Il est possible que vous ayez des doutes sur les performances de vos requêtes SQL, voici comment avoir une idée rapide de ce qui tourne
On va utiliser ACS dans Base de données choisir SQL Performance center
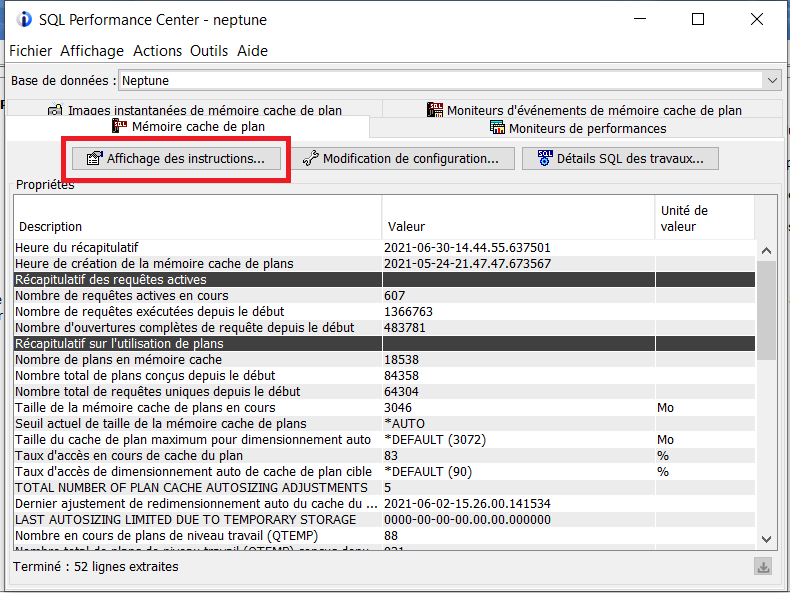
Vous avez un onglet Affichage des instructions
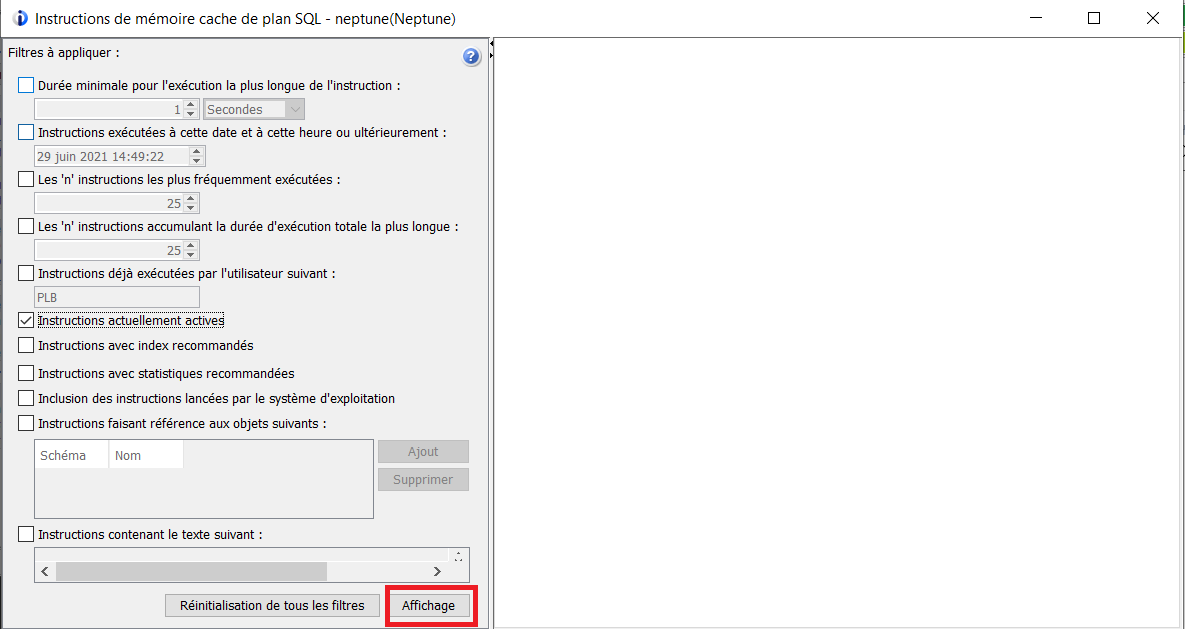
Vous choisissez le filtre à appliquer, ici on choisit les actives, vous pouvez être beaucoup plus pertinent en limitant votre choix.
