https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-11-03 11:53:522024-11-04 09:11:40Utilisez de l’Unicode en 5250
Vous êtes en train d’analyser votre data base et vous voulez mettre en place des relations sur celle-ci.
Je vais vous re présenter les contraintes d’intégralité référentielles et plus précisément pour voir et comprendre les données en attente de validation .
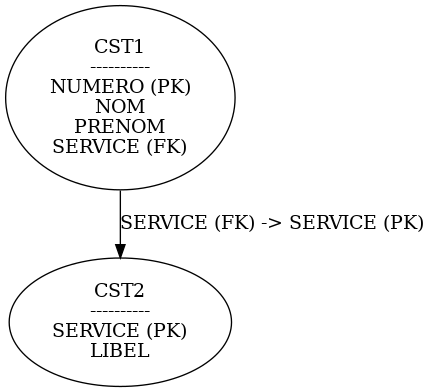
Voici un petit exemple pour illustrer : Considérons un fichier pour les employés et un pour les services services :
Création du fichier des services CREATE OR REPLACE TABLE GDATA.CST2 ( SERVICE CHAR(3) CCSID 1147 NOT NULL DEFAULT » , LIBEL CHAR(30) CCSID 1147 NOT NULL DEFAULT » , CONSTRAINT GDATA.Q_GDATA_CST2_SERVICE_00001 PRIMARY KEY( SERVICE ) )
RCDFMT CST2F ;
1/ Création du fichier des employés avec une contrainte
CREATE OR REPLACE TABLE GDATA.CST1 (
NUMERO DECIMAL(5, 0) NOT NULL DEFAULT 0 , NOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » , PRENOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » , SERVICE CHAR(3) CCSID 1147 NOT NULL DEFAULT » , PRIMARY KEY( NUMERO ) , CONSTRAINT GDATA.Q_GDATA_CST1_SERVICE_00001 FOREIGN KEY( SERVICE ) REFERENCES GDATA.CST2 ( SERVICE ) ON DELETE NO ACTION ON UPDATE NO ACTION )
RCDFMT CST1F ;
Vous pouvez ajouter la contrainte ultérieurement avec
ALTER TABLE GDATA.CST1 ADD CONSTRAINT GDATA.Q_GDATA_CST1_SERVICE_00001 FOREIGN KEY( SERVICE ) REFERENCES GDATA.CST2 ( SERVICE ) ON DELETE NO ACTION ON UPDATE NO ACTION ;
2/ Alimentation des données
Création des services
INSERT INTO GDATA/CST2 VALUES(‘COM’, ‘Comptabilité’) INSERT INTO GDATA/CST2 VALUES(‘PRO’, ‘Production ‘)
Création des employés
INSERT INTO GDATA/CST1 VALUES(01, ‘Berthoin’, ‘Pierre-Louis’, ‘COM’) INSERT INTO GDATA/CST1 VALUES(02, ‘Berthoin’, ‘Younes ‘, ‘PRO’)
Sur une insertion avec service inexistant, un message d’erreur est produit
INSERT INTO GDATA/CST1 VALUES(03, ‘Berthoin’, ‘Yasmine ‘, ‘CRP’)
ID message . . . . . . : SQL0530
Message . . . . : Opération non admise par la contrainte référentielle Q_GDATA_CST1_SERVICE_00001 de GDATA.
Sur une suppression de service avec des employés liés, un message d’erreur est produit
DELETE FROM GDATA/CST2 WHERE SERVICE = ‘PRO’
ID message . . . . . . : SQL0532
Message . . . . : Suppression impossible à cause de la contrainte référentielle Q_GDATA_CST1_SERVICE_00001 de GDATA.
