Dans une base de données bien définie, nos enregistrements sont identifiés par des clés (ie unique). Il existe toutefois différentes façon de matérialiser ces clés en SQL.
Première bonne résolution : on ne parlera pas ici des DDS (PF/LF) !
Quelques rappels
je n’insiste pas, mais une base de donnée relationnelle, DB2 for i dans notre cas, fonctionne à la perfection, à condition de pouvoir identifier nos enregistrements par des clés.
Cf https://fr.wikipedia.org/wiki/Forme_normale_(bases_de_donn%C3%A9es_relationnelles)
Une normalisation raisonnable pour une application de gestion est la forme normale de Boyce-Codd (dérivée de la 3ème FN).
Clés
Vous pouvez implémenter vos clés de différentes façons, voici une synthèse :
| Type | Où | Support valeur nulle ? | Support doublon ? | Commentaire |
| Contrainte de clé primaire | Table | Non | Non | Valeur nulle non admise, même si la colonne clé le supporte |
| Contrainte d’unicité | Table | Oui | non : valeurs non nulles oui : valeurs nulles | Gère des clés uniques uniquement si non nulles |
| Index unique | Index | Oui | Non | Gère des clés uniques. La valeur NULL est supportée pour 1 unique occurrence |
| Index unique where not null | Index | Ouis | non : valeurs non nulles oui : valeurs nulles | Gère des clés uniques uniquement si non nulles |
Attention donc à la définition de UNIQUE : à priori ce qui n’est pas NULL est UNIQUE.
Concrètement ?
Prenons un cas de test simpliste pour montrer la mécanique : un fichier article avec une clé et un libellé
Clé primaire
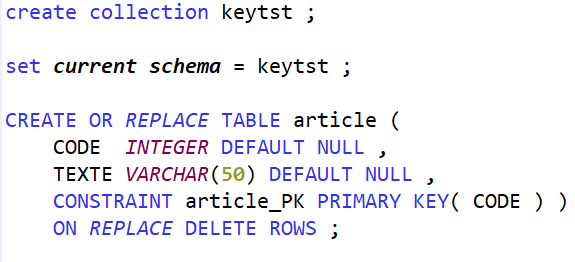
La colonne CODE admet des valeurs nulles, mais est fait l’objet de la contrainte de clé primaire.
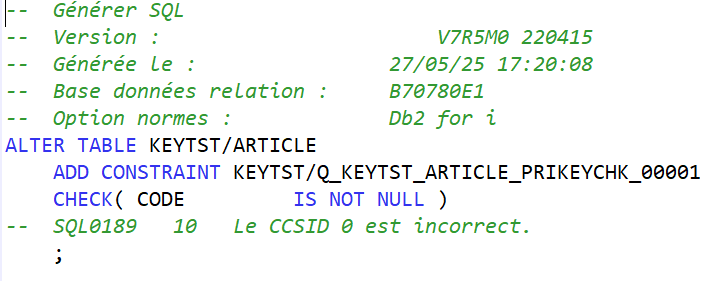
A la création de la contrainte de clé primaire, le système créé automatiquement une contrainte de type CHECK pour interdire l’utilisation de valeur nulle dans cette colonne :

Avec :
La clé primaire joue son rôle avec des valeurs non nulles :

Et des valeurs nulles :