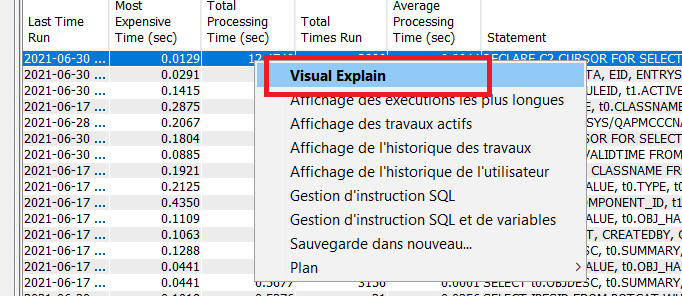
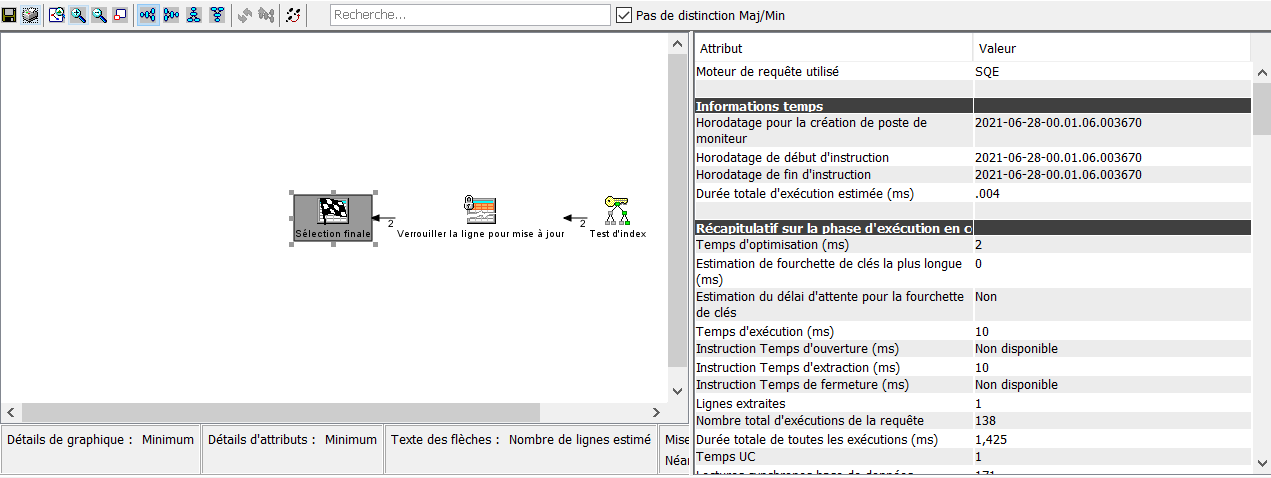
Une fois que vous avez repéré une requête candidate, il vous suffit de faire un clic droit sur celle ci et vous pouvez lancer directement Visual Explain, qui vous expliquera le comportement de cette requête, vous pourrez alors faire les ajustements qui s’imposent
Le résultat dans V-E
PS: Le principal critère de performance sur SQL, c’est les index, pensez à surveiller les suggestions faites par Index Advisor
L’idée est de limiter les requêtes selon certain critères (de temps d’exécution, d’espace temporaire occupé etc… ) Jusqu’à présent c’était pas toujours simple et un peu binaire
Ajout d’un seuil à contrôler
Se fait par la procédure QSYS2.ADD_QUERY_THRESHOLD
Vous devez indiquer : – Un nom ici Seuil – Le seuil à contrôler – Une valeur pour ce seuil – Un filtre d’inclusion ou d’exclusion ici inclusion du profil PLB – Un délai de rafraichissement en seconde
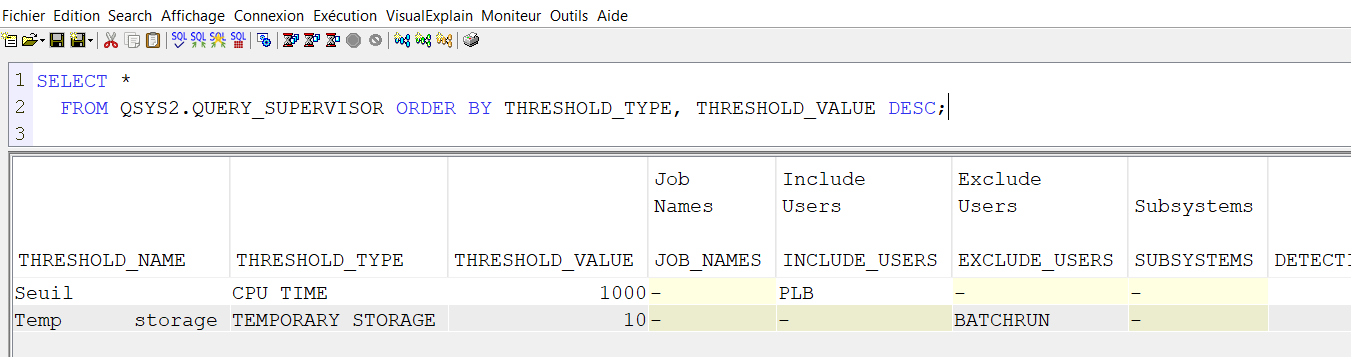
Vous avez une vue qui permet de voir les seuils définis sur votre partition
C’est la vue QUERY_SUPERVISOR
exemple
voir tous les seuils définis pour Query supervisor
SELECT * FROM QSYS2.QUERY_SUPERVISOR ORDER BY THRESHOLD_TYPE, THRESHOLD_VALUE DESC;
;
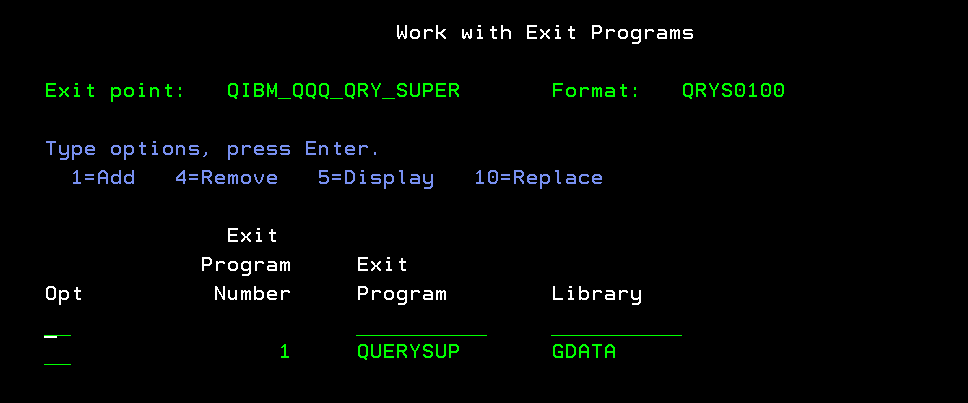
Vous pouvez indiquer un programme d’exit QIBM_QQQ_QRY_SUPER
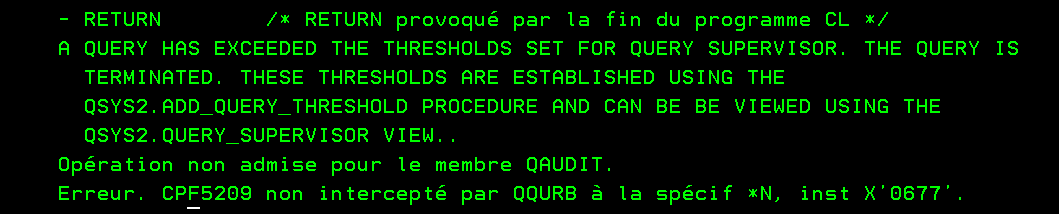
ci joint un exemple basique pour expliquer ce qui ce passe
Il existe un grand nombre d’API aux fonctionnalités diverses dont certaines nous permettent de récupérer des données structurées dans différents formats (XML, JSON, …).