Pas de service SQL mais un peu d’astuce et c’est ok
Il suffit de chercher les employés avec un service inexistant
CREATE TABLE QTEMP.ATTENTES AS (SELECT * FROM GDATA.CST1 A WHERE NOT EXISTS ( SELECT * FROM GDATA.CST2 B WHERE A.SERVICE = B.SERVICE AND B.SERVICE IS NOT NULL)) WITH DATA;
Remarque :
Vous pouvez passer cette commande avant de mettre en œuvre votre contrainte ! Vous pourrez ainsi mettre des relations dans votre application sans risque
Vous pouvez ensuite utiliser, un outil de modélisation :
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-10-14 14:55:212024-10-15 10:27:15Mettez des relations dans votre DB
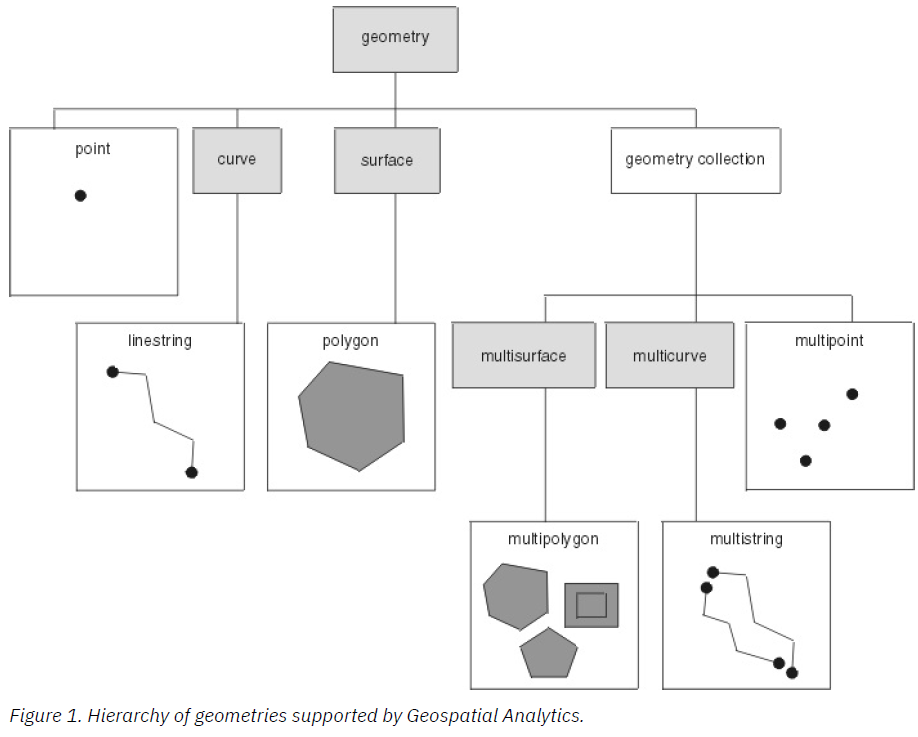
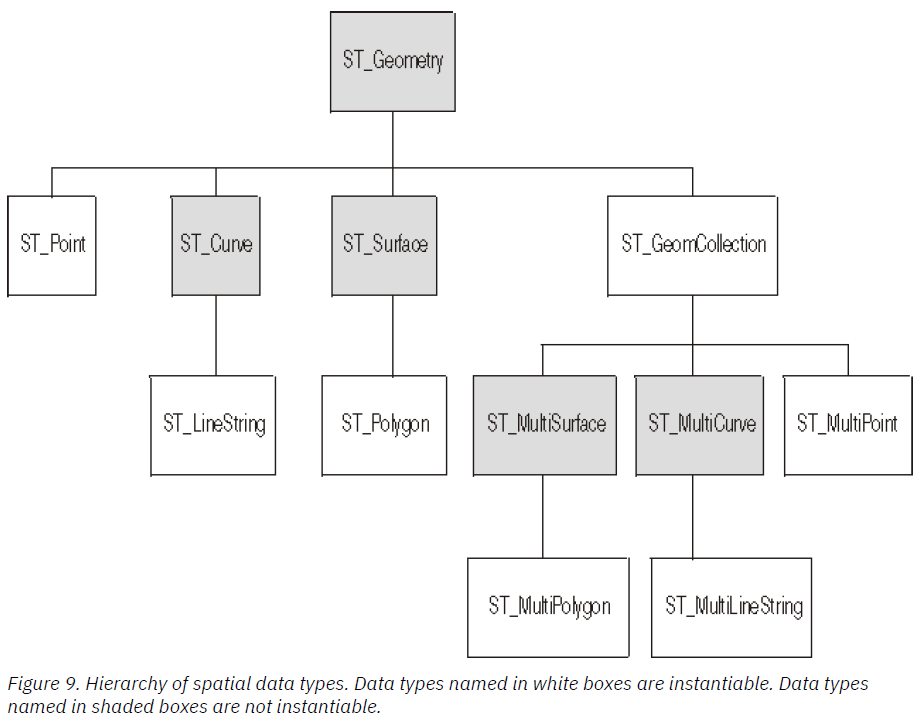
Concernant les fichiers JSON, on observe plusieurs types de géométries, principalement POLYGON et MULTIPOLYGON. C’est pourquoi il nous faut définir dans nos fichiers, une colonne qui puisse englober plusieurs types de géométries. Pour ce faire, le document Database Geospatial Analytics nous fournit quelques informations …
Nous choisirons donc, pour nos fichiers, une colonne basée sur la fonction ST_GEOMETRY, qui nous permet d’englober les deux type nommés ci-dessus. Voici donc comment nous constituerons nos tables.
-- Table des états américains
CREATE TABLE GGEOLOC.US_STATES (
STATE_ID CHAR(2) PRIMARY KEY,
STATE_FULL_NAME VARCHAR(50),
STATE_GEO QSYS2.ST_GEOMETRY);
-- Table des pays
CREATE TABLE GGEOLOC.COUNTRIES (
CODE_ISO VARCHAR(3) PRIMARY KEY,
NAME VARCHAR(50),
CNTRY_GEO QSYS2.ST_GEOMETRY);
-- Table des villes
CREATE TABLE GGEOLOC.MYCITIES (
CTY_NAME VARCHAR(50) ,
CTY_GEO QSYS2.ST_GEOMETRY);
Cet article étant dédié aux fonctions géospatiales, nous n’expliciterons pas la récupération des données.
