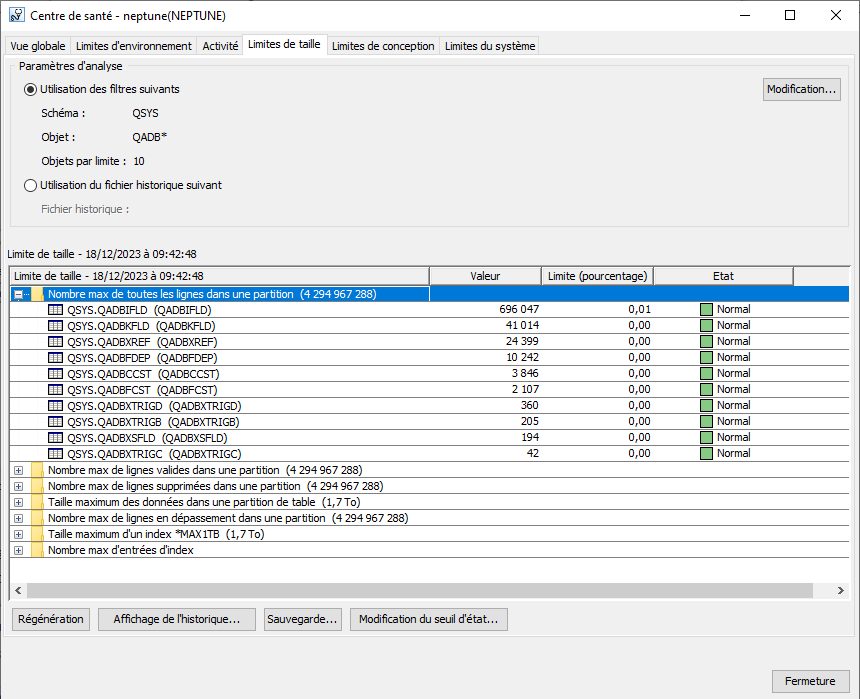
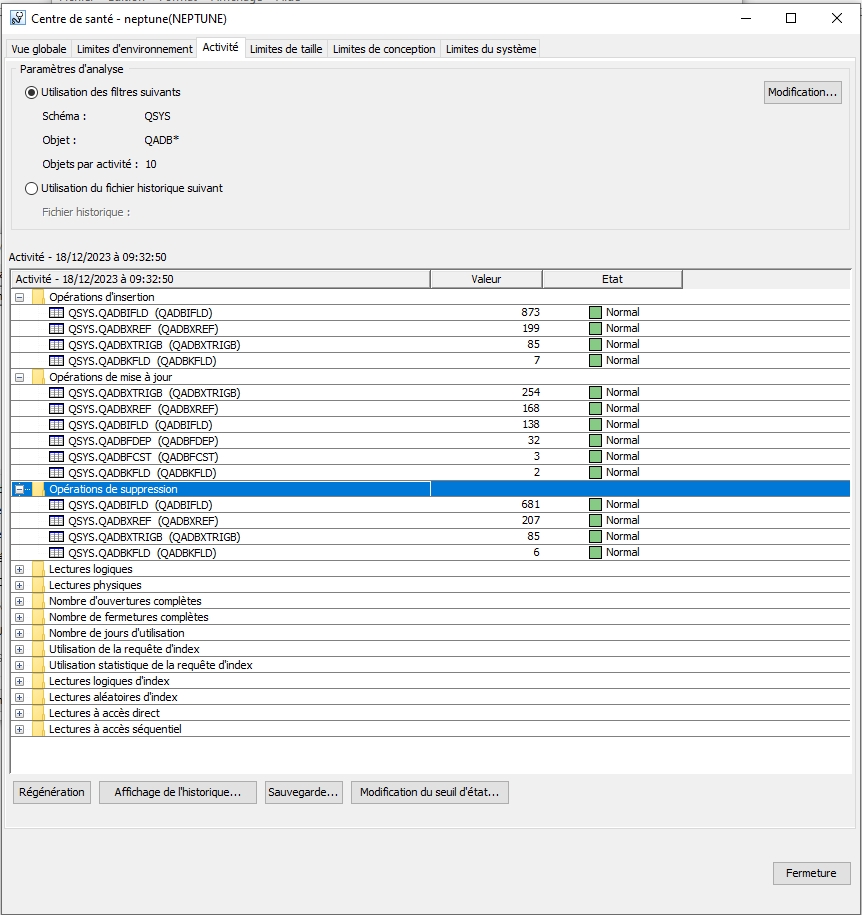
Vous trouvez que la recherche de fichier dans l’IFS par les services SQL n’est pas assez performante ;
Par exemple vous gérez des archives PDF sur l’IFS (toujours penser à épurer régulièrement).
