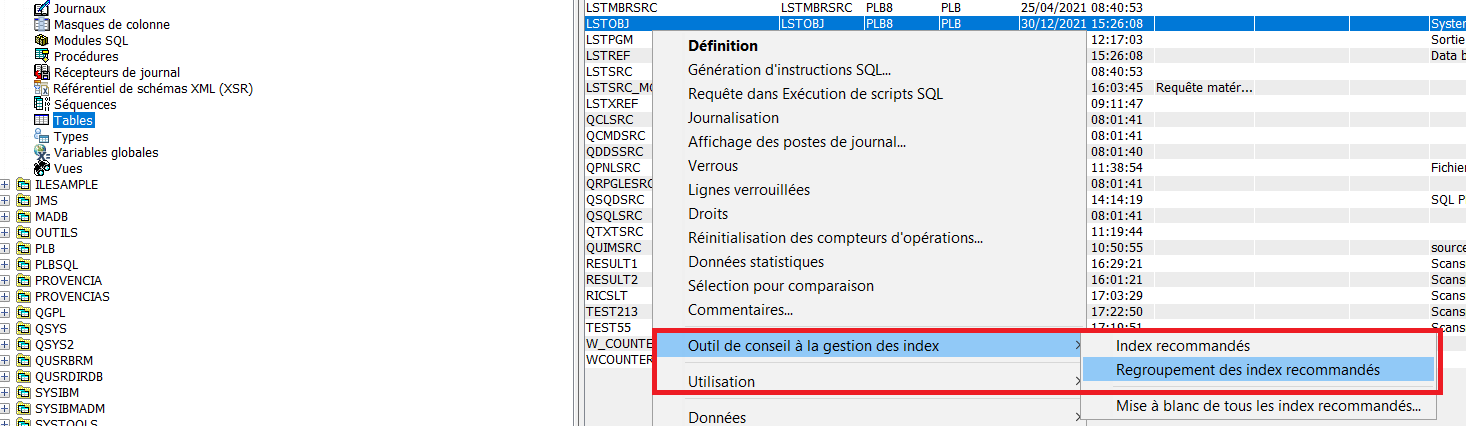
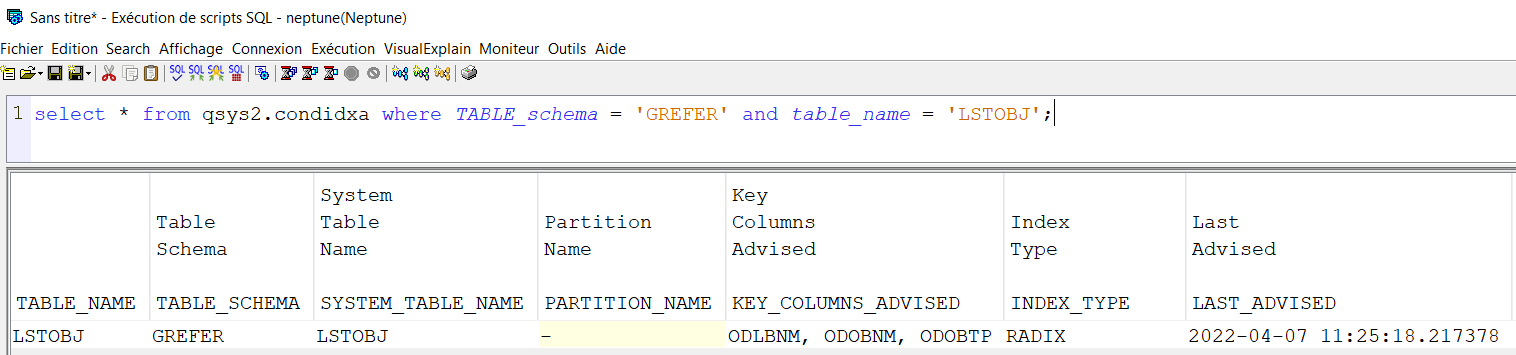
La table QSYS2.SYSIXADV implémente les conseils de création d’index. Ceci à chaque fois qu’une requête exécutée nécessiterait la création d’un index pour être plus performante. Il est utile de consulter cette table régulièrement afin de créer les index conseillés parmi les plus consommateurs et/ou les plus sollicités.
Il existe la procédure RESET_TABLE_INDEX_STATISTICS (https://www.ibm.com/docs/en/i/7.4?topic=services-reset-table-index-statistics-procedure) dont le premier rôle est de remettre à zéro les statistiques sur ces index. Une option permet la suppression des suggestions à condition que l’index ait été créé entretemps.
