE ( \
QSYS2.ACTIVE_JOB_INFO(\
RESET_STATISTICS => 'NO',\
SUBSYSTEM_LIST_FILTER => '',\
JOB_NAME_FILTER => '*ALL',\
CURRENT_USER_LIST_FILTER => '',\
DETAILED_INFO => 'NONE'\
)\
) \
ORDER BY \
SUBSYSTEM, RUN_PRIORITY, JOB_NAME_SHORT, JOB_NUMBER\
",
rows_to_fetch=countjobs)
A
Les données obtenues sont au format JSON. (voir plus bas les données brutes)
5 – Insertion des données dans un frame PANDAS et sauvegarde vers EXCEL
#insertion des résultats dans un Frame PANDAS
dframe = pd.DataFrame(result['data'])
print(dframe)
print("Sauvegarde vers Excel")
dframe.to_excel(
"/users/ericfroehlicher/Documents/travaux_actifs.xlsx",
sheet_name="Travaux actifs",
index=False
)
Retour de mapepire
Le flux de données renvoyé par MAPEPIRE contient l’ensemble des données et méta données au format JSON.
Voici un extrait du flux retourné (exemple sur 5 travaux)
/wp-content/uploads/2017/05/logogaia.png00Eric Froehlicher/wp-content/uploads/2017/05/logogaia.pngEric Froehlicher2025-03-14 16:52:362025-03-14 16:52:37Générer des données avec MAPEPIRE en PYTHON
Vous connaissez tous la notion de liste de bibliothèques qui existe sur l’ibmi
la même notion existe sous unix c’est le path, et qui impacte vos commandes exécutées par exemple à partir de QSH
Vous pouvez le changer temporairement, voici la commande par exemple qui prend votre PATH et lui ajoute l’accès au commande open source de votre machine
Vous pouvez le changer de maniére dénitive pour une utilisateur
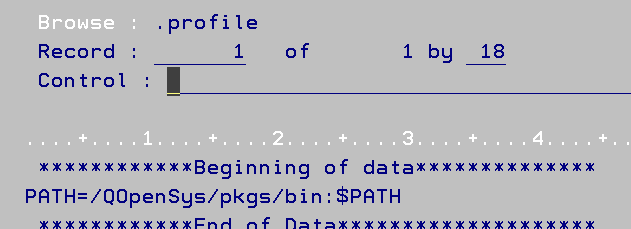
En créant un fichier .profile à la racine de votre path
Ca devrait donner ca /home/<votreuser>/.profile
Vous lui ajouter ces commandes
# Mise en ligne commande Open source PATH=/QOpenSys/pkgs/bin:$PATH export PATH PASE_PATH
Vous pouvez le changer globalement pour votre partition
Vous devez créer le fichier /etc/profile et lui ajouter ces lignes
# Mise en ligne commande Open source en plus des commandes standards export PATH=/usr/bin:.:/QOpenSys/usr/bin
Remarque :
Vous pouvez également travailler en hardcodant , ce n’est pas conseillé pour des raisons de maintenance exemple une copie de clé publique /QOpenSys/pkgs/bin/ssh-copy-id ….
Vous pouvez également utiliser la variable d’environnement PATH
Bien sur si vous décidez d’utiliser le fichier etc/profile ou la variable d’environnement PATH avec portée *SYS, pensez à l’impact global sur votre système
zip archive.zip analyse.csv adding: analyse.csv (deflated 84%) $
et par défaut si vous zippez sur une archive existante il ajoute
zip archive.zip xmlversion.txt adding: xmlversion.txt (stored 0%) $
pour voir le résultat
unzip -l archive.zip Archive: archive.zip Length Date Time Name ——— ———- —– —- 9934 2019-03-29 23:44 analyse.csv 17 2019-02-13 10:49 xmlversion.txt ——— ——- 9951 2 files $
Pour vous aider nous proposons une commande ADDTOARCF que vous pouvez retrouver ici https://github.com/Plberthoin/PLB/tree/master/GTOOLS/ un CLLE + un CMD
Remarque :
Vous pouvez ajouter une un fichier à un zip généré par CPYTOARCF Par défaut il créera la l’archive Vous pouvez indiquer des options si elles sont valides dans la commande Zip Vous avez un fichier stdout.log dans votre répertoire courant
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-10-25 11:05:562024-10-25 11:07:21Ajouter des fichiers à une archive ZIP
Open sourceMise en place d’une documentation Sphinx sur IBM i
Introduction
Introduction
Cet article à pour but de présenter la possibilité d’exploiter diverses solutions libres et gratuites très répandues dans le monde OpenSource. L’objectif est de découvrir Sphinx, un outil de génération de documentation sous forme de site web. Il est notamment utilisé pour réaliser les documentations suivantes :
La référence de l’OpenSource sur IBM i, IBM i OSS Docs – ici
Nous allons donc voir en quelques étapes simples comment publier et maintenir votre documentation directement sur votre IBM i.
