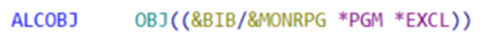Quand on fait des développements, il est parfois nécessaire de verrouiller un programme afin d’empêcher son utilisation par d’autres utilisateurs pendant qu’il est exécuté.
Cependant, il n’est pas possible de verrouiller un programme.
Lorsque on saisit :
Le programme &MONRPG peut être exécuté par un autre utilisateur. Cette commande va verrouiller la description d’objet du programme, mais pas son utilisation.
Alors, comment peut-on gérer le verrouillage d’un programme ?
Une solution possible est d’utiliser une data area qui sera allouée au début du programme avec la commande ALCOBJ. Tant que cette data area sera verrouillée par le travail, aucun autre travail ne pourra se l’allouer.
ATTENTION ! Il est possible de verrouiller à plusieurs reprises le même objet du même travail.
Cette data area restera verrouillée jusqu’à la fin du travail ou jusqu’à ce que on désalloue l’objet avec la commande DLCOBJ (l’objet doit être désalloué autant de fois qu’il a été alloué).
Si l’on ne fait pas DLCOBJ avant ALCOBJ, il peut arriver que :
1. On appelle un programme qu’on a verrouillé par une DTAARA.
2. Le programme plante.
3. L’utilisateur revient dans ce même programme.
4. Il verrouille une fois supplémentaire.
5. Quand il a fini sans problème, il va rester un verrouillage.
Il est donc important de faire DLCOBJ avant un ALCOBJ. Il désalloue ce témoin de verrouillage après usage pour laisser la place libre à un travail suivant.
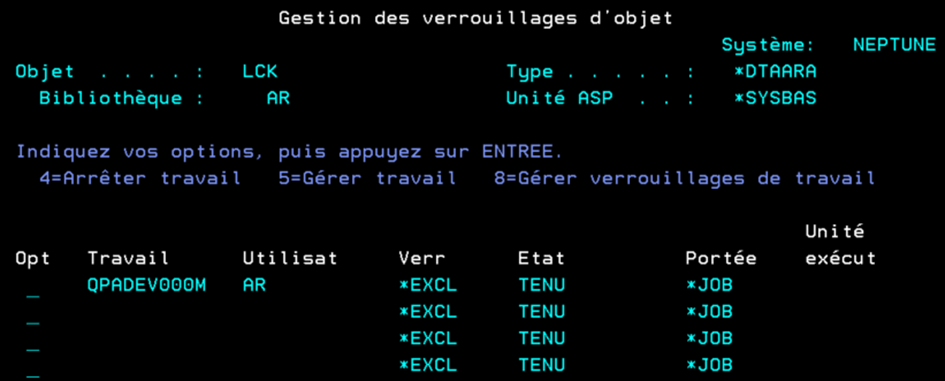
Et finalement, si l’on veut trouver le travail qui alloue, on peut utiliser la vue qsys2.object_lock_info :.
Le cache ARP (Address Resolution Protocol) est une table qui associe une adresse IP à une adresse mac, ces dernières sont utilisées pour les connexions
Le problème qui peut intervenir, c’est si vous changez une adresse IP sur une machine de votre SI, il est possible que cette information pollue votre connexion, n’étant pas mise à jour en temps réel.
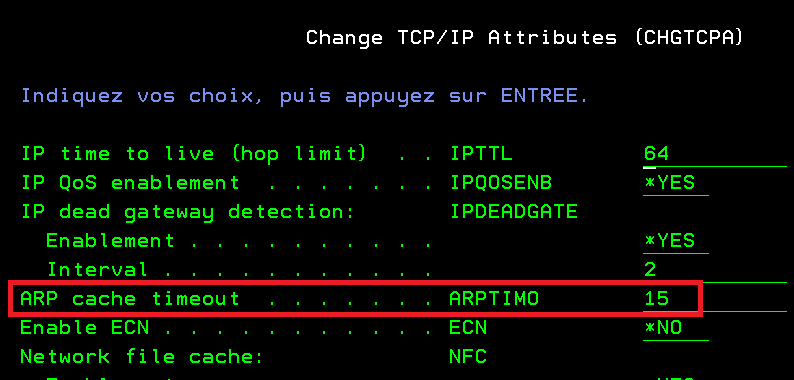
Vous pouvez régler cette fréquence par la commande CHGTCPA.
La valeur est exprimée en minutes et le plus souvent 15 minutes est un bon compromis !
Votre cache est réinitialisée par un IPL ou par un arrêt de TCP/IP c’est un peu brutal, on va voir comment le consulter et comment agir dessus.
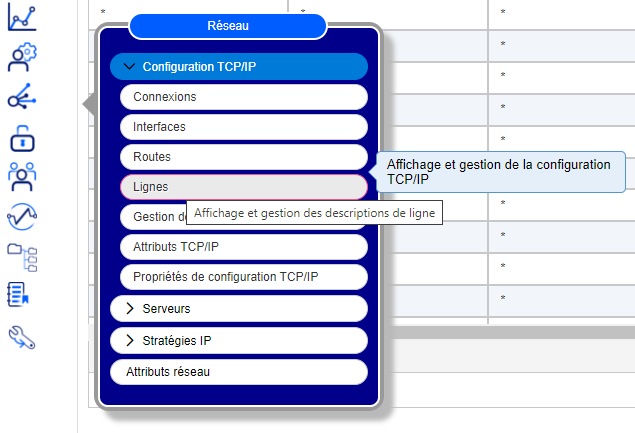
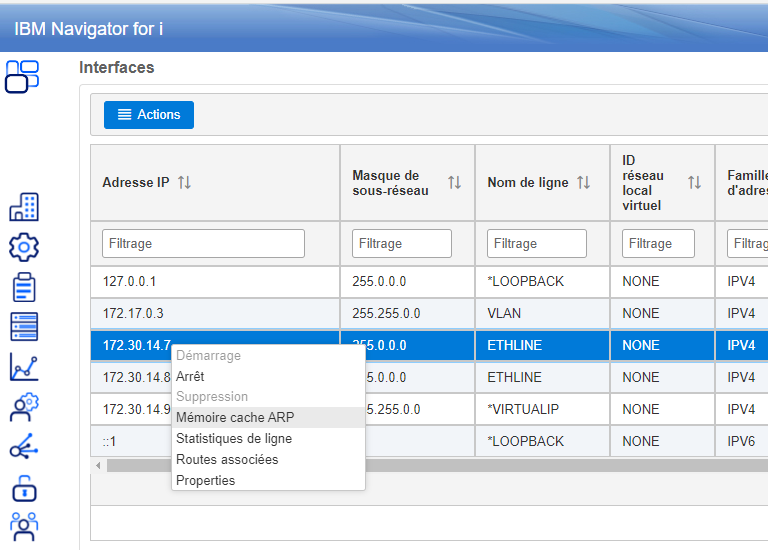
En utilisant navigator for i
Vous devez sélectionner Lignes dans le menu déroulant
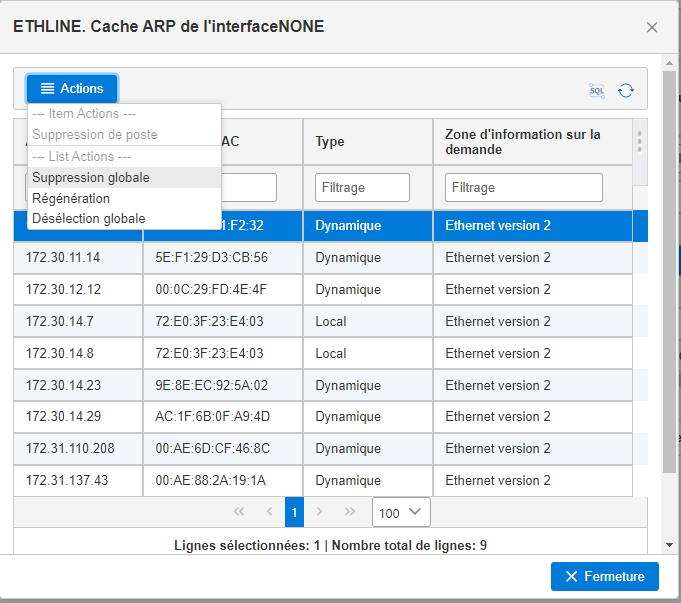
Vous pouvez voir votre cache en cliquant sur Mémoire cache ARP
Vous pouvez supprimer une entrée en cliquant dessus ou même supprimer toutes les entrées en cliquant sur suppression globale
Vous pouvez également intervenir en 5250
Vous pouvez clearer le cache en passant la commande CHGTCPDMN (sans paramètre) https://www.ibm.com/support/pages/dns-query-returning-old-ip-address
Pour le reste il existe des API
par exemple :
QtocRmvARPTblE pour clearer QtocLstPhyIfcARPTbl pour lister les entrées du cache dans un user space
Vous pouvez donc soit coder un outil, soit en récupérer un sur internet on vous met celui qu’on utilise sur mon github.
Nous utilisons de plus en plus de certificats pour crypter nos communications. Leur gestion via DCM sur l’IBM i devient donc de plus en plus nécessaire et « subtile ».
