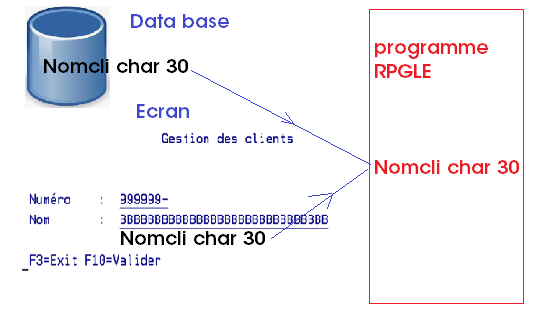
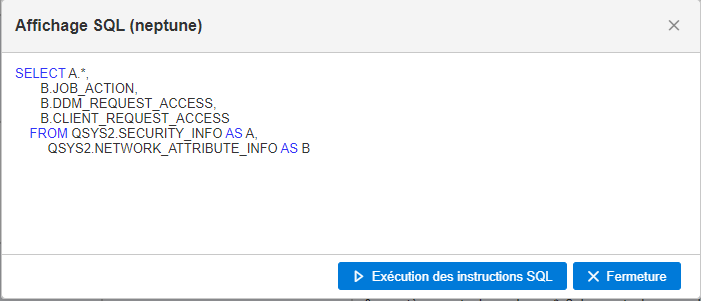
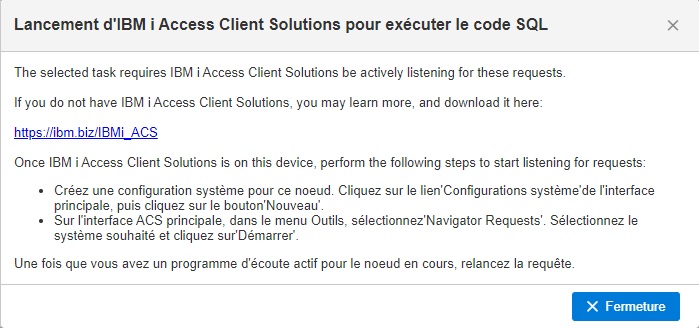
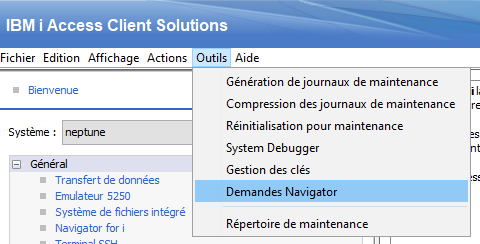
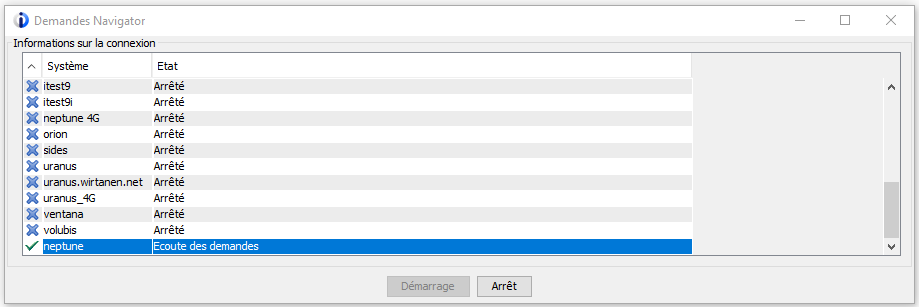
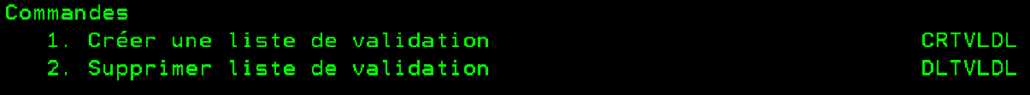Un des concepts de base qui différentie le RPG de beaucoup de langage est la bufférisation unique, je vais essayer de vous expliquer ce que c’est.
Le principe
C’est qu’une zone quelque soit son buffer de provenance DS, FMT, Zone élémentaire, etc … pour un nom et une description unique occupera qu’un seul espace mémoire dans le programme.
On dit également qu’une zone n’est pas qualifiée contrairement à d’autres langages ou on parlera de zone de tel ou tel format ou buffer….
Exemple en cobol
move nomcli of database to nomcli of ecran
dans notre cas il n’y a pas de move puisqu’on a une seule zone
évitez le (lol)
numcli = numcli ;
Les avantages
Grosse diminution des transferts de zones
Enormément utilisé dans l’existant
Les inconvénients
-Risque d’écrasement nom maitrisé, on peut avoir une zone dans 5 ou 6 buffers par exemple des zones clés
-Les doublons de zone dans 2 tables
Exemple
Filer1 dans la table1 char 30 Filer1 dans la table2 char 40
Le programme ne saura pas déterminer la définition à utiliser
Il faudra renommer une des 2 Zones, ou qualifier les zones dans les buffers ce qui revient à annuler le principe de bufferisation unique
Pour renommer une zone sur une déclaration de fichier
Vous devrez avoir une carte I
exemple ci dessous
Pour qualifier vous devrez indiquer le mot clé qualified sur la ds ou le fichier
du coup on revient à un usage classique pour les affectations de valeurs
database.nomcli = ecran.nomcli ;
Conclusion :
Ca peut être un vrai avantage, mais l’arrivée de SQL chamboule beaucoup la donne
Il faut faire un peu attention dans le cadre de la maintenance.