Prérequis
PASE (IBM Portable Application Solutions Environment for i)
Environnement OpenSource sur l’IBM i
Python sur votre IBM i (Pour rappel, les modules OpenSource comme python sont compilés et mis à disposition par IBM spécialement pour l’IBM i, il n’y a pas plus de risque à les utiliser qu’à utiliser des logiciels sous licence)
Etape 1 – Mise en place de l’environnement
Cette section est réalisée via qsh, qp2term ou ssh.
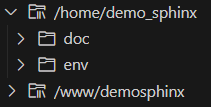
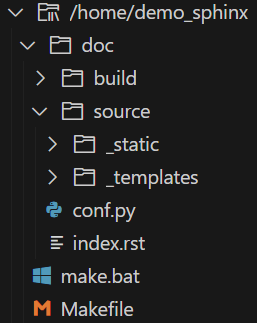
Le projet sera structuré comme suit :
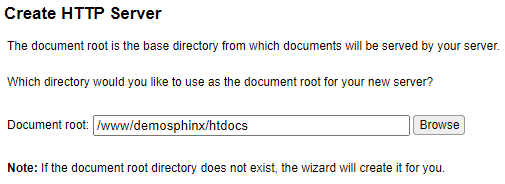
/home/demosphinx sera le répertoire du projet, il contiendra les sources (doc/) et l’environnement de travail python (env/). /www/demosphinx sera le répertoire du serveur Apache permettant de publier localement la documentation
Une fois l’arborescence créée, on installe ou met à jour Python 3.9 :
$ yum install python39
On crée ensuite un environnement virtuel pour python afin d’éviter d’être impacté par des changements de versions et pour isoler notre environnement de travail :
// Création de l'environnement virtuel Python
$ python3.9 -m venv --system-site-packages /home/demosphinx/env
// Entrer dans l'environnement virtuel
$ source /home/demosphinx/env/bin/activate
// Mise à jour du gestionnaire de paquets python (pip)
(env) $ pip install --upgrade pip
// Installation et mise à jour de Sphinx
(env) $ pip install --upgrade sphinx
// Installation du thème ReadTheDocs (Facultatif)
(env) $ pip install sphinx-rtd-theme
D’autres modules peuvent être intéressant, comme myst-parser (qui permet notamment d’utiliser du MarkDown pour rédiger sa documentation) et sphinx-jinja (qui permet l’usage de variables dans les pages). Il existe également une grande quantité de thèmes natifs présentés ici et des thèmes tiers présentés ici.
Etape 2 – Création du projet
Cette section est réalisée via qsh, qp2term ou ssh.
L’environnement en place on peut très simplement créer notre documentation.
// Entrer dans l'environnement virtuel
$ source /home/demosphinx/env/bin/activate
// Positionnement dans le répertoire du projet
$ cd /home/demosphinx/doc
// Génération du projet
$ sphinx-quickstart
On arrive ensuite sur un assistant qui va nous guider pour saisir les informations de base nécessaires à la documentation (qui seront toujours modifiables dans les sources de la documentation) : Le nom du projet, ceux des auteurs, la version, la langue de la documentation, etc… Voici un exemple :
Bienvenue dans le kit de démarrage rapide de Sphinx 7.3.7.
Veuillez saisir des valeurs pour les paramètres suivants (tapez Entrée pour accepter la valeur par défaut, lorsque celle-ci est indiquée entre crochets).
