Vous désirez connaitre la taille occupée par les MTI (Maintained Temporary Index) sur votre machine, voici une Méthode. Vous avez des buckets (espaces dans votre mémoire centrale) sur votre partition.
Vous avez un service QSYS2.SYSTMPSTG qui permet de voir ces buckets
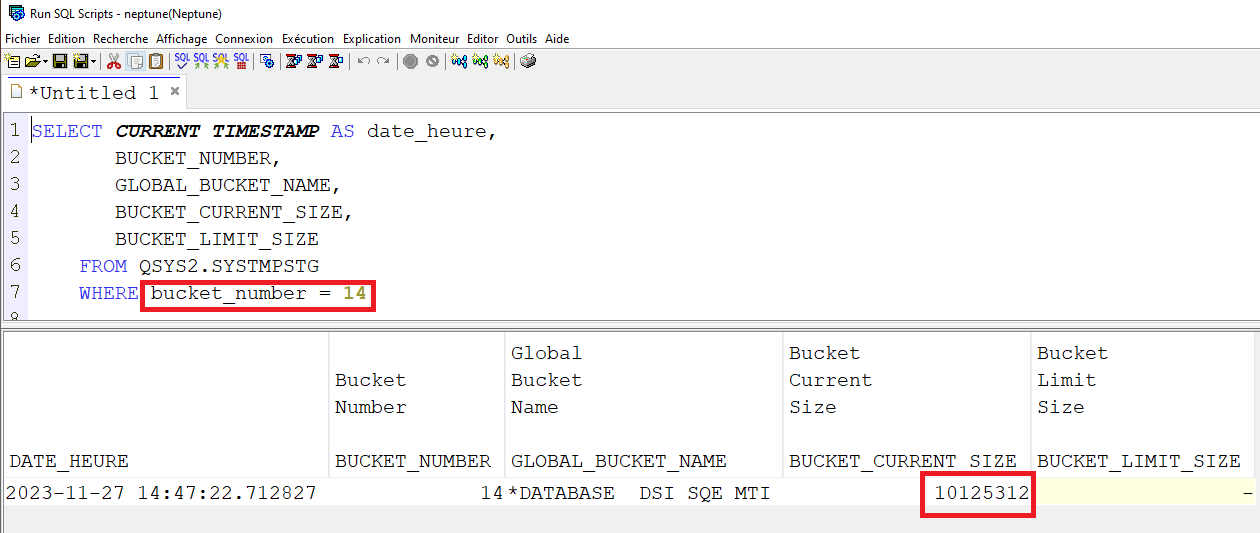
La taille des MTI, c’est le bucket 14
Voici la requête pour voir cette taille
SQL SELECT CURRENT TIMESTAMP AS date_heure, BUCKET_NUMBER, GLOBAL_BUCKET_NAME, BUCKET_CURRENT_SIZE, BUCKET_LIMIT_SIZE FROM QSYS2.SYSTMPSTG WHERE bucket_number = 14
Pour diminuer cette taille il faut créer les index qu’Index advisor vous suggère.
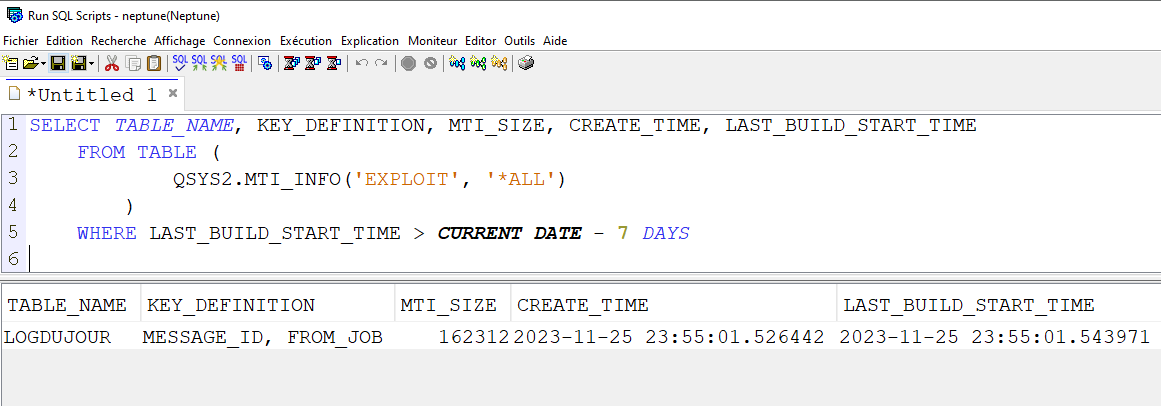
Vous avez une fonction table qui vous indique les MTIs de votre système, QSYS2.MTI_INFO
Ceux qui concernent votre base de données doivent être construits
Ici ceux utilisés depuis une semaine sur la bibliothèque exploit !
SELECT * FROM TABLE ( QSYS2.MTI_INFO(‘EXPLOIT’, ‘*ALL’) ) WHERE LAST_BUILD_START_TIME > CURRENT DATE – 7 DAYS
Remarque :
Cet espace sera réutilisé par les autres Buckets
Vous pouvez faire un suivi de ces buckets , par exemple ceux de la base de données pour voir les grandes variations
La mise à jour du fichier d’index Advisor dépendra de la méthode utilisée pour générer l’index, n’hésitez pas à effacer des enregistrements dans le fichier QSYS2.SYSIXADV.