Pour réaliser la suppression de ces suggestions, on peut alors se créer une procédure SQL pour réaliser simplement ce ménage de façon régulière une fois que les conseils ont été suivis :
CREATE OR REPLACE PROCEDURE GREFER.DLTADVIDX (
IN LIB CHARACTER(10),
IN FIC CHARACTER(10),
IN JOURS INTEGER)
LANGUAGE SQL
MODIFIES SQL DATA
PROGRAM TYPE MAIN
CONCURRENT ACCESS RESOLUTION DEFAULT
DYNAMIC RESULT SETS 0
OLD SAVEPOINT LEVEL
COMMIT ON RETURN NO
SET OPTION DBGVIEW = *SOURCE
BEGIN
DECLARE SQLCODE INTEGER DEFAULT 0;
DECLARE RETCODE INTEGER DEFAULT 0;
DECLARE SQLSTATE CHAR(5) DEFAULT ‘00000’;
DECLARE RETSTATE CHAR(5) DEFAULT ‘00000’;
DECLARE COMPTE INTEGER;
DECLARE RFIC CHAR(10);
DECLARE OTYPE CHAR(10);
DECLARE MSG CHAR(256);
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION, NOT FOUND SET RETCODE = SQLCODE;
SET RETSTATE = SQLSTATE;
SELECT X.OBJATTRIBUTE INTO OTYPE FROM TABLE (QSYS2.OBJECT_STATISTICS(‘QSYS’, ‘LIB’, LIB) ) AS X ;
IF RETCODE = 0 THEN If UPPER(FIC) = ‘*ALL’ Then
Set RFIC = ‘ ‘;
End If;
If LOCATE(‘*’, FIC) > 1 Then Set RFIC = SUBSTR(FIC, 1, LOCATE(‘*’, FIC) -1);
End If;
If RFIC is not null then
SELECT COUNT(*) INTO COMPTE FROM QSYS2.SYSIXADV WHERE TABLE_SCHEMA=UPPER(LIB) AND TABLE_NAME LIKE UPPER(trim(RFIC))||’%’ AND LAST_ADVISED<(NOW()-JOURS DAYS);
Else
SELECT COUNT(*) INTO COMPTE FROM QSYS2.SYSIXADV
WHERE TABLE_SCHEMA=UPPER(LIB)
AND TABLE_NAME = UPPER(FIC) AND LAST_ADVISED < (NOW() - JOURS DAYS);
End If;
IF RETCODE <> 0 THEN
Set MSG = ‘Anomalie de traitement’;
Return;
END IF;
CASE COMPTE
WHEN 0 THEN
Set MSG = ‘Rien a supprimer’;
Return;
WHEN 1 THEN
Set MSG = TRIM(CHAR(COMPTE)) CONCAT ‘ information supprimee’;
ELSE
SET MSG = TRIM(CHAR(COMPTE)) CONCAT ‘ informations supprimees’;
END CASE;
If RFIC is not null then
DELETE FROM QSYS2.SYSIXADV WHERE TABLE_SCHEMA = UPPER(LIB)
AND TABLE_NAME LIKE UPPER(trim(RFIC))||’%’
AND LAST_ADVISED<(NOW()-JOURS DAYS); Else DELETE FROM QSYS2.SYSIXADV WHERE TABLE_SCHEMA = UPPER(LIB) AND TABLE_NAME = UPPER(FIC) AND LAST_ADVISED<(NOW()-JOURS DAYS); End If; IF RETCODE <> 0 THEN
Set MSG = ‘Anomalie de traitement’;
END IF;
Call systools.lprintf(msg);
ELSE
Set MSG = ‘Bibliothèque inexistante’;
Call systools.lprintf(msg);
END IF;
END;
LABEL ON ROUTINE GREFER.DLTADVIDX(CHAR(), CHAR(), INT)
IS ‘INIT STATS INDEX. (DELETE STATS)’;
COMMENT ON PARAMETER ROUTINE GREFER.DLTADVIDX (CHAR(), CHAR(), INT)
(LIB IS ‘BIBLIOTHÈQUE DU FICHIER’, FIC IS ‘INDEX’, JOURS
IS ‘NOMBRE DE JOURS DERNIÈRE INFORMATION’);
Cette fonction admet trois paramètres, Bibliothèque, Fichier et Nombre de jour de conservation de la suggestion.
Exemples d’utilisation :
Call Grefer.DLTADVIDX(‘MYLIB’, ‘*ALL’, 1); supprimera tous les conseils de plus d’un jour pour tous les fichiers de la bibliothèque MYLIB
Call Grefer.DLTADVIDX(‘MYLIB’, ‘MYF*’, 7); supprimera tous les conseils de plus de 7 jours pour tous les fichiers de la bibliothèque MYLIB dont le nom commence par MYF
Call Grefer.DLTADVIDX(‘MYLIB’, ‘MYFILE’, 28); supprimera tous les conseils de plus de 28 jours pour le fichier MYFILE de la bibliothèque MYLIB
Cela permet de nettoyer ce cumul de conseils sur certaines bibliothèques, fichiers avant d’évaluer les réels besoins de la base de données en se basant sur les ESTIMATED_CREATION_TIME les plus gourmandes et/ou les TIMES_ADVISED les plus nombreuses.