Chemin racine sélectionné : .
Vous avez deux options pour l'emplacement du répertoire de construction de la sortie de Sphinx.
Soit vous utilisez un répertoire "_build" dans le chemin racine, soit vous séparez les répertoires "source" et "build" dans le chemin racine.
> Séparer les répertoires source et de sortie (y/n) [n]: y
Le nom du projet apparaîtra à plusieurs endroits dans la documentation construite.
> Nom du projet: SphinxOnIBMi
> Nom(s) de(s) l'auteur(s): Gaia Mini Systèmes
> Version du projet []: v0
Si les documents doivent être rédigés dans une langue autre que l'anglais, vous pouvez sélectionner une langue ici grâce à son id entifiant. Sphinx utilisera ensuite cette langue pour traduire les textes que lui-même génère.
Pour une liste des identifiants supportés, voir
https://www.sphinx-doc.org/en/master/usage/configuration.html#confval-language.
> Langue du projet [en]: fr
Fichier en cours de création /home/demosphinx/doc/source/conf.py.
Fichier en cours de création /home/demosphinx/doc/source/index.rst.
Fichier en cours de création /home/demosphinx/doc/Makefile.
Fichier en cours de création /home/demosphinx/doc/make.bat.
Terminé : la structure initiale a été créée.
Vous devez maintenant compléter votre fichier principal /home/demosphinx/source/index.rst et créer d'autres fichiers sources de documentation. Utilisez le Makefile pour construire la documentation comme ceci :
make builder
où « builder » est l'un des constructeurs disponibles, tel que html, latex, ou linkcheck.
Le projet de documentation est maintenant généré !
Les différentes pages sont à ajouter dans le répertoire source/ :
index.rst (ou index.md si le module MarkDown est installé) – Il s’agit du point d’entrée de la documentation.
conf.py contient les informations de création de la documentation comme le thème, la langue, les différents format interprétés, etc…
Voici un exemple de fichier de configuration :
# Configuration file for the Sphinx documentation builder.
#
# For the full list of built-in configuration values, see the documentation:
# https://www.sphinx-doc.org/en/master/usage/configuration.html
# -- Project information -----------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
project = 'SphinxOnIBMi'
copyright = '2024, Gaia'
author = 'Gaia'
# -- General configuration ---------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
extensions = []
templates_path = ['_templates']
exclude_patterns = []
language = 'fr'
# -- Options for HTML output -------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
html_theme = 'alabaster'