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-11-27 17:15:012023-11-28 09:55:34Connaitre la taille vos MTI
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-11-19 20:07:162023-11-19 20:07:17Générer un XLS avec SQL
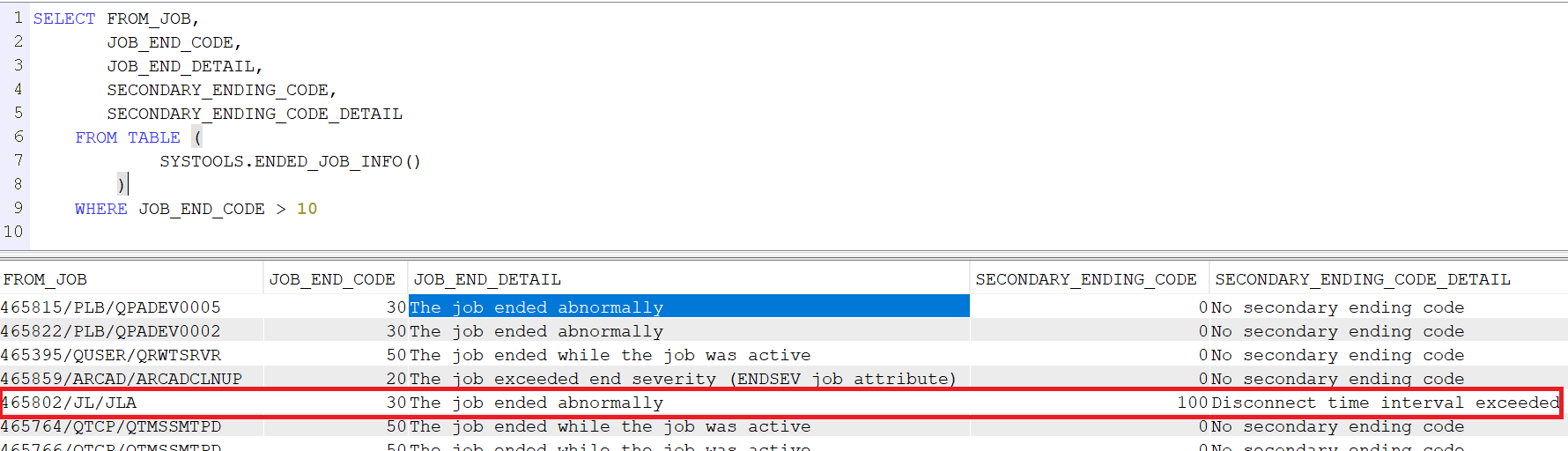
La TR3 de la V7R5, nous apporte une nouvelle fonction table qui va nous permettre d’analyser plus finement et surtout plus simplement la fin d’un travail, soit en réalité le message CPF1164, en effet on a accès directement au code secondaire .
Exemple :
SELECT FROM_JOB, JOB_END_CODE, JOB_END_DETAIL, SECONDARY_ENDING_CODE, SECONDARY_ENDING_CODE_DETAIL FROM TABLE ( SYSTOOLS.ENDED_JOB_INFO() ) WHERE JOB_END_CODE > 10
Remarque :
Par défaut il analyse la veille soit (current date – 1)
Depuis la V7R1 (SF99701 – DB2 – niveau 23), on peut invoquer des web service via SQL. Les fonctions se trouvent dans SYSTOOLS.
En V7R4 TR5, sont sorties de nouvelles fonctions, elles se trouvent dans QSYS2.
Outre les fonctions HTTP, celles pour encoder / décoder en base64 et pour encoder / décoder L’URL, ont aussi été implémentées dans QSYS2.
Rappel des différences entre ces fonctions
Tout d’abord les performances. Les fonctions de QSYS2 permettent un gain non négligeable, elles sont basé sur les fonctions AXIS en C natif, contrairement à celles de SYSTOOLS qui sont basées sur des classes java.
Les paramètres dans l’entête ou le corps du message sont transmis en JSON pour les fonctions de QSYS2, à la place de XML pour celle de SYSTOOLS.
La gestion des certificats est simplifiée par l’utilisation de DCM, alors qu’avec les fonctions de SYSTOOLS, il fallait pousser le certificat dans le magasin du runtime java utilisé par les fonctions HTTP. En cas de multiple versions de java installées, il fallait s’assurer de laquelle servait pour les fonctions HTTP. L’ajout du certificat, se faisait via des commandes shell.
Les types et tailles des paramètres des fonctions ont été adaptés pour ne plus être des facteurs limitants de l’utilisation des fonctions SQL, voici quelques exemples :
Certaines utilisations ont aussi été simplifiées en automatisant des tâches.
Prenons l’exemple d’un appel à un web service avec une authentification basique. Le couple profil / mot de passe doit être séparé par « : » et l’ensemble encoder en base64. C’est la norme HTTP.
Dans le cas des fonctions de SYSTOOLS, il fallait effectuer l’ensemble des opérations, alors qu’avec les fonctions de QSYS2, il suffit de passer le profil et le mot de passe dans la propriété BasicAuth. La mise en forme et l’encodage étant faits directement par les fonctions AXIS :
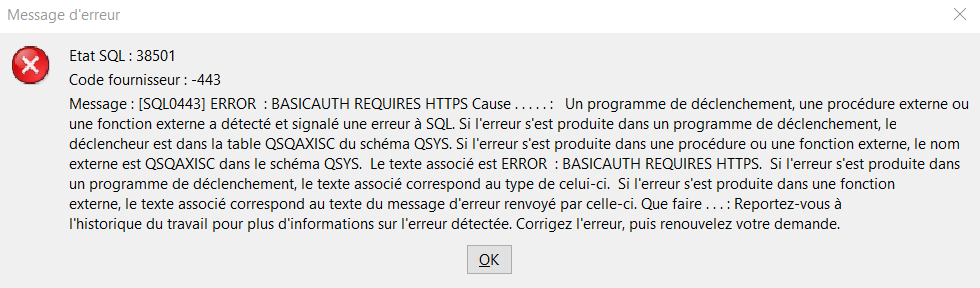
Il y a par contre un cas limitatif des fonctions QSYS2, que IBM a rajouté, alors que la norme HTTP autorise ce type d’appel.
Il s’agit d’avoir une authentification basique sur un appel en http.
Ce cas n’est pas trop contraignant, aujourd’hui le https est la norme et le http quasiment disparu…. quasiment ! Nous rencontrons encore chez nos clients des web services « interne » en http. La migration en https n’étant pas vendeur auprès des directions qui n’y voit aucun gain pour le métier. C’est l’éternel problème des changements structurels en IT.
Dans ces cas, la fonction de QSYS2, renverra une erreur, assez claire !
Le premier réflexe est de voir avec le fournisseur du service s’il ne dispose pas d’une version en https.
Maintenant, si vous n’avez pas d’autre choix que d’appeler un web service en http avec authentification basique, il faudra continuer d’utiliser les fonctions de SYSTOOLS. Dans tous les autres cas, aucune hésitation, utilisez les fonctions de QSYS2.
Mais mettons nous d’accord, de l’authentification basique en http, ce n’est pas de la sécurité, c’est une absurdité.
En http, le message passe en clair sur la trame réseau, avec votre profil / mot de passe, encodé en base 64, et non encrypté, donc en clair eux aussi.
