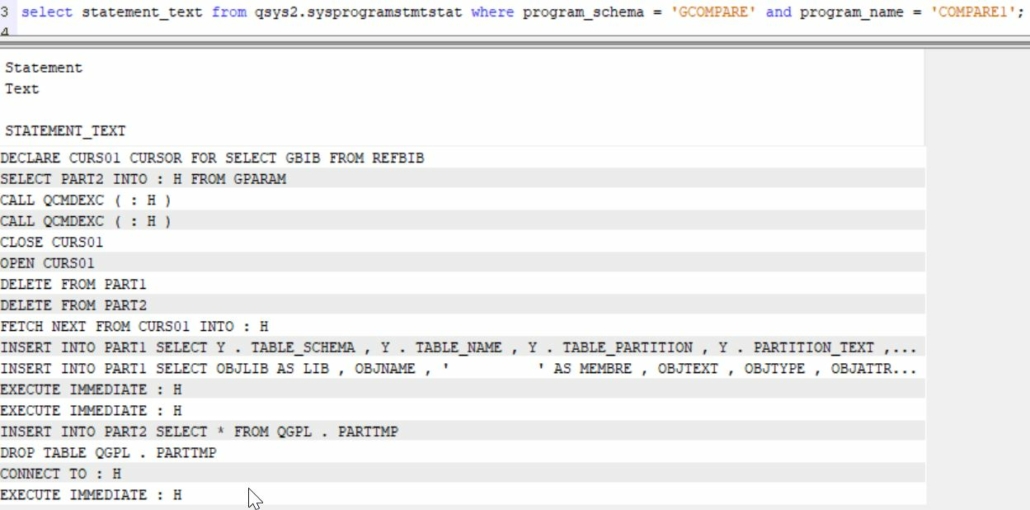
Une des difficultés, quand on développe avec VSCE sur IBMi ,
C’est que si on est 2 deux à modifier le même source, c’est le dernier qui a raison avec perte de modification du premier même s’il a sauvegardé
Voici comment on peut améliorer les choses.
On va créer un fichier base de données qui liste les sources qui sont en cours de maintenance, un peu comme un ALM.
Avec GIT on peut arriver à des mécanismes identiques, et surtout, il faut commencer à mettre vos sources dans l’IFS directement
Voila comment, vous pouvez faire pour améliorer les choses
CREATE TABLE DB_OPENLCK (FICHIER CHAR ( 10) NOT NULL WITH
DEFAULT, BIBLIO CHAR ( 10) NOT NULL WITH DEFAULT, MEMBRE CHAR ( 10)
NOT NULL WITH DEFAULT, PARTAGE CHAR ( 3) NOT NULL WITH DEFAULT,
PUSER CHAR ( 10) NOT NULL WITH DEFAULT, PDATE DATE NOT NULL WITH
DEFAULT, PTIME TIME NOT NULL WITH DEFAULT)
Pour ajouter un source à verrouiller
INSERT INTO DB_OPENLCK VALUES(‘QRPGLESRC’, ‘GDATA’, ‘AAAA’,
‘NON’, ‘PLB’, current date, current time)
Et parmi les programmes d’exit il en a un qui va nous permettre de mettre en œuvre ce contrôle
C’est le QIBM_QDB_OPEN
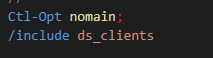
On va donc écrire un programme, ici en SQLRPGLE
**free
//
// ce programme permet d'éviter de travailler à 2 sur un même source
//
Dcl-Pi *N;
DS_parm likeds(ds_parm_t) ;
reponse int(10);
End-Pi;
// dsprogramme
dcl-ds *N PSDS ;
nom_du_pgm CHAR(10) POS(1);
init_user CHAR(10) POS(254);
enc_user CHAR(10) POS(358);
End-ds ;
// ds format DBOP0100
Dcl-DS ds_parm_t qualified template ;
taille_entete Int(10);
format Char(8);
offset_liste Int(10);
nbr_fichiers Int(10);
taille_liste Int(10);
job Char(10);
profil Char(10);
jobnbr Char(6);
cur_profil Char(10);
reste Char(1024);
End-DS;
// liste des fichiers dans notre cas un seul
Dcl-DS liste ;
fichier Char(10);
biblio Char(10);
membre Char(10);
filler Char(2);
typefichier Int(10);
sous_jacent Int(10);
access Char(4);
End-DS;
// variable de travail
Dcl-S partage char(4);
Dcl-S puser char(10);
ds_parm.offset_liste += 1;
dsply enc_user ;
liste = %subst(ds_parm : ds_parm.offset_liste :
ds_parm.taille_liste);
ds_parm.offset_liste += ds_parm.taille_liste;
// lecture des informations dans le fichier de verrouillage explicite
// le verrouillage est donc par utilisateur
exec sql
SELECT PARTAGE, PUSER into :partage , :puser
FROM DB_OPENLCK WHERE FICHIER = :FICHIER and BIBLIO
= :BIBLIO and MEMBRE = :MEMBRE ;
//
// La régle mise en oeuvre ici
// on autorise
// si même utilisateur