html_static_path = ['_static']
Les différents fichiers sources peuvent être édités directement sur l’IBM i via VSCode, RDi…
Etape 3 – Création de la page Apache via HTTPAdmin
Cette section est réalisée via HTTPAdmin.
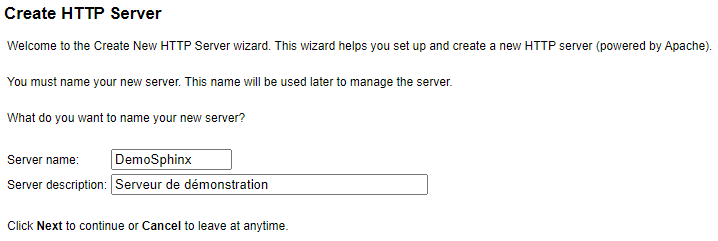
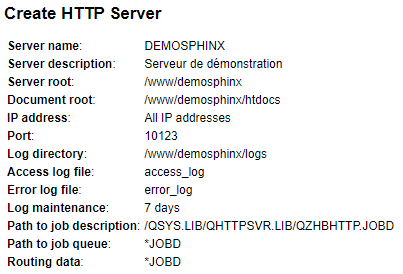
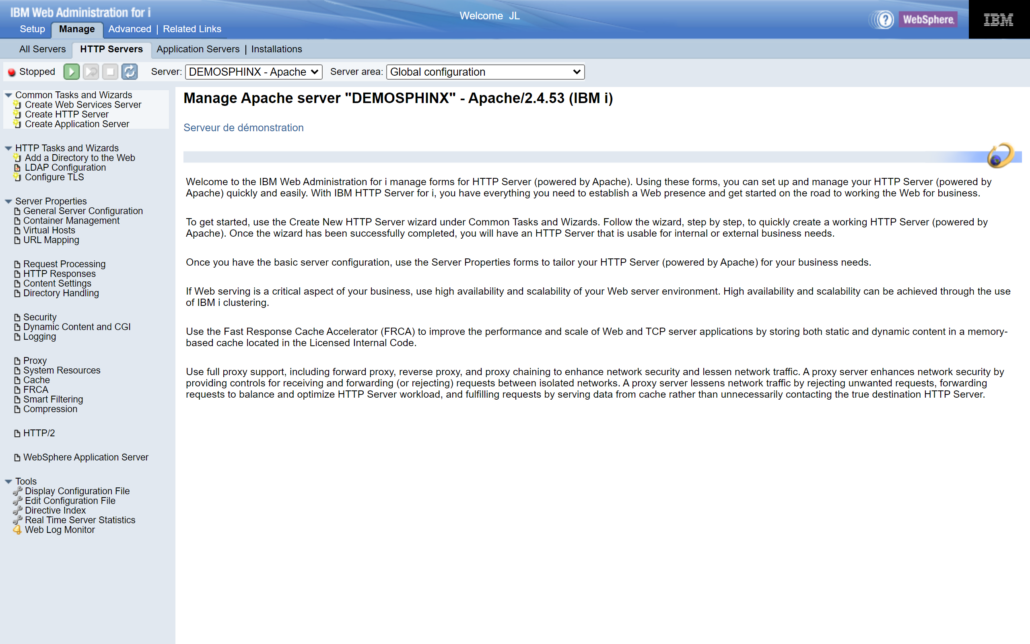
Avant de générer la documentation en tant que telle, créons un petit serveur Apache basique (on pourrait tout à fait utiliser une instance nginx). Pour se faire nous allons passer par HTTPAdmin afin d’exploiter l’assistant de configuration pour créer le serveur :
L’instance Apache est maintenant créée :
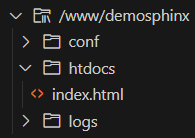
Pour éviter les problèmes de CCSID, il est préférable de supprimer au préalable le fichier index.html qui sera regénéré par Sphinx.
Etape 4 – Génération de la documentation
Cette section est réalisée via qsh, qp2term ou ssh.
Revenons sur notre environnement PASE pour générer la documentation, pour cela, une simple commande suffit :
// Entrer dans l'environnement virtuel
$ source /home/demosphinx/env/bin/activate
// Génération de la documentation vers le répertoire de l'instance Apache
$ sphinx-build -b html /home/demosphinx/doc/source /www/demosphinx/htdocs -E
Sphinx v7.4.7 en cours d'exécution chargement des traductions [fr]... fait
construction en cours [mo] : cibles périmées pour les fichiers po 0
Écriture...
construction [html] : cibles périmées pour les fichiers sources 1
mise à jour de l'environnement : [nouvelle configuration] 1 ajouté(s), 0 modifié(s), 0 supprimé(s)
lecture des sources... [100%] index
Recherche des fichiers périmés... aucun résultat trouvé
Environnement de sérialisation... fait
vérification de la cohérence... fait
documents en préparation... fait
copie des ressources...
Copie des fichiers statiques... fait
copie des fichiers complémentaires... fait
copie des ressources: fait
Écriture... [100%] index
génération des index... genindex fait
Écriture des pages additionnelles... search fait
Export de l'index de recherche en French (code: fr)... fait
Export de l'inventaire des objets... fait
La compilation a réussi.
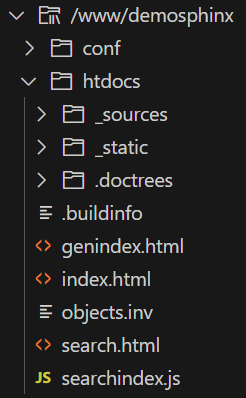
Les pages HTML sont dans /www/demosphinx/htdocs.
Voici les fichiers produits par la génération, directement dans notre instance Apache :
On voit entre autre le script Java Script, searchindex.js, un moteur de recherche intégré directement dans la documentation, l’un des gros points forts de Sphinx.