Bienvenue à bord
ST_ISSIMPLE & ST_GEOMETRYTYPE …
… attachez vos ceintures
ST_ISSIMPLE nous permet de savoir si la géométrie de la figure sélectionnée est simple (valeur 1) ou bon (valeur 0).
SELECT STATE_FULL_NAME,
CASE QSYS2.ST_ISSIMPLE(STATE_GEO)
WHEN 0 THEN 'Geometry is not simple'
WHEN 1 THEN 'Geometry is simple'
END
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
Geometry is not simple
Hawaii
Geometry is simple
Illinois
Geometry is simple
Indiana
Geometry is simple
Wisconsin
Geometry is simple
ST_GEOMETRYTYPE nous permet de savoir de quel type de géométrie nous parlons, et nous pouvons donc constater que la simplicité de la géométrie n’a pas de lien avec le caractère « MULTI » de la figure.
SELECT STATE_FULL_NAME, QSYS2.ST_GEOMETRYTYPE(STATE_GEO)
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
ST_MULTIPOLYGON
Hawaii
ST_MULTIPOLYGON
Illinois
ST_POLYGON
Indiana
ST_POLYGON
Wisconsin
ST_POLYGON
ST_ASTEXT & ST_ASBINARY …
… briefing avant décollage
Si nous exécutons une extraction brute de nos données, on ne comprend pas immédiatement
select STATE_ID, STATE_FULL_NAME, STATE_GEO
from GGEOLOC.US_STATES where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'CO');
ST_AREA nous donne la surface en m² d’une aire géographique (POLYGON ou MULTIPOLYGON)
on ajoute une colonne ici pour avoir une idée de l’aire en km²
select STATE_ID, STATE_FULL_NAME, QSYS2.ST_AREA(STATE_GEO), integer(QSYS2.ST_AREA(STATE_GEO)/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'HI');
AL
Alabama
1.3409800288446873E11
134098
AR
Arkansas
1.3838751120399905E11
138387
HI
Hawaii
1.4748657954505682E10
14748
OK
Oklahoma
1.8250255202012402E11
182502
TX
Texas
6.886199875225208E11
688619
ST_BUFFER nous donne les coordonnées d’une surface élargie du nombre de mètres voulus
voici un exemple de calcul de surfaces en élargissant de 1000 m les frontières de deux états
select STATE_ID, STATE_FULL_NAME, integer(QSYS2.ST_AREA(STATE_GEO)/1000000), integer(QSYS2.ST_AREA(QSYS2.ST_BUFFER(STATE_GEO, 1000))/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'AL');
AL
Alabama
134098
135822
OK
Oklahoma
182502
184806
ST_DISJOINT & ST_WITHIN …
… garder le cap
ST_DISJOINT retourne 1 si deux figures n’ont rien en commun.
select CTY_NAME, CODE_ISO
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where QSYS2.ST_DISJOINT(CTY_GEO, CNTRY_GEO) = 0 ;
HELSINKI
FIN
TEGUCIGALPA
HND
NAIROBI
KEN
GUADALAJARA
MEX
COPENHAGEN
DNK
LYON
FRA
NANTES
FRA
OSLO
NOR
ROCHESTER
USA
ST_WITHIN retourne 1 si la première figure est complètement dans la seconde.
Exemple : Une ville est-elle contenue dans un pays ? Un pays est-il contenu dans une ville ?
select CTY_NAME, CODE_ISO, QSYS2.ST_WITHIN(CTY_GEO, CNTRY_GEO), QSYS2.ST_WITHIN(CNTRY_GEO, CTY_GEO)
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where CTY_NAME in ('LYON', 'ROCHESTER') and CODE_ISO in ('FRA', 'USA') ;
LYON
FRA
1
0
ROCHESTER
FRA
0
0
LYON
USA
0
0
ROCHESTER
USA
1
0
ST_INTERSECTS & ST_INTERSECTION …
… passer la frontière
ST_INTERSECTS nous permet de savoir si deux figures ont une intersection (la fonction retourne 1 si tel est le cas)
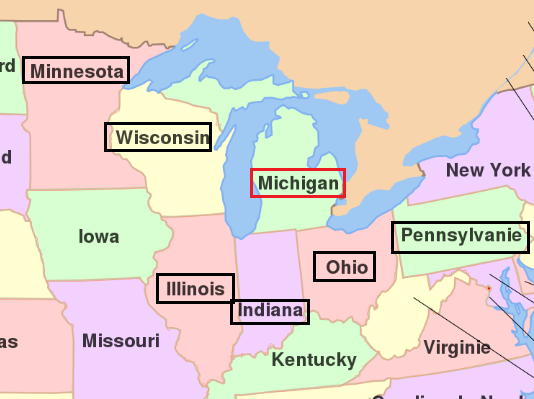
Dans l’exemple suivant, on cherche parmi une liste d’états, à savoir si ceux-ci sont directement voisins du Michigan
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN') ;
Michigan
Illinois
Etats éloignés
Michigan
Indiana
Etats Voisins
Michigan
Minnesota
Etats éloignés
Michigan
Ohio
Etats Voisins
Michigan
Pennsylvania
Etats éloignés
Michigan
Wisconsin
Etats Voisins
Il suffisait de voir la carte pour s’en rendre compte !! Heureusement, ST_INTERSECTION nous en dit beaucoup plus puisqu’elle nous indique la forme de l’intersection entre deux figures géométriques.