Les outils standards
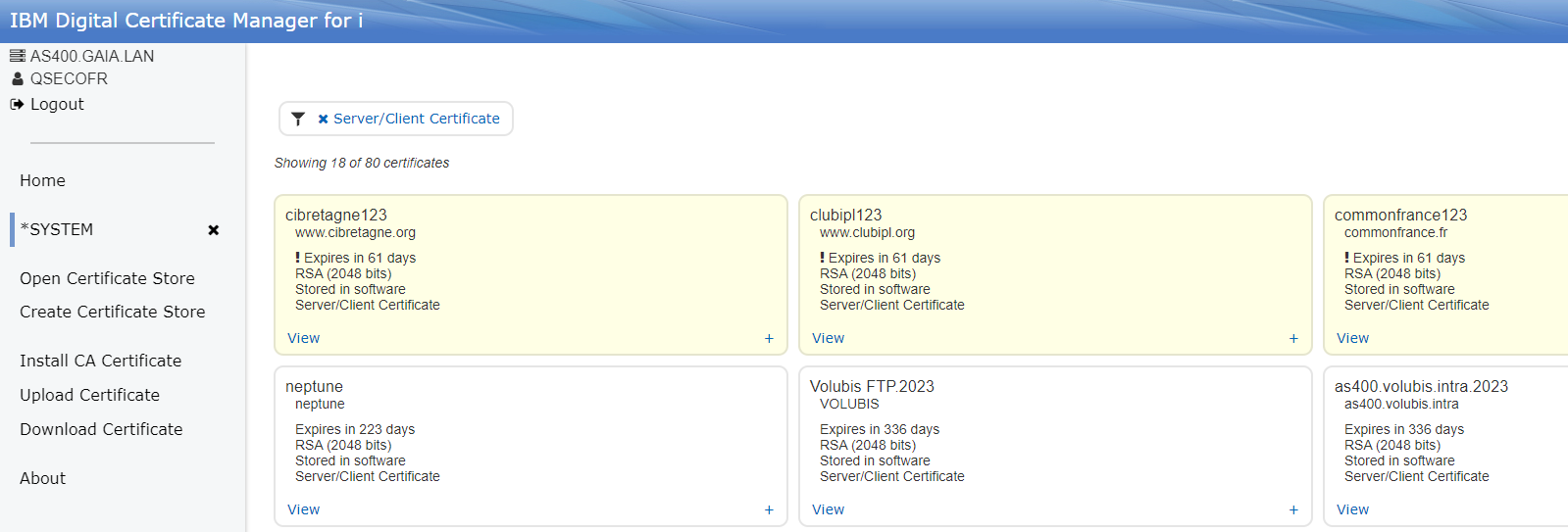
Interface web de DCM (Digital Certificate Manager)
Beaucoup plus pratique et réactive depuis sa réécriture, elle comprend l’ensemble des fonctions (presque en réalité) : création des autorités, création des certificats, gestion des applications (au sens DCM), affectation, renouvellement, importation et exportation :
C’est propre, pratique.
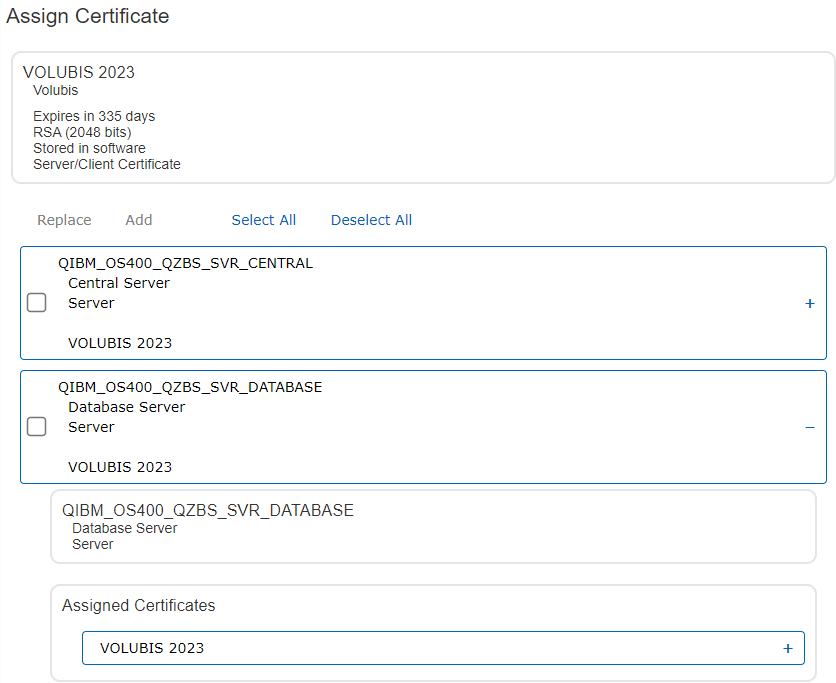
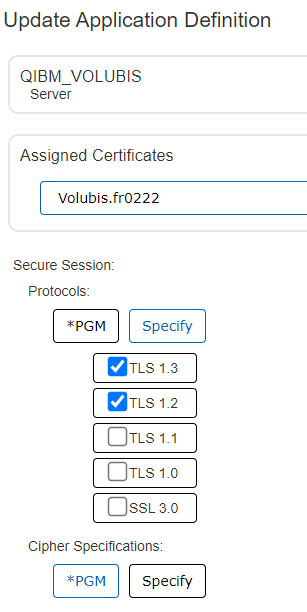
Pour rappel, le principe : DCM permet de gérer les certificats (stocker, renouveler etc …), mais également de les affecter à une ou plusieurs applications IBM i. La notion d’application dans DCM est proche d’une notion de service : serveur telnet, serveur http, serveur ou client FTP et bien d’autres.
Ainsi un certificat peut être assigné à aucune, une ou plusieurs applications :
Et chaque application dispose de ses propres attributs, permettant par exemple de choisir les niveaux de protocoles :
A priori, on a pas de raison d’aller modifier ces attributs très souvent, l’interface web est parfaite pour ces actions
Services SQL
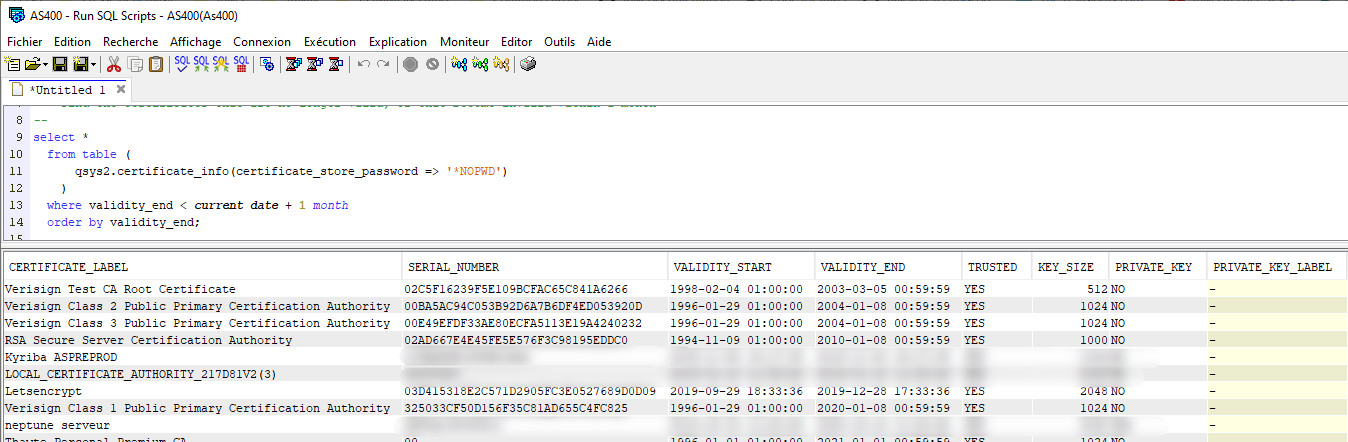
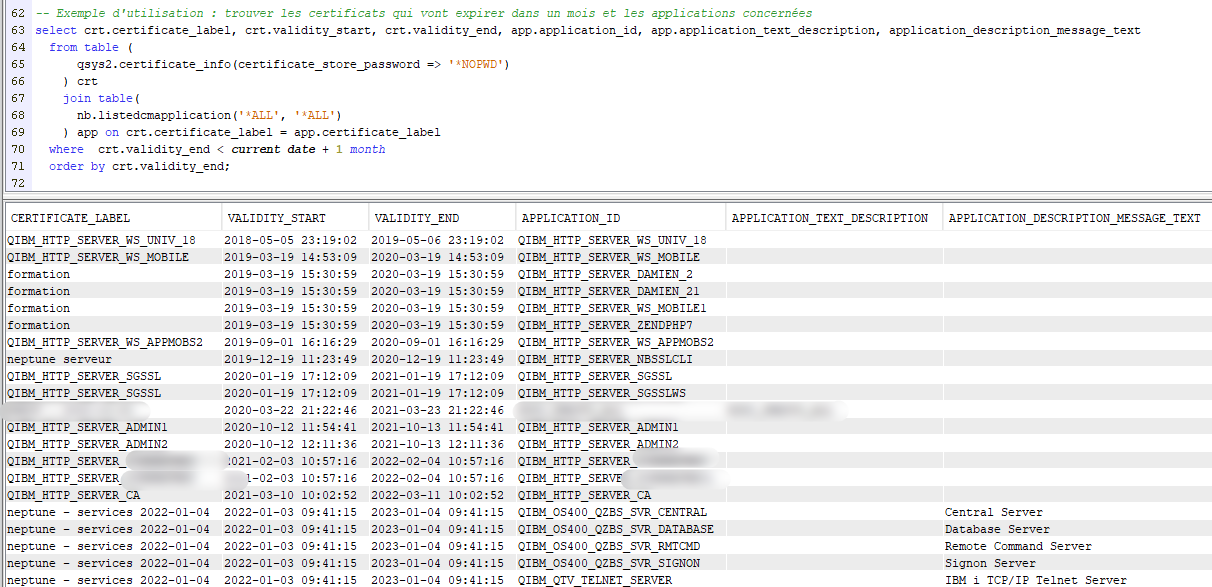
Pour plus de facilité, et de capacité d’automatisation, IBM délivre une fonction table (UTDF) : qsys2.certificate_info
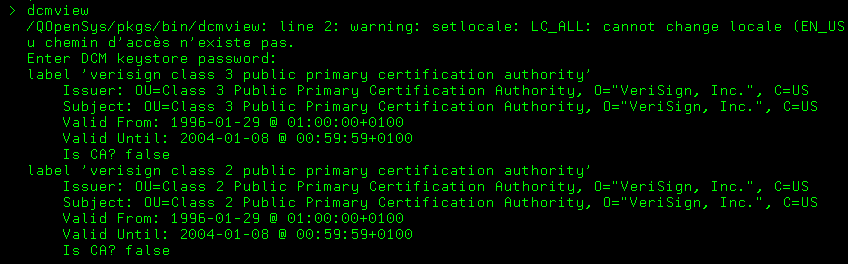
Grâce à Jesse Gorzinski (M. Open Source chez IBM), vous disposez également de commandes shell pour effectuer les principales actions de DCM : création, affectation de certificats, liste …
Il faut absolument l’installer, cela vous permet d’automatiser de nombreuses actions courantes.