Grace aux fonctions SQL de l’IBMi nous pouvons récupérer ces données pour les insérer dans les fichiers de la base de données.
La commande SQL suivante permet d’afficher les données dans un champ DATA
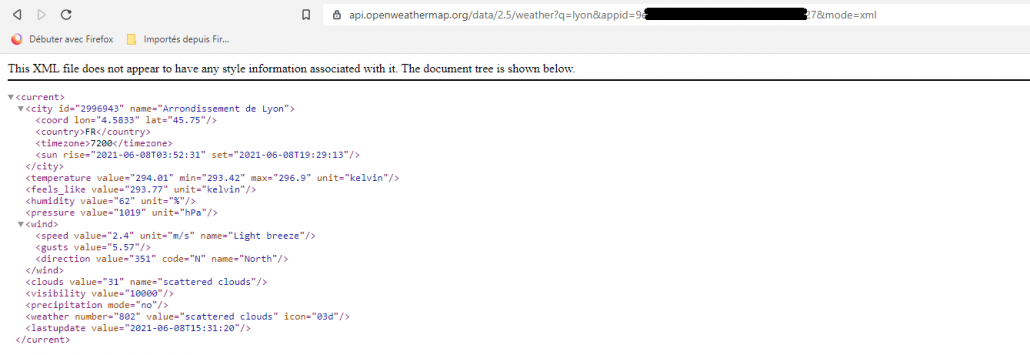
SELECT DATA FROM (values char(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=xml',''), 4096)) ws(data);
Sortie API en JSON
La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values char(SYSTOOLS.HTTPGETCLOB('api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}',''), 4096)) ws(data);
Sortie API en HTML
La commande SQL suivante permet d’afficher les données dans un champ DATA
SELECT DATA FROM (values char(SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/weather?q={city name}&appid={API key}&mode=html',''), 4096)) ws(data);
Récupération des données
En XML
On crée un fichier qui contiendra les colonnes que l’on veut récupérer (Ville, Température en cours, date, …)
CREATE TABLE GG/METEODB (VILLE_ID DECIMAL (9, 0) NOT NULL WITH DEFAULT, VILLE_NOM CHAR (50) NOT NULL WITH DEFAULT, TEMPERATURE DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MIN DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MAX DECIMAL (5, 2) NOT NULL WITH DEFAULT, DATE_MAJ CHAR (20) NOT NULL WITH DEFAULT);
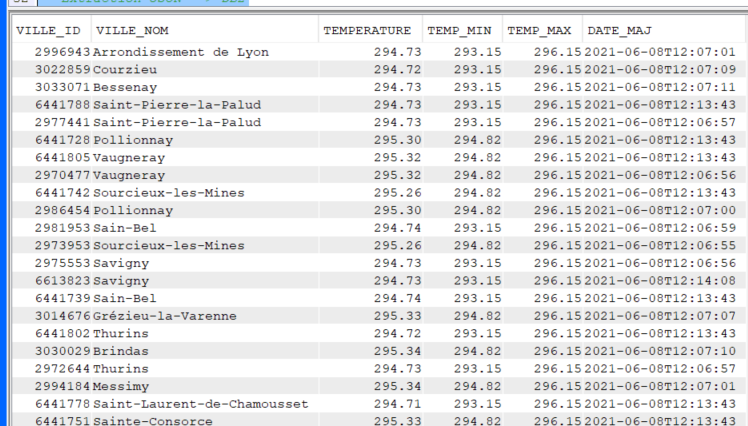
Récupérer les données de l’API dans le fichier créé :
INSERT INTO GG.METEODB select xdata.* FROM xmltable('$doc/cities/list/item' PASSING XMLPARSE(document SYSTOOLS.HTTPGETCLOB('https://api.openweathermap.org/data/2.5/find?lat=45.75&lon=4.5833&cnt=10&appid={API key}&mode=xml','')) AS "doc" COLUMNS ville_id decimal(9, 0) PATH 'city/@id', ville_nom varchar(50) PATH 'city/@name', temperature decimal(5, 2) PATH 'temperature/@value', temp_min decimal(5, 2) PATH 'temperature/@min', temp_max decimal(5, 2) PATH 'temperature/@max', date_maj varchar(20) PATH 'lastupdate/@value' ) as xdata;
En JSON
Contrairement à XML, on peut créer tout de suite un fichier qui contiendra les colonnes que l’on veut récupérer.