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_ASTEXT(QSYS2.ST_INTERSECTION(t1.STATE_GEO, t2.STATE_GEO)),
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
ST_DISTANCE va retourner la distance entre deux points, mais il est intéressant de l’utiliser sur des figures de type POLYGON …
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_DISTANCE(t1.STATE_GEO, t2.STATE_GEO)/1000
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
Michigan
Illinois
58.493941547601004
Michigan
Indiana
0.0
Michigan
Minnesota
33.60195301382611
Michigan
Ohio
0.0
Michigan
Pennsylvania
179.1488383130458
Michigan
Wisconsin
0.0
… pour lesquelles on se rend compte que la fonction retourne la distance (ramenées en km ici) entre les points les plus proches des deux figures comparées.
Atterrissage
Nous n’avons exploré ici qu’une partie des fonctions géospatiales disponibles. Il en existe bien d’autres fonctions pour savoir si une figure recouvre complètement une autre, si une figure est contenue dans une autre si une figure en traverse une autre, … Il existe également des fonctions de manipulation des GEOHASHES (système de géocodage basé sur la division d’une zone géographique en cellules).
Bref, tout une panoplie de fonctions que l’on peut combiner à l’infini et au-delà !
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2024-10-09 18:03:122025-03-13 17:38:35LE TOUR DU MONDE EN 10 (+1) FONCTIONS GEOSPATIALES
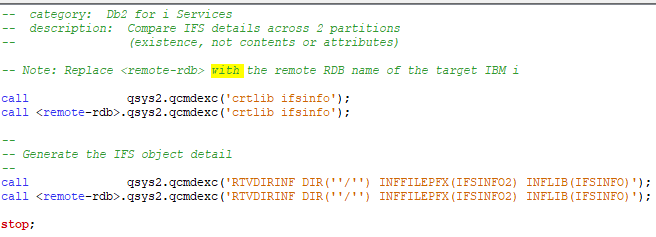
Vous indiquer le nom de votre base de données distantes et vous exécuter votre requête sur le système distant.
derrière cette requête ce cache un protocole nommé DRDA , comme ODBC il permet de ce connecté à une base de donnée distante.
Nous allons voir comment le mettre en œuvre .
sur le système source Vous devez créer une entrée pour la base de données
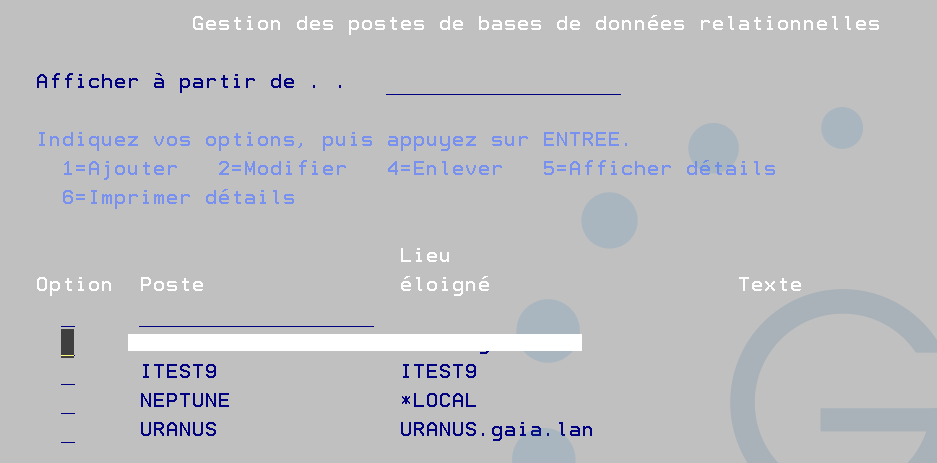
le plus simple c’est de passer par la commande WRBRDBDIRE , vous ajouterez une connexion IP à votre système distant.
Sur le système cible Vous devez paramétrer le service par la commande CHGDDMTCPA , il faut avoir le même mode d’authentification que la base de données distante, par défaut user + mot de passe vous devez démarrer le service STRTCPSVR *DDM
voila c’est tout vous pouvez à partir de votre système source faire un connect SQL sur votre système cible si vous avez un mot de passe.
Si vous ne voulez pas renseigner de mot de passe comme dans les exemples ACS vous allez devoir utiliser sur votre système source les postes poste d’authentification serveur. Pour les ajouter vous avez la commande ADDSVRAUTE, vous devrez également avoir mis la valeur système QRETSVRSEC à ‘1’ pour que vos mots de passe soit enregistrés
il est conseillé d’ajouter un poste générique, par exemple QDDMDRDASERVER en indiquant un user et un mot de passe du système cible !
il n’y a pas de commande WRKSRVAUTE mais vous pouvez en trouver une ici https://github.com/Plberthoin/PLB/tree/master/GTOOLS/
Exemple :
A partir de ce moment la mot de passe sera passé directement.