Exemple :
Les applications ?
« Houston, nous avons un problème ! ». Pas si grave non plus …
Il est facile de déterminer quels sont les certificats expirés ou qui vont expirer. Donc ceux à renouveler (création par DM ou importation). Par contre, seul l’interface web de DCM permet de voir les applications assignées, et donc les impacts de la péremption du certificat !
La connaissance des applications est primordiale : certaines nécessitent un arrêt/redémarrage du service (donc une interruption pour les utilisateurs), d’autres non.
Si aucune application n’est liée, on ne va peut être rien faire. Sinon, on va anticiper (sisi).
DCM permet de voir les applications, mais il vous faut aller sur le certificat et voir le détail par l’interface graphique. Donc humainement sur chacune de vos partitions.
API -> fonction table (UDTF)
Cette information est accessible par les APIs de DCM.
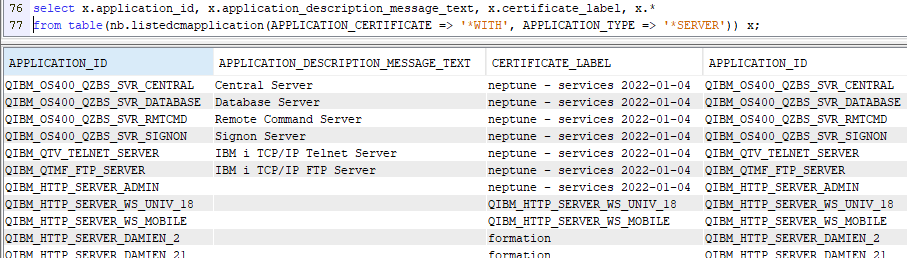
Pour plus de faciliter, nous vous proposons une fonction table SQL : listedcmapplication
L’objectif est de lister les applications ET les certificats associés :
Les deux paramètres permettent de sélectionner les applications avec ou sans certificat, les applications serveur ou client.
Vous pouvez également facilement utiliser les informations conjointes de qsys2.certificate_info. Par exemple, quels certificats vont expirer dans le mois et quelles sont les applications impactées :
Le code est open source, il est perfectible, n’hésitez pas à participer !
Quelques idées : agrégation des informations de différentes partitions, service correspondant actif ou non …
https://www.gaia.fr/wp-content/uploads/2023/02/dcm.png268618Nathanaël Bonnet/wp-content/uploads/2017/05/logogaia.pngNathanaël Bonnet2023-02-14 08:33:362023-02-14 08:35:31Gérer vos certificats par DCM
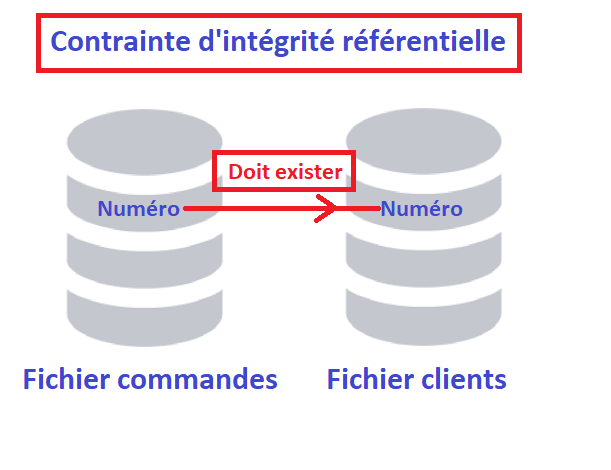
Egalement appelée clés étrangères, c’est une approche data centrique pour gérer les dépendances des données entre les tables de votre base de données.
Prenons un exemple :
Une commande ne peut pas avoir un client qui n’existe pas et à l’inverse, vous ne pouvez pas supprimer un client qui a encore des commandes
Jusqu’à maintenant, on avait tendance à laisser gérer cette dépendance à l’application, ce qui immanquablement créait des orphelins, qu’on devait corriger par des programmes de contrôle
Il existe donc une alternative c’est de demander à SQL de gérer cette dépendance, c’est l’approche data centrique, voyons comment
Dans la bibliothèque PLB nous allons créer 2 tables
tclients pour les clients
CREATE TABLE PLB.TCLIENTS ( NUMERO CHAR(6) CCSID 1147 NOT NULL DEFAULT » , NOM CHAR(30) CCSID 1147 NOT NULL DEFAULT » )
ALTER TABLE PLB.TCLIENTS ADD CONSTRAINT PLB.Q_PLB_TCLIENTS_NUMERO_00001 PRIMARY KEY( NUMERO )
Cette table doit impérativement avoir une clé primaire sur la clé que vous voulez contrôler ici NUMERO
tcommande pour les commandes
CREATE TABLE PLB.TCOMMANDE ( NUMERO CHAR(6) CCSID 1147 NOT NULL DEFAULT » , NUMEROCDE CHAR(6) CCSID 1147 NOT NULL DEFAULT » , DESCRCDE CHAR(30) CCSID 1147 NOT NULL DEFAULT » )
ALTER TABLE PLB.TCOMMANDE ADD CONSTRAINT PLB.Q_PLB_TCOMMANDE_NUMEROCDE_00001 UNIQUE( NUMEROCDE ) ;
On ajoute une clé sur le numéro de commande qui ne sert pas pour la contrainte, mais qui logiquement serait présente pour identifier votre commande
Mise en Œuvre
Pour ajouter votre contrainte vous avez 2 solutions
ALTER TABLE PLB.TCOMMANDE ADD CONSTRAINT PLB.Q_PLB_TCOMMANDE_NUMERO_00001 FOREIGN KEY( NUMERO ) REFERENCES PLB.TCLIENTS ( NUMERO ) ON DELETE RESTRICT ON UPDATE RESTRICT ;
Vous fixez une action sur le fichier parent, en cas de non respect de la règle posée, le plus souvent on met RESTRICT qui interdira l’opération. Vous pouvez regarder les autres actions pour voir , attention à *CASCADE qui peut être très brutal …
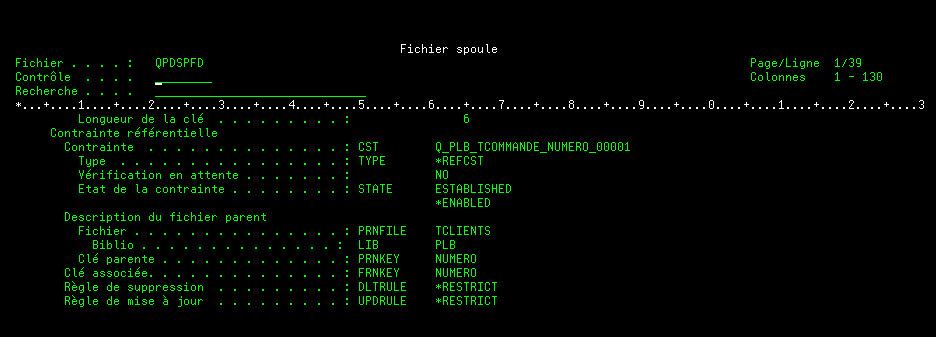
En ajoutant votre contrainte, vous pouvez avoir ce message qui indique que des valeurs ne respectent pas la régle de contrôle énoncée
Message . . . . : Les valeurs de clé de la contrainte référentielle sont incorrectes.
Cause . . . . . : La contrainte référentielle Q_PLB_TCOMMANDE_NUMERO_00001 du fichier dépendant TCOMMANDE, bibliothèque PLB, est en instance de vérification. Le fichier parent TCLIENTS, bibliothèque PLB, possède une règle de suppression de *RESTRICT et une règle de mise à jour de *RESTRICT. La contrainte est en instance de vérification car l’enregistrement 2 du fichier dépendant comporte une valeur de clé étrangère qui ne correspond pas à celle du fichier parent pour l’enregistrement 0. Si le numéro d’enregistrement du fichier parent ou du fichier dépendant est 0, l’enregistrement ne peut pas être identifié ou ne satisfait pas à l’état vérification en instance.
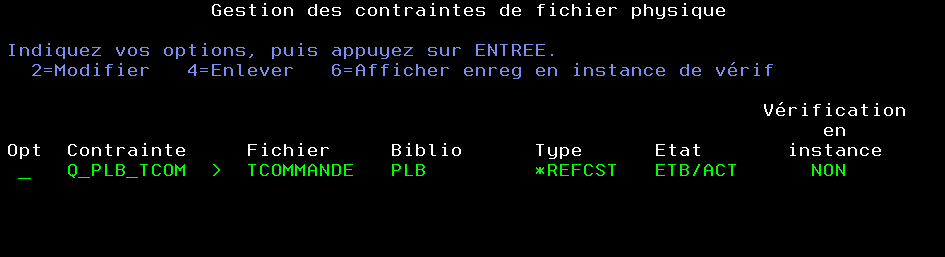
A ce moment la contrainte est active mais vous avez des enregistrements non conformes vous pouvez les voir par WRKPFCST
l’option 6 permet de voir les enregistrements en attente de validation et en erreur
Testons, si vous essayez de créer une commande avec un client qui n’existe pas vous aurez un message de ce type par DFU ou dans un programme RPGLE
Message . . . . : Violation de contrainte référentielle sur le membre TCOMMANDE.