Edit :Précision apportée par Gautier Dumas de CFD-innovation. Merci à lui. On peut contourner le problème avec les fonctions de QSYS2. Il ne faut pas utiliser la propriété BASICAUTH, mais construire l’authentification basique comme on le faisait avec celle de SYSTOOLS. VALUES QSYS2.HTTP_GET( ‘http://hostname/wscommon/api/contacts’, ‘{« header »: »Authorization, BASIC dGVzdHVzZXI6dGVzdHB3ZA== »}’); Il n’y a donc vraiment plus de raison de continuer avec les fonctions de SYSTOOLS !
https://www.gaia.fr/wp-content/uploads/2025/02/DT-1-e1739799848306.png205175Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2023-11-06 11:53:362025-02-17 14:49:32SQL – appel de webservice
Administration, SQL_DB2Comprendre comment un travail interactif est affecté à un sous système.
C’est des entrées écran qui peuvent être indiquées sur des sous systèmes, par les commandes ADDWSE et CHGWSE.
Il va utiliser le nom de l’unité écran, il va faire la recherche dans cet ordre :
-Par nom -par nom générique -*all
Vous avez un service SQL qui permet de les visualiser QSYS2.WORKSTATION_INFO
Voici une requête qui permet de voir et comprendre les entrées de votre système
SELECT A.SUBSYSTEM_DESCRIPTION_LIBRARY, A.SUBSYSTEM_DESCRIPTION, WORKSTATION_NAME
FROM QSYS2.WORKSTATION_INFO as A Join QSYS2.SUBSYSTEM_INFO AS B
on A.SUBSYSTEM_DESCRIPTION_LIBRARY= b.SUBSYSTEM_DESCRIPTION_LIBRARY and
A.SUBSYSTEM_DESCRIPTION = b.SUBSYSTEM_DESCRIPTION
and B.STATUS = 'ACTIVE' and ALLOCATION = '*SIGNON'
where WORKSTATION_NAME not like('%*%')
union
SELECT A.SUBSYSTEM_DESCRIPTION_LIBRARY, A.SUBSYSTEM_DESCRIPTION, WORKSTATION_NAME
FROM QSYS2.WORKSTATION_INFO as A Join QSYS2.SUBSYSTEM_INFO AS B
on A.SUBSYSTEM_DESCRIPTION_LIBRARY= b.SUBSYSTEM_DESCRIPTION_LIBRARY and
A.SUBSYSTEM_DESCRIPTION = b.SUBSYSTEM_DESCRIPTION
and B.STATUS = 'ACTIVE' and ALLOCATION = '*SIGNON'
where WORKSTATION_NAME like('%*%')
union
SELECT A.SUBSYSTEM_DESCRIPTION_LIBRARY, A.SUBSYSTEM_DESCRIPTION, WORKSTATION_TYPE
FROM QSYS2.WORKSTATION_INFO as A Join QSYS2.SUBSYSTEM_INFO AS B
on A.SUBSYSTEM_DESCRIPTION_LIBRARY= b.SUBSYSTEM_DESCRIPTION_LIBRARY and
A.SUBSYSTEM_DESCRIPTION = b.SUBSYSTEM_DESCRIPTION
and B.STATUS = 'ACTIVE' and ALLOCATION = '*SIGNON'
where WORKSTATION_TYPE = '*ALL'
En principe ca représentera l’ordre de recherche dans votre #ibmi
Remarque :
Quand 2 entrées sont démarrés avec le même critère c’est le premier qui est pris en compte Ici les entrées QPADEV* entrerons dans QINTER On peut également faire des entrées par type les 2 principaux sont IBM-3477-FC 132 IBM-3179-2 80 https://www.rfc-editor.org/rfc/rfc1205 Mais à éviter pas simple à gérer
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-11-03 11:43:412023-11-03 11:43:44Comprendre comment un travail interactif est affecté à un sous système.
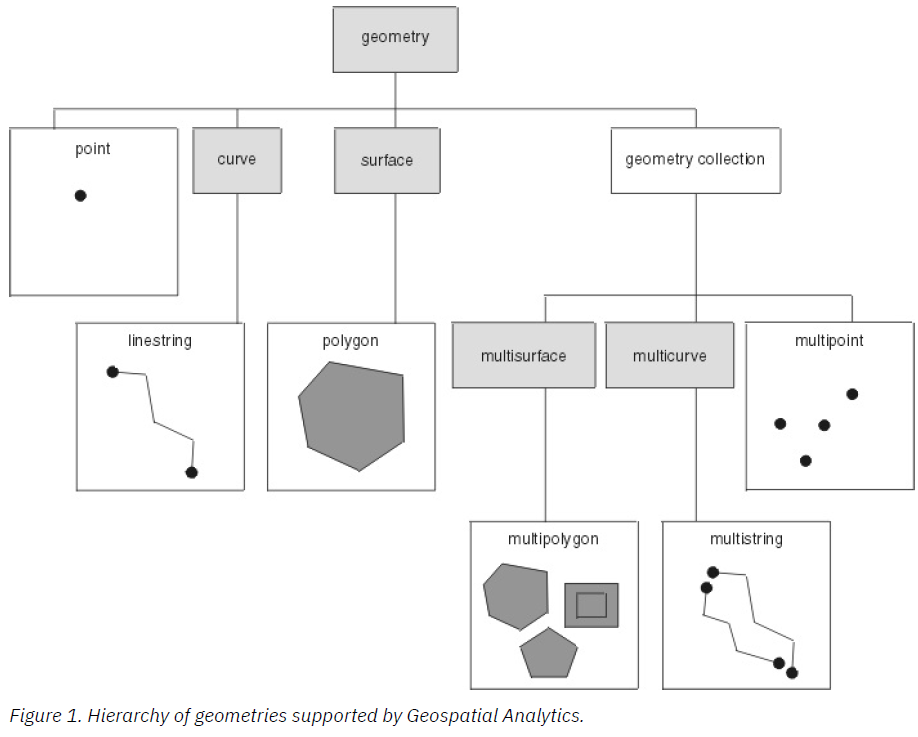
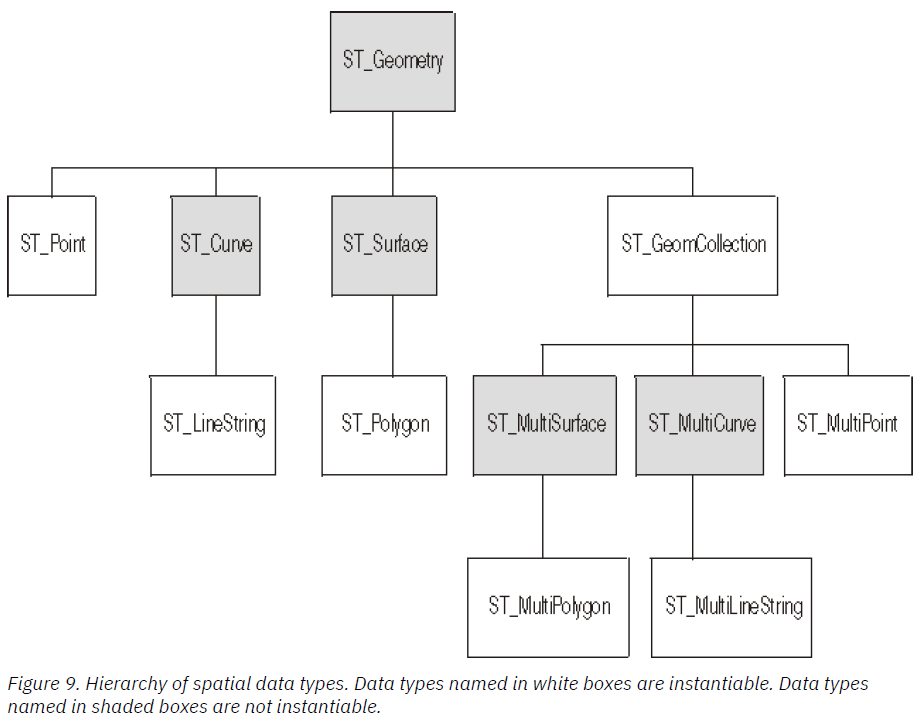
Concernant les fichiers JSON, on observe plusieurs types de géométries, principalement POLYGON et MULTIPOLYGON. C’est pourquoi il nous faut définir dans nos fichiers, une colonne qui puisse englober plusieurs types de géométries. Pour ce faire, le document Database Geospatial Analytics nous fournit quelques informations …