Les nouveaux développeurs préfèrerons un monde qualifié …
Les zones qualifiées sont automatiquement déclarées en packed, en effet elles sont considérées comme des zones internes. Très peu d’impact en réalité, sauf à des DS passées en paramètre par exemple. C’est le cas également pour les likerec où les zones sont implicitement qualified :
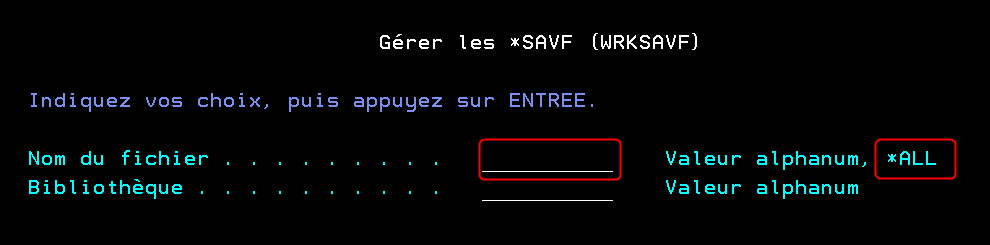
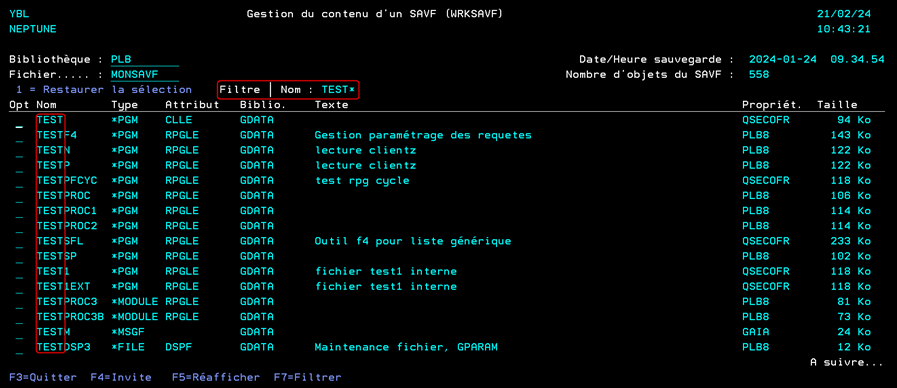
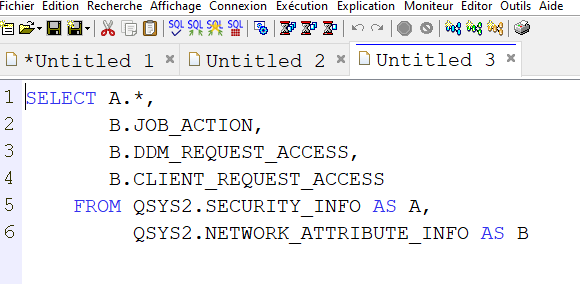
Il existe une commande DSPSAVF qui permet de visualiser le contenu d’un Save File (SAVF), elle est très utile et nous nous sommes demandés si nous pouvions améliorer son ergonomie. Depuis l’intégration des Technical Release 7.5 TR2 et 7.4 TR8, de nouvelles vues et tables de fonctions permettent d’obtenir des informations à propos des SAVF et de leur contenu.
Nous avons ainsi créé WRKSAVF, une commande qui permet de lister le contenu d’un SAVF (comme DSPSAVF) mais avec des fonctionnalités supplémentaires :
Explorer les *SAVF d’une bibliothèque
Restaurer directement un objet depuis cette liste
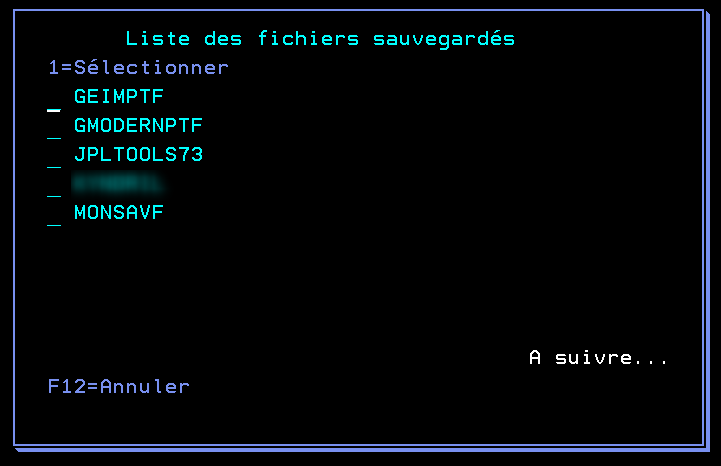
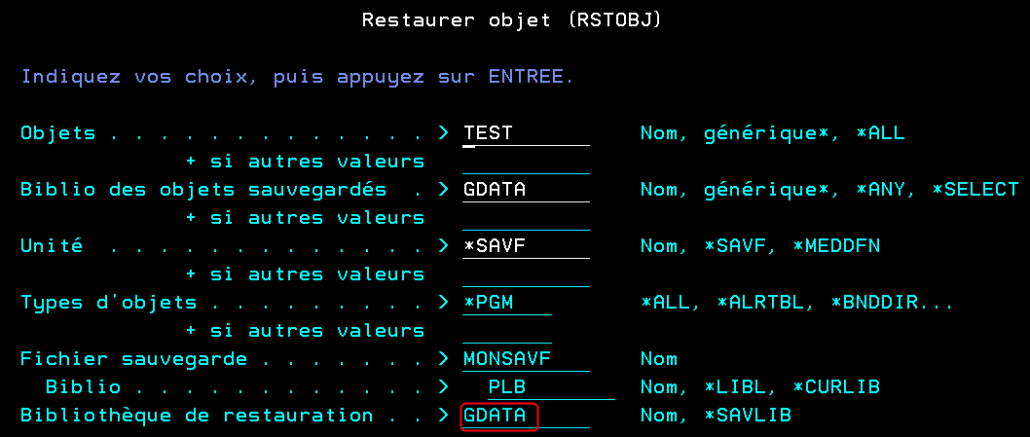
Lors du lancement de la commande WRKSAVF, vous devez choisir le fichier SAVF dans la bibliothèque souhaitée. Si vous souhaitez accéder à la liste des SAVF existants, renseignez *ALL en nom de fichier et nommez votre bibliothèque.
Ensuite, vous n’avez qu’à sélectionner le SAVF de votre choix pour accéder à ses informations essentielles.
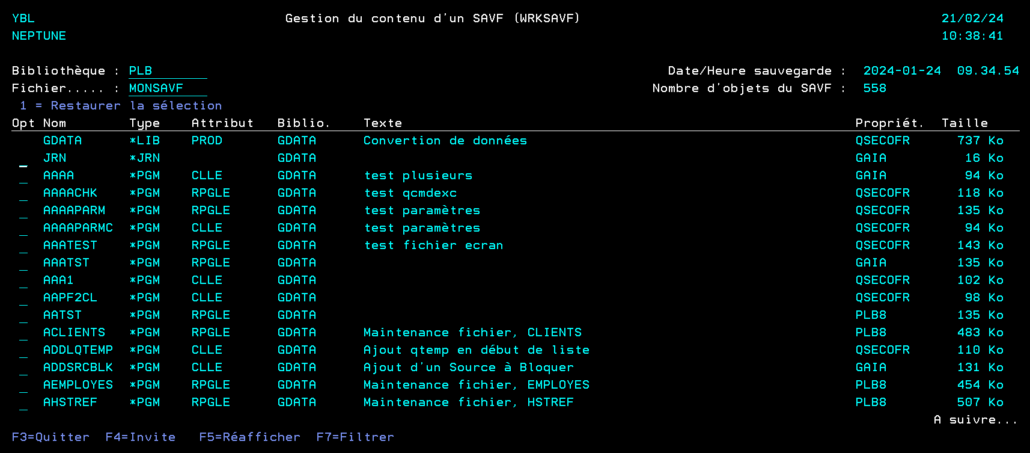
C’est à ce moment que la vue QSYS2.SAVE_FILE_INFO nous permet de récupérer des informations importantes telles que:
La date à laquelle le SAVF a été sauvegardé.
Le nombre d’objets contenus dans ce SAVF.
Si les données ont été compressées à la sauvegarde.
Etc. (je vous invite à consulter la documentation IBM i, les informations y sont nombreuses).
La deuxième vue qui nous intéresse est QSYS2.SAVE_FILE_OBJECTS, qui nous donne plus d’informations sur l’objet à l’intérieur du SAVF :
Le type de l’objet.
L’attribut de l’objet.
La bibliothèque d’origine de l’objet.
Le propriétaire de l’objet.
La taille de l’objet.
Etc. (ici encore, je vous renvoie à la documentation IBM i pour de plus amples informations ).
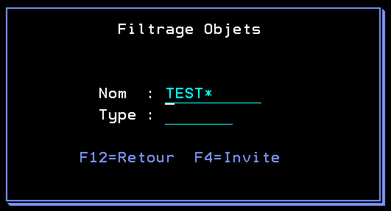
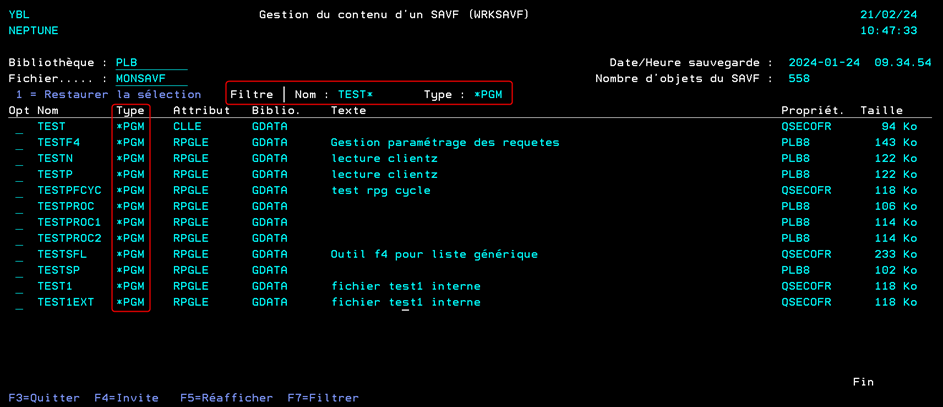
Une fois sur l’écran de gestion du contenu d’un SAVF, il vous est possible de filtrer son contenu :
Par nom, en indiquant par exemple que vous souhaitez afficher les objets commençant par « TEST »
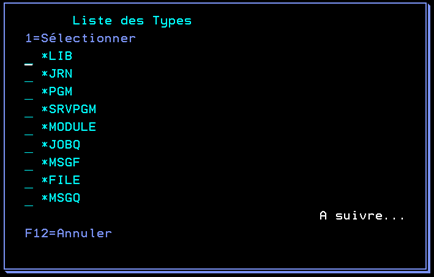
Par type, l’utilisation de F4 vous permet de choisir parmi les types existants pour les objets de ce SAVF ou en saisissant le type voulu.
Il est alors possible de restaurer un objet en indiquant l’option 1.
Attention, la bibliothèque de restauration (RSTLIB) choisie par défaut est la bibliothèque de l’objet sauvegardé, il ne vous reste alors qu’à renseigner celle de votre choix pour y restaurer l’objet.
Une fois la demande de restauration exécutée, un message de complétion au pied du SFL vous indiquera :
Que tout s’est bien déroulé.
Que tout s’est bien déroulé, avec modification de sécurité.
Premier point Les formats ne doivent pas se chevaucher
Deuxième point les formats qui devront s’afficher en plus d’un format affiché devront avoir le mot clé OVERLAY
Troisième points Pour que le contenu d’un format soit lu il faut
Exfmt + ou touche CF ou Write + Read
Notre écran a 3 formats (Haut , Milieu, Bas) c’est le milieu qui doit être en exfmt (reçoit le focus)
Le DSPF
A DSPSIZ(24 80 *DS3)
A R HAUT
A ZONE1 10A B 6 3
A 4 3'Format haut'
A R MILIEU
A OVERLAY
A CA03(03)
A ZONE2 10A B 12 3
A 10 3'Format milieu'
A R BAS
A OVERLAY
A 22 10'F3 = Exit'
A 21 3'Format bas'
**free
Ctl-Opt DFTACTGRP(*NO);
Dcl-f overlay WORKSTN;
dou *in03 ;
write haut ;
write bas ;
exfmt milieu ;
if not *in03 ;
read haut ;
dsply zone1 ;
dsply zone2 ;
endif ;
enddo ;
*inlr = *on;
Remarque :
cette règle s’applique dans les formats Fenêtres (WINDOW) par contre les règles de chevauchement pour les fenêtres sont différentes
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-02-26 07:25:242024-02-26 15:34:02Superposition dans les DSPF OVERLAY
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-02-19 07:09:142024-04-23 16:11:47Tester l’affichage de vos écrans
Vous utilisez UIM pour faire vos AIDES et vos menus
Vous voulez avoir une version multi langue sans changer votre panel de groupe
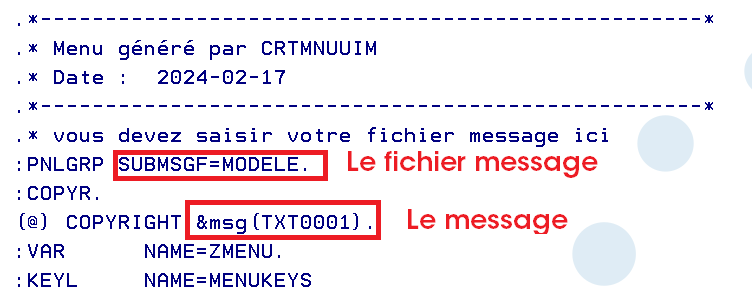
Il n’existe pas de solution dynamique, mais vous pouvez utiliser les fichiers messages, comme pour les commandes et les écrans, à la compile il vous suffira de mettre en ligne la bibliothèque avec le bon langage
rappel un message est identifié par 7 caractéres xxxnnnn xxx est est généralement 3 lettres (mais avec des exceptions exemple SQL et SQ2) nnnn est composé de 4 chiffres
La partie utilisée dans les écrans et les commandes, c’est uniquement le message sur 132 caractères c’est le paramètre MSG()
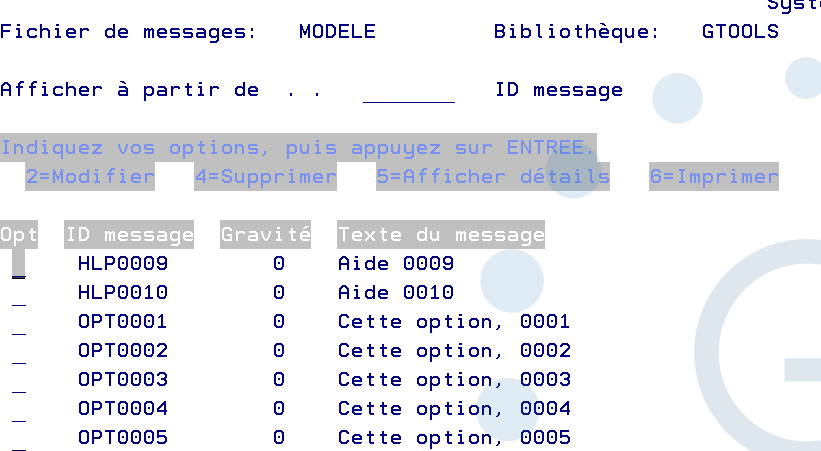
dans notre exemple : Nous avons différencié 3 Types de messages pour simplifier TXT sur la structure du menu OPT sur le texte des options à afficher HLP sur les aides d’option à afficher USR sur les commandes (mais pas utilisé pour l’instant le tag MENUI ne semblant pas admettre de message ) c’est le standard des fichiers de messages associés au menu SDA
Nous avons créer une commande
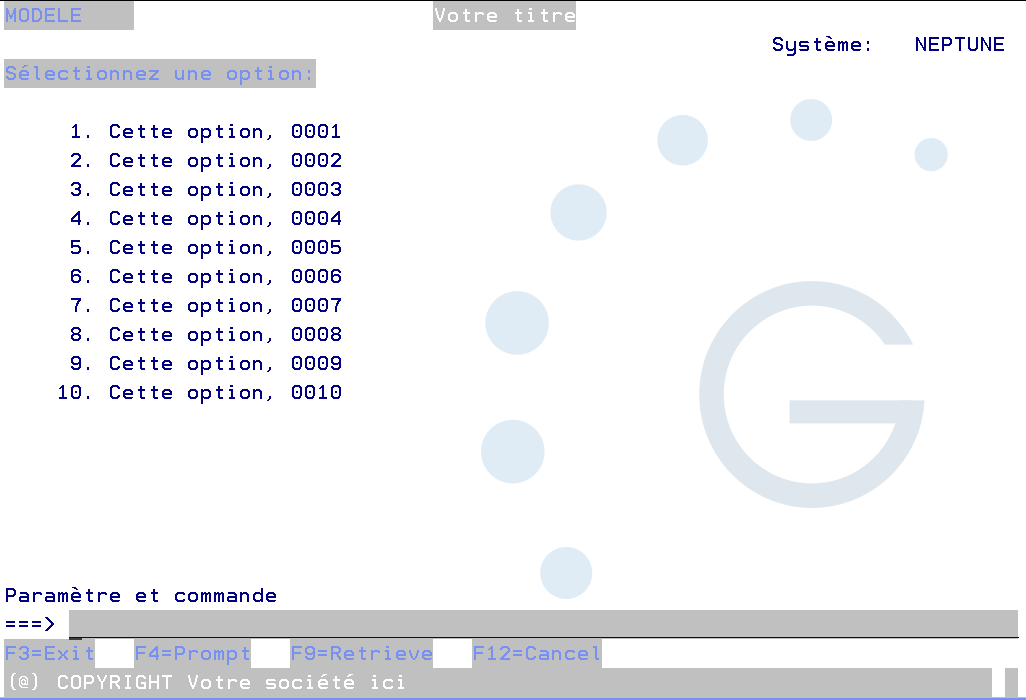
CRTMNUMOD qui génère ces messages dans le msgf, par défaut c’est un menu de 10 options avec texte en Français
Les identifiants de messages sont remplacés par les textes des messages, si vous avez une version par langue , mettez la bibliothèque de la langue en ligne avant la compile et c’est joué.
Vous pouvez utiliser la même technique sur les panneaux d’aide
Vous pouvez indiquer de nouveaux identifiants si vous avez des textes de plus de 132 caractères
Vous pouvez utiliser des caractères spéciaux pour éviter certains problèmes de syntaxe
Pour les traductions vous pouvez même les automatiser en utilisant des webservices type Google , reverso, ou deepl bientôt nous ferons un article sur ce blog
/wp-content/uploads/2017/05/logogaia.png00Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-02-18 12:14:302024-02-19 20:00:48Créer un menu UIM multi-langue
C’est une bibliothèque qui contient les sources d’environ 15 outils IBMi, le plus connu est NETS qui permet de gérer les partages en mode 5250. Elle est développée par Jim Sloan, ce sont les outils TAATOOLS et depuis la version V3.7 ce sont eux qui gérent les licences.
Donc vous pouvez acquérir une licence du produit en vous adressant ici : support@taatool.com
Vous pouvez également avoir une version des outils sur votre machine : en effet avant la version 3.7 IBM distribuait gratuitement ce produit
Dans ce menu vous avez par exemple l’option 12 qui permet de gérer les utilisateurs désactivés, c’est une alternative simple à Navigator for i dans certains cas.
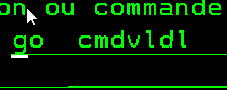
Pour rappel, les listes de validation sont des objets sur IBMi, de type VLDL.
Par ligne de commande, on peut seulement créer une liste ou la supprimer.
L’utilisation classique des listes d’autorisation est la sécurisation de vos serveurs IWS par authentification basique. Celles-ci permettent l’utilisation d’un profil qui n’est pas un réel utilisateur IBM i.
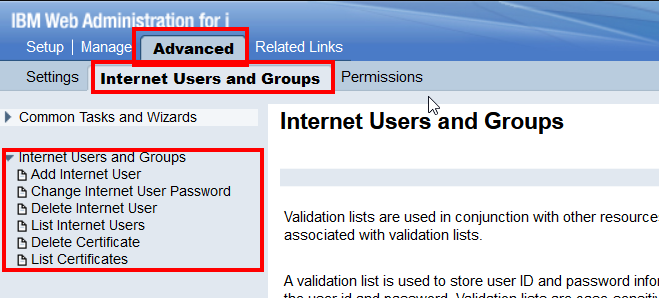
La gestion, de ces listes, se passe dans navigator for i, dans le HTTPAdmin :
Onglet « Advanced »
Ce que vous pouvez faire :
Ajouter une entrée dans la liste, si la liste de validation n’existe pas, elle sera créé pour l’occasion. A minima, il faut renseigner la liste de validation, un profil et un mot de passe
Changer le mot de passe d’une entrée
Supprimer une entrée
Lister les entrées d’une liste
Ce que vous ne pouvez pas faire :
Consulter le mot de passe en cours d’une entrée, un classique en terme de sécurité.
Supprimer une liste de validation, il faut utiliser la commande 5250 DLTVLDL
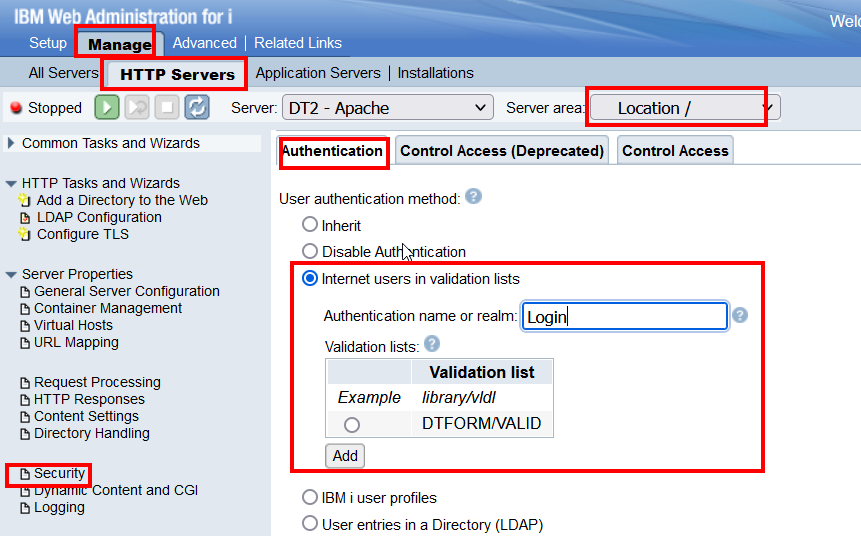
Pour mettre en place la sécurisation d’un serveur via ces listes, il faut, toujours depuis le HTTPAdmin, au niveau de la gestion des sécurités de votre serveur HTTP*, sélectionner l’option liste de validation :
Avantage :
Ne pas créer de réel utilisateur IBMi pour l’authentification.
Permettre à des tiers extérieurs d’avoir un login ne pouvant servir que dans le cadre d’appel HTTP à un serveur protéger par la liste d’autorisation dont est issu le login
Encryption de la liste au niveau OS. Pas de possibilité d’accès aux données de la liste de façon simple.
En cas d’appel depuis l’extérieur du réseau de confiance, ça semble une bonne option.
Inconvénient :
Il faut connaître en amont le client qui va se connecter, et donc avoir une gestion de demande /création de compte
L’interface de gestion n’est pas compatible avec un grand nombre d’entrées dans la liste. Dans ce cas il faudra, soit trouver une autre solution pour sécuriser son serveur, soit utiliser les API misent à disposition par IBM
* Sur les versions récentes, la sécurité peut aussi être gérée au niveau du serveur applicatif. A vous de voir, si vous voulez un duo de serveurs HTTP/applicatif ou seulement un serveur applicatif, mais c’est un autre sujet…
IBM nous fournit des API pour gérer les listes de validation. On retrouve les actions possibles dans Navigator for i…. Et d’autres !
En regardant de plus près ces API, on constate sur la création d’une entrée de la présence d’un attribut permettant ou non de décrypter un mot de passe :
Navigator for i utilisant les valeurs par défaut, lorsqu’on crée une entrée par ce biais, le mot de passe n’est pas décryptable. Par contre, si on crée une entrée par l’API correspondante, avec cet attribut positionné à QSY_VFY_FIND (1), on peut par la suite récupérer le mot de passe via l’API C QsyFindValidationLstEntry() ou son équivalent QSYFDVLE
Prenons des exemples :
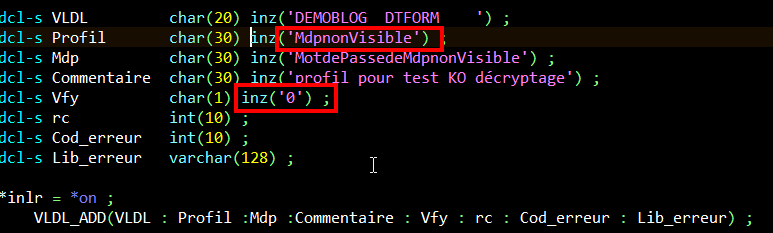
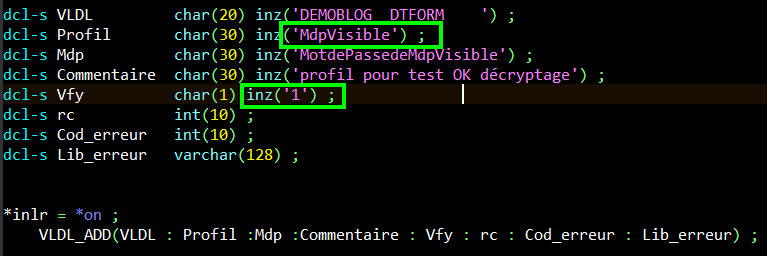
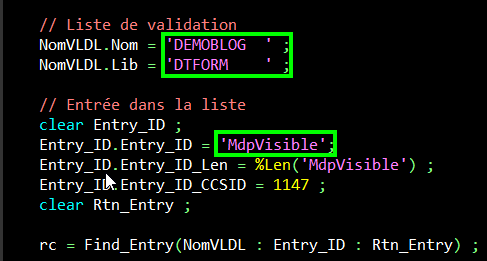
Je crée dans une liste de validation, dédié à l’article, DTFORM/DEMOBLOG, un profil MdpnonVIsible avec l’attribut de décryptage à ‘0’, et un profil MdpVisible avec l’attribut de décryptage à ‘1’.
Première remarque : l’appel d’api d’ajout d’une entrée dans une liste de validation renvoie un erreur si la liste n’existe pas. Il faut la créer au préalable par la commande CRTVLDL.
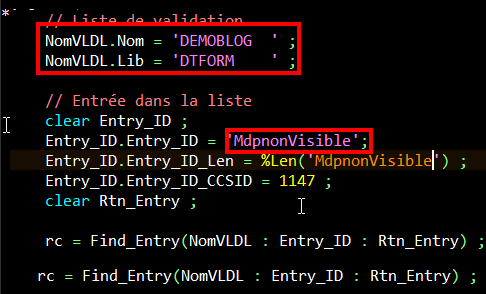
En regardant dans Navigator for i, les deux entrées apparaissent sans distinction :
Lors du décryptage, si on tente un appel de l’API find avec une erreur, mauvais nom de liste, profil inexistant, …, le retour est en erreur, comme pour toutes les API : -1. On peut récupérer le message détaillé de l’erreur, on reste sur de la gestion standard :
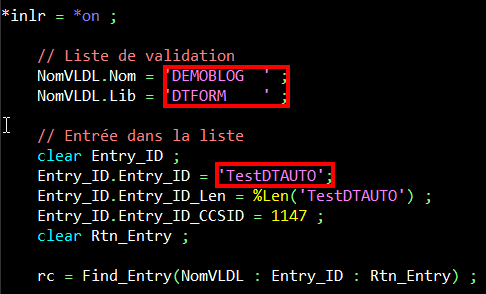
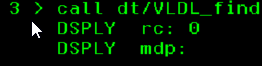
Si on lance l’API Find avec pour le profil MdpnonVisible :
L’API renvoie un code retour ok, mais pas de mot de passe, normal, il n’est pas décryptable.
Avec le profil décryptable, on récupère bien le mot de passe initial :
Par cette méthode, vous pouvez donc récupérer des mots de passe stockés dans une liste de validation, à la condition que l’entrée ait été créée avec le top de décryptage à ‘1‘.
Pour compléter la sécurité sur le décryptage des mots de passe, vous pouvez mettre :
Sur la liste de validation
Un profil technique comme propriétaire
Aucun droit sur aucun autre profil .
Avoir un programme dédié au décryptage avec :
Comme propriétaire le même que celui de la liste de validation
Compilé pour faire de l’adoption de droit.
Et si on veut aller plus loin, en cas de debug possible en prod, protéger les sources, du programme de décryptage et ses appelants, par mot de passe.
Bien entendu cette stratégie n’est valable que si la gestion des droits utilisateurs est rigoureuse… Pas de *allobj sur les profils par exemple !
Conclusion :
Vous pouvez utiliser les listes de validation pour stocker des profils/mot de passe, sans les stocker en clair sur la machine. Mais on peut très bien imaginer utiliser ces listes pour stocker toutes les données sensibles permettant les échanges inter-applications ou autre :
URL d’invocation de WS
IP ou nom DNS pour FTP / SFTP
…
Et pour cela de se créer une liste par usage, liste pour URL, liste pour IP/DNS, …, de mettre dans le profil, un code application, et dans le mot de passe la valeur que l’on veut récupérer, avec la limitation de 600 caractères pour le mot de passe, à part pour des URL très spécifique, ça ne devrait pas être limitatif.
Les listes de validation restent des objets très peu connu, mais qui mérite de l’être !
/wp-content/uploads/2017/05/logogaia.png00Damien Trijasson/wp-content/uploads/2017/05/logogaia.pngDamien Trijasson2024-02-05 14:16:002024-04-15 17:56:25Utiliser les listes de validation comme coffre fort de mot de passe
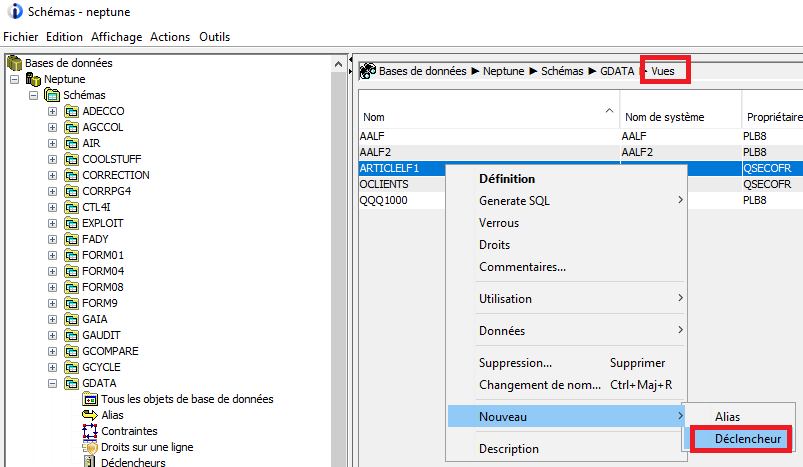
On connait les triggers before et after, mais on peut créer des triggers instead of pour remplacer l’action prévue, par exemple en écrivant dans une autre table
Ce type de trigger ne peut être mis que sur des vues
Voici un exemple
Création d’une table des frais
CREATE TABLE PLB/CLIENT_FRAIS ( NOM CHAR ( 40) NOT NULL WITH DEFAULT, PRENOM CHAR ( 30) NOT NULL WITH DEFAULT, MONTANT DEC ( 9, 2) NOT NULL WITH DEFAULT, NUMEMP CHAR ( 6) NOT NULL WITH DEFAULT)
Création d’une table audit des frais
CREATE TABLE PLB/AUDIT_FRAIS ( NUMEMP CHAR ( 06) NOT NULL WITH DEFAULT, MONTANT DEC ( 9, 2) NOT NULL WITH DEFAULT, DATFRAIS DATE NOT NULL WITH DEFAULT, HEUREFRAIS TIME NOT NULL WITH DEFAULT)
Création d’une vue sur la table des frais
CREATE VIEW PLB/CLIENT_FRAIS_vue AS SELECT * FROM PLB/CLIENT_FRAIS
Création d’un trigger Instead of sur cette vue Qui quand on écrit dans la table des frais remplace cette écriture par une écriture dans le fichiers des audits de frais.
CREATE TRIGGER INSTEADTEST INSTEAD OF INSERT ON CLIENT_FRAIS_vue REFERENCING NEW AS N FOR EACH ROW MODE DB2ROW BEGIN ATOMIC INSERT INTO AUDIT_FRAIS VALUES(N.NUMEMP, N.MONTANT, current date , current time);
END;
Test ajout d’un enregistrement
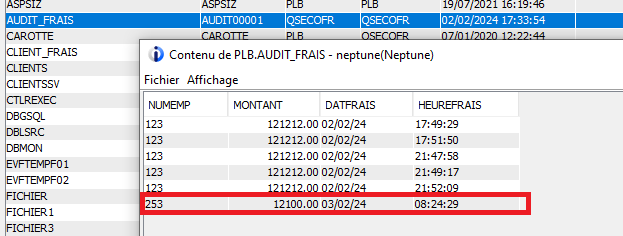
INSERT INTO PLB/CLIENT_FRAIS VALUES(‘Bouzin’, ‘Maurice’, 12100, 253)
Vous retrouvez l’enregistrement dans le fichier audit de frais et non celui des frais
https://www.gaia.fr/wp-content/uploads/2017/02/team3.png600600Pierre-Louis BERTHOIN/wp-content/uploads/2017/05/logogaia.pngPierre-Louis BERTHOIN2024-01-18 16:59:252024-01-30 17:00:12Requêtes SQL dans ACS extraites de Navigator for i