

Nous rencontrons régulièrement dans les applications historiques, des dates stockées en base de données sous des types autres que date.
Dans du numérique, 6 dont 0, 8 dont 0, dans de l’alpha, sur 6, 8 ou 10, dans des colonnes distinctes, SS, AA, MM, JJ….
Dans la plupart des applicatifs, il existe des programmes, ou des fonctions ile, permettant de convertir ces champs en « vrai » format date, en gérant les cas limite. Si date = 0, ou si date = 99999999, 29 février…
Dans des programmes avec des accès natifs à la base de données, ces programmes / fonctions remplissent leur rôle parfaitement.
Par contre dès qu’on choisit d’accèder à la base de données par SQL, nous constatons que ces programmes sont peu à peu délaissés pour des manipulations de date directement dans les réquêtes SQL, avec des requêtes alourdit à base de case et de concat.
Pour harmoniser les règles de conversion, et allèger visuellement vos requêtes, vous pouvez créer votre propre fonction SQL, qui rendra les mêmes services que les programmes existants.
Prenons l’exemple, rencontré chez un client, d’un ERP qui stocke les dates sous un type numérique de 7 dont 0. La première position contient 0 ou 1 pour le siècle. 0 =19 et 1 = 20.
Dans cette base :
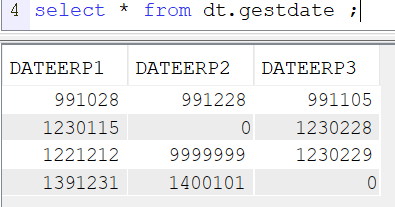
- 950118 = 18/01/1995
- 1230118 = 18/01/2023
- on peut trouver les valeurs 0 et 9999999 qui ne sont pas des dates, et qu’il faudra gérer lors de la conversion
- on peut trouver des fausses dates : 29022023, 31092022…
Nous allons créer une fonction SQL qui permettra de gérer la conversion de ces colonnes en « vraie » date.
Pour la gestion des cas limites, j’ai choisi les règles suivantes, à chacun d’adapter en fonction de ses besoins :
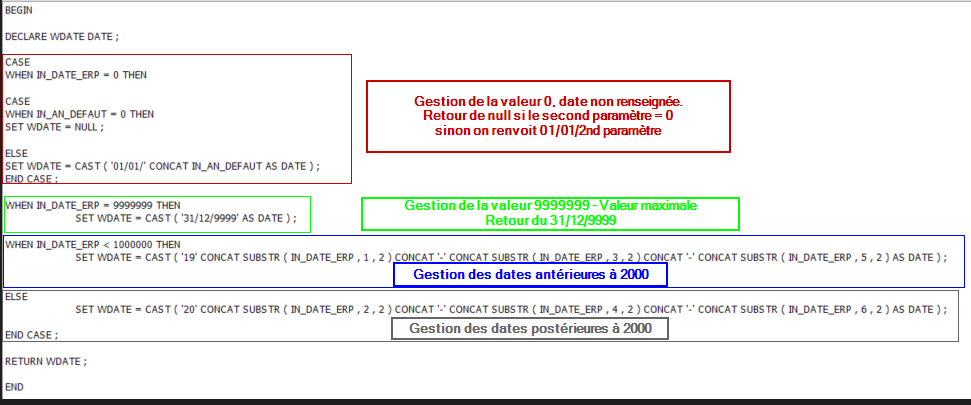
- 9999999 –> 31/12/9999
- 0 soit null si 0 passé en second paramètre, soit 01/01/Année passée en second paramètre
- les dates inexistantes –> null
Notre jeu d’essai est composé d’une table avec 3 colonnes numérique de 7 dont 0 avec 4 enregistrements :
Pour créer nos propres fonctions SQL, on peut le faire directement en mode script via un requêteur SQL, ou utiliser une fonction d’ACS qui permet une préconfiguration en mode graphique. Je vais détailler cette seconde méthode.
Dans le bloc « Base de données » d’ACS, sélectionner l’option Schémas
Déplier l’arborescence, de votre base de données et Schémas.
Il va falloir se positionner sur le schéma (la bibliothèque) qui contiendra la fonction SQL.
Je vous conseille d’utiliser la bibliothèque contenant vos données métier, pour en faciliter l’utilisation dans vos applications.
Si les données sont en ligne, la fonction le sera aussi !
Déplier l’arboresence au niveau du schéma souhaité et cliquer sur l’item « Fonctions ».
La liste des fonctions déjà existantes dans ce schéma apparait dans la partie droite….