On retrouve ici le nom de la contrainte générée automatiquement !
Avec une contrainte de clé unique ?
Le comportement est identique sur une clé non nulle.
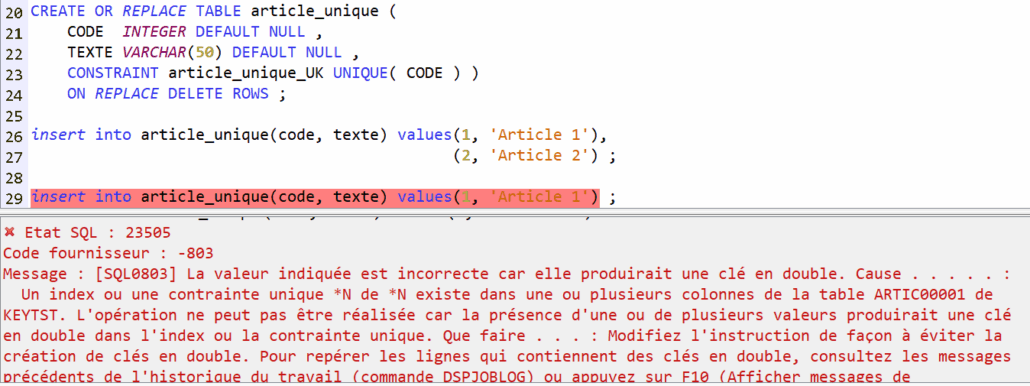
Mais avec une clé nulle (ou dont une partie est nulle si elle composée) :
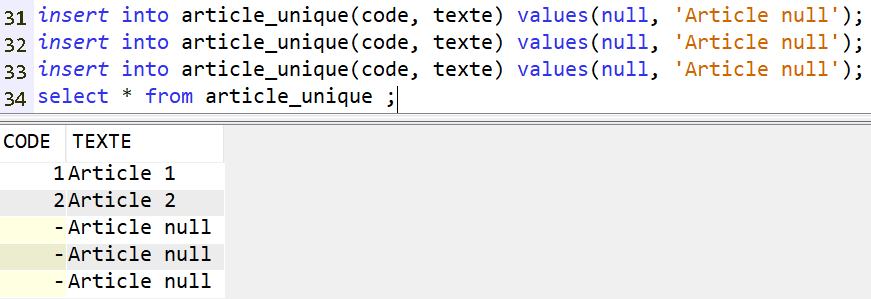
On peut ajouter un index unique pour gérer le problème. Dans ce cas, une et une seule valeur nulle sera acceptée :

Mais dans ce cas pourquoi ne pas utiliser une clé primaire ??
Clé étrangère, jointure
Ajoutons un fichier des commandes, ici une simplification extrême : 1 commande = 1 article.
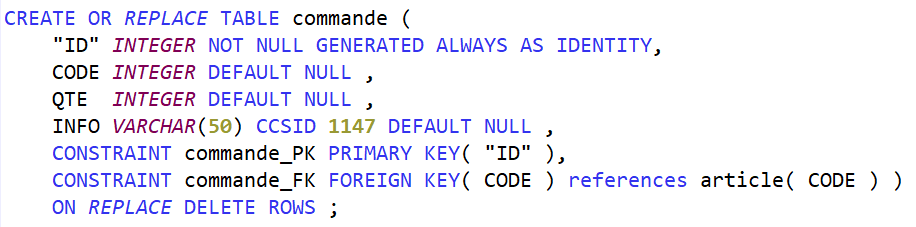
On ajoute une contrainte de clé étrangère qui matérialise la relation entre les tables commande et article. Pour cette contrainte commande_FK, il doit exister une contrainte de clé primaire ou de clé unique sur la colonne CODE dans la table article.
La contrainte se déclenche si l’article référencé n’existe pas :
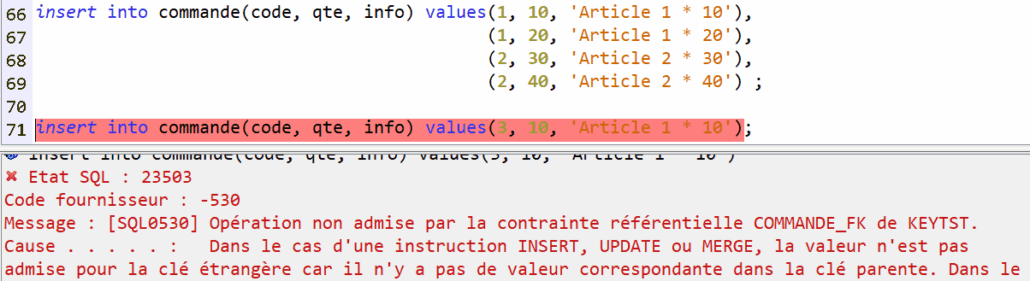
Cas identique mais en s’appuyant sur la table article_unique qui dispose d’une clé unique et non primaire :
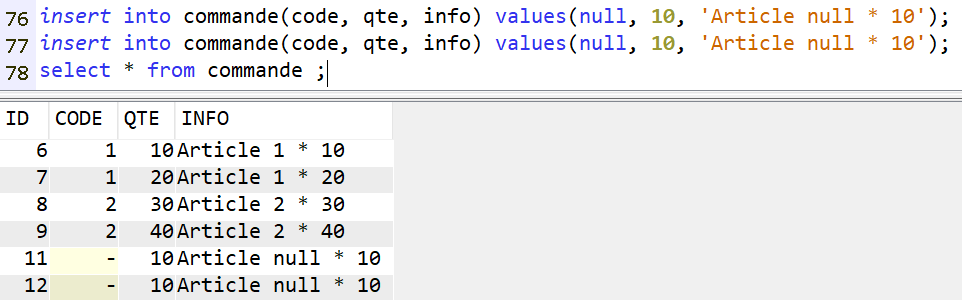
Dans ce cas les valeurs nulles sont supportées, en multiples occurrences (sauf à ajouter encore une fois un index unique au niveau de la commande).
Récapitulons ici nos données pour comprendre les jointures :