Démarrage de l’instance et résultat
On peut démarrer notre instance via HTTPAdmin :
Ou via 5250 et la commande :
STRTCPSVR SERVER(*HTTP) HTTPSVR(DEMOSPHINX)
Voici le résultat avant d’avoir rédigé la documentation :
Il ne reste plus qu’à remplir la documentation et à jouer avec les différentes possibilités de Sphinx et de ses modules.
https://www.gaia.fr/wp-content/uploads/2022/09/logo128.png128128Julien/wp-content/uploads/2017/05/logogaia.pngJulien2024-07-30 02:15:122024-07-30 12:20:47Mise en place d’une documentation Sphinx sur IBM i
Les changements de politique d’Oracle pour Java (JRE* ou JDK*) peuvent impacter l’utilisation d’ACS* (problèmes potentiels au lancement et à l’exécution d’ACS).
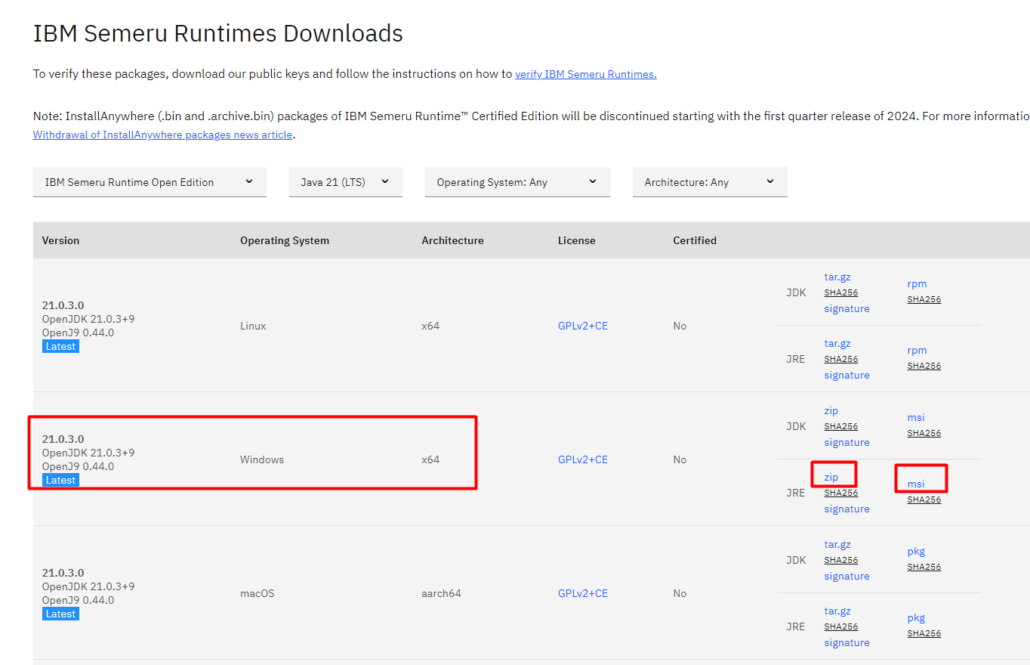
Pour éviter ces problèmes, l’environnement d’exécution privilégié recommandé par IBM est IBM Semeru Runtimes. C’est une solution gratuite basée sur OpenJDK avec la JVM Open Source IBM OpenJ9.