Cause . . . . . : L’opération en cours sur le membre TCOMMANDE, fichier TCOMMANDE, bibliothèque PLB a échoué. La contrainte Q_PLB_TCOMMANDE_NUMERO_00001 empêche l’insertion ou la mise à jour du numéro d’enregistrement 0 dans le membre TCOMMANDE du fichier dépendant TCOMMANDE dans la bibliothèque PLB : aucune valeur de clé correspondante n’a été trouvée dans le membre TCLIENTS du fichier parent TCLIENTS de la bibliothèque PLB. Si le numéro d’enregistrement est zéro, l’erreur s’est produite lors d’une opération d’insertion. La règle de contrainte est 2. Les règles de contrainte sont les suivantes : 1 — *RESTRICT
dans vos programmes RPG vous pourrez par exemple utiliser les fonctions %error()
Maintenant essayons de voir ce qui ce passe dans un programme SQLRPGLE, ce qui est la norme de développement à ce jour
**FREE
// création d'une commande avec un client qui n'existe pas
exec sql
INSERT INTO PLB/TCOMMANDE VALUES('000004', '000007',
'Lunettes bleaues') ;
dsply ('Insert : ' + %char(sqlcode)) ;
// modification d'une commande avec un client qui n'existe pas
exec sql
UPDATE PLB/TCOMMANDE SET NUMERO = '000007' ;
dsply ('Update : ' + %char(sqlcode)) ;
// supression d'un client qui a des commandes
exec sql
DELETE FROM PLB/TCLIENTS WHERE NUMERO = '000001' ;
dsply ('delete : ' + %char(sqlcode)) ;
*inlr = *on ;
Vous pouvez faire un DSPFD exemple : DSPFD FILE(PLB/TCOMMANDE) TYPE(*CST)
Par les vues SQL exemple
SELECT * FROM qsys2.SYSCST WHERE TDBNAME = ‘PLB’ and TBNAME = ‘TCOMMANDE’ and CONSTRAINT_TYPE = ‘FOREIGN KEY’ ;
Vous pouvez les administrer par la commande WRKPFCST exemple : QSYS/WRKPFCST FILE(PLB/TCOMMANDE) TYPE(*REFCST)
Avec l’option 6 vous pourrez par exemple voir les enregistrements en instance de vérification, c’est la commande DSPCPCST, pas de sortie fichier !
Conseil :
C’est une très bonne solution sur vos nouvelles bases de données, mais attention l’ajouter sur des bases de données existantes peut être risqué en effet certain traitements pouvant essayer de bypasser ce contrôle, ou avoir des erreurs présentes sur votre base …
Astuces
Vous pouvez utiliser une contrainte temporaire pour vérifier les orphelins de votre base :
Ajout de la contrainte
DSPCPCST pour voir les erreurs
Retrait de la contrainte
Cette opération doit se faire hors activité utilisateur !
SYSCST La vue SYSCST contient une ligne pour chaque contrainte du schéma SQL. SYSREFCST La vue SYSREFCST contient une ligne pour chaque clé étrangère du schéma SQL. SYSKEYCST La vue SYSKEYCST contient une ou plusieurs lignes pour chaque UNIQUE KEY, PRIMARY KEY ou FOREIGN KEY dans le schéma SQL. Il existe une ligne pour chaque colonne dans chaque contrainte de clé unique ou primaire et les colonnes de référence d’une contrainte référentielle. SYSCHKCST La vue SYSCHKCST contient une ligne pour chaque contrainte de vérification dans le schéma SQL. Le tableau suivant décrit les colonnes de la vue SYSCHKCST. SYSCSTCOL La vue SYSCSTCOL enregistre les colonnes sur lesquelles les contraintes sont définies. Il existe une ligne pour chaque colonne dans une clé primaire unique et une contrainte de vérification et les colonnes de référence d’une contrainte référentielle. SYSCSTDEP La vue SYSCSTDEP enregistre les tables sur lesquelles les contraintes sont définies.
Nous rencontrons régulièrement dans les applications historiques, des dates stockées en base de données sous des types autres que date. Dans du numérique, 6 dont 0, 8 dont 0, dans de l’alpha, sur 6, 8 ou 10, dans des colonnes distinctes, SS, AA, MM, JJ….
Dans la plupart des applicatifs, il existe des programmes, ou des fonctions ile, permettant de convertir ces champs en « vrai » format date, en gérant les cas limite. Si date = 0, ou si date = 99999999, 29 février…
Dans des programmes avec des accès natifs à la base de données, ces programmes / fonctions remplissent leur rôle parfaitement.
Par contre dès qu’on choisit d’accèder à la base de données par SQL, nous constatons que ces programmes sont peu à peu délaissés pour des manipulations de date directement dans les réquêtes SQL, avec des requêtes alourdit à base de case et de concat. Pour harmoniser les règles de conversion, et allèger visuellement vos requêtes, vous pouvez créer votre propre fonction SQL, qui rendra les mêmes services que les programmes existants.
Prenons l’exemple, rencontré chez un client, d’un ERP qui stocke les dates sous un type numérique de 7 dont 0. La première position contient 0 ou 1 pour le siècle. 0 =19 et 1 = 20.
Dans cette base :
950118 = 18/01/1995
1230118 = 18/01/2023
on peut trouver les valeurs 0 et 9999999 qui ne sont pas des dates, et qu’il faudra gérer lors de la conversion
on peut trouver des fausses dates : 29022023, 31092022…
Nous allons créer une fonction SQL qui permettra de gérer la conversion de ces colonnes en « vraie » date.
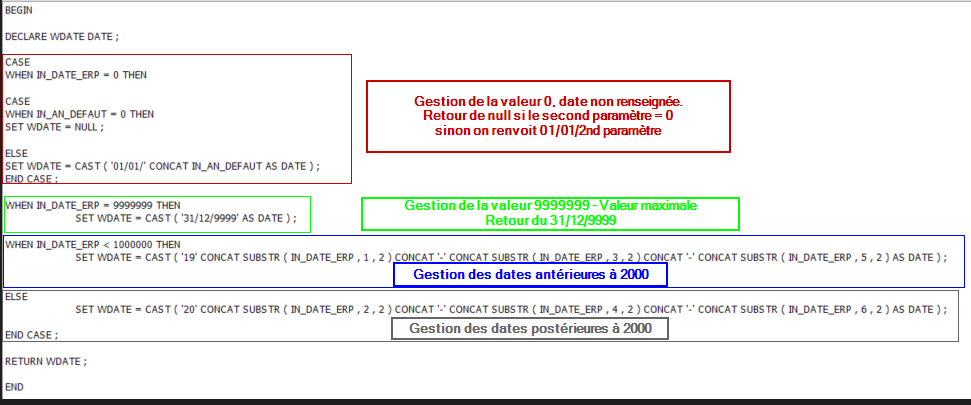
Pour la gestion des cas limites, j’ai choisi les règles suivantes, à chacun d’adapter en fonction de ses besoins :
9999999 –> 31/12/9999
0 soit null si 0 passé en second paramètre, soit 01/01/Année passée en second paramètre
les dates inexistantes –> null
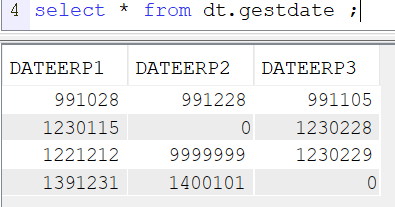
Notre jeu d’essai est composé d’une table avec 3 colonnes numérique de 7 dont 0 avec 4 enregistrements :
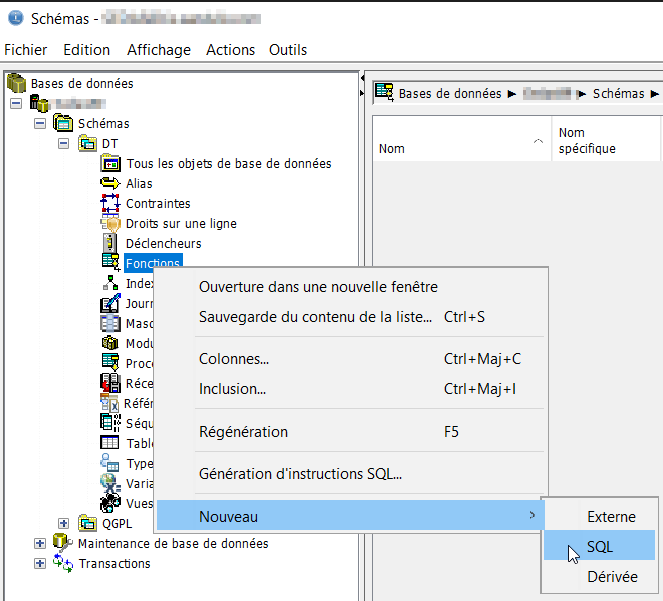
Pour créer nos propres fonctions SQL, on peut le faire directement en mode script via un requêteur SQL, ou utiliser une fonction d’ACS qui permet une préconfiguration en mode graphique. Je vais détailler cette seconde méthode.
Dans le bloc « Base de données » d’ACS, sélectionner l’option Schémas
Déplier l’arborescence, de votre base de données et Schémas.
Il va falloir se positionner sur le schéma (la bibliothèque) qui contiendra la fonction SQL. Je vous conseille d’utiliser la bibliothèque contenant vos données métier, pour en faciliter l’utilisation dans vos applications. Si les données sont en ligne, la fonction le sera aussi !