Vous avez un logiciel gratuit qui s’appelle Omnifind, celui-ci permet de gérer des index textes sur l’IFS
mais aussi sur les spools si vous le désirez.
Notre besoin était sur l’IFS nous allons donc étudier ce cas au cours de cet article.
Nous avons déjà posté un autre article sur la mise en œuvre de Omnifind
Vous pouvez en savoir plus ici
https://www.ibm.com/support/pages/omnifind-ibm-i
Une fois que vous avez mis en place Omnifind et créé l’index qui va bien.
Vous retrouvez des procédures dans la collection que vous avez créée, chez nous elle s’appelle OMNIFIND.
Dans ces procédures vous en avez une qui s’appelle SEARCH qui va scanner dans vos fichiers
ceux qui contiennent une chaine de caractères.
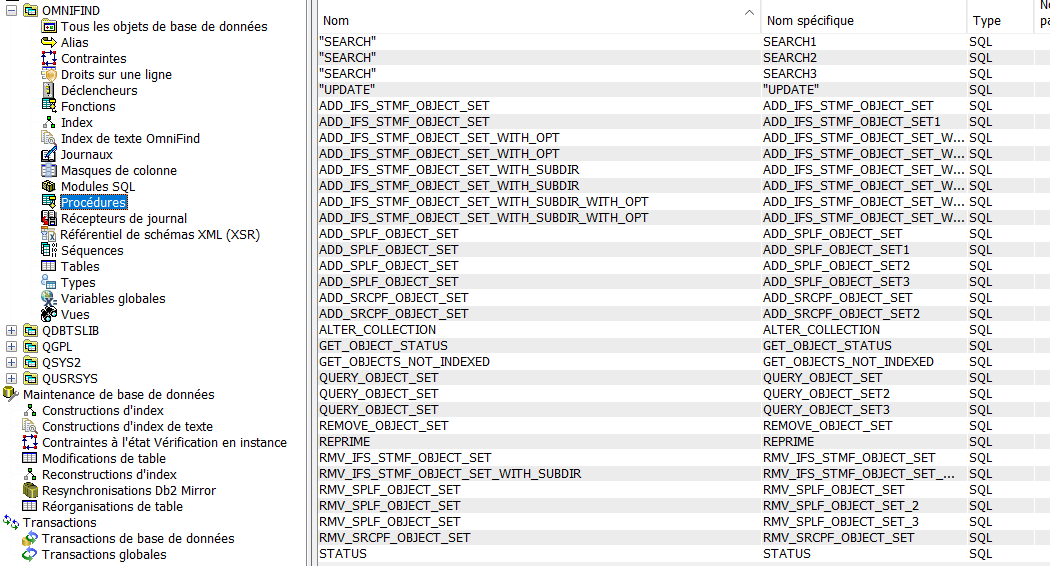
Cette procédure renvoie un resultset ; Ce qui explique qu’en retour dans une interface ACS vous avez une liste et dans
un STRSQL juste un message de fin.
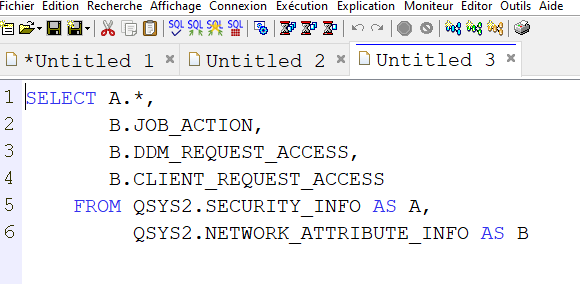
La problématique est donc de savoir comment traiter un resultset dans un programme avec, en plus, un résultat renvoyé dans un CLOB au format XML
Nous avons choisi de faire cet exercice en RPGLE.