CREATE TABLE GG.METEOBD (VILLE_ID DECIMAL (9, 0) NOT NULL WITH DEFAULT, VILLE_NOM CHAR (50) NOT NULL WITH DEFAULT, TEMPERATURE DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MIN DECIMAL (5, 2) NOT NULL WITH DEFAULT, TEMP_MAX DECIMAL (5, 2) NOT NULL WITH DEFAULT, DATE_UX_MAJ DECIMAL (12, 0) NOT NULL WITH DEFAULT)
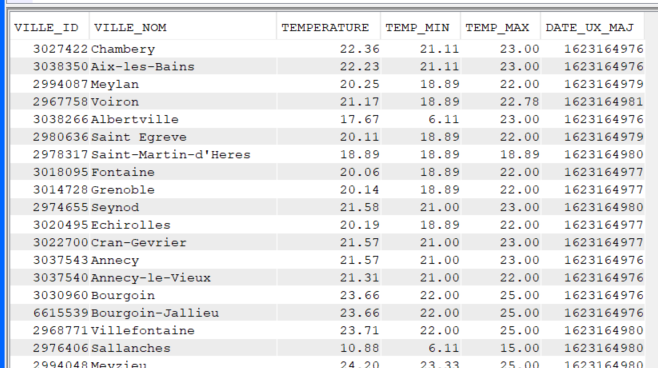
Récupérer les données de l’API dans le fichier créé :
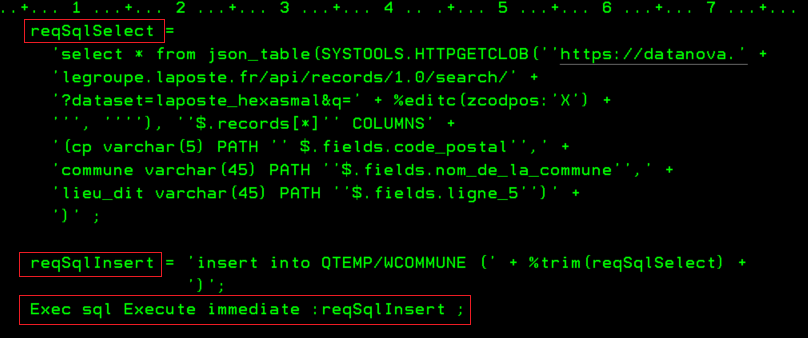
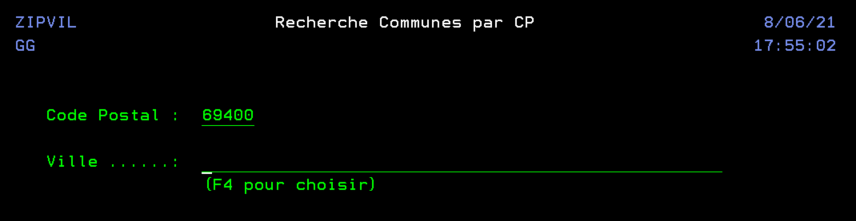
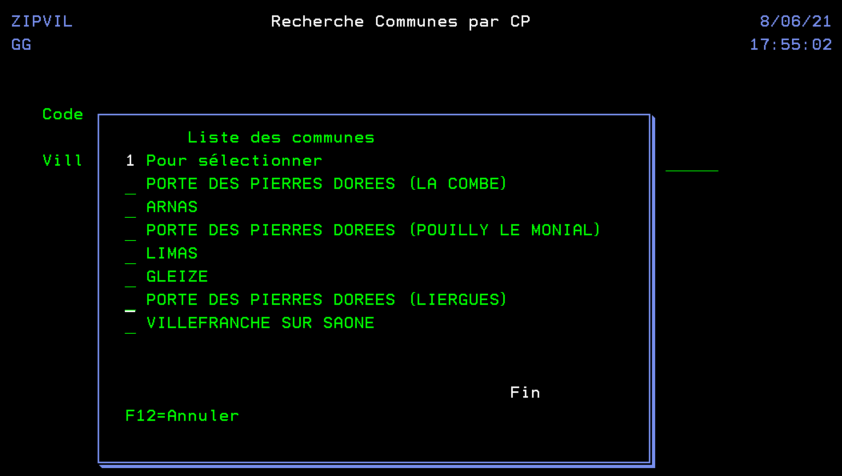
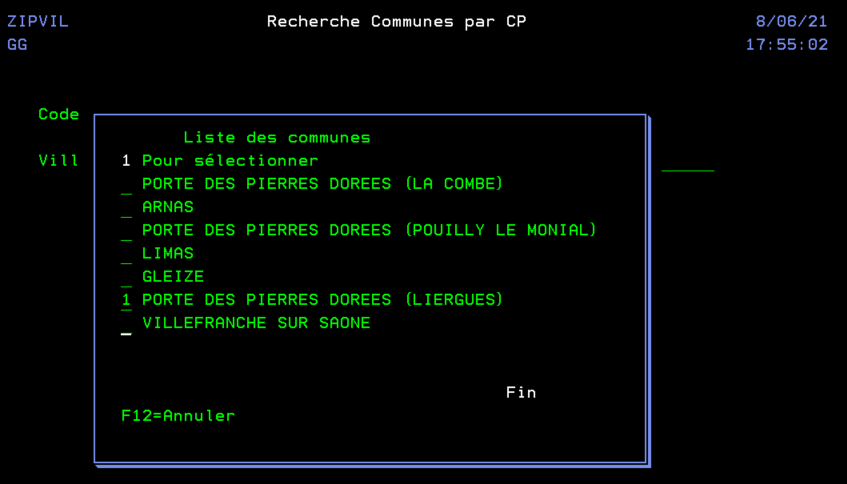
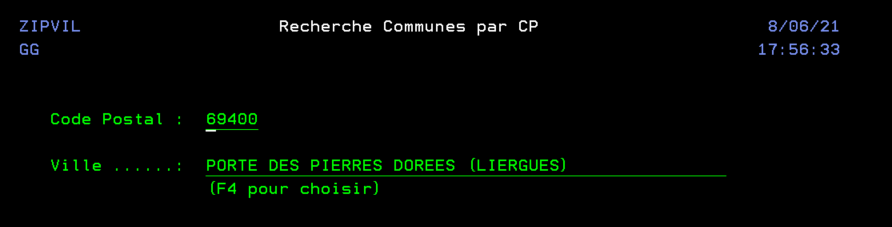
En utilisant une API de LA POSTE qui ne nécessite pas d’inscription au préalable, ni d’identification. Nous pouvons réaliser un programme qui nous aide à retrouver une commune à partir d’un code postal, dans l’optique d’aider au remplissage de certains formulaires. On crée un fichier temporaire en interrogeant directement l’API.