Démarrons par ARTICLE & COMMANDE :
La table ARTICLE ne peut pas avoir de clé nulle, donc pas d’ambiguïté ici

Avec right join ou full outer join nous accèderons au lignes de commande pour lesquelles CODE = null.
C’est le comportement attendu.
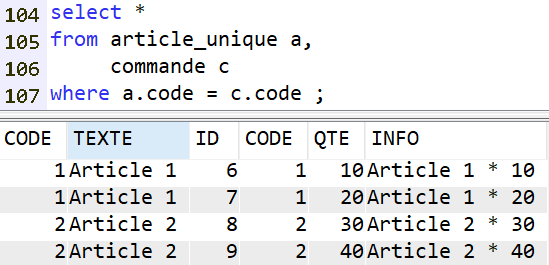
Voyons avec ARTICLE_UNIQUE et COMMANDE :
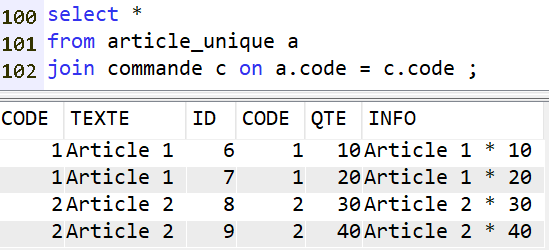
Ici on pourrait s’attendre à obtenir également les lignes 11 et 12 de la table COMMANDE : le CODE est nulle pour celles-ci, mais il existe une ligne d’ARTICLE pour laquelle le code est null. Il devrait donc y avoir égalité.
En réalité les jointures ne fonctionnent qu’avec des valeurs non nulles
De même que la clause WHERE :
Il faut donc utiliser ce style de syntaxe :
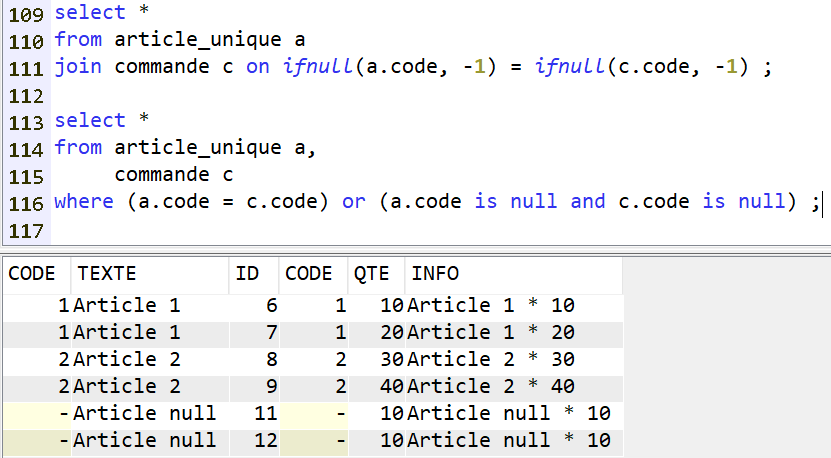
C’est à dire :
- soit remplacer les valeurs nulles par des valeurs inexistantes dans les données réelles
- soit explicitement indiquer la condition de nullité conjointe
Bref, syntaxiquement cela va rapidement se complexifier dans des requêtes plus évoluées.
Clé composée
Evidemment, c’est pire ! Imaginons que l’on ait une clé primaire/unique dans la table ARTICLE composée de 2 colonnes (CODE1, CODE2), et donc présentes toutes les deux dans la table COMMANDE :