Je vous joins un exemple ici, vous pouvez l’améliorer par exemple pour le parsage XML, ou la gestion des variables :
**free
//
// Options de compile
//
ctl-opt
DFTACTGRP(*NO) ;
//
// Paramètre chaine à scanner
//
Dcl-Pi *N;
p_texte char(30) ;
End-Pi;
//
// Initialisation des options de compile SQL
//
EXEC SQL
Set Option
Naming = *SQL,
Commit = *None,
UsrPrf = *User,
DynUsrPrf = *User,
Datfmt = *iso,
CloSqlCsr = *EndMod;
// Zone du result set pour la procedure SEARCH
dcl-s objtype char(10) ;
dcl-s objattr char(10) ;
dcl-s objlib char(10) ; // peut être nul int1
dcl-s objname char(10) ; // peut être nul int2
dcl-s objinfo SQLTYPE(CLOB:65531) ;
dcl-s objmod TIMESTAMP ;
dcl-s objtime int(5) ;
// Déclaration de l'adresse du result set
dcl-s RS1 SQLTYPE(RESULT_SET_LOCATOR) ;
// pour les variables à valeurs nulles
dcl-s Ind1 int(5) ;
dcl-s Ind2 int(5) ;
// Variables de travail
Dcl-S w_objinfo Varchar(65531);
//
// Contrôle des paramètres
//
if %parms = 0 ;
dsply ('Vous devez saisir une recherche') ;
return ;
*inlr = *on ;
endif;
// Appel de la procédure ici de la collection OMNIFIND
// la procédure est dans la collection qui contient l'index TXT
exec sql
Call OMNIFIND.SEARCH(:p_texte);
// Si result set créé
if SQLCODE = +466;
// Vous associez le resultset de la procédure à votre curseur
exec sql ASSOCIATE LOCATORS (:RS1) WITH PROCEDURE OMNIFIND.SEARCH ;
exec sql ALLOCATE C1 CURSOR FOR RESULT SET :RS1;
// boucle de traitement du curseur associé
exec sql fetch c1 into :objtype ,
:objattr ,
:objlib:ind1 ,
:objname:ind2 ,
:objinfo ,
:objmod ,
:objtime ;
// ici traitement du fichier
// récupération des données du CLOB
Traitement() ;
dow sqlcode = 0;
// traitement des variables lues...
exec sql fetch c1 into :objtype ,
:objattr ,
:objlib:ind1,
:objname:ind2,
:objinfo ,
:objmod ,
:objtime ;
// récupération des données du CLOB
Traitement() ;
// ici traitement du fichier
//
ENDDO;
exec sql close C1;
ENDIF;
*inlr = *on;
//
// Procédure de traitement
//
dcl-proc Traitement ;
dcl-s w_file char(256);
dcl-s pos1 int(5) ;
dcl-s pos2 int(5) ;
// dcl-s w_text char(50);
w_objinfo = %subst(objinfo_data : 1 : objinfo_len) ;
// traiter XML ca serait mieux
// recherche <file_path>
pos1 = %scan('<file_path>' : w_objinfo ) ;
// recherche </file_path>
pos2 = %scan('</file_path>' : w_objinfo ) ;
w_file = %subst(w_objinfo : (pos1 + 11) : (pos2 - (pos1 + 11))) ;
//
// Traitement du fichier w_file
//
//w_text = %subst(w_file : 1 : 50) ;
//dsply w_text ;
end-proc ;
Les points importants à comprendre :
C’est la déclaration et l’utilisation d’un curseur basé sur un resultset – j’ai mis un commentaire dans le source.
Et la manipulation d’une variable CLOB.
Voila les points principaux à retenir :
Quand vous déclarez une dans votre programme RPGLE votre variable CLOB,
DCL-S XXX SQLTYPE(CLOB:nnnn);
En réalité, après traduction c’est déclaré comme ça :
DCL-DS XXX;
XXX_LEN UNS(10);
XXX_DATA CHAR(nnnn) CCSID(*JOBRUNMIX);
END-DS XXX;
nnnn étant la longueur de la zone
XXX_LEN contient la longueur du contenu de la zone
XXX_DATA contient la donnée
Dans la partie traitement vous pouvez facilement faire un QCMDEXC en SQL, par exemple pour faire une copie, un envoi ou une suppression
Voila un exemple concret que vous pouvez adapter, n’hésitez pas à tester Omnifind car il est gratuit et comme on met de plus en plus de chose dans l’IFS, il est de plus en plus utile !