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2021-06-09 13:56:312022-04-12 12:28:31UTILISATION DES API EN SQL
Voici quelques variables que vous pouvez utiliser dans vos requêtes SQL
par exemple Client_Ipaddr qui est arrivée avec la TR4
Quelques registres et variables d’environnement
select current time as heure_en_cours, current date as date_en_cours, current user as utilisateur_courant, current timestamp as timestamp_en_cours, CURRENT CLIENT_ACCTNG as Client_connexion, CURRENT CLIENT_APPLNAME as Client_Application, Current timezone as Fuseau_Horaire, Current server as Current_Server , current path as Current_path, CURRENT CLIENT_APPLNAME as Programme_client, CURRENT CLIENT_USERID as Utilisateur_client, CURRENT CLIENT_PROGRAMID as Programme_client from sysibm.sysdummy1
Quelques Variables globales dans SYSIBM
select SYSIBM.Client_Host as Client_Host, SYSIBM.Client_Ipaddr as Client_Ipaddr, SYSIBM.Client_Port as Client_Port, SYSIBM.Package_Name as Package_Name, SYSIBM.Package_Schema as Package_Schema, SYSIBM.Package_Version as Package_Version, SYSIBM.Routine_Schema as Routine_Schema, SYSIBM.Routine_Specific_Name as Routine_Specific_Name, SYSIBM.Routine_Type as Routine_Type from sysibm.sysdummy1
Comme dans nos exemples, ces variables sont utilisables dans vos requêtes
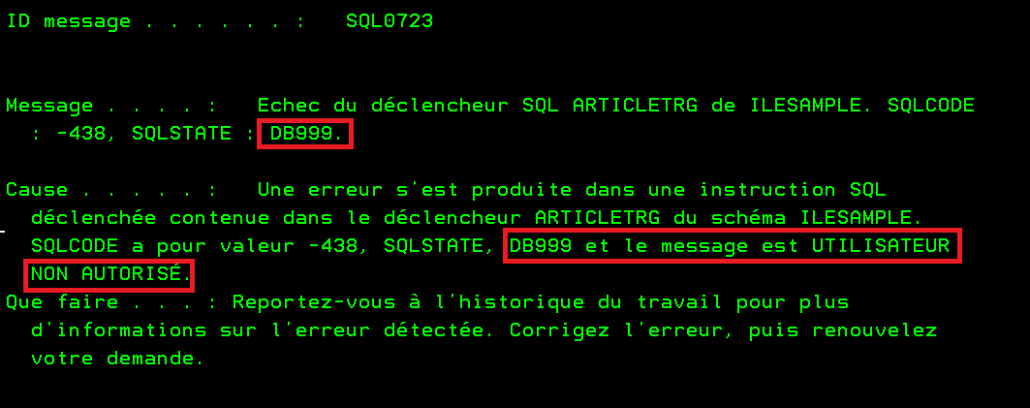
Depuis la TR4 de la V7R4, vous pouvez passer votre propre SQLSTATE ce qui est très intéressant sur les triggers avants par exemple. Vous pouvez avoir la vraie raison du refus C’est un petit pas pour SQL, mais un grand pas pour le développeur SQL
Exemple
Création de la table
CREATE OR REPLACE TABLE ARTICLE ( NOMART CHAR(30) CCSID 297 NOT NULL DEFAULT » , NUMART DECIMAL(6) , DESIGN CHAR(25) CCSID 297 NOT NULL DEFAULT » , PRXUNI DECIMAL(6) ) Insertion d’un article (Je sais, je surfe sur l’actualité du moment) INSERT INTO ARTICLE VALUES(‘Maillot Benzema’, 19, ‘Maillot Benzema EDF’, 166)
tentative de mise à jour
UPDATE ARTICLE SET PRXUNI = 167 WHERE NUMART = 19
Création d’un trigger de controle ici on teste que l’utilisateur est bien ‘DBADMIN’ pour pouvoir modifier le tarif
CREATE OR REPLACE TRIGGER ARTICLETRG BEFORE UPDATE OF PRXUNI ON ARTICLE FOR EACH ROW BEGIN ATOMIC IF CURRENT USER <> ‘DBADMIN’ THEN SIGNAL SQLSTATE ‘DB999’ SET MESSAGE_TEXT = ‘UTILISATEUR NON AUTORISÉ’; END IF; END;
Par SQL
Maintenant dans un programme RPGLE
On va utiliser get diagnostics pour récupérer le SQLTATES et le Message associé
**free dcl-s MessageText char(45) ; dcl-s ReturnedSQLState char(5); exec sql SET OPTION COMMIT = *NONE ; // test mise à jour trigger exec sql UPDATE ARTICLE SET PRXUNI = 167 WHERE NUMART = 19 ; exec sql get diagnostics condition 2 :ReturnedSQLState = RETURNED_SQLSTATE , :MessageText = MESSAGE_TEXT; dsply (ReturnedSQLState + ‘ ‘ + MessageText) ; *inlr = *on ;
Vous lancez le programme
Conclusion :
c’est une nouveauté qui devrait simplifier le contrôle des triggers est donc leur usage.