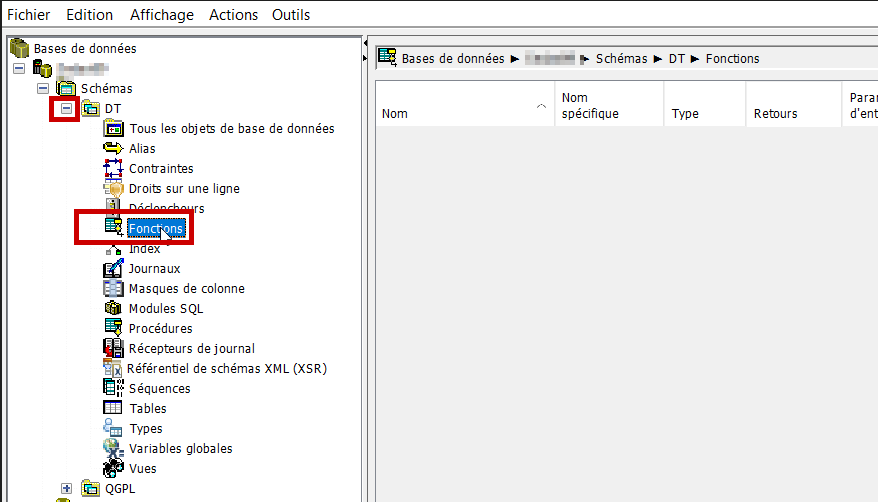
Déplier l’arboresence au niveau du schéma souhaité et cliquer sur l’item « Fonctions ».
La liste des fonctions déjà existantes dans ce schéma apparait dans la partie droite….
Par clic droit sur l’item « Fontions », choisir dans le menu, « Nouveau », puis « SQL »
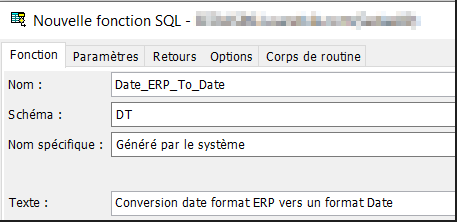
Dans la fenêtre de paramétrage, on va se déplacer d’onglet en onglet.
Saisir le nom pour votre fonction.
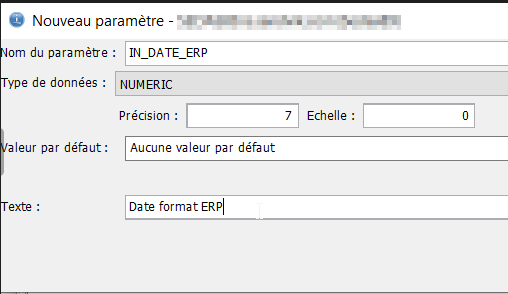
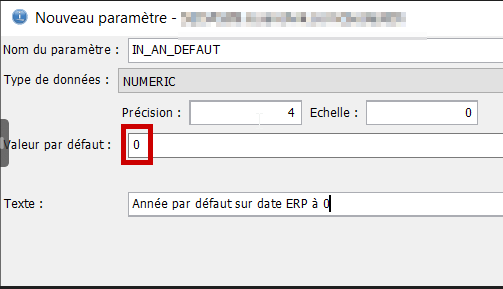
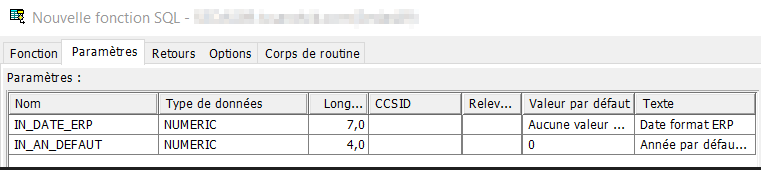
Onglet « Paramètres » par le bouton sur la droite « Ajout… », on va déclarer les paramètres en entrée de la fonction, en premier un numérique de 7 dont 0 et en second un numérique de 4 dont 0 pour passer une année par défaut en cas de 0.
Pour l’année par défaut, nous ajoutons une valeur par défaut, 0. Nous verrons l’intérêt de cette valeur par la suite.
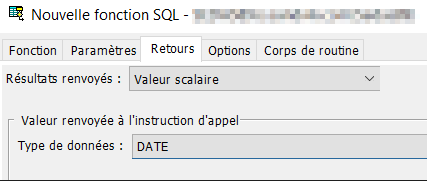
Onglet « Retours », nous déclarons la valeur de retour, soit une date au format date.
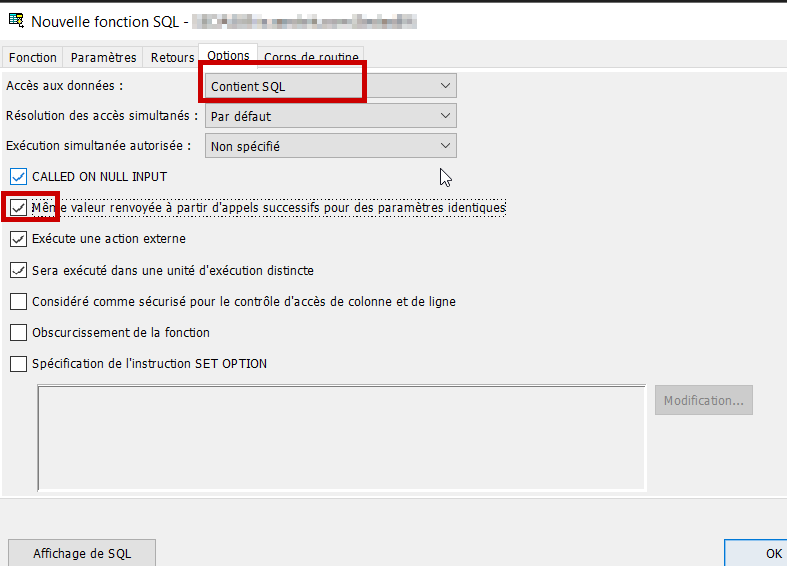
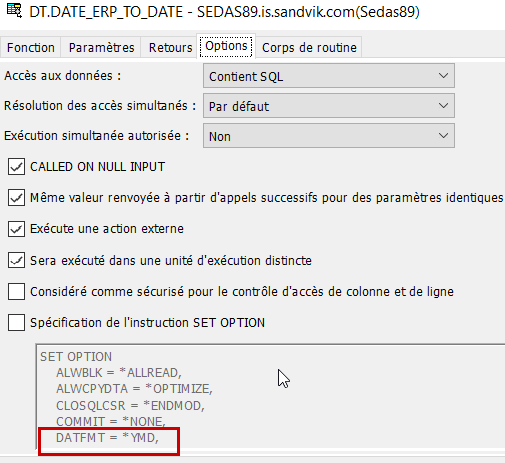
Onglet Options : cet onglet permet de fixer le contexte d’éxecution de la fonction, et donc le bon fonctionnement de la fonction ainsi que son optimisation. Par rapport aux valeurs par défaut, j’ai modifié 2 paramètres :
– Accès aux données. Ma fonction n’accèdera à aucune table, j’ai donc choisi l’option « Contient SQL ». Si ma fonction devait accèder à des tables en lecture uniquement, il faudrait laisser l’option par défaut « Lit des données SQL », enfin si la fonction devait mettre à jour des tables, l’option « Modifie des données SQL ».
– Même valeur renvoyée à partir d’appels successifs pour des paramètres identiques. En cochant cette case, j’autorise le moteur SQL à enregistrer le résultat de la fonction avec les paramètres d’appel dans le cache SQL et de réutiliser ce résultat sans éxécuter la fonction en cas d’appel avec les mêmes paramètres. 1230118 renverra toujours 18/01/2023. Et Date = 0, an par défaut = 0 renverra toujours null…
Ces paramètres sont à fixer selon l’usage mais aussi le code utilisé dans la fonction.
Onglet « Corps de routine », il ne reste plus qu’à coder la fonction en SQL procédural. Pour rappel, on encadre le code par « BEGIN (sans ;) / end (sans ; ) », dans l’interface graphique… Dans un script SQL, il faut bien ajouter un « ; » après le end. Les conditoinnements ne prennent de « ; » que sur le end Les instructions autres se terminent par un « ; » On peut utiliser des variables de travail, il faut les déclarer par …. Declare ! La valeur retour est renvoyées par l’instruction return.
Vous pouvez maintenant utiliser votre fonction, que ce soit par un scripteur SQL, dans vos SQLRPGLE, dans des scripts SQL lancé par runsqlstm…
Vous constaterez que je n’ai passé que le 1er paramètre à ma fonction. Le second ayant une valeur par défaut, il devient facultatif. Ce qui veut dire, que si vous avez besoin de rajouter un paramètre à une fonction SQL déjà existante, ajouter une valeur par défaut permet de ne pas avoir à reprendre l’existant. Seuls les cas nécéssitant ce nouveau paramètre seront à traiter.
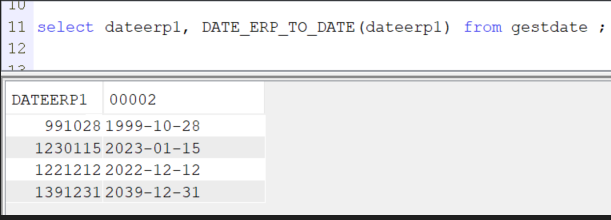
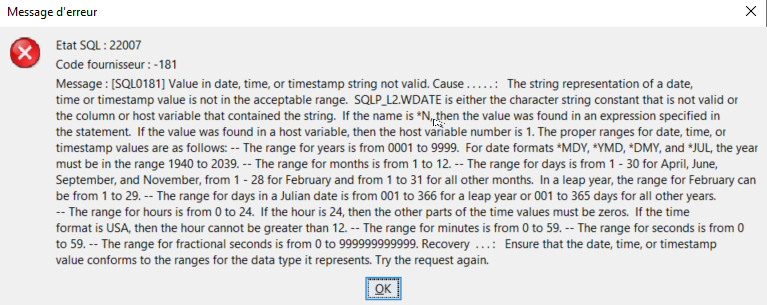
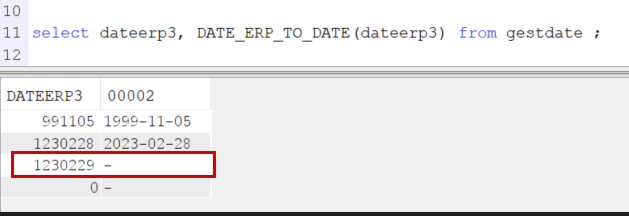
Si nous lançons la fonction sur la colonne DATEERP3 qui contient une valeur qui n’est pas une date, 1230229, la requête plante :
Les résultats s’arrêtent dès le crash et ne renvoit que les deux premiers enregistrements dont la résolution de la fonction était ok :
Il faut ajouter une gestion d’erreurs à notre fonction.