Nous choisirons donc, pour nos fichiers, une colonne basée sur la fonction ST_GEOMETRY, qui nous permet d’englober les deux type nommés ci-dessus. Voici donc comment nous constituerons nos tables.
-- Table des états américains
CREATE TABLE GGEOLOC.US_STATES (
STATE_ID CHAR(2) PRIMARY KEY,
STATE_FULL_NAME VARCHAR(50),
STATE_GEO QSYS2.ST_GEOMETRY);
-- Table des pays
CREATE TABLE GGEOLOC.COUNTRIES (
CODE_ISO VARCHAR(3) PRIMARY KEY,
NAME VARCHAR(50),
CNTRY_GEO QSYS2.ST_GEOMETRY);
-- Table des villes
CREATE TABLE GGEOLOC.MYCITIES (
CTY_NAME VARCHAR(50) ,
CTY_GEO QSYS2.ST_GEOMETRY);
Cet article étant dédié aux fonctions géospatiales, nous n’expliciterons pas la récupération des données.
Bienvenue à bord
ST_ISSIMPLE & ST_GEOMETRYTYPE …
… attachez vos ceintures
ST_ISSIMPLE nous permet de savoir si la géométrie de la figure sélectionnée est simple (valeur 1) ou bon (valeur 0).
SELECT STATE_FULL_NAME,
CASE QSYS2.ST_ISSIMPLE(STATE_GEO)
WHEN 0 THEN 'Geometry is not simple'
WHEN 1 THEN 'Geometry is simple'
END
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
Geometry is not simple
Hawaii
Geometry is simple
Illinois
Geometry is simple
Indiana
Geometry is simple
Wisconsin
Geometry is simple
ST_GEOMETRYTYPE nous permet de savoir de quel type de géométrie nous parlons, et nous pouvons donc constater que la simplicité de la géométrie n’a pas de lien avec le caractère « MULTI » de la figure.
SELECT STATE_FULL_NAME, QSYS2.ST_GEOMETRYTYPE(STATE_GEO)
FROM GGEOLOC.US_STATES where STATE_ID in ('WI', 'IL', 'IN', 'HI', 'AK');
Alaska
ST_MULTIPOLYGON
Hawaii
ST_MULTIPOLYGON
Illinois
ST_POLYGON
Indiana
ST_POLYGON
Wisconsin
ST_POLYGON
ST_ASTEXT & ST_ASBINARY …
… briefing avant décollage
Si nous exécutons une extraction brute de nos données, on ne comprend pas immédiatement
select STATE_ID, STATE_FULL_NAME, STATE_GEO
from GGEOLOC.US_STATES where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'CO');
ST_AREA nous donne la surface en m² d’une aire géographique (POLYGON ou MULTIPOLYGON)
on ajoute une colonne ici pour avoir une idée de l’aire en km²
select STATE_ID, STATE_FULL_NAME, QSYS2.ST_AREA(STATE_GEO), integer(QSYS2.ST_AREA(STATE_GEO)/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'TX', 'AL', 'AR', 'HI');
AL
Alabama
1.3409800288446873E11
134098
AR
Arkansas
1.3838751120399905E11
138387
HI
Hawaii
1.4748657954505682E10
14748
OK
Oklahoma
1.8250255202012402E11
182502
TX
Texas
6.886199875225208E11
688619
ST_BUFFER nous donne les coordonnées d’une surface élargie du nombre de mètres voulus
voici un exemple de calcul de surfaces en élargissant de 1000 m les frontières de deux états
select STATE_ID, STATE_FULL_NAME, integer(QSYS2.ST_AREA(STATE_GEO)/1000000), integer(QSYS2.ST_AREA(QSYS2.ST_BUFFER(STATE_GEO, 1000))/1000000)
from GGEOLOC.US_STATES
where STATE_ID in ('OK', 'AL');
AL
Alabama
134098
135822
OK
Oklahoma
182502
184806
ST_DISJOINT & ST_WITHIN …
… garder le cap
ST_DISJOINT retourne 1 si deux figures n’ont rien en commun.
select CTY_NAME, CODE_ISO
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where QSYS2.ST_DISJOINT(CTY_GEO, CNTRY_GEO) = 0 ;
HELSINKI
FIN
TEGUCIGALPA
HND
NAIROBI
KEN
GUADALAJARA
MEX
COPENHAGEN
DNK
LYON
FRA
NANTES
FRA
OSLO
NOR
ROCHESTER
USA
ST_WITHIN retourne 1 si la première figure est complètement dans la seconde.