Par clic droit sur l’item « Fontions », choisir dans le menu, « Nouveau », puis « SQL »
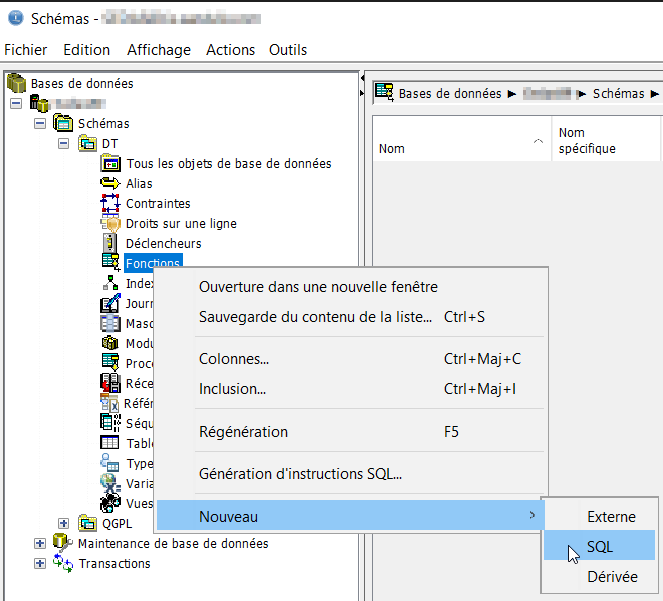
Dans la fenêtre de paramétrage, on va se déplacer d’onglet en onglet.
Saisir le nom pour votre fonction.
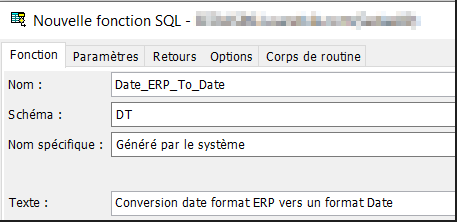
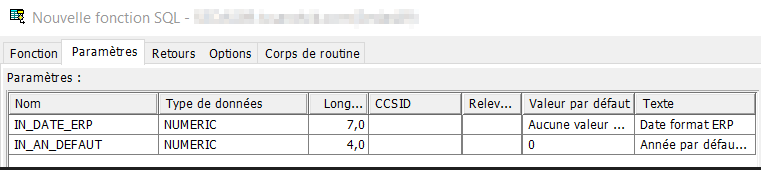
- Onglet « Paramètres » par le bouton sur la droite « Ajout… », on va déclarer les paramètres en entrée de la fonction, en premier un numérique de 7 dont 0 et en second un numérique de 4 dont 0 pour passer une année par défaut en cas de 0.
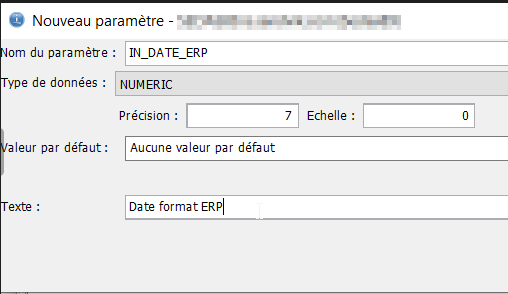
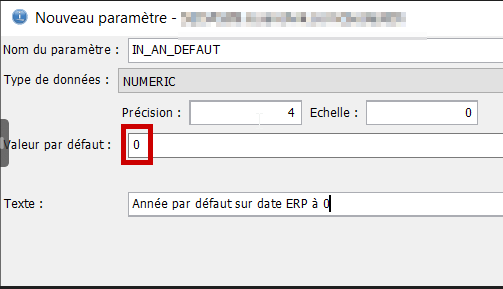
Pour l’année par défaut, nous ajoutons une valeur par défaut, 0. Nous verrons l’intérêt de cette valeur par la suite.
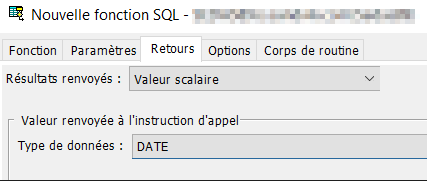
- Onglet « Retours », nous déclarons la valeur de retour, soit une date au format date.