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-05-26 12:59:392022-04-12 14:18:01Conversion d’une OUTQ en PDF par GENERATE_PDF
Vous voulez copier un fichier vers un autre, une des alternatives est d’utiliser SQL, en utilisant une instruction du genre insert into ficcible select * from ficsource. Il existe d’autres méthodes que les plus anciens connaissent bien, mais les nouveaux un peu moins. C’est la commande CPYF voici quelques utilisation à connaître
1) Les sélections
Sélection d’un nombre d’enregistrement Paramètres FROMRCD TORCD exemple les 100 premiers FROMRCD(1) TORCD(100)
Sélection sur des valeurs de clé FROMKEY TOKEY exemple les clés de 0001 à 0002 FROMKEY(1 (0001)) TOKEY(1 (00002))
Sélection sur des caractères d’un format INCCHR RCD Exemple les enregs qui OUI en position 15 INCCHAR(RCD 15 *EQ ‘OUI’)
Sélection des avec des relations INCREL Exemple les enregistrements valides et avec une date de référence > ‘20200101’ INCREL((*IF VALIDE *EQ ‘OUI’) (*AND DATEREF *GT ‘20200101’))
2) Les performances
La plupart du temps un CPYF est plus rapide qu’une copie par SQL
Quand on copie un fichier qui a des clés, pour améliorer les performances on peut indiquer, FROMRCD(1) au lieu de FROMRCD(*START) , la copie se fera sans tenir compte de l’index, et le gain est d’environ la moitié.
3) Les ajustements de zones
Paramètre FMTOPT utilisez les 2 paramètres suivants pour que vos nouvelles zones soient initialisées et que celle qui ont changé soient recadrées FMTOPT(*MAP *DROP)
4) Les messages d’erreur
Vous devez monitorer, votre commande CPYF, CPF2800 CPF2900 CPF3100 Avant de copier, vérifier si votre fichier source contient des enregistrements DCL &nbr *dec 10 RTVMBRD SOURCE NBRRCD(&nbr) if cond(&nbr *gt 0) then(do) cpyf … enddo
5) Formater à l’exécution
Pour améliorer le paramétrage et l’administration vous pouvez construire la commande CPYF dynamiquement
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-05-09 10:32:022022-04-12 14:22:075 choses à savoir sur le CPYF
Une définition simple, ce sont des traitements qui se déclenchent pour traiter des entrées d’une pile et qui ne renvoient pas de résultats directs au proccess émetteur
Il existe des produits spécifiques pour faire ça, sur l’IBMi le plus connu est bien sur mqseries . Mais il est maintenant possible d’installer des produits open source comme RabbitMQ , etc…
Il existe également des solutions natives de la plateforme.
Parmi ces solutions il y a 2 méthodes
Cyclique ( toutes les 30 secondes)
A l’événement qui ne se déclencheront qu’en cas de nécessité (exemple triggers)
On ne présentera ici que les secondes.
Les triggers
Ce sont des programmes qu’on va enregistrer au niveau de la base de données, ils vont se déclencher sur un update, insert ou delete avant ou après l’action.
On peut les déclarer par commande ADDPFTRG ou par l’instruction SQL CREATE TRIGGER, on peut être plus précis sur l’exécution en SQL (Niveau zone modifiée par exemple)
Les DTAQs
Ce sont des files d’attentes que l’on crée par CRTDTAQ , on peut écrire dedans par API (QSNDDTAQ, QRCVDTAQ) ou par SQL QSYS2.SEND_DATA_QUEUE() et QSYS2.RECEIVE_DATA_QUEUE()
Pour la réception, on peut indiquer un temps négatif souvent -1, et le traitement se déclenchera quand il y aura un entrée dans la file !
soit dans le programme de traitement CALL PGM(QRCVDTAQ) PARM(&DTAQNOM &DTAQBIB &DTAQLEN &DATA &WAIT) /* &wait = -1 */
Les msgqs en wait
historiquement, souvent utilisé, par exemple pour superviser la msgq qsysopr
dans le programme de traitement qui boucle sur cette instruction RCVMSG … WAIT(*MAX)
Les fichiers à fin retardée
Le principe est le suivant, votre programme attendra un enregistrement quand il aura fini de lire les enregistrements trouvés
Avant le programme RPGLE OVRDBF FILE(VOTREFIC) EOFDLY(99999)
dans le programme RPGLE
dou %eof() ; …. read VOTREFIC ; … endif ;
Les watchers
Permettent d’analyser en temps réels des messages qui arrive dans les joblog, les historiques de log voir une autre file de message (MSGQ) . Pour démarrer un watcher, on utilise la commande STRWCH STRWCH SSNID(ANAWCH) WCHPGM(votre bib/votre programme) + CALLWCHPGM(WCHEVT) WCHMSG((ALL)) WCHMSGQ((Votre bib/votre msgq))
votre programme reçoit 4 paramètres L’option, la session, l’erreur et la donnée du message
C’est des actions système enregistrées que vous pouvez voir par la commande WRKREGINF, et seules les actions définies dans cette liste sont utilisables.