Exemple : Une ville est-elle contenue dans un pays ? Un pays est-il contenu dans une ville ?
select CTY_NAME, CODE_ISO, QSYS2.ST_WITHIN(CTY_GEO, CNTRY_GEO), QSYS2.ST_WITHIN(CNTRY_GEO, CTY_GEO)
from GGEOLOC.MYCITIES, GGEOLOC.COUNTRIES
where CTY_NAME in ('LYON', 'ROCHESTER') and CODE_ISO in ('FRA', 'USA') ;
LYON
FRA
1
0
ROCHESTER
FRA
0
0
LYON
USA
0
0
ROCHESTER
USA
1
0
ST_INTERSECTS & ST_INTERSECTION …
… passer la frontière
ST_INTERSECTS nous permet de savoir si deux figures ont une intersection (la fonction retourne 1 si tel est le cas)
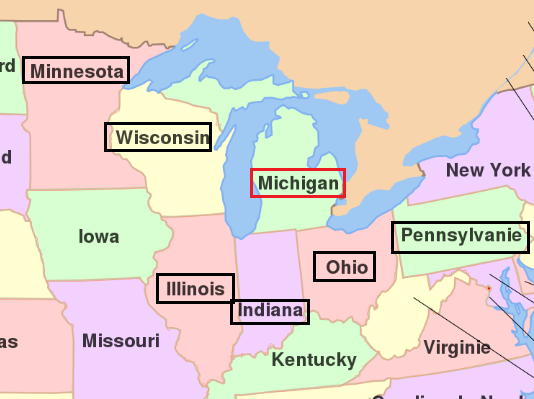
Dans l’exemple suivant, on cherche parmi une liste d’états, à savoir si ceux-ci sont directement voisins du Michigan
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN') ;
Michigan
Illinois
Etats éloignés
Michigan
Indiana
Etats Voisins
Michigan
Minnesota
Etats éloignés
Michigan
Ohio
Etats Voisins
Michigan
Pennsylvania
Etats éloignés
Michigan
Wisconsin
Etats Voisins
Il suffisait de voir la carte pour s’en rendre compte !! Heureusement, ST_INTERSECTION nous en dit beaucoup plus puisqu’elle nous indique la forme de l’intersection entre deux figures géométriques.
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_ASTEXT(QSYS2.ST_INTERSECTION(t1.STATE_GEO, t2.STATE_GEO)),
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
ST_DISTANCE va retourner la distance entre deux points, mais il est intéressant de l’utiliser sur des figures de type POLYGON …
select t1.STATE_FULL_NAME, t2.STATE_FULL_NAME,
QSYS2.ST_DISTANCE(t1.STATE_GEO, t2.STATE_GEO)/1000
CASE WHEN QSYS2.ST_INTERSECTS(t1.STATE_GEO, t2.STATE_GEO) = 1
THEN 'Etats Voisins'
ELSE 'Etats éloignés'
END as config
from GGEOLOC.US_STATES t1, GGEOLOC.US_STATES t2
where t1.STATE_ID = 'MI'
and t2.STATE_ID in('WI', 'IL', 'IN', 'OH', 'PA', 'MN');
Michigan
Illinois
58.493941547601004
Michigan
Indiana
0.0
Michigan
Minnesota
33.60195301382611
Michigan
Ohio
0.0
Michigan
Pennsylvania
179.1488383130458
Michigan
Wisconsin
0.0
… pour lesquelles on se rend compte que la fonction retourne la distance (ramenées en km ici) entre les points les plus proches des deux figures comparées.
Atterrissage
Nous n’avons exploré ici qu’une partie des fonctions géospatiales disponibles. Il en existe bien d’autres fonctions pour savoir si une figure recouvre complètement une autre, si une figure est contenue dans une autre si une figure en traverse une autre, … Il existe également des fonctions de manipulation des GEOHASHES (système de géocodage basé sur la division d’une zone géographique en cellules).
Bref, tout une panoplie de fonctions que l’on peut combiner à l’infini et au-delà !
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2023-10-09 18:03:122023-10-09 18:03:14LE TOUR DU MONDE EN 10 (+1) FONCTIONS GEOSPATIALES
Comment gérer simplement les informations de modifications sur les enregistrements utilisateur + date de création ou de modification
Vous connaissez la méthode applicative par sql ou update
Vous connaissez la méthode par trigger after, vous modifiez les zones dans le buffer après avec les informations en cours.
Voici un solution ou vous n’avez rien à faire, vous laissez faire SQL
Soit la table suivante des applications :
CREATE TABLE APPLICATION1 FOR SYSTEM NAME APPLICAT1 ( DESCRIPTION_APPLICATION FOR COLUMN DES_APP CHAR(50) NOT NULL WITH DEFAULT, APPLICATION_CODE FOR COLUMN APP_COD CHAR(8) NOT NULL WITH DEFAULT,
/* Informations de mise à jour */ APPAUSRCHG VARCHAR(18) GENERATED ALWAYS AS (USER), APPATMPCHG TIMESTAMP FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP NOT NULL, APPAUSRCRT CHAR(18) NOT NULL DEFAULT USER IMPLICITLY HIDDEN, APPATMPCRT TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP IMPLICITLY HIDDEN ) Explications :
GENERATED ALWAYS AS (USER), indique que la zone est systématiquement forcée avec l’utilisateur en cours FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP indique qu’a chaque modification, vous aurez la date en cours DEFAULT USER indique valeur par défaut utilisateur en cours DEFAULT CURRENT_TIMESTAMP indique valeur par défaut date en cours HIDDEN indique que la zone n’apparaitra pas dans un select *
UPDATE GDATA.APPLICATION1 SET DESCRIPTION_APPLICATION = ‘TEST2’, APPLICATION_CODE = ‘test2’ WHERE DESCRIPTION_APPLICATION = ‘TEST’
Visualisation du résultat
Sauf zones cachées
SELECT * ROM GDATA.APPLICATION1
Avec les zones cachés
SELECT DESCRIPTION_APPLICATION, APPLICATION_CODE, APPAUSRCHG, APPATMPCHG, APPAUSRCRT, APPATMPCRT FROM GDATA.APPLICATION1
Remarques : Les zones user devront être sur 18 en varchar Vous devez utiliser le format explicite pour la création Voila , Simple et efficace Merci à Patrick pour son exemple de code
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-09-07 21:19:252023-09-12 11:35:57Tables avec informations de création et modification
En sélectionnant la bibliothèque et le fichier, vous pouvez soit utiliser le résultat dans un programme CLLE. Ou directement dans un select avec la fonctions SQL QCMDEXC
3) Sans générer de fichier
Cette méthode est moins connue, mais elle permet de traiter tous les membres d’un fichier sans générer de fichier intermédiaire
Vous allez avoir un programme CLLE, qui aura cette logique
Vous allez récupérer le premier membre RTVMBRD FILE(LIB/FIL) MBR(*FIRSTMBR) RTNMBR(&MBR) MONMSG MSGID(CPF0000) EXEC(do) ENDDO
Vous allez ensuite boucler sur les suivants RTVMBRD FILE(LIB/&FIL) MBR(&MBR *NEXT) RTNMBR(&MBR) MONMSG MSGID(CPF3049) EXEC(leave)
Vous allez ainsi lire tous vos membres de votre fichier.