Et c’est une règle d’or sur les fonctions personnalisées. Vous n’avez le droit à aucun plantage de la fonction, au risque de traiter dans vos programmes des résultats tronqués si la gestion des sqlcode / sqlstate n’est pas faite.
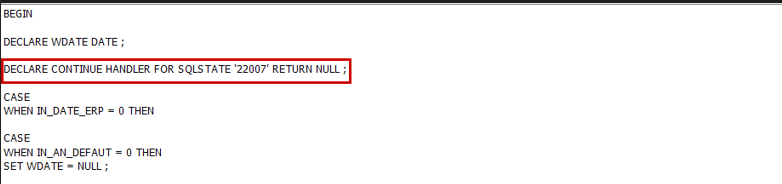
En début de script, je rajoute le monitoring, sur le SQLSTATE renvoyé par l’erreur et je choisit de renvoyer la valeur null :
N’ayant pas beaucoup d’instructions dans ma fonction, je me contente de cette gestion d’erreur. Dans des cas plus complexe, ne pas hésiter à monitorer avec un SQLEXCEPTION
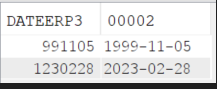
Maintenant la fonction renvoie null si la date n’existe pas et nous avons les résultats pour nos 4 enregistrements.
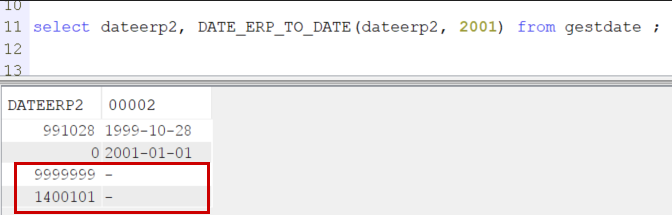
Si nous lançons la fonction sur la colonne DATEERP2 qui contient des dates valides et la valeur 9999999, nous constatons
que deux dates ne sont pas traduites :
Vu que je n’ai monitoré que le sqlstate 220007, nous savons que c’est pour date invalide que la conversion n’a pas eu lieu. Le problème vient du format de date dans ma fonction SQL, par défaut *YMD
Ce format de date est limité dans le temps au 31/12/2039…
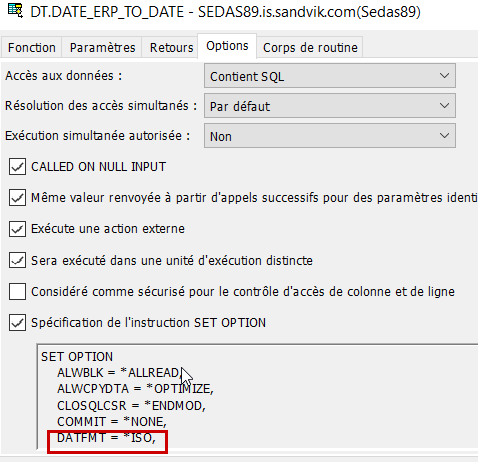
Il faut passer en format *iso pour convertir des dates au-delà de 2039, et donc pour cela modifier le set option par défaut.
Maintenant, tout fonctionne comme voulu, ma fonction est opérationnelle :
Vous pouvez continuer à utiliser les programmes existants pour ces conversion, mais dans ce cas il faut interdire à vos développeurs la conversion dans les requêtes SQL.
L’avantage de passer par une fonction SQL, c’est que cette fonction peut aussi être utilisée par des applicatifs distants qui viennent requêter sur la base de données. Appli web, bien entendu, mais aussi les ETL, comme Talend, et de garder la main sur les règles de conversion, plutôt que de les déporter sur chaque outil.
/wp-content/uploads/2017/05/logogaia.png00Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2023-01-30 17:49:172023-02-20 09:58:14Conversion en format date par fonction SQL
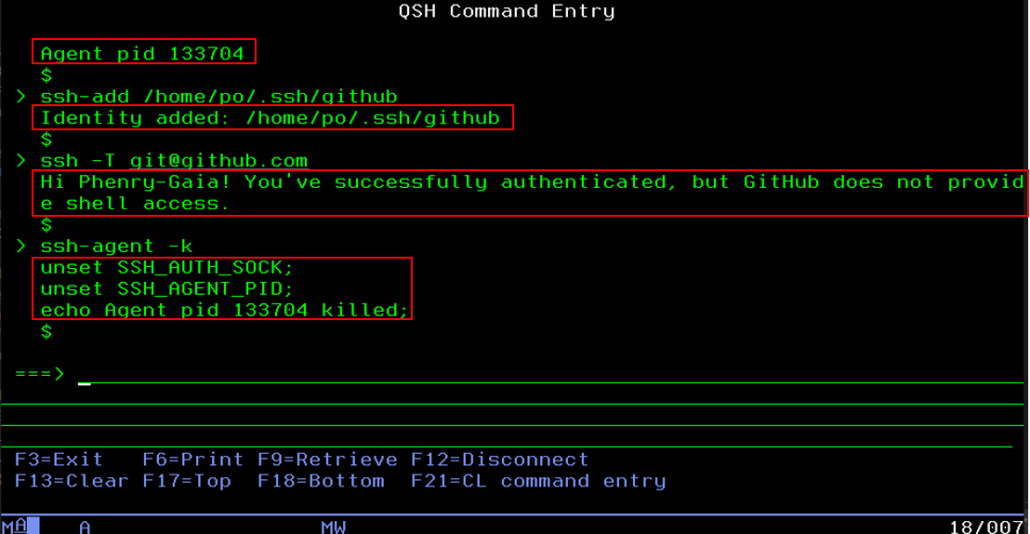
Le passage de commandes shell est tout à fait possible dans les programmes de CL (langage de contrôle sur IBM i) via QSH CMD(&maCommande). Si dans une session QSH (STRQSH) l’état des logs s’affiche, nous n’avons pas ces retours quand les commandes shell sont passées via un programme CL.
Les deux écrans suivants permettent de tester l’authentification à Github (plateforme de versionnage du code, de contrôle et de collaboration ) ; ce travail servira d’exemple à notre article :
Commandes manuelles, dans une session QSH avec les logs (en rouge)
Commande automatisée dans un programme CL, sans retour de logs
Il existe tout de même un moyen pour récupérer les logs d’une commande shell passée via un programme CL ; l’interrogation des tables système par requête SQL.
Principe
Par un programme CL, les commandes QSH sont soumises dans un travail via SBMJOB
Plusieurs paramètres sont nécessaires :
la commande QSH (ici &QSH)
le travail doit être identifiable par un nom &JOBNAME, une bibliotheque &LIB, une file de travail &JOBQ, une file de sortie &OUTQ et un utilisateur &USER ; que l’on peut déclarer de cette manière
les noms de variables et leurs valeurs sont arbitraires
l’instant t de l’exécution &TIMESTAMP
Ce sont ces paramètres qui alimentent notre requête SQL, et nous permettent de trouver les logs.
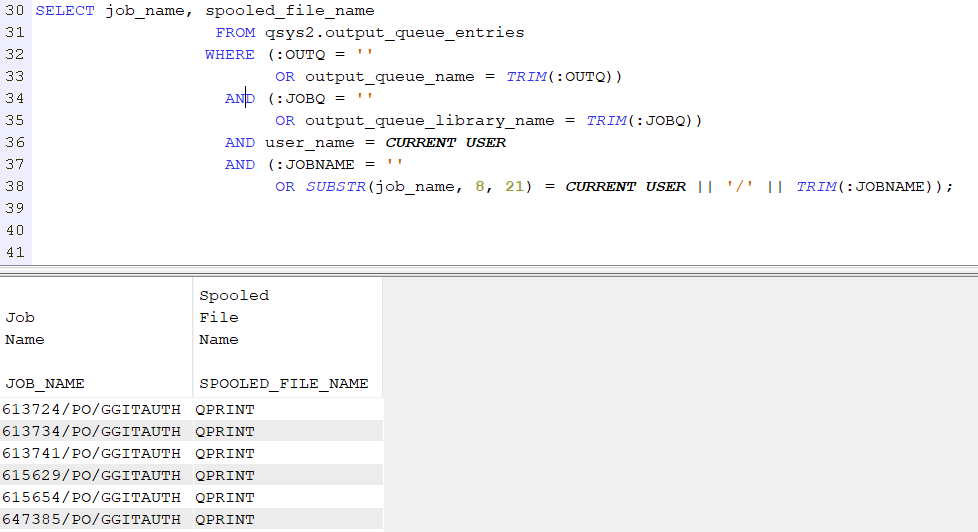
VUE qsys2.output_queue_entries
La première composante de notre requête SQL est la récupération des infos du travail en fonction des paramètres, expliqués ci-dessus, via la vue système qsys2.output_queue_entries.