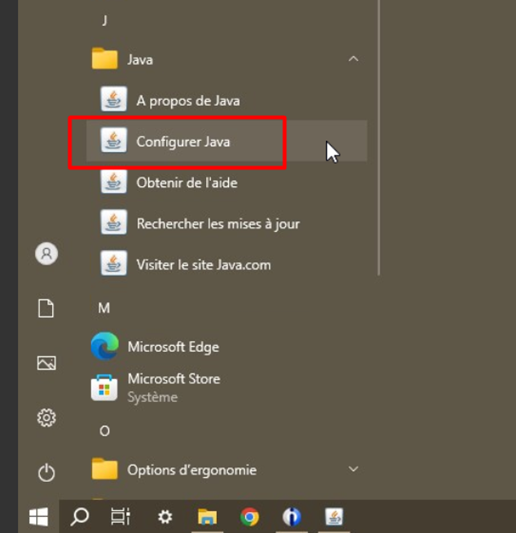
Si la version d’Oracle a été installée précédemment, après l’installation allez dans Démarrer > Programmes > Java > Configurer Java
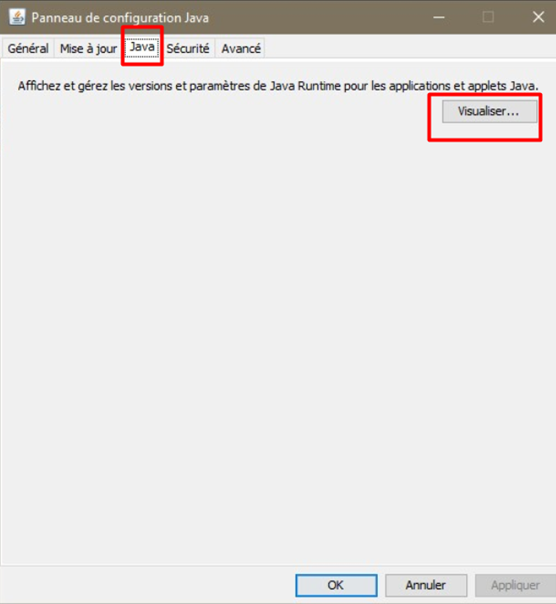
Dans le panneau de configuration Java, allez sur l’onglet Java pour visualiser et gérer les différentes versions installées du JRE :
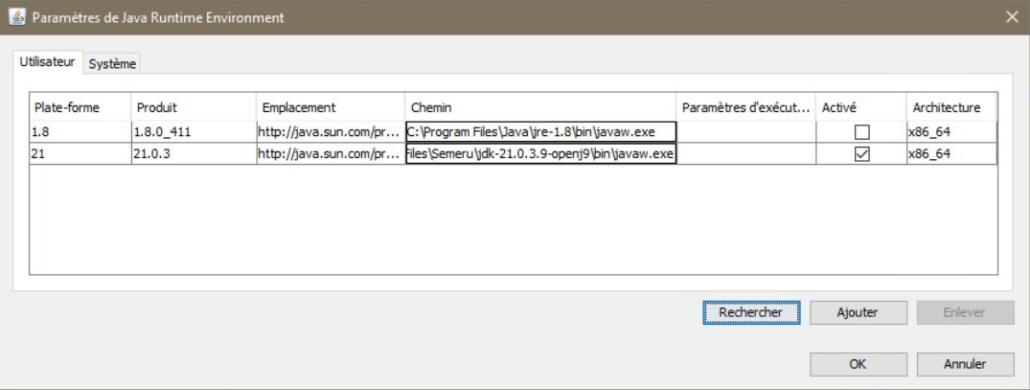
Si Java est déjà installé sur le poste, vous pouvez désactiver la version d’Oracle et activer la version OpenJ9 :
Il suffit de rechercher la nouvelle version pour l’ajouter, puis l’activer
–
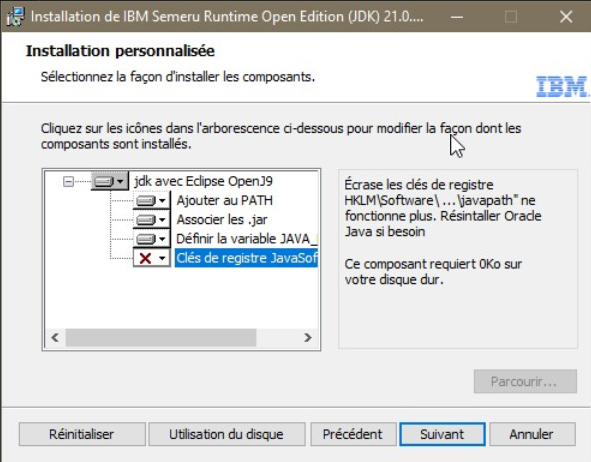
Installation d’OpenJ9 en tant que JRE pour ACS seulement
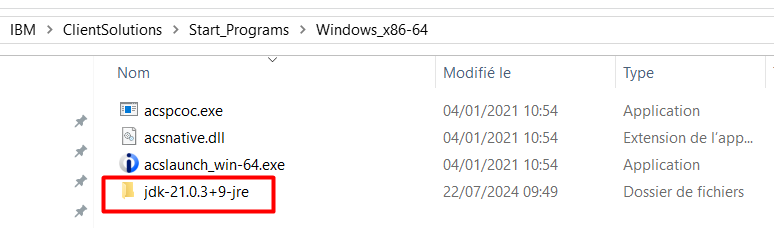
Vous pouvez installer le JRE directement dans le répertoire \IBM\ClientSolutions\Start_Programs\Windows_x86-64.