Vous pouvez facilement, par des services sql comparer 2 partitions (valeurs systèmes, fonctions , etc …)
Remarques
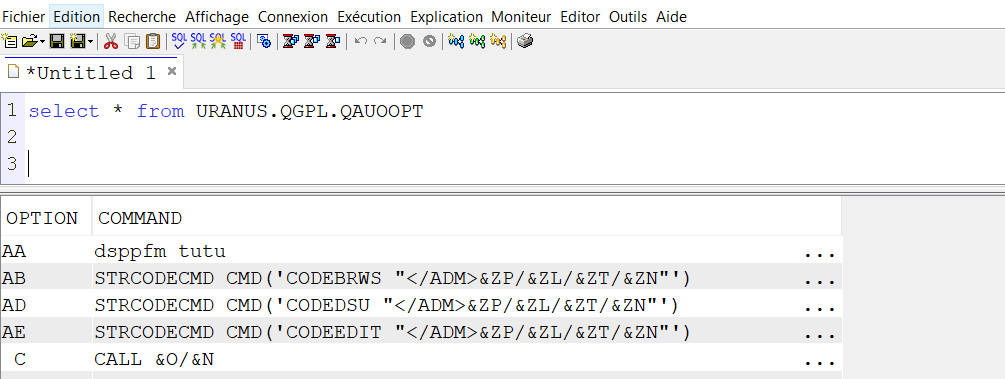
Les noms doivent être en majuscule il est conseillé de mettre un programme d’exit de contrôle Attention, vous pouvez vous connecter avec un utilisateur *disabled Les fichier DDM sur IP s’appuient sur cette technologie
Vous voulez nommer votre groupe d’activation pour toute une application donc sans indiquer d’option dans le source qui seraient prioritaires par rapport à votre commande de compile
On va parler ici des BIND c’est l’opération que fait une commande pour compiler le module et l’assembler pour en faire un programme
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-29 09:05:152024-08-29 09:05:16Nommer un groupe d’activation pour des programmes RPGLE
Vous voulez connaitre la bibliothèque d’un programme en cours d’exécution, pour ajouter cette bibliothèque par exemple, pour contextualiser un exit programme, un watcher, un trigger ou pour limiter un environnement prod, versus dev. Le tout, sans harcoder une bibliothèque qui figera votre code et vos environnements.
Voici 2 exemples
En RPGLE
dcl-ds *N PSDS ;
bibli_du_pgm CHAR(10) POS(81);
nom_du_pgm CHAR(10) POS(1);
End-ds ;
dcl-s present ind ;
// on tente d'ajouter la bibliothèque
exec sql
call qcmdexc('Addlible ' concat :bibli_du_pgm concat ' *FIRST') ;
if sqlcode = 0 ;
present = *on ;
endif ;
// votre traitement ici
// on enlève si on a ajouté
if present = *on ;
exec sql
call qcmdexc('Rmvlible ' concat :bibli_du_pgm ) ;
endif ;
En CLLE
PGM
DCL VAR(&DATA) TYPE(*CHAR) LEN(80)
DCL VAR(&LIB) TYPE(*CHAR) LEN(10)
DCL VAR(&PGM) TYPE(*CHAR) LEN(10)
DCL VAR(&TEMOIN) TYPE(*LGL)
/* Paramétrage de l'appel */
CHGVAR VAR(%BIN(&DATA 1 4)) VALUE(80)
CHGVAR VAR(%BIN(&DATA 5 4)) VALUE(80)
CHGVAR VAR(%BIN(&DATA 9 4)) VALUE( 0)
CHGVAR VAR(%BIN(&DATA 13 4)) VALUE( 0)
/* Appel de la procédure */
CALLPRC PRC('_MATPGMNM') PARM(&DATA)
/* Extraction des informations */
chgvar &pgm %SST(&DATA 51 10)
chgvar &lib %SST(&DATA 19 10)
/* ajout de la bibliothèque */
ADDLIBLE &LIB *FIRST
monmsg cpf2103 exec(do)
chgvar &temoin '1'
enddo
/* Votre traitement ici */
/* on enlève si on a ajouté */
if cond(*not &temoin) then(do)
RMVLIBLE &LIB
enddo
ENDPGM
Remarque :
On a mis également le programme en cours dans les exemples
On a mis le code pour enlever la bibliothèque après le traitement, uniquement si c’est notre programme qui l’a ajouté.
En RPGLE si vous avez un fichier vous devrez déclarer votre fichier en USROPN et ouvrir le fichier par un OPEN, après avoir ajouté la bibliothèque
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-17 09:22:572024-08-20 10:47:56Connaitre la bibliothèque du programme en cours
Que se passe-t-il si on définit soi-même une zone IDENTITY lors de la mise à jour d’une table ?