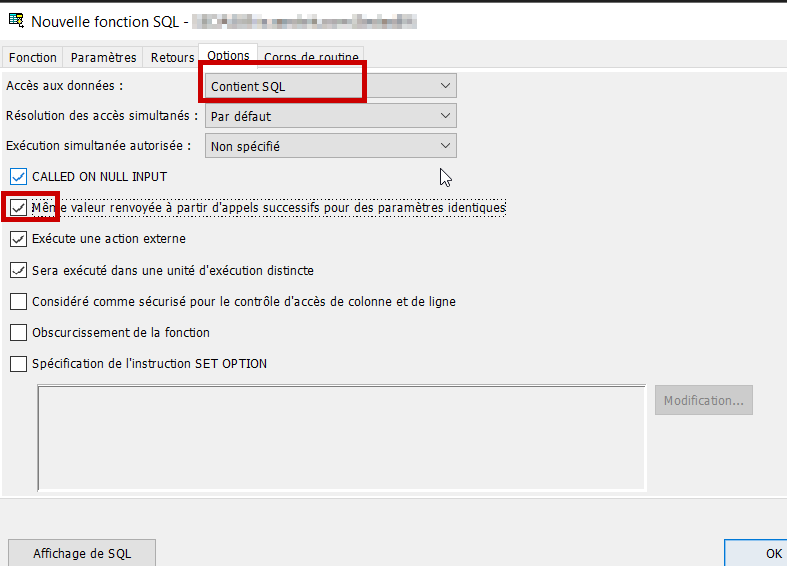
- Onglet Options : cet onglet permet de fixer le contexte d’éxecution de la fonction, et donc le bon fonctionnement de la fonction ainsi que son optimisation.
Par rapport aux valeurs par défaut, j’ai modifié 2 paramètres :
– Accès aux données. Ma fonction n’accèdera à aucune table, j’ai donc choisi l’option « Contient SQL ». Si ma fonction devait accèder à des tables en lecture uniquement, il faudrait laisser l’option par défaut « Lit des données SQL », enfin si la fonction devait mettre à jour des tables, l’option « Modifie des données SQL ».
– Même valeur renvoyée à partir d’appels successifs pour des paramètres identiques. En cochant cette case, j’autorise le moteur SQL à enregistrer le résultat de la fonction avec les paramètres d’appel dans le cache SQL et de réutiliser ce résultat sans éxécuter la fonction en cas d’appel avec les mêmes paramètres.
1230118 renverra toujours 18/01/2023. Et Date = 0, an par défaut = 0 renverra toujours null…
Ces paramètres sont à fixer selon l’usage mais aussi le code utilisé dans la fonction.
- Onglet « Corps de routine », il ne reste plus qu’à coder la fonction en SQL procédural.
Pour rappel, on encadre le code par « BEGIN (sans ;) / end (sans ; ) », dans l’interface graphique… Dans un script SQL, il faut bien ajouter un « ; » après le end.
Les conditoinnements ne prennent de « ; » que sur le end
Les instructions autres se terminent par un « ; »
On peut utiliser des variables de travail, il faut les déclarer par …. Declare !
La valeur retour est renvoyées par l’instruction return.
Vous pouvez maintenant utiliser votre fonction, que ce soit par un scripteur SQL, dans vos SQLRPGLE, dans des scripts SQL lancé par runsqlstm…
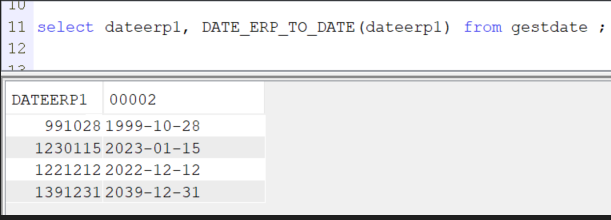
Vous constaterez que je n’ai passé que le 1er paramètre à ma fonction. Le second ayant une valeur par défaut, il devient facultatif. Ce qui veut dire, que si vous avez besoin de rajouter un paramètre à une fonction SQL déjà existante, ajouter une valeur par défaut permet de ne pas avoir à reprendre l’existant. Seuls les cas nécéssitant ce nouveau paramètre seront à traiter.
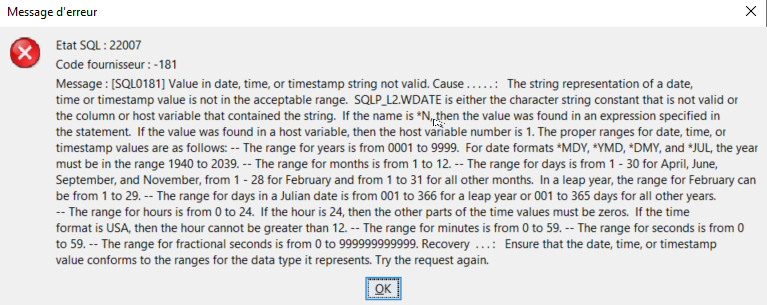
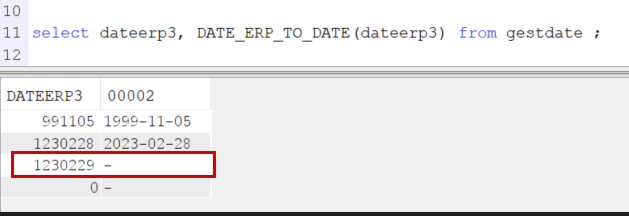
Si nous lançons la fonction sur la colonne DATEERP3 qui contient une valeur qui n’est pas une date, 1230229, la requête plante :
Les résultats s’arrêtent dès le crash et ne renvoit que les deux premiers enregistrements dont la résolution de la fonction était ok :
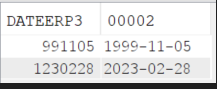
Il faut ajouter une gestion d’erreurs à notre fonction.