Et les performances ?
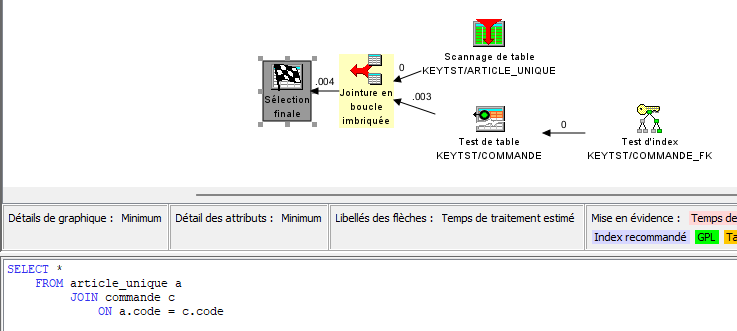
En utilisant la jointure, l’optimiseur est capable de prendre en charge des accès par index :
Mais en utilisant IFNULL/COALESCE, ces valeurs deviennent des valeurs calculées, ce qui invalide l’usage des index :
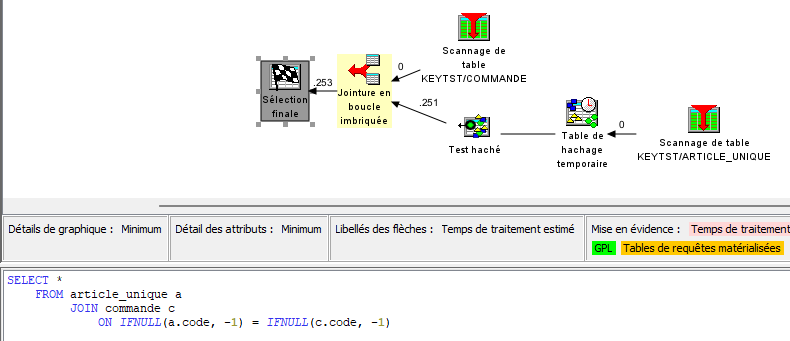
Ce n’est donc pas viable sur des volumes plus importants. Il existe des solutions (index dérivés par exemple) mais la mécanique se complique encore !
Préconisations
De façon générale pour vos données de gestion, en excluant les fichier de travail (QTEMP a d’autres propriétés), les fichiers de logs, les fichier d’import/export …
- Pas de valeur NULL dans vos clés
- Pour les clés atomique c’est une évidence, pour les clés composées c’est beaucoup plus simple
- Une contrainte de clé primaire pour toutes vos tables !
- N’hésitez pas à utiliser des clés auto-incrémentées
- Des contraintes d’unicités ou des index uniques pour vos autres contraintes d’unicité, techniques ou fonctionnelles
- Pas d’excès, sinon il y a un défaut de conception (cf les formes normales)
- Si possible des contraintes de clé étrangère pour matérialiser les relations entre les tables
- Délicat sur l’existant, les traitements doivent tenir compte du sens de la relation
- Favorisez l’usage des clés, contraintes et index par l’optimiseur
- Scalabilité entre vos environnements de développement/test et la production