Ce n’est évidemment pas la meilleure des idées qu’on puisse avoir, mais parfois dans l’urgence d’une correction de données …
Commençons par créer une table de tests avec une zone identité de type bigint :
CREATE TABLE NK.IDENT
(
ID BIGINT GENERATED BY DEFAULT AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER),
NOM_SQL_ZONE_CHAR FOR COLUMN ZONECHAR CHAR(20) NOT NULL DEFAULT '',
CONSTRAINT IDENT_PK PRIMARY KEY( ID)
)
RCDFMT RIDENT ;
RENAME TABLE NK.IDENT TO TESTS_IDENTITY
FOR SYSTEM NAME IDENT;
Les zones qui nous intéressent dans la vue syscolumns de QSYS2 ressemblent à ça :
select column_name,
is_identity,
identity_generation,
identity_minimum,
identity_maximum
from qsys2.syscolumns
where system_table_name ='IDENT'
and system_table_schema ='NK'
order by ordinal_position;
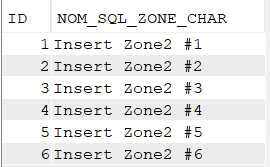
Alimentation de la table avec quelques enregistrements
insert into nk.ident (Zonechar) values ('Insert Zone2 #1');
insert into nk.ident (Zonechar) values ('Insert Zone2 #2');
insert into nk.ident (Zonechar) values ('Insert Zone2 #3');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #4');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #5');
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #6');
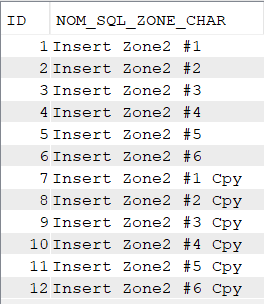
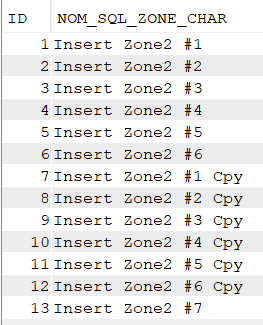
On peut ignorer ID ou le renseigner en DEFAULT, la table est alimentée :
select * from nk.ident;
Que se passe-t-il si je définis moi-même ID lors d’un insert ?
Si l’identity est déjà occupée par un enregistrement : SQL n’accepte pas l’instruction, il fait ce qu’on lui a demandé !
insert into nk.ident (ID, Zonechar) values (1, 'Insert KO');
Si je fais des insertions de données dans IDENT en définissant moi-même des ID libres :
insert into nk.ident
select id+6, trim(zonechar) || ' Cpy' from nk.ident;
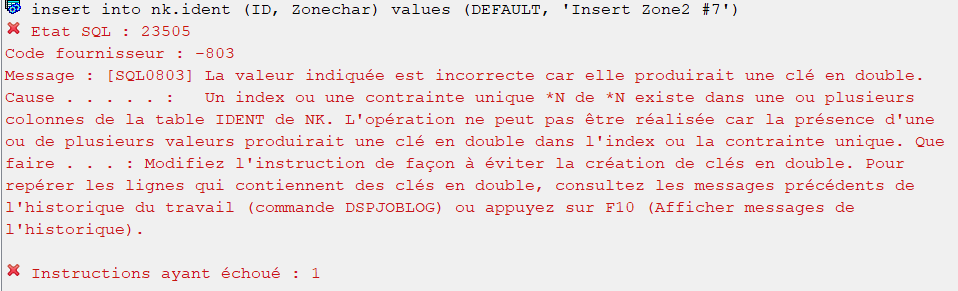
Mais si je refais une insertion de données en laissant à nouveau SQL gérer l’identity :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
On consulte la log du travail comme le message d’erreur nous invite :
select message_second_level_text
from table(qsys2.joblog_info('111778/QUSER/QZDASOINIT'))
where message_id = 'CPF5009';
Deux enregistrements sont trouvés :
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti.Le membre numéro 1 (enregistrement numéro 1, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti. Le membre numéro 1 (enregistrement numéro 7, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
Le premier message est relatif à la tentative d’insertion « insert into nk.ident (ID, Zonechar) values (1, ‘Insert KO’); » tentée plus haut et pour laquelle l’erreur était attendue.
Le second message est relatif à «insert into nk.ident (ID, Zonechar) values (DEFAULT, ‘Insert Zone2 #7’); »
SQL a tenté d’utiliser la valeur suivante de la dernière identity qu’il a lui-même géré, mais a échoué car la valeur IDENT.ID=7 existe déjà.
Si on retente l’insertion qui vient juste d’échouer :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
Elle échoue de la même façon, sauf que cette fois SQL a tenté d’utiliser l’ID = 8 :
&N Cause . . . . . : L’opération d’écriture ou de mise à jour dans le membre numéro 1 (enregistrement numéro 0, format RIDENT) pour le membre IDENT du fichier IDENT, se trouvant dans NK, n’a pas abouti. Le membre numéro 1 (enregistrement numéro 8, format RIDENT) a la même clé d’enregistrement que le membre numéro 1 (enregistrement numéro 0, format RIDENT). Si ce numéro d’enregistrement est 0, la clé d’enregistrement en double a été créée lors d’une opération d’écriture.