Pour ajouter un programme c’est soit la commande addexitpgm ou l’option 8 dans wrkreginf.
Le principe , on reçoit un buffer avec les données en cours et on renvoie status pour dire ok ou ko, vous pouvez dire OK systématiquement et traiter ou faire un contrôle d’autorisation applicatif
Exemple sur FTP
PGM PARM (& APPID & OPID & USRPRF & REMOTEIP & REMOTELEN & OPINFO & OPLEN & OK) DCL & APPID * CHAR 4 /* ID D’APPLICATION, NUM BINAIRE */ DCL & OPID * CHAR 4 /* ID D’OPERATION, NUMERO BINAIRE */ DCL & OPNUM * 4 /* OPERATION ID, UTILISABLE DANS CL */ DCL & USRPRF * CHAR 10 /* PROFIL UTILISATEUR UTILISANT FTP */ DCL & REMOTEIP * CHAR 251 /* ADRESSE IP */ DCL & REMOTELEN * CHAR 4 /* LONGUEUR DU PARAMETRE PRECEDENT */ DCL & OPINFO * CHAR 251 /* INFORMATIONS SPECIFIQUES OP */ DCL & OPLEN * CHAR 4 /* LONGUEUR DU PARAMETRE PRECEDENT */ DCL & OK * CHAR 4 /* SIGNAL DE CONFIRMATION / / seulement utilisateur FTPUSR */ if cond(&USRPRF *ne ‘FTPUSR’) then(do) chgvar &ok (X’00000001′) enddo ENDPGM
Vous devez arrêter le service FTP pour que cela soit pris en compte ENDTCPSVR *FTP puis STRTCPSVR
Conclusions
Vous avez plusieurs solutions dans certains cas , et certaines sont plus à jour
les 4 à utiliser aujourd’hui sont Les triggers pour la base de données, si possible en SQL Les watchers pour les événements de log systèmes Les progammes d’exit pour les actions Système, par exemple pour les connexions ODBC Les dtaq pour gérer des piles de données applicatives
Tous ces programmes sont appelés souvent, ils doivent être donc optimisés et ils ne doivent pas planter pour éviter de bloquer la file !
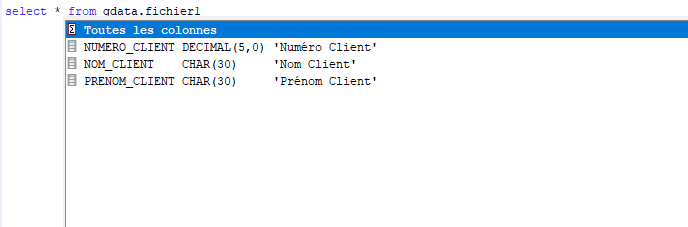
Vous avez un fichier pf, et pour les gens qui font des requetes dessus vous voulez mettre des noms plus signicatif
exemple remplacer num234 par numero_de_client
Vous ne voulez pas ou vous pas migrer vers une base en SQL , voila comment faire
Cette opération ne peut pas être faite en SQL En effet ALTER TABLE FICHIER1 ALTER COLUMN ne permet pas de changer le nom de la colonne
C’est le mot clé Alias qui permet ca
Fichier avant
A R FICHIER1F A* A NUMCLI 5 0 COLHDG(‘Numéro’ ‘Client’) A NOMCLI 30 COLHDG(‘Nom ‘ ‘Client’) A PRECLI 30 COLHDG(‘Prénom’ ‘Client’)
Vous pouvez mettre des noms longs
fichier après, on ajoute les alias
A R FICHIER1F A* A NUMCLI 5 0 COLHDG(‘Numéro’ ‘Client’) A ALIAS(NUMERO_CLIENT) A NOMCLI 30 COLHDG(‘Nom ‘ ‘Client’) A ALIAS(NOM_CLIENT) A PRECLI 30 COLHDG(‘Prénom’ ‘Client’) A ALIAS(PRENOM_CLIENT)
Pour ne pas perdre vos données vous pouvez faire un change pf
Cette opération ne change pas le niveau de format , pas de recompile de votre application
vous devrez avoir le source sur votre machine de prod pour faire un CHGPF
Si vous n’avez pas le source mais que vous voulez préparer les données pour de la BI par exemple vous pouvez faire des vues qui seront utilisées à la place de vos PF !