Dans ce cas, le JRE OpenJ9 ne sera utilisé que par ACS, les autres logiciels continueront à utiliser le JRE installé sous Windows.
–
Il faudra bien lancer ACS par l’exécutable acslaunch_win-64.exe du répertoire IBM\ClientSolutions\Start_Programs\Windows_x86-64, et pas le .jar
–
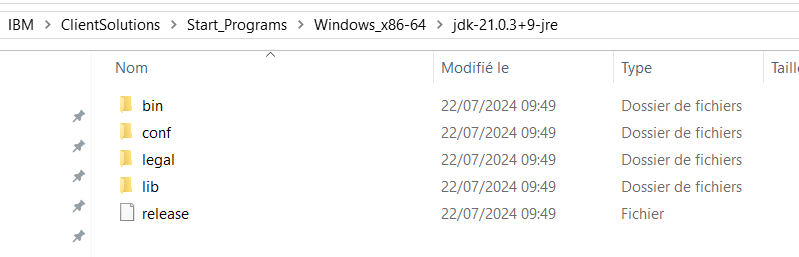
Décompressez le JRE zippé que vous avez téléchargé :
–
Copiez le dossier contenu dans l’archive dans le répertoire \IBM\ClientSolutions\Start_Programs\Windows_x86-64
–
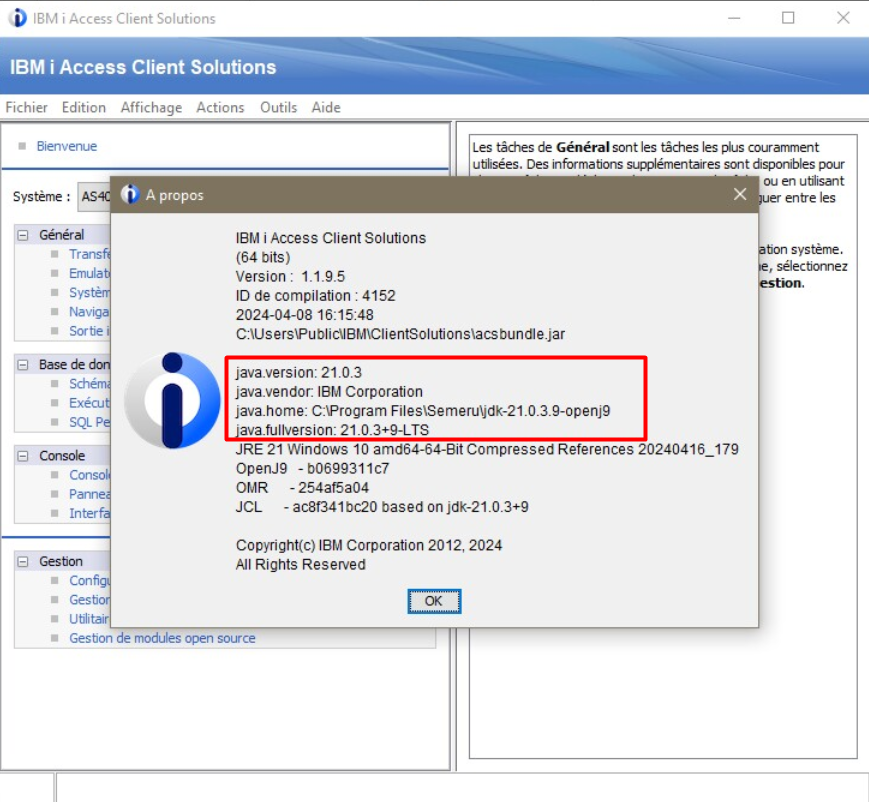
Vérification de la version du JRE utilisée par ACS
Ouvrir ACS et aller dans Aide > A propos
–
Attention
Avant de déployer le JRE d’OpenJ9 sur vos PC, il est impératif de vérifier si ACS et vos configurations de sessions 5250 fonctionnent correctement, car il peut y avoir quelques effets de bord sur certaines configurations lors du passage à OpenJ9.