&N Que faire . . . : Modifiez les clés en double, de sorte que chaque enregistrement ait une clé unique. Renouvelez la demande.
Comment corriger la situation ?
La solution pour se sortir de là si on a fait 3000 insertions ne va pas être de tenter 3000 insertions bidons pour que la table ait son compteur interne gérant l’identity à jour (d’ailleurs, si quelqu’un sait où il se cache je suis preneur).
On récupère la dernière ID utilisée dans la table :
select max(ID) from nk.ident ;
Et on ajoute 1 pour mettre à jour la table :
alter table nk.ident
alter column id restart with 13;
L’instruction précédente :
insert into nk.ident (ID, Zonechar) values (DEFAULT, 'Insert Zone2 #7');
se passe bien maintenant et la numérotation de IDENT.ID a bien repris normalement :
select * from nk.ident;
Pour se prémunir de tout ceci, il suffit de vérifier la nature de la clé primaire d’une table avant de commencer à y insérer des enregistrements.
Sur DB2 l’usage d’IDENTITY dans une table SQL n’est pas très répandu, il est donc nécessaire de comprendre la structure d’une table avant de l’utiliser. L’IDENTITY se révèle alors pratique tant qu’on laisse le système la gérer. On peut bien sûr, dans des cas exceptionnels, la gérer soi-même si on fait attention…
/wp-content/uploads/2017/05/logogaia.png00Nicolas kintz/wp-content/uploads/2017/05/logogaia.pngNicolas kintz2024-08-13 09:51:272024-08-13 09:51:28Gestion de l’IDENTITY d’une table
Analyse par les fichiers supports ( c’est des fichiers modèles qui sont dans QSYS ) CRTDUPOBJ OBJ(QAWCTPJE) FROMLIB(QSYS) OBJTYPE(*FILE) TOLIB(Votrebib) NEWOBJ(QPFRADJTP)
pour analyser le suivi ici du pour des travaux interactifs
SELECT TPPNAM, TPFLG1, TPCSIZ, TPCRES, TPCACT, TPDFLT, TPNFLT, TPWI, TPAW, TPCJOB, TPAJOB, TPNSIZ, TPNACT FROM Votrebib/QPFRADJTP WHERE TPPNAM = ‘*INTERACT’ order by TPDATE, TPTIME
Deuxième exemple, voir les ports filtrés sur votre partition
Analyse par services SQL
create table votrebib.analyse as( WITH Log_Port AS ( SELECT CAST(ENTRY_DATA AS VARCHAR(1000)) AS entry FROM TABLE ( QSYS2.DISPLAY_JOURNAL(‘QUSRSYS’, ‘QIPFILTER’, JOURNAL_ENTRY_TYPES => ‘TF’) ) ) SELECT SUBSTR(entry, 1, 10) AS line, SUBSTR(entry, 29, 15) AS AdrSrcIp, SUBSTR(entry, 44, 5) AS SrcPort, SUBSTR(entry, 49, 15) AS AdrDestIp, SUBSTR(entry, 64, 5) AS DestPort FROM Log_Port ) WITH DATA;
Remarques
Certains journaux sont en standard , d’autres devront être démarrés Si vous n’analysez pas ne les démarrer pas Pensez à faire le ménage dans les récepteurs si vous les démarrez
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-08-02 09:13:592024-08-14 15:49:25Utilisez les journaux Système
Vous voulez créer un trigger qui vous indique la création d’un enregistrement dans un fichier par exemple pour superviser, dans notre exemple on enverra un email , il est conseillé de faire un fichier de paramétrage
En SQL ca créera un programme CEE et ca l’associera au trigger
CREATE OR REPLACE TRIGGER ALERTE_MSG
AFTER INSERT ON REP_VALID
REFERENCING NEW AS N
FOR EACH ROW
MODE DB2ROW
-- email destinataire
BEGIN
DECLARE W_EMAIL CHAR(50);
DECLARE W_SUJET CHAR(100);
DECLARE W_NOTES CHAR(200);
DECLARE EXIT HANDLER FOR SQLSTATE '38501'
RESIGNAL SQLSTATE '38501' SET MESSAGE_TEXT = 'ENVOI MAIL IMPOSSIBLE.';
SET W_NOTES = 'Job : ' concat trim(N.REPNBR)
concat '/' concat trim(N.REPUSER) concat '/' concat trim(N.REPJOB) ;
SET W_EMAIL = 'votre@email.fr' ;
SET W_SUJET = 'Enregistrement crée' ;
CALL QCMDEXC('SNDSMTPEMM RCP((''' concat trim(w_email) concat
''')) SUBJECT(''' concat trim(replace(w_sujet , '''', '"'))
concat ''') NOTE('''
concat trim(replace(W_NOTES , '''' , '"')) concat''') CONTENT(*HTML)') ;
END;
Remarques :
Dans les 2 cas si l’utilisateur n’est pas inscrit à la liste de distribution votre email ne sera pas envoyé c’est plus simple de gérer l’erreur en CLP. Si vous devez accéder aux données du buffer ca sera plus rapide et plus simple en SQL ici n.zone
C’est des triggers après , puisque l’information doit être écrite dans tous les cas .