Exemple
CREATE VIEW fichier_client AS SELECT nomcli as nom_client, numcli as numero_client, precli as prenom_client FROM fichier1
2) Vous voulez ajouter une zone à notre pf
L’opération peut se faire cette fois directement par SQL, même sur un PF
Exemple, vous voulez ajouter une zone mail à votre fichier
ALTER TABLE FICHIER1 ADD COLUMN MAIL_CLIENT FOR COLUMN MAIL CHARACTER ( 50) CCSID 1147 NOT NULL WITH DEFAULT
Vous ne perdez pas les données, ni les fichiers qui pointent dessus Mais attention comme en DDS vous changer le niveau de format donc vos programmes doivent être recompilés ou vous devez indiquer lvlchk(*no) sur vos fichiers (analyse à faire) Vous restez en format DDS, vous ne pourrez pas ajouter tous les types de données Attention il faudra reporter la zone dans votre DDS pour être cohérent
3) Contrôlez les données de vos fichiers
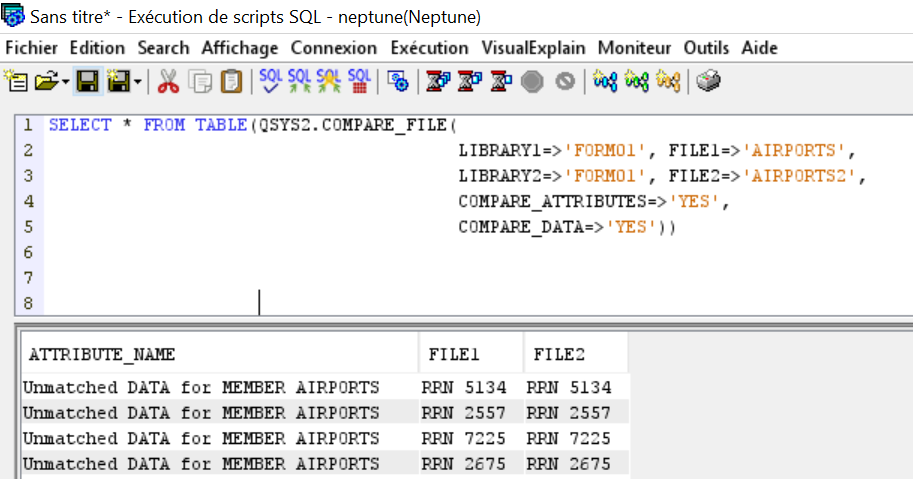
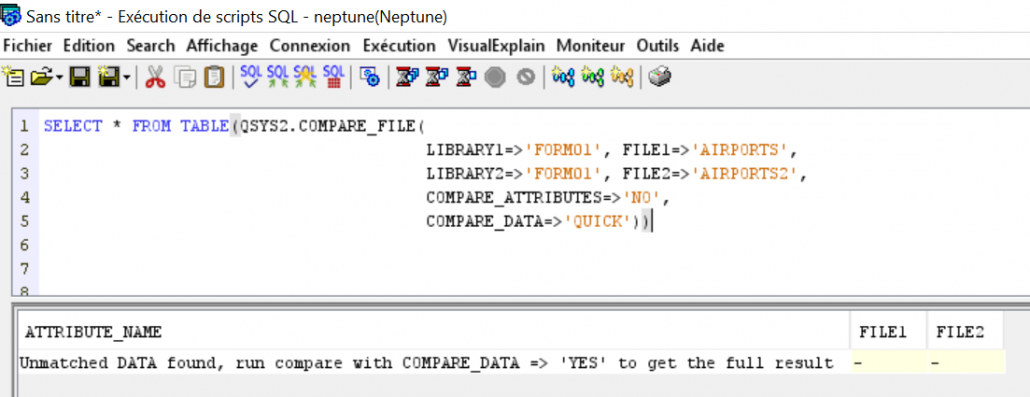
Si vous avez des fichiers PF, vous pouvez avoir des données erronées, vous pouvez maintenant simplement contrôler la validité de vos données par une fonction table, systools.validate_data !
Ça vous permettra d’avoir la liste des enregistrements qui ont des erreurs de données, ça peut être intéressant de le faire de temps en temps sur les données sensibles de votre base.
4) Supprimer définitivement les enregistrements effacés
Quand vous supprimez vos données elles ne sont pas réellement supprimés elles sont juste flaguées Pour les supprimer vous devez faire un RGZPFM de votre table qui supprimera réellement les enregistrements et qui reconstruira les indexes . Commencer par le faire sur les tables qui ont le plus d’enregistrements supprimés
5) Contrôler qu’il ne vous manque pas d’index
Un des principaux axe pour améliorer les performances de votre base de données est souvent d’ajouter des index manquants.
Pour connaitre les index à analyser, vous avez une table qui s’appelle QSYS2.SYSIXADV qui vous propose des suggestions d’index
Vous pouvez ajouter les index qui sont souvent et régulièrement demandés.
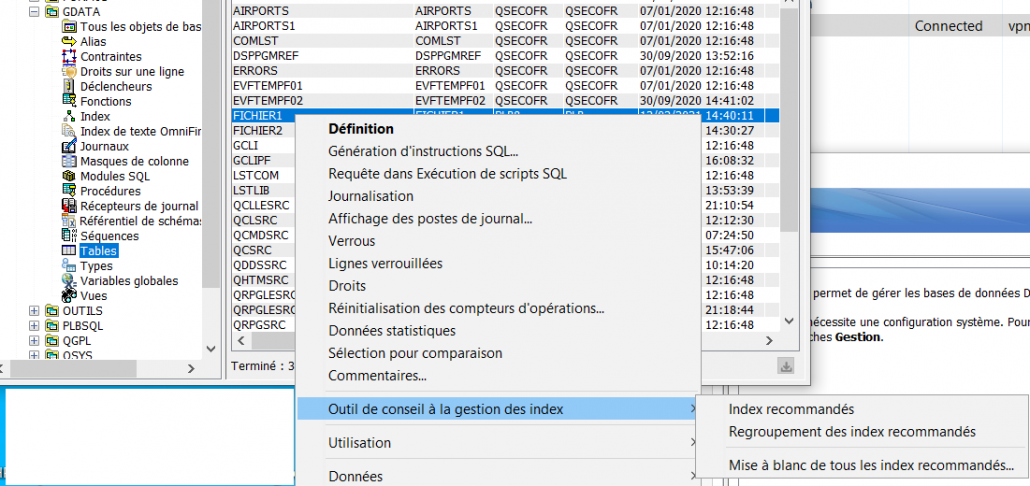
Vous pouvez également voir ces suggestions sur ACS.
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2021-03-13 09:49:092022-04-12 16:47:135 petites astuces pour améliorer votre base de données