Encapsulation et récupération de la liste des logs d’un travail
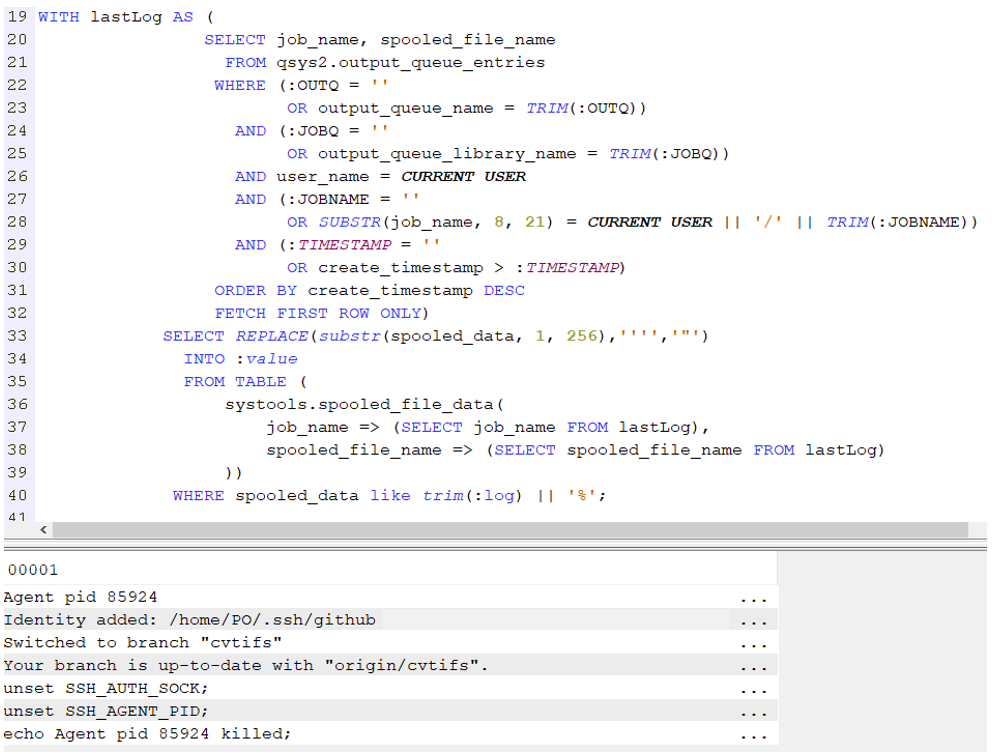
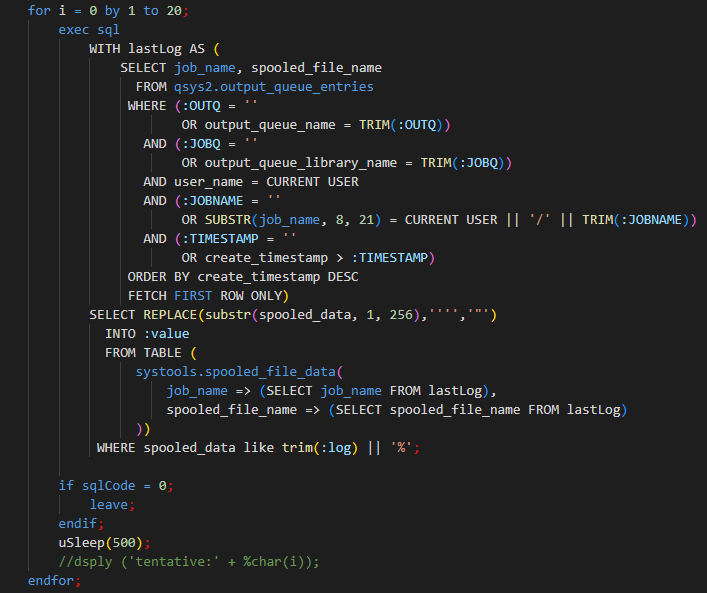
Nous récupérons la dernière ligne entrée dans qsys2.output_queue_entries (ORDER BY create_timestamp DESC FETCH FIRST ROW ONLY) que nous encapsulons dans un WITH ; ce qui correspond aux identifiants associés au dernier travail lancé par le programme CL.
Le résultat du WITH (alias lastLog ici) est passé dans un SELECT sur la vue systools.spooled_file_data pour récupérer la liste des spools associés à la commande QSH (variable &QSH dans notre exemple): WHERE spooled_data like trim(:log) || '%'.
Nous obtenons les spools associées à une (ou plusieurs) commandes QSH lancé(es) via un programme CL
Intégration dans un programme
A ce niveau, nous sommes capable d’obtenir les logs générées par une commande QSH pour consultation ; en passant nos requêtes SQL dans un exécuteur de script. Voyons maintenant comment il est possible d’obtenir ces logs par un programme et d’adapter le traitement en fonction de leurs valeurs.
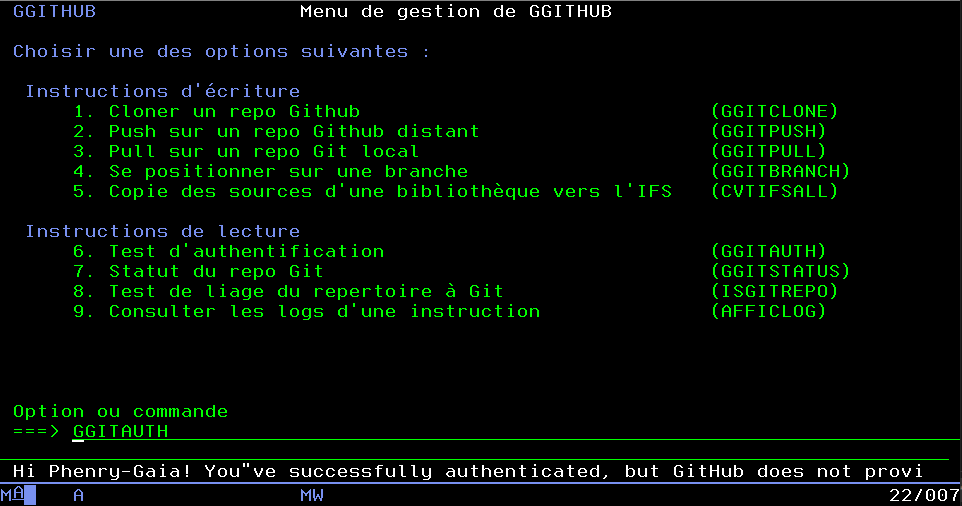
Programme CL
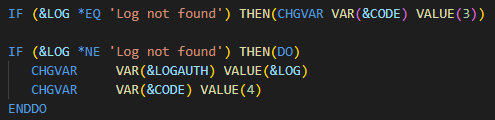
L’idée est d’avoir notre programme CL (ici ggitAuth.clle) qui :
soumet le travail,
appelle un programme SQLRPGLE qui retourne la log (ici getqshlog.sqlrpgle),
effectue le traitement en fonction de la valeur de la log retournée par le programme SQLRPGLE.
Programme SQLRPGLE
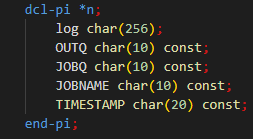
Le programme SQLRPGLE reçoit en paramètre :
la valeur de la log ciblé log,
la file de sortie OUTQ,
la file de travail JOBQ,
le nom du travail JOBNAME,
le temps d’exécution TIMESTAMP.
Par un exec sql, nous retrouvons l’interrogation de table vue précédemment. Celle-ci est intégrée dans une boucle pour gérer le délai d’écriture dans la table au moment du passage de la commande QSH :
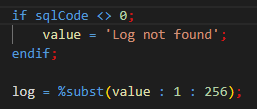
Enfin nous mettons dans une variable la valeur de la log ; qui prend ‘Log not found’ en cas d’échec de la requête (sqlCode <> 0).
En résumé
Il est possible dans un environnement IBM i d’exécuter des commandes shell comparables à ce qui peut se faire sur UNIX. Les logs générées par ces commandes sont consultables par interrogation de tables SQL. Pour aller plus loin, la récupération des logs pour analyse dans un programme permet la prise de décision dans ce dernier.