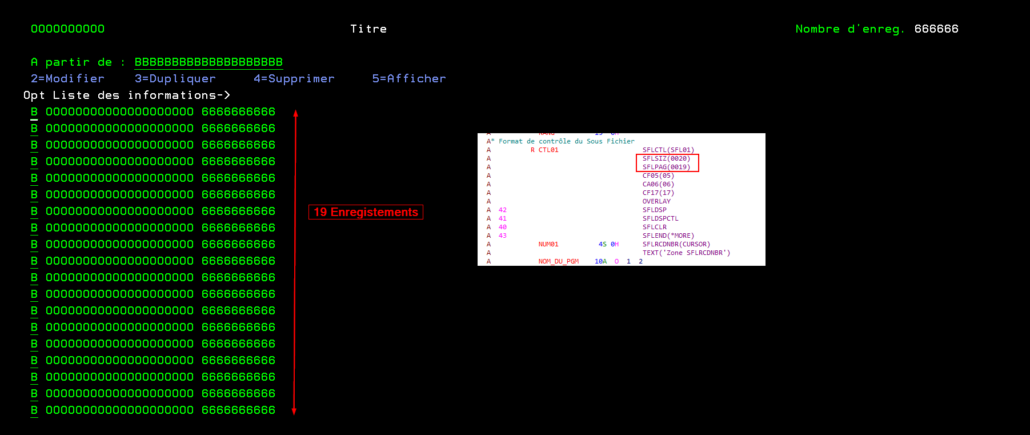
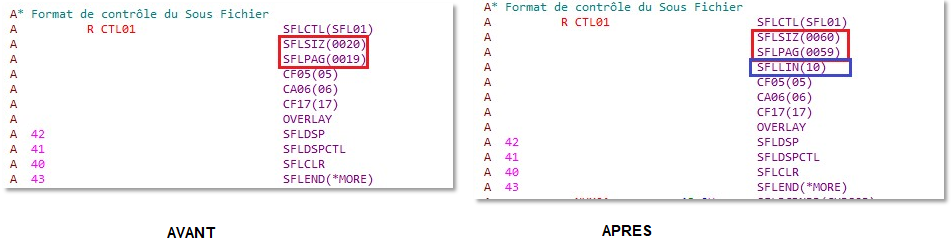
Un sous-fichier nous permet d’afficher un nombre de lignes qui est limité par la taille de l’écran. Cette taille est définie dans le script source de l’écran par le paramètre SFLPAG.
On possède un fichier que l’on souhaite afficher et qui contient plus de 19 enregistrement. Il serait donc intéressant de l’afficher sur plusieurs colonnes.
Solution
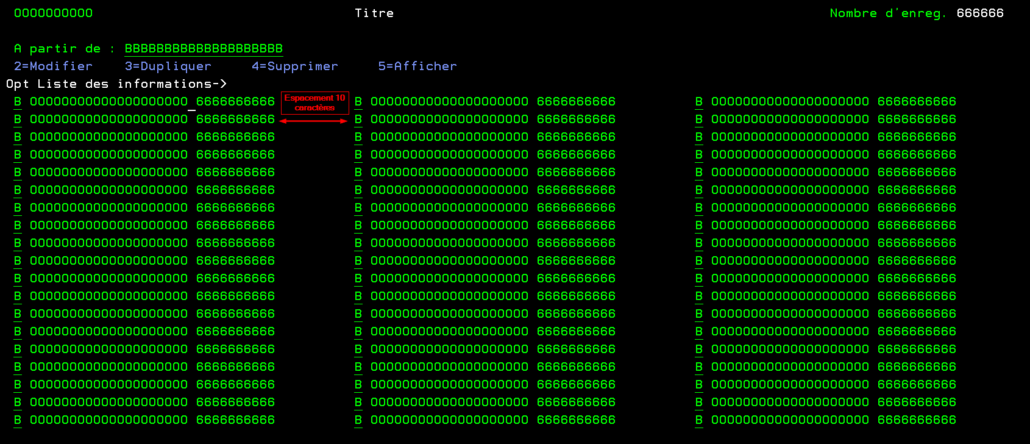
Une petite modification du script source permet de créer un sous fichier qui contient plusieurs colonnes. Il faut donc indiquer le nombre total de données que l’on souhaite voir à l’écran dans SFLPAG ainsi que le nombre de caractère qui séparent deux colonnes
La maquette se présente ainsi, le paramètre de SFLLIN correspond à l’espace (en caractères) entre deux colonnes.
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2024-07-16 09:38:142024-07-16 09:48:33Afficher plusieurs colonnes d’enregistrements dans un sous-fichier