Vous pouvez également utiliser cette méthode pour traiter des membres de transfert qui arriveraient dans votre fichier.
Conclusion :
Vous avez 3 solutions pour les traiter les membres d’un fichier, à vous de choisir la méthode la plus adapter à votre traitement
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-07-25 12:10:102023-08-11 16:02:47Traiter les membres d’un fichier
La commande STRDBMON vous permet de lancer des moniteurs de base de données, si vous lancez un moniteur privé (sur le travail en cours), il prendra fin quand le job se terminera.
Mais si vous lancez un moniteur public pour tous les travaux par exemple, comment l’arrêter, vous pouvez vouloir un moniteur tous les jour de 14h à 18h pour analyser les JOB ODBC ou autres.
Nous proposons un petit code que vous pourrez améliorer qui fera cette opération :
PGM parm(&fil &lib &dly)
/* Ce programme démarre un moniteur base de données */
/* pour les jobs ODBC , Pendant x secondes */
/* ce job doit être soumis dans QSYSNOMAX */
/* par exemple */
/* Paramètres */
DCL VAR(&FIL ) TYPE(*CHAR) LEN(10)
DCL VAR(&LIB ) TYPE(*CHAR) LEN(10)
DCL VAR(&DLY ) TYPE(*CHAR) LEN(06)
/* Variables de travail */
DCL &MSGID *CHAR LEN(7)
DCL &DATA *CHAR LEN(100)
DCL &ID *CHAR LEN(10)
/* Contrôle des paramètres */
chkobj &lib *lib
monmsg cpf9801 exec(do)
SNDUSRMSG MSG('Bibliothèque,' *BCAT &LIB *BCAT +
'inexistante') MSGTYPE(*INFO)
return
enddo
chkobj &lib/&fil *file
monmsg cpf9801 exec(do)
goto suite
enddo
SNDUSRMSG MSG('Monitor,' *BCAT &fil *BCAT +
'déjà existant') MSGTYPE(*INFO)
return
suite:
/* démarrage */
STRDBMON OUTFILE(&LIB/&FIL) +
JOB(*ALL/QUSER/QZDASOINIT) +
HOSTVAR(*SECURE) COMMENT('ODBC JOBS')
/* Lecture de l'id du moniteur */
/* message CPI436A */
DOUNTIL COND(&MSGID = 'CPI436A')
RCVMSG MSGQ(*PGMQ) MSGDTA(&DATA) +
MSGID(&MSGID)
enddo
CHGVAR VAR(&ID) VALUE(%SST(&DATA 29 10))
SNDUSRMSG MSG('Moniteur, ' *BCAT &ID *BCAT 'démarré') +
MSGTYPE(*INFO)
/* Retardement de l'arrêt en secondes */
DLYJOB DLY(&dly)
ENDDBMON JOB(*ALL) MONID(&ID)
SNDUSRMSG MSG('Moniteur, ' *BCAT &ID *BCAT 'arrêté') +
MSGTYPE(*INFO)
ENDPGM
Vous pouvez indiquer la bibliothèque et le fichier de sortie pour le monitor et le temps d’exécution en secondes
Vous pouvez changer les filtres au niveau du STRDBMON en précisant ce que vous voulez analyser
vous pouvez faire une commande comme ceci pour lancer plus facilement votre programme !
Vous pouvez le planifier dans votre Scheduler et indiquer par exemple un nom de fichier DBMAAMMJJ pour chaque jour, vous pourrez ainsi comparer au fil du temps ce qui ce passe sur cette période dans votre base de données.
Attention à bien le soumettre dans une file qui ne bloquera pas vos traitements, par exemple QSYSNOMAX ou QUSRNOMAX
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2023-07-14 11:50:412023-08-11 16:04:43Un moniteur DB limité dans le temps
Sur le site https://adresse.data.gouv.fr/ En cliquant sur l’item « Outils et API », on accède librement à la documentation des API en rapport avec les adresses. Nous choisissons donc celle sobrement intitulée « API Adresse ». La documentation montre différentes manières d’utiliser cette API. Le retour est un geojson FeatureCollection respectant la spec GeoCodeJSON.
Récupération et manipulation des données
But du programme
Nous allons réaliser un programme qui permettra, en écrivant partiellement une adresse, de récupérer une adresse complète d’après une liste déroulante de 50 occurrences.
Nous choisirons pour notre programme une interrogation relativement simple et nous n’extrairons qu’une partie des données du geojson.