Il existe une commande DSPSAVF qui permet de visualiser le contenu d’un Save File (SAVF), elle est très utile et nous nous sommes demandés si nous pouvions améliorer son ergonomie. Depuis l’intégration des Technical Release 7.5 TR2 et 7.4 TR8, de nouvelles vues et tables de fonctions permettent d’obtenir des informations à propos des SAVF […]
Contrôler le nombre de paramètres passés à un programme CL – %PARMS() / CEETSTA
Il arrive parfois d’avoir moins de paramètres passés à un programme CL que le nombre attendu, par exemple si on ajoute un paramètre à ce dernier mais que pour diverses raisons on ne souhaite pas modifier et recompiler tous les programmes qui y font appel.
Il existe deux solutions relativement simples à implémenter pour contrôler le nombre de paramètres transmis afin d’adapter en conséquence le comportement du programme : La fonction intégrée %PARMS et l’API CEETSTA.
%PARMS() – V7R4 et ultérieures
À partir de la V7R4, rien de plus simple, il suffit d’utiliser la fonction intégrée %PARMS(), qui retourne le nombre de paramètres :
PGM PARM(&PARAM1 &PARAM2)
/* Paramètres */
DCL VAR(&PARAM1) TYPE(*CHAR) LEN(10)
DCL VAR(&PARAM2) TYPE(*CHAR) LEN(10)
/* Corps du programme en fonction du passage du paramètre */
IF COND(%PARMS() *EQ 2) THEN(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 est renseigné')
ENDDO
ELSE CMD(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 n''est pas renseigné')
ENDDO
ENDPGM
Malheureusement, si on est confrontés à une contrainte de version, %PARMS ne descend pas en dessous de la V7R4 :
CEETSTA – V7R3 et antérieures
Dans ce cas, la solution la plus propre (je ne parlerai donc pas de monitoring sur un CHGVAR) est l’utilisation de l’API CEETSTA. Il suffit de lui passer en paramètre : – Une variable qui contiendra la valeur de retour, 1 si le paramètre est transmis, 0 s’il n’est pas transmis – Une variable indiquant la position du paramètre à contrôler
presence_flag
Sortie
*INT
Variable de retour : 1 ou 0
arg_num
Entrée
*INT
Position de la variable à tester
PGM PARM(&PARAM1 &PARAM2)
/* Paramètres */
DCL VAR(&PARAM1) TYPE(*CHAR) LEN(10)
DCL VAR(&PARAM2) TYPE(*CHAR) LEN(10)
/* Déclaration des variables nécessaires à l'utilisation de l'API */
DCL VAR(&PRESENCE) TYPE(*INT) /* Variable de retour : 1 ou 0 */
DCL VAR(&ARG_NUM) TYPE(*INT) VALUE(2) /* Position de la variable à tester */
/* Appel de l'API */
CALLPRC PRC('CEETSTA') PARM((&PRESENCE) (&ARG_NUM))
/* Corps du programme en fonction du passage du paramètre */
IF COND(&PRESENCE *EQ 1) THEN(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 est renseigné')
ENDDO
ELSE CMD(DO)
SNDPGMMSG MSG('Le paramètre &PARAM2 n''est pas renseigné')
ENDDO
ENDPGM
Remarques
Le compte des paramètres pour la arg_num commence à 1 La valeur de retour est un *INT pas un *LGL
https://www.gaia.fr/wp-content/uploads/2023/08/Openssh.gif191194Julien/wp-content/uploads/2017/05/logogaia.pngJulien2023-12-24 01:41:132023-12-24 01:41:15Contrôler le nombre de paramètres passés à un programme CL – %PARMS() / CEETSTA