Et c’est une règle d’or sur les fonctions personnalisées. Vous n’avez le droit à aucun plantage de la fonction, au risque de traiter dans vos programmes des résultats tronqués si la gestion des sqlcode / sqlstate n’est pas faite.
En début de script, je rajoute le monitoring, sur le SQLSTATE renvoyé par l’erreur et je choisit de renvoyer la valeur null :
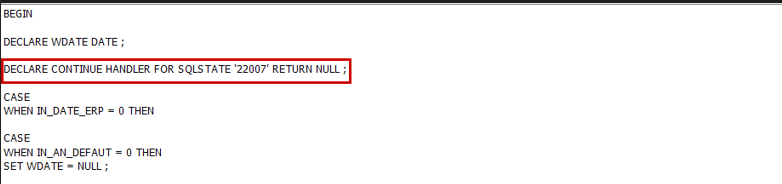
N’ayant pas beaucoup d’instructions dans ma fonction, je me contente de cette gestion d’erreur. Dans des cas plus complexe, ne pas hésiter à monitorer avec un SQLEXCEPTION
Maintenant la fonction renvoie null si la date n’existe pas et nous avons les résultats pour nos 4 enregistrements.
Si nous lançons la fonction sur la colonne DATEERP2 qui contient des dates valides et la valeur 9999999, nous constatons
que deux dates ne sont pas traduites :
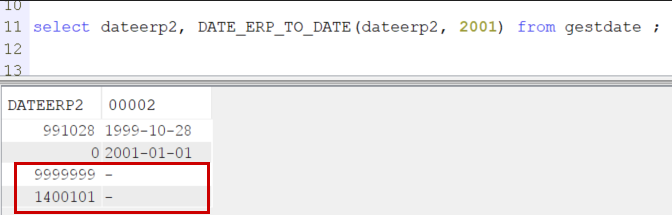
Vu que je n’ai monitoré que le sqlstate 220007, nous savons que c’est pour date invalide que la conversion n’a pas eu lieu.
Le problème vient du format de date dans ma fonction SQL, par défaut *YMD
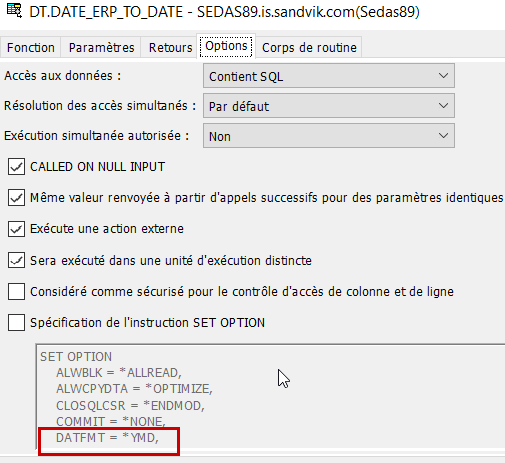
Ce format de date est limité dans le temps au 31/12/2039…
Il faut passer en format *iso pour convertir des dates au-delà de 2039, et donc pour cela modifier le set option par défaut.
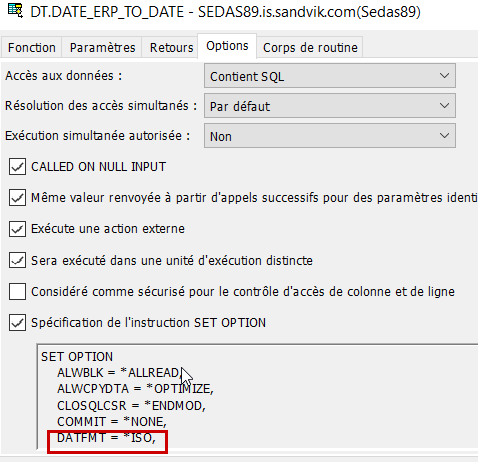
Maintenant, tout fonctionne comme voulu, ma fonction est opérationnelle :

Vous pouvez continuer à utiliser les programmes existants pour ces conversion, mais dans ce cas il faut interdire à vos développeurs la conversion dans les requêtes SQL.
L’avantage de passer par une fonction SQL, c’est que cette fonction peut aussi être utilisée par des applicatifs distants qui viennent requêter sur la base de données. Appli web, bien entendu, mais aussi les ETL, comme Talend, et de garder la main sur les règles de conversion, plutôt que de les déporter sur chaque outil.

")