Nous écrirons les adresses dans un fichier, sous forme d’une fiche client contenant les éléments suivants :
Identifiant (integer auto incrémenté)
Raison Sociale (varchar)
Adresse (varchar)
Code Postal (varchar)
Ville (varchar)
Coordonnées géographiques (ST_POINT)
Préparation du fichier
create table GGEOLOC.MESCLIENTS
(ID int GENERATED ALWAYS AS IDENTITY (
START WITH 1 INCREMENT BY 1
NO MINVALUE NO MAXVALUE
NO CYCLE NO ORDER
CACHE 20 ),
RAISOC varchar(64),
ADRESSE varchar(128),
CODEPOS varchar(16),
VILLE varchar(64),
COORDGEO QSYS2.ST_POINT);
Programme de saisie
**free
ctl-opt dftactgrp(*no) ;
// Fichiers
dcl-f FORMCLIE workstn indds(DS_Ind) usropn;
// Procédures
dcl-pr Touche_F4 EXTPGM('TOUCHE_F4');
p_Sql char(1024) ;
p_Titre char(35);
p_Ret char(116);
end-pr;
// Variables
dcl-s reqSqlDelete varchar(2000);
dcl-s reqSqlCreate varchar(2000);
dcl-s reqSqlDrop varchar(2000);
dcl-s coordonees varchar(64) ;
dcl-s queryapi varchar(64);
dcl-s httpText varchar(256);
dcl-s pIndicators Pointer Inz(%Addr(*In));
// Pour F4 : liste des fichiers
dcl-s w_Sql char(1024) ;
dcl-s w_Titre char(35);
dcl-s w_Ret char(116);
// DS Informations Programme
dcl-ds *N PSDS;
nom_du_pgm CHAR(10) POS(1);
nom_du_prf CHAR(10) POS(358);
end-ds;
// Déclaration des indicateurs de l'écran
Dcl-DS DS_Ind based(pIndicators);
Ind_Sortie ind pos(3);
Ind_Liste ind pos(4);
Ind_Annuler ind pos(12);
Ind_Valider ind pos(17);
Ind_SFLCLR ind pos(40);
Ind_SFLDSP ind pos(41);
Ind_SFLDSPCTL ind pos(42);
Ind_SFLEnd ind pos(43);
Ind_DisplayCoord ind pos(80);
Ind_RaisonS ind pos(81);
Ind_5Lettres ind pos(82);
Ind_CodePos ind pos(84);
Ind_Ville ind pos(85);
Indicators char(99) pos(1);
End-DS;
// Paramètres en entrée
dcl-pi *N;
end-pi;
// SQL options --------------------------------------------- //
Exec SQL
Set Option
Naming=*Sys,
Commit=*None,
UsrPrf=*User,
DynUsrPrf=*User,
Datfmt=*iso,
CloSqlCsr=*EndMod;
//--------------------------------------------------------- //
// Contrôle taille écran
Monitor;
Open FORMCLIE;
On-Error;
Dsply 'Nécessite un écran 27 * 132';
*inlr=*on;
Return;
EndMon;
Dou Ind_Sortie or Ind_Annuler;
znompgm = nom_du_pgm;
znomprf = nom_du_prf;
Exfmt FMT01;
select ;
when Ind_Sortie ;
leave;
when Ind_Annuler;
leave;
when Ind_Liste;
if %len(%trim(zadresse)) <= 4 ;
Ind_5Lettres = *on;
iter;
endif;
traitementListe();
when Ind_Valider;
if zraisoc = *blanks;
Ind_RaisonS = *on ;
endif;
if zcodpos = *blanks;
Ind_CodePos= *on ;
endif;
if zville = *blanks;
Ind_Ville = *on ;
endif;
if %subst(indicators:81:4) <> '0000';
iter ;
endif;
Exec SQL
insert into MESCLIENTS (RAISOC, ADRESSE, CODEPOS, VILLE, COORDGEO)
values (:zraisoc, :zadresse, :zcodpos, :zville,
QSYS2.ST_POINT(:zlongit, :zlatit)) ;
Ind_DisplayCoord = *off;
clear FMT01;
endsl ;
Enddo;
*inlr = *on;
//======================================================================== //
// Procédures //
//======================================================================== //
//------------------------------------------------------------------------ //
// Nom : rechercheAdresse //
// But : lister des adresses recueillies via une API //
// à partir d'une chaine de plus de 4 caractères //
// Retour : N/A //
//------------------------------------------------------------------------ //
dcl-proc rechercheAdresse ;
dcl-pi *n ;
l_httpText varchar(256) value;
end-pi;
reqSqlDrop = 'drop table QTEMP/WADRESSE' ;
Exec sql Execute immediate :reqSqlDrop ;
reqSqlCreate = 'create table QTEMP/WADRESSE' +
' (address varchar(128), numero varchar(8), street varchar(128), ' +
'postcode varchar(16), city varchar(64), coordinates blob)' ;
Exec sql Execute immediate :reqSqlCreate ;
reqSqlDelete = 'delete from QTEMP/WADRESSE' ;
Exec sql Execute immediate :reqSqlDelete ;
Exec sql
insert into QTEMP/WADRESSE
(select ltrim(ifnull(numero, '') || ' ' ||
coalesce(street, locality, '') || ' ' ||
postcode || ' ' || city),
ifnull(numero, ''), coalesce(street, locality, ''),
postcode,
city,
QSYS2.ST_POINT(longitude, latitude)
from json_table(QSYS2.HTTP_GET(:l_httpText, ''), '$.features[*]'
COLUMNS
(numero varchar(8) PATH '$.properties.housenumber',
street varchar(128) PATH '$.properties.street',
locality varchar(128) PATH '$.properties.locality',
name varchar(128) PATH '$.properties.name',
municipality varchar(128) PATH '$.properties.municipality',
postcode varchar(8) PATH '$.properties.postcode',
city varchar(64) PATH '$.properties.city',
longitude float PATH '$.geometry.coordinates[0]',
latitude float PATH '$.geometry.coordinates[1]'))
);
end-proc ;
//------------------------------------------------------------------------ //
// Nom : traitementListe //
// But : Affichage d'une liste de 50 adresses maximum //
// Retour : N/A //
//------------------------------------------------------------------------ //
dcl-proc traitementListe ;
queryapi = %scanrpl(' ':'+':%trim(zadresse)) ;
httpText ='https://api-adresse.data.gouv.fr/search/?q=' +
queryapi + '&limit=50' ;
rechercheAdresse(httpText);
clear w_ret ;
w_sql =
'select address from QTEMP/WADRESSE' ;
w_titre = 'Adresses proposées';
touche_f4(W_Sql: W_titre : w_ret) ;
if (w_ret <> ' ') ;
clear zadresse;
clear zcodpos;
clear zville;
Exec SQL
select
ltrim(ifnull(numero, '') || ' ' || street), postcode, city,
REPLACE(
REPLACE(QSYS2.ST_asText(COORDINATES), 'POINT (', ''), ')', '')
into :zadresse, :zcodpos, :zville, :coordonees
from QTEMP.WADRESSE
where address = :w_ret ;
if sqlcode = 0 ;
Ind_DisplayCoord = *on ;
zlongit = %dec(%subst(coordonees: 1 : %scan(' ':coordonees)):15:12) ;
zlatit = %dec(%subst(coordonees: %scan(' ':coordonees) + 1
: %len(%trim(coordonees)) - %scan(' ':coordonees)):15:12) ;
endif;
endif ;
end-proc ;
Quelques explications sur les fonctions SQL utilisées
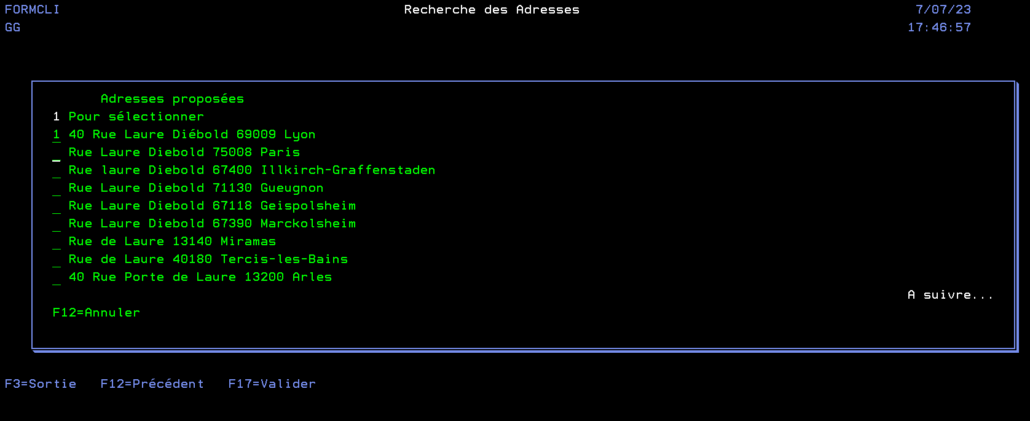
Tout d’abord nous choisissons de ne pas utiliser la propriété « label » proposée par l’API Adresse. En effet, si celle-ci semble pratique de prime abord, elle n’est pas toujours significative (voir photo du milieu qui où elle ne contient que le nom de la municipalité)
Nous, préférerons donc reconstituer cette adresse en concaténant des zones que l’on retrouve dans chaque occurrence du fichier JSON.