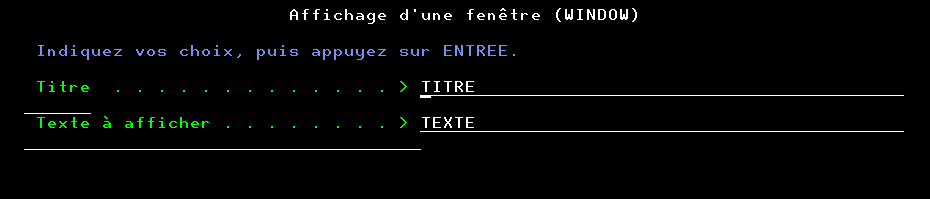
Vous avez besoin d’afficher une fenêtre avec un titre est un texte , par exemple dans des opérations d’administration
Vous pouvez utiliser un écran de type DSPF et un programme associé voici une alternative intéressante en utilisant DSM (Dynamic Screen Manager) qui vous permettra de créer dynamiquement un écran à la volée sans source à compiler
Le SQL package est un objet qui stocke des informations pour en tirer partie au cours d’une future utilisation, depuis l’arrivée du moteur SQE, ils sont utilisés en second par rapport au cache SQL
Il faut différencier 2 types de SQL PACKAGE :
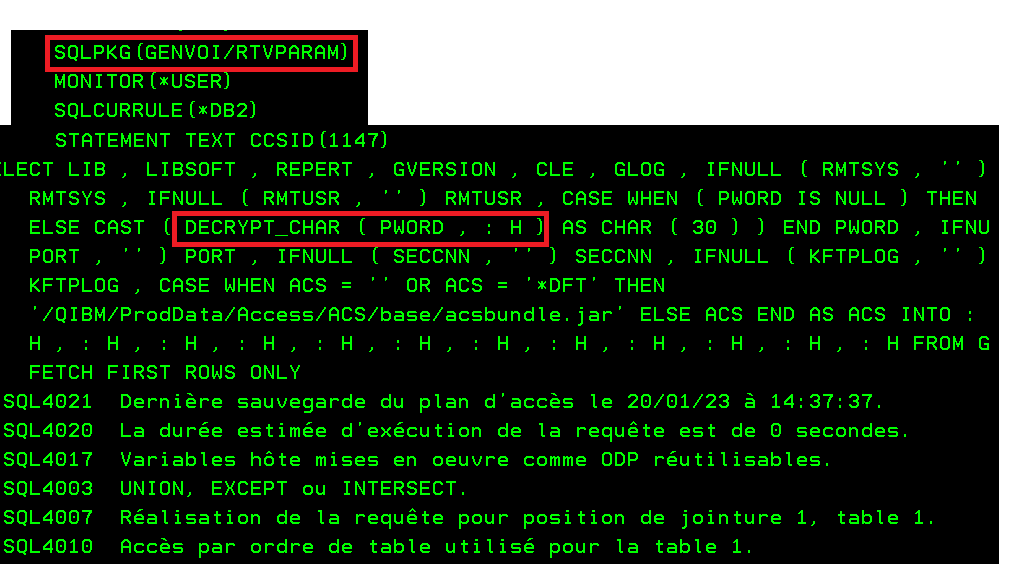
Les sql packages qui font partie de votre programme pour les SQL statiques, vous pouvez les consulter par la commande PRTSQLINF de votre programme sqlrpgle qui produira un spool comme celui ci :
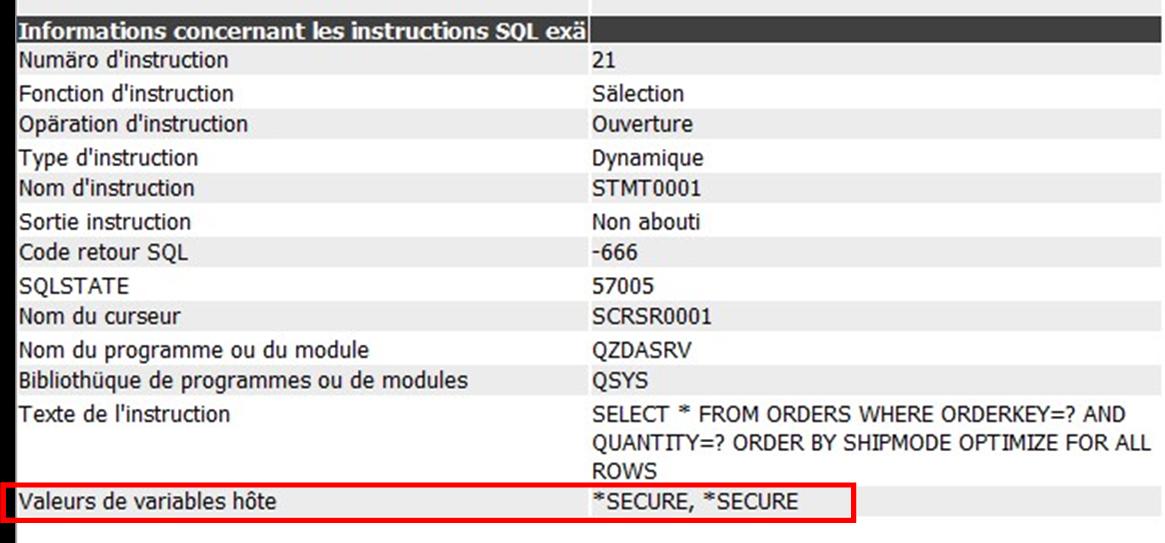
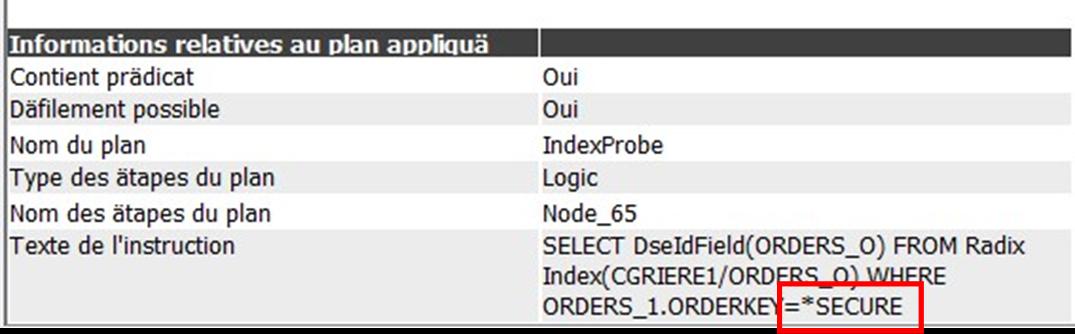
On voit que également en ayant utilisé une variable hôte que l’information n’apparait pas en claire
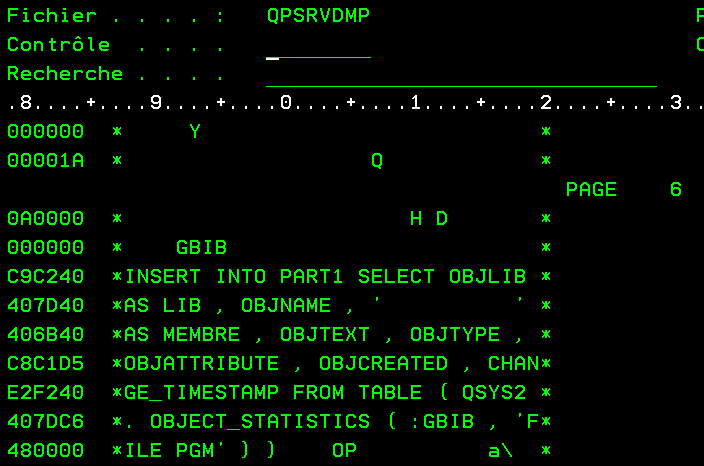
Il existe une deuxième catégorie de packages SQL qui sont dus à l’utilisation du Extended Dynamic SQL, ce sont des objets qui sont créés essentiellement pour des accès ODBC et dynamiques, ce sont des objets de type *SQLPKG, ils sont en principe créés dans la bibliothèque qui contient la base de données. SQL utilisera les informations qui sont stockées à l’intérieur quand il en aura besoin. Il est difficile de voir le contenu des ces objets , cependant vous pouvez faire un dump de cet objet, par la commande DMPOBJ comme ci-dessous , mais encore une fois pas de contenu des variables hôtes.
Ces objets peuvent être supprimés, le système les recréera automatiquement quand, par exemple, vous changez de version d’IBM i ou quand il occupe trop de place. Attention cependant, il en existe certains qui font partie de SQL comme
QSQLPKG2 de QSYS QSQXDPKG de QSYS
En règle générale, il ne faut pas toucher à ceux dont le nom commence par Q, ni aux objets qui sont dans QSYS.
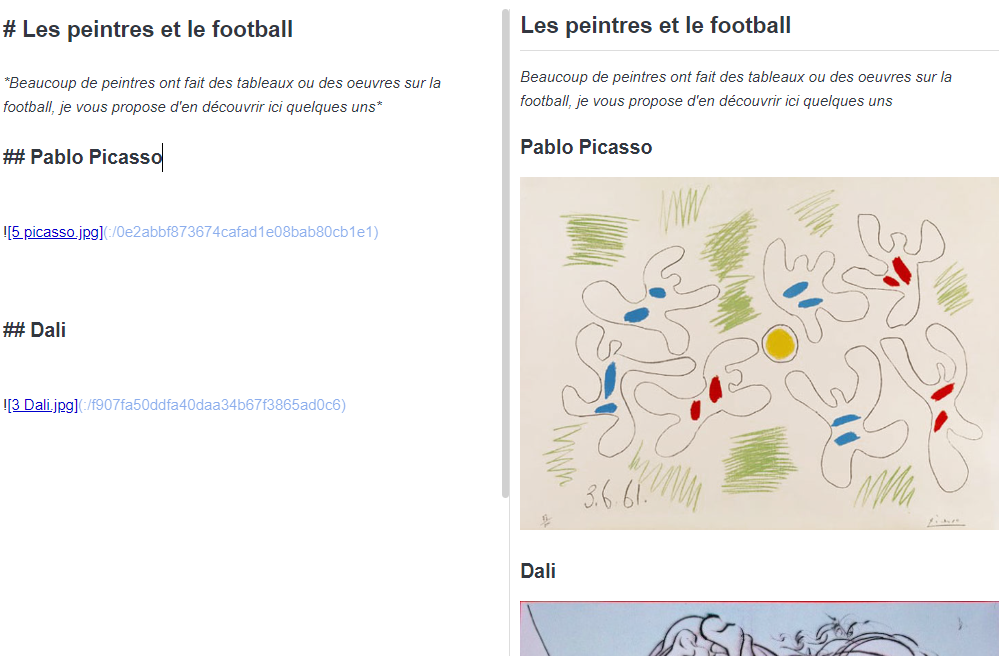
Ce son des fichiers qui ont l’extension MD, ce format a été créer par John Gruber, son but était de produire des fichiers formatés très simple à administrer un peu comme RTF mais encore en plus simple.
(il existe sous forme d’extension pour VSE également, et même sur téléphone)
L’utilisation est très simple, et relativement classique pour les utilisateurs de produits Windows
Vous avez une barre avec les différents éléments que vous voulez intégrer.
L’outil est WYSIWYG ce qui permet de voir en temps réel ce que vous voulez faire
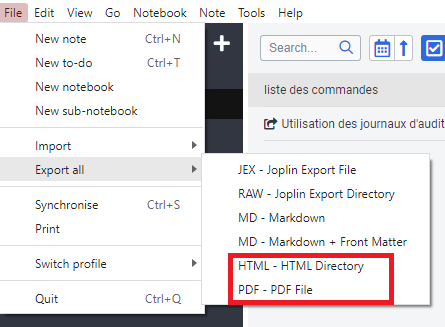
il dispose également de nombreuses possibilités d’exportation comme HTML et PDF
Conclusion :
C’est un format simple à utiliser et c’est un standard pour les nouveaux qui arrivent sur notre plateforme. il est donc fortement conseillé de vous y mettre, et l’effort n’est pas important au regard de ce qu’il peut rapidement vous apporter.
Vous pourrez facilement faire des docs techniques de qualité et les exporter, il existe de nombreuses extensions pour vous aider