// si non trouvé en modification
// Si on on a dit partage à oui
//
if (sqlcode = 100 or partage = 'OUI' or puser = enc_user) ;
reponse = 1 ;
else ;
reponse = 0 ;
endif ;
// fin de programme
*inlr = *on;
ici notre règle est la suivante
on autorise
Si le source n’est pas présent dans le fichier
Si l’utilisateur est le même que celui en cours
Si on a accepté le partage et donc le risque
Pour ajouter votre pgm exit
SYSTEM/ADDEXITPGM EXITPNT(QIBM_QDB_OPEN)
FORMAT(DBOP0100)
PGMNBR(1)
PGM(GDATA/OPENSRC)
REPLACE(*NO)
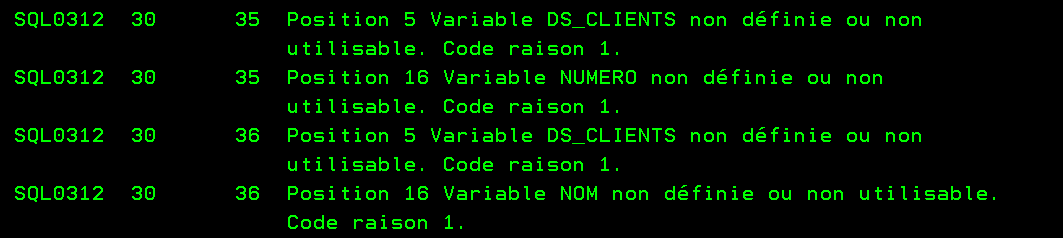
Quand on essaye d’accéder par VSCDE à notre source
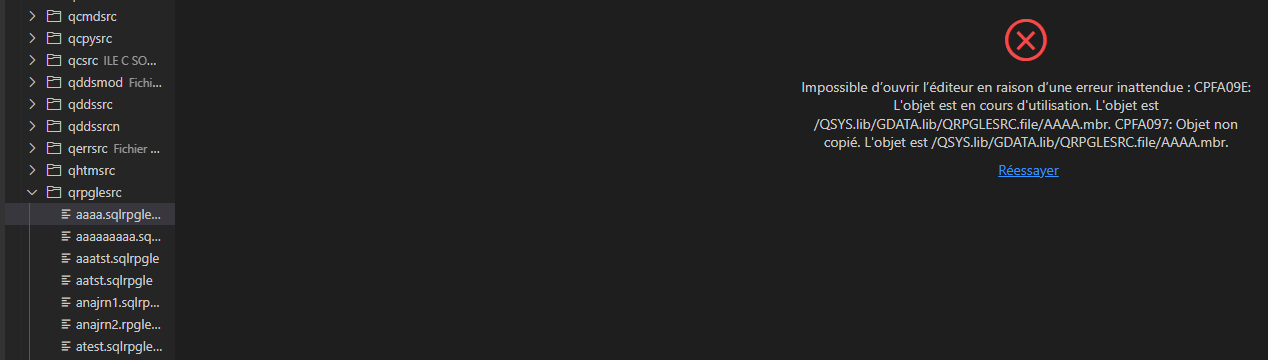
Remarque
Le contrôle marche aussi avec RDI
Il marche également pour SEU, parfois on préfère un contrôle spécifique SEU, vous devrez utiliser le programme d’exit
QIBM_QSU_ALW_EDIT en utilisant le même fichier par exemple !
**free
//
// Ce programme eviter de travailler à 2 sur un même source
//
Dcl-Pi *N;
biblio char(10);
fichier char(10);
membre char(10);
reponse char(1);
End-Pi;
// dsprogramme
dcl-ds *N PSDS ;
nom_du_pgm CHAR(10) POS(1);
init_user CHAR(10) POS(254);
enc_user CHAR(10) POS(358);
End-ds ;
Dcl-S partage char(4);
Dcl-S puser char(10);
// lecture des informations dans le fichier de verrouillage explicite
// le verrouillage est donc par utilisateur
exec sql
SELECT PARTAGE, PUSER into :partage , :puser
FROM DB_OPENLCK WHERE FICHIER = :FICHIER and BIBLIO
= :BIBLIO and MEMBRE = :MEMBRE ;
//
// La règle mise en œuvre ici
// on autorise
// si même utilisateur
// si non trouvé en modification
// Si on on adit partage à oui
//
if (sqlcode = 100 or partage = 'OUI' or puser = enc_user) ;
reponse = '1' ;
else ;
reponse = '0' ;
endif ;
// fin de programme
*inlr = *on;
On ajoute comme ca
SYSTEM/ADDEXITPGM EXITPNT(QIBM_QSU_ALW_EDIT)
FORMAT(EXTP0100)
PGMNBR(1)
PGM(GDATA/OPENSRCE)
REPLACE(*NO)
Ca ne fait pas tout, que faire si on est 2 sur le même source ? peut être faut il avoir un source de référence pour éviter le versionnage
Remarque :
Pour diminuer le nombre d’appels du programme d’exit , vous pouvez limiter le déclenchement aux fichiers qui sont audités.
Vous devez indiquer le paramètre PGMDTA(*JOB *CALC ‘*OBJAUD’) sur les commandes ADDEXITPGM ou CHGEXITPGM.
Exemple :
ADDEXITPGM EXITPNT(QIBM_QDB_OPEN)
…
PGMDTA(*JOB *CALC ‘*OBJAUD’)
Vous devez ensuite indiquer les fichiers à auditer :
Exemple :
CHGOBJAUD OBJ(GDATA/QRPGLESRC)
OBJTYPE(FILE) OBJAUD(CHANGE)
A partir de ce moment la, seuls les fichiers audités déclencheront l’appel du programme d’exit QIBM_QDB_OPEN