QSYS2.ST_POINT : Cette fonction est utilisée lors de la collecte des données fournie par l’API Adresse.
Elle permet de transformer les coordonnées longitude, latitude en une variable de type BLOB qui représente un point précis et qui est utilisable par les fonctions Géospatiales du SQL.
QSYS2.ST_ASTEXT : Cette fonction permet de transformer un champ géométrique (ST_POINT, ST_LINESTRING, ST_POLYGON, …) en un champ WKT (well-known-text) qui nous sera plus compréhensible.
Cinématique du programme
Ce programme est un simple écran qui nous permet la saisie d’un formulaire avec la possibilité de rechercher ou compléter une adresse en utilisant la touche F4 (la fonction externe appelée n’est pas décrite dans cet article). Une fois le formulaire validé, on l’efface.
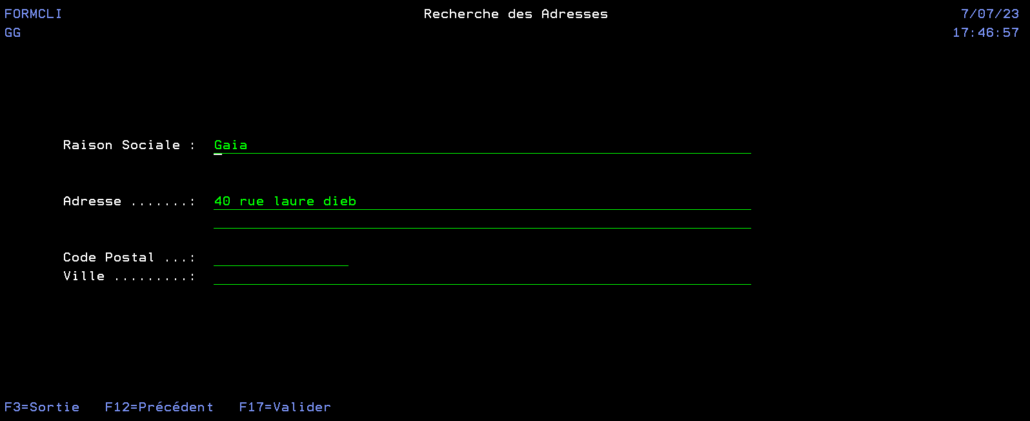
Tout d’abord on commence à remplir le formulaire mais on ne connait pas précisément l’adresse.
Donc, après avoir tapé un morceau d’adresse on presse F4
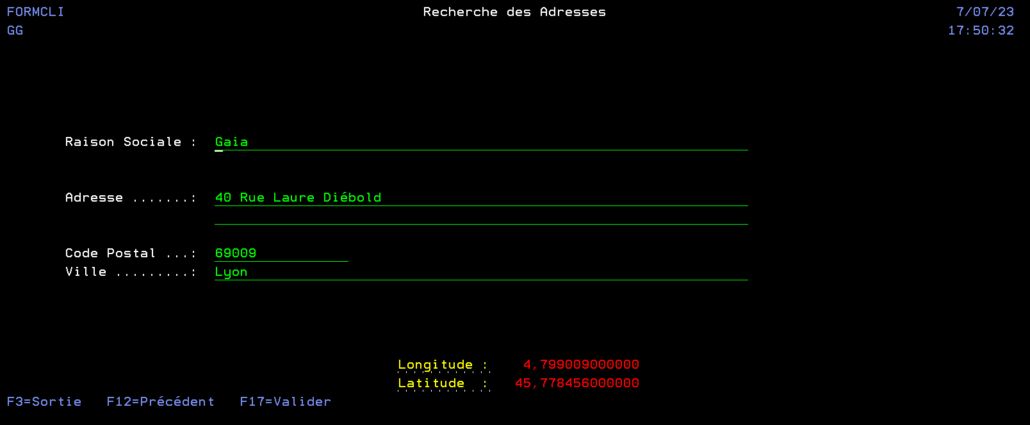
On valide, le formulaire est alors complétement rempli
On presse F17 pour valider celui-ci (et réinitialiser l’écran).
Vérification des données enregistrées
Version BLOB
Version WKT (well-known-text)
Conclusion
Nous avons montré ici un exemple simple de l’utilisation d’une API couplée avec les fonctions géospatiales proposées par IBM. Il est possible d’envisager des requêtes plus complexes incluant le code postal, la ville ou encore le type de donnée (rue, lieu-dit ou municipalité). On peut aussi envisager des requêtes d’après les coordonnées géographiques pour retrouver une adresse. Le champ des possibles, comme le monde, est vaste …
https://www.gaia.fr/wp-content/uploads/2021/07/GG-2.jpg343343Guillaume GERMAN/wp-content/uploads/2017/05/logogaia.pngGuillaume GERMAN2023-07-10 08:34:102023-08-11 16:38:36RETROUVER UNE ADRESSE